이해하기 위해 많은 배경지식이 필요한듯,,
Mutual information 이라는 개념 자체가 재미있는 게
class에 대하여 loss를 구하는 것보다 contrastive 하게 loss를 구하는게 더 많은 정보를 담을 수 있다는 것!
꽤나 흥미로운 부분,,
[CPC]Representation Learning with Contrastive Predictive Coding
High-level information
일반적으로 Down-stream task를 high level problem이라고 하는데 문장을 예시로 보았을 때
'하늘이 예쁘다' 처럼 문장의 의미는 데이터 전체를 걸쳐서 담겨 있음. 즉 데이터 안에서 변화가 느리다.
또한 '하늘이' '예쁘다' 와 같이 데이터 안에서 정보가 공유 되고 이런 거를 shared information이라고 이해하면 될듯
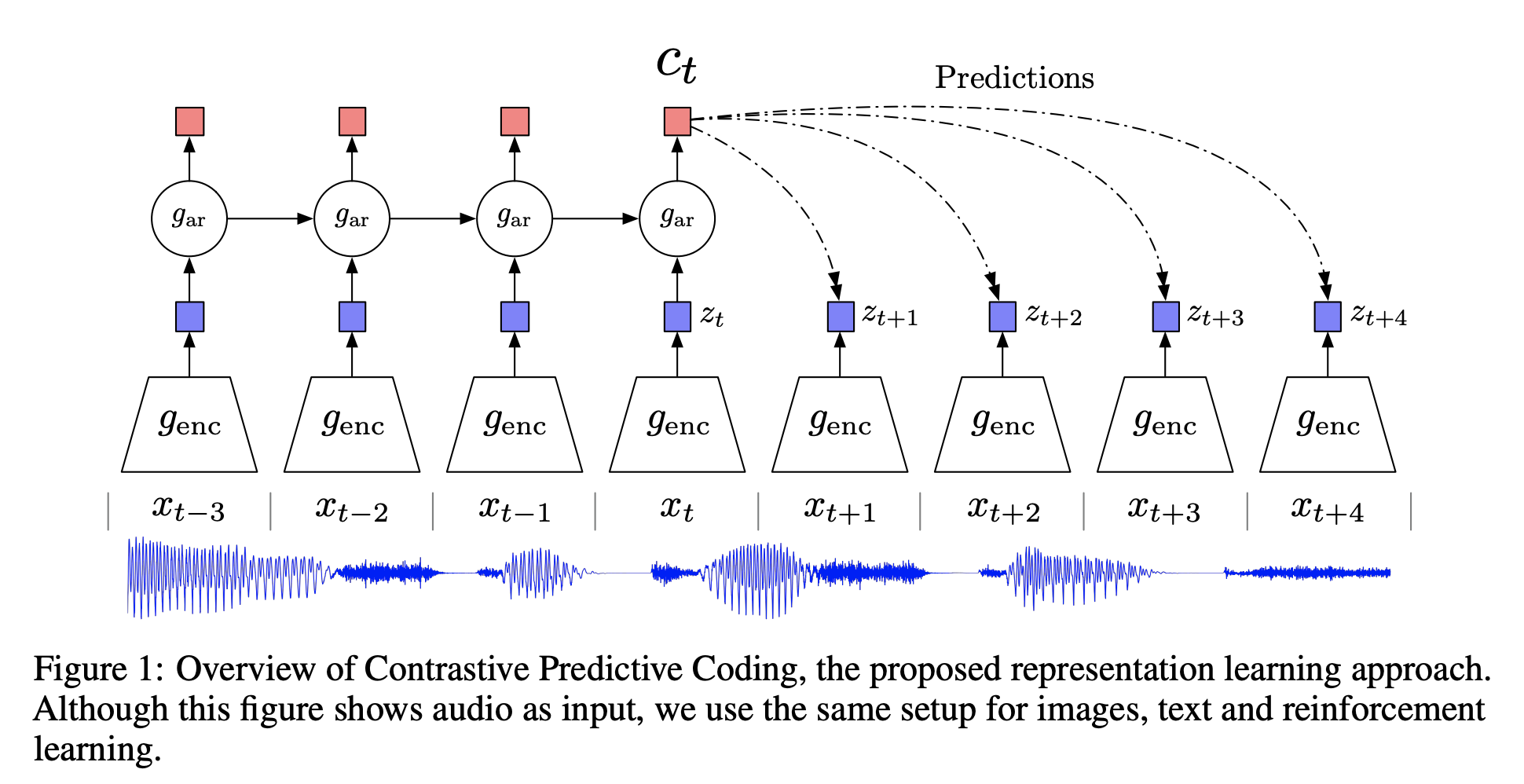
흥미로운 점은 비교적 먼 거리에 있는 positive 쌍들도 가깝게 되도록 학습을 하는 건데, 구조가 attention 연산과 비슷하다.
[NCE]Noise-contrastive estimation: A new estimation principle for unnormalized statistical models
https://paperswithcode.com/method/infonce
본 논문이랑 infonce에 관한 코드를 읽어보면 더 좋을듯
정말 간단히 정리하고 넘어가자면 input이 들어왔을 때 class로 분류하기 보다는 이게 '진짜' 확률 분포에서 나온 건지, 인위적으로 만든 확률 분포에서 나온 건지 분류하는 이진 모델로 학습을 시킬 수 있다! 이러면 많은 class들에 대해 계산할 필요 없이 binary하게 학습이 가능해짐
(하지만 인위적 분포에서 왔다는 걸 어떻게 아는지 아직 이해 못함)
Introduction
기존의 random walk 기반의 모델은 "가까이"있는 node들이 representation space에서도 "가까이" 있어야한다는 직관에서 고안됨. 하지만 이러한 방식은 하이퍼 파라미터에 민감하고, proximity information을 over-emphasize한다.
따라서 본 논문에서는 "Mutual Information"을 기반으로한 unnsupervised graph learning 방식을 제시.
여기서도 contrastive method들 사용하는데 대조 대상이 global / local parts of a graph임!
3.DGI METHODOLOGY
일단 node feature set을 adjacency matrix로 받음 (N, N)
목표는 encoder, E를 학습시키는 것
E(X, A) = H이고, H는 high-level representation임 나중에 얘네들은 down stream task에 씀!!
3.2 Local- Global MUTUAL INFORMATION MAXIMIZATION
SUMMARY VECTOR (s) : 전체 그래프의 정보를 담은 global information
s = R(E(X, A))
readout function R
discriminator D
D(h, s)는 probability scores assigned to patch-summary pair(높을수록 해당 patch가 summary를 담고 있으니 좋은 것)
Negative sample은 다른 graph에서 가져오거나, 아니면 corruption function C 통과시켜서 augmentaion해서 씀
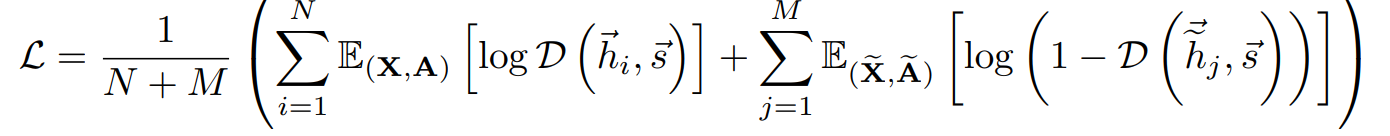
결국 이런식으로 negative sample M개랑 positive n개 해서 BCE loss 최적화하면 됨
이런 식으로 결국 모든 patch representation들이 global graph summary를 담고 있는 mutual information를 보존하기 때문에 거리가 멀더라도 비슷한 node의 유사성을 발견할 수 있게 함
4.2 EXPERIMENTAL SETUP
Transductive Learning
E를 뭔가 재미있게 구할 줄 알았는데 GCN layer 적용해서 Transductive learning (train/ test data set 분리안하고 전체에 대해 학습하는 것)
Corruption function
C의 경우에는 row-wise shuffling을 통해서 같은 node지만 그래프에서 위치가 바뀌도록 세팅
Inductvie learning
GCN대신 mean-pooling propagtion rule 적용
근데 이게 뭐지,,,
(그래프 노드들의 특징을 추출해서 표현하기 때문에 훈련 데이터가 아닌 새로운 데이터에도 적용 가능하다고 함,,,(???))
Readout, discriminator
뭐야 넘 실망,, R그냥 H들 평균 냄
D는 scoring matrix W 학습해야 됨 (??????)
생각해보니 unsupervised learning이니까 정답이 없네... 그래서 W도 학습해도 되는구나
4.3 Results
흥미롭게 supervised learning인 GCN보다 unupservised learning인 DGI의 성능이 좋았는데 이는 two-layer neighborhood만 볼 수 있는 GCN과 달리 DGI에서는 모든 노드들이 전체 그래프의 구조 정보에 접근이 가능했기 때문이다.
