[ICDE'24]Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
Abstract
LLM 기반의 추천을 할 때는 추천 시스템과 large semantic gap이 존재함
본논문에서는 어쨌든 CF 잘잡는 LLM 기반 추천시스템 만들고자했고, candidate set없이 전체 item set에서 generate하는 방식으로
item indexing 방법으로는 vector quantization 방식 사용
Introduction
계속해서 등장하는~~ Language sematntic과 collaborative semantic 사이의 gap~~~
LLM에 의해 인코딩된 text embedding으로부터 discrete ID 만들어냄( vector quantization해서)
이때 uniform semantic mapping을 통해서 potential conflict in ID allocation 해결
alijgnment tuning을 위해서는 specific task series를 고안했음 (LLM 파인튜닝함)
sequential item prediction에다가 explicit index language alignment랑 implicit recommendation-oriented alignment 추가
METHOD
1) Sequential Item Prediction

이런식으로 LLM prompt에 넣어서 next item prediction 파인튜닝
2) Explicit Index-Language Alignment
결국엔 item indice들은 text description semantic 정보를 담고 있어야 하고, 관련있는 다른 item에 대한 정보도 담아야 함..

3) Implicit Recommendation-oriented Alignmen

이런 식의 비대칭적 학습도 시킴ㄷㄷ
진짜 온갖거 다 시키네...
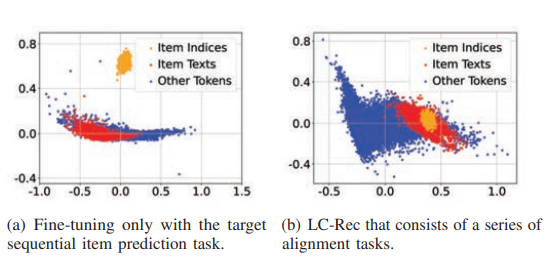
우왕 이런 식으로 기존 방식은 Item indice들이 text 들하고 멀리 떨어져있었는데
LC-Rec 통해서는 어느정도 겹치게 됨
-> Semantic 반영이 되었당 ,,,
