[CIKM'24]Learnable Item Tokenization for Generative Recommendation
Introduction
기존의 Item tokenization 방법론들은 세 가지 type으로 item을 인덱싱함
- ID identifier (numerical ID) 얘는 semantic 담기 부족+ cold start 문제
- Textual identifiers 얘는 semantic 정보가 hierachically 분포되지는 X + CF signal 부족
- Codebook 기반 얘도 여전히 CF 부족하고 imbalance한 분포
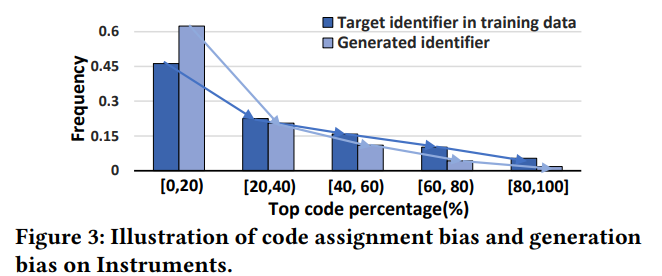
본 논문에서 생각한느 ideal identifier는 다음과 같은 기준을 만족해야함
- hierarchical semantics을 통합시켜야함
- CF signal이 token 배정에 통합시켜야함
- 다양성도 개선해야함.. item generation 공평하도록
ITEM TOKENIZATION
뭐.. 위의 세가지 문제가 있다 정도
METHOD
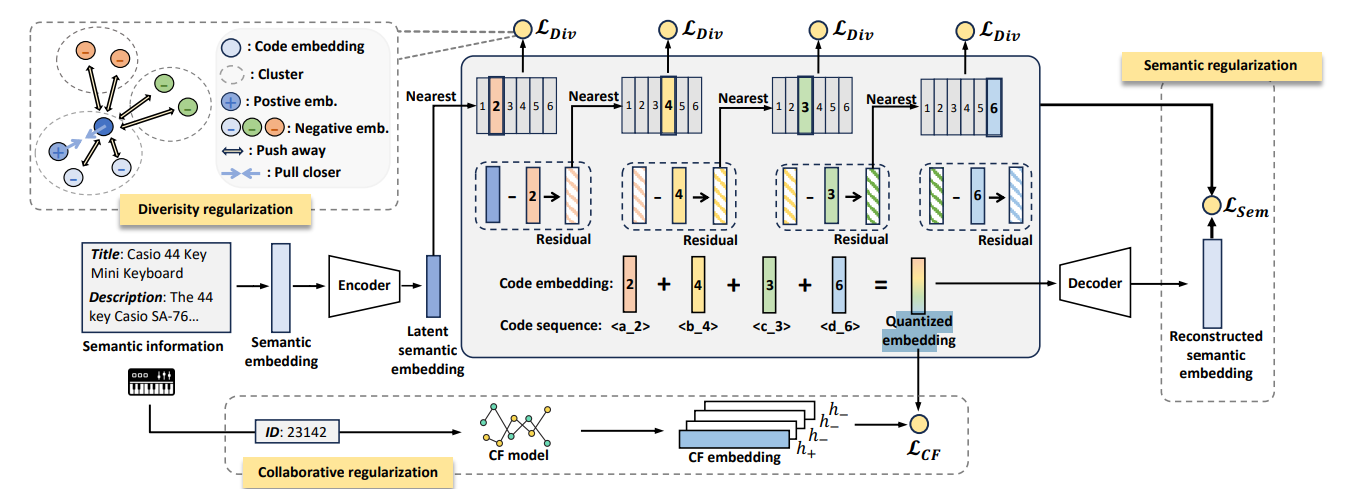
뭔가뭔가.. 되게 다양함
diversity 제약도 주고, CF 랑 loss도 추가해주고,, Reconstruction loss
머 일케 해주면
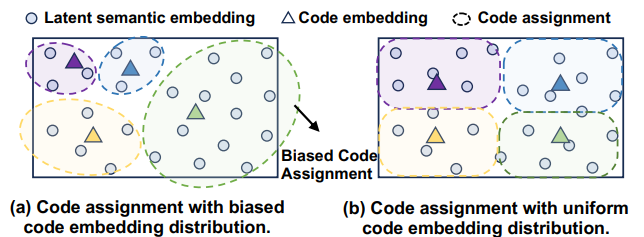
이렇게 된다함,,

Es muss sein!