[NIPS'24]LLM-ESR: Large Language Models Enhancement for Long-tailed Sequential Recommendation
Abstract
기존 추천 모델은 user의 시퀀스 길이가 너무 짧고, item 중 일부만 소비된다는 문제가 있음
따라서 long-tail user와 long-tail item challenge를 야기하게 됨.
기존에 이런 문제를 해결하는 시도들이 있었지만 noisy issue나 seeasw issue가 있음 애초에 내재된 scarcity 때문에
LLM이 이것을 해결해줄 것으로 보임
a retrieval augmented self-distillation method 제안
Introduction
기존의 방식들은 long-tail item들과 popular item사이의 co-occurrence pattern을 감지하였다. true relationship을 제대로 반영하지 않는다면 seesaw 문제를 일으킬 수 있음
최근에는 LLM을 추천에 이용하고자하는 노력들이 있었는데 여기에는 두 가지 문제점이 있다.
1) 비효율적 통합
prompt engineering을 하거나, Token 단에서 추가하는데 이런식으로는 추론 cost가 큰 LLM을 실제 산업 현장에 적용하기 어렵다
2) Semantic 정보의 활용 부족
embedidng layer를 freeze시키지 않고 추천을 위해 fine tuning시키면 본래 item 간의 semantic 정보가 망가질 수가 있다. 또한 item side에서만 사용하고 user information은 쓰지 않는다.
본 논문에서는 LLM을 SRS에 잘 쓰기 위해서(long-tail 문제를 잘 해결하기 위해서)LLM-ESR을 제안하겠다. 첫번째로, item의 semantic embedding들과 user의 semantic embedding을 LLM에서 얻는다. 얘네는 cached되어서 사용할 수 있기 때문에 inference시에는 extra cost가 들지 않음. LLM에게서 얻어진 embedding은 freeze시켜서 semantic 정보 잃지 않도록 ㅏㅎㅁ
그리구 self=distillation으로... similar user간
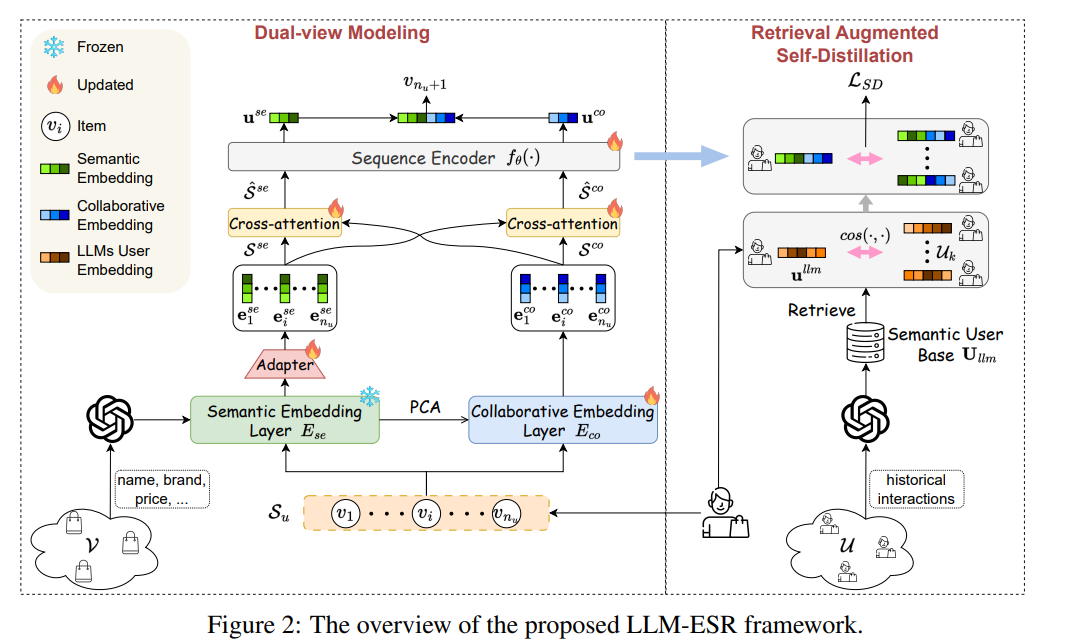
LLM-ESR
3.2 Dual-view Modeling
llama의 last hidden layer state에서 embedding얻은 다음

이런식으로 MLP태우기 (LLM은 Freeze!!)
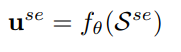
user embedding은 또 이런식으로 SASRec 태움
3.3 Retreicval Augmented Self-Distillation
흥미로운 개념이 Self-distillation이라는 거는 한의 model이 student도 되면서 동시에 teacher도 됨
