[WWW'23]Learning Vector-Quantized Item Representation for Transferable Sequential Recommenders
Abstract
item text와 item representation을 binding하는 것은 too tight하다.
-> text feature를 과장하거나, domain gap의 부정적인 효과를 극대화할 수 있음
이를 위해 VQ-Rec 제안.
얘는 첫번째로 text를 discrete indices vector로 변환한다음.. code embeding table에서 찾아가지고 item representation으로 표현
Introduction
기존의 PLM에서 text 뽑고 Sequential recommender에다가 올리는 UnisRec / ZesRec 같은 방법론들은 "too tight"하다.
1) text랑 sequential recommendation 사이의 semantic gap 존재
2) domain이 다른 text사이의 gap 때문에 performance 하락 가능성
본 논문에서는 discrete item indices를 기반으로 해서 text와 item representation 사이의 strong binding을 완화시키게따
text => representation 바로 안하고 two step으로만들기!
Approach Overview
Transformer 쓸 건데 adapter가 아니라 transferable item representations
for feeding the backbone를 학습시켜버림
1) item text => discrete indices(item code)
2) lookup해가지고 item representation 얻어옴
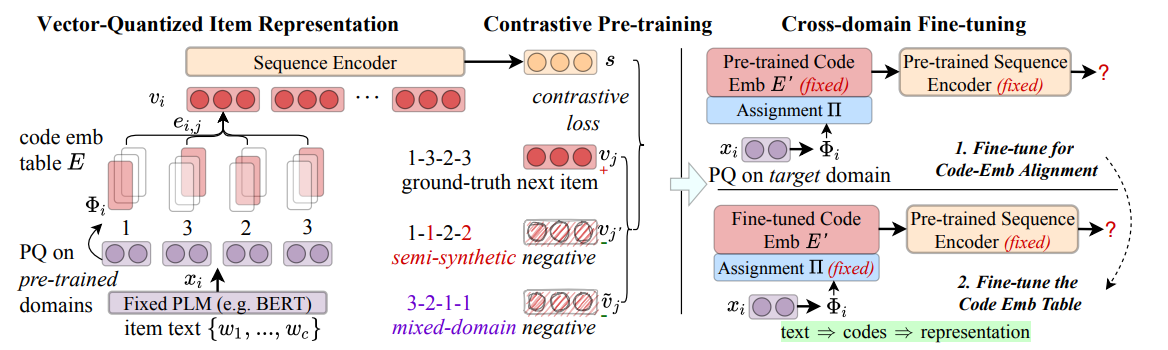
2.2 Vector-Quantized Item Representation
2.2.1 Vector-Quantized Code Learning
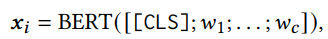
짱오랜만의 BERT.. 얘 써가지고 text encoding 얻음!
이때 D개의 subvector로 나눈다음에
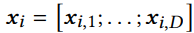
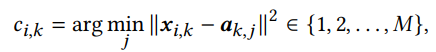
각각 centroid로 나눠서 보내줌 ㅋ ㅋ
이게 말이 돼???
하ㅣ긴 각 부분이 특정 Semantic을 담도록 바꿔줄 수 있을듯?? 근데 의문인점은 PLM을 고정시키는 걸텐데 이렇게 일렬로 쭉 맘대로 잘라버려도 되는 건가 하는 의문..
차라리 여기서도 Filter마냥 추출해서 하면 더 좋지 않았을까??

쨌든 코드 추출하고
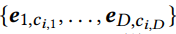
embedding으로 맵핑
이정도면 c바로 써도 되지않나?? 이유는 모르게쌈
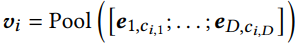
2.2.3 Representation Distinguishability vs. Code Uniformit
당연히 서로 다른 item이 동일한 ocde로 할당되는 걸 방지해야함 이때 collision 가능성을 최소화하기 위해서는 벡터가 균등하게 분포해야함.
2.3 Contrastive Recommender Pre-training
2.3.1 Self-attentive Sequence Encoding
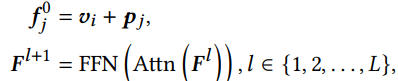
VQ로 얻어진 item representation을 시퀀스로 받아서 sequential encoder에 집어 넣기
2.3.2 Enhanced Contrastive Pre-training
contrastive learning을 위해서 synthetic code를 만들어수 negative sample로 쓸건뎅 fully-synthesized면 너무 동떨어질 수도 있으니까 true item code기반으로 hard negative를 ㅏㅁㄴ들겠다. true item code를 c_i라고 했을 때, 베르누이 확률분포를 따르는 lo에 따라서 바꿔버림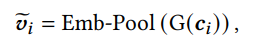
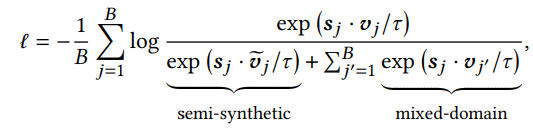
이렇게까지구 꾸역꾸역 contrastive learning 텀을 추가해줘야 성능이 나온다...
2.4 Cross-domain Recommender Fine-tun
