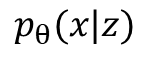
알아야할 개념이 매우 많다..
Variational Inference
MLE
관측지 X가 등장할 확률을 최대화 P(X | theta) 최대화하는 파라미터 찾기
따라서 얘는 딱 관측지에 맞춰서 확률을 추론하기 때문에 만약 관측치에 등장하지 않는 데이터가 있다면 얘가 나올 확률은 0이 되게 됨
(Ex. 주사위가 있고 관측치가 [1, 1, 2]라면 3-6까지는 확률 0을 부여하는 쪽으로 학습이 된다.)
MAP
얘는 데이터의 분포에 대한 추론
P(theta | X) = P(X |theta) *P(theta) / P(X) 로 표현해서 단순히 P(X)가 최대가 되게 하는 theta를 구하는게 아니라 X가 주어졌을 때 theta가 최대가 되게하는 분포를 찾는게 목적
결국엔 classification을 할 때는 P(theta1 | X)랑 P(theta2 | X)중에서 큰 값으로 분류하는 것
(Ex. 일반 동전과 조작된 동전이 있을 때 관측치로부터 일반동전과 조작동전이 나올 확률을 각각 구해서 만약 일반 동전의 확률이 더 높다면 이 관측치는 일반동전에서 온 거겠구나)
Variational Inference란 P(z|x)를 모사하는게 어려워서 q(z)로 근사하는 것을 말한다. (q(z)는 어떠한 쉬운 확률 분포들의 class고 정규 분포랑 비슷하게 평균이나, 표준편차 등의 파라미터를 조정)
VAE에서는 P(z}x)를 정규 분포 따른다고 가정하면 MSE랑 같아져서 그렇게 하지 않고 Variational Inference를 하는 것임,,
1. Introduction
intractable posterior 분포를 따르는 latent variable을 어떻게 학습할까?
본 논문에서는 variational lower bound를 reparameterize해서 미분 가능한 estimator를 만들었다.
2.1 Problem Scenario
𝑝θ (𝑥|𝑧)
결국 하고자하는 것은 어떠한 z가 있을 때 우리가 원하는 x를 만드는게 목적.
하지만 일반적인 AE의 decoder만 가져다가 random variable z를 넣으면 output이 우리가 원하는 이미지가 안나옴. 따라서 z를 만들어내는 encoder도 학습을 하고 decoder도 학습을 하는게 목표
즉 encoder를 제대로 만들려면 p(z | x)의 분포를 제대로 학습해야하고, 이를qφ (z|x)라는 새로운 분포를 만들어서 이와 비슷해지도록 학습
따라서 Encoder의 결과로는 qφ (z|x)의 분포를 추정하기 위한 (정규 분포로 근사함) mu, logvar가 나오고 얘를 학습함
Decoder에서는 들어온 z로부터 x를 복원해야함
