1. Introduction
Youtube 추천 알고리즘이 맞이한 어려움
Scale
: 유튜브 데이터셋 자체가 너무 크기 때문에 기존의 추천 알고리즘을 적용하기 어려움
Freshness
: 매초마다 새롭게 업로드되는 비디오에 추천 시스템일 잘 적용될 수 있어야 함
Noise
: user satisfaction의 ground truth를 얻기란 어려움 그래서 noisy한 implicit feedback signal을 사용해야함
2. SYSTEM OVERVIEW
크게는 두 가지로 구성 candidate generation과 ranking
user간 유사성은 본 비디오의 ID나 search query token 또는 demographics
3 CANDIDATE GENERATION
WSABIE: Scaling Up To Large Vocabulary Image Annotation
low dimension space에서 image representation이랑 annotation학습
이미지 -> D 차원
annotation -> D 차원
으로 맵핑하는 함수 학습
ΦW (i)TΦI (x)얘의 score 높을수록 annotation이 이미지를 잘 설명
여기서 rank 잘나와야하는 애는 결과적으로 rank가 낮아야 함
loss function으로 rank 사용
위 논문의 rank loss 사용했다고 함!
3.1 Recommendation as Classification
corpus V에서 user와 context가 주어졌을 때 video, class를 예측하는 multi classification으로 볼 수 있음
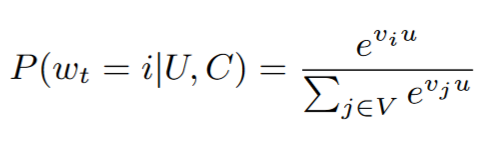
u는 User vector, vi는 candidate video에 대한 벡터
deep neural net의 목적은 context와 history를 잘 반영하는 user vector 학습하기!
본 논문에서는 implicit data 사용 (tail에 대해서도 데이터가 있어서)
hierarchical softmax는 종종 별 상관 없는 케이스에 대한 분류도 실행해서 딱히 이득이 없음
negative sampling을 통해서 softmax 계산을 빠르게함
serving시에는 softmax 계산 값들이 필요하지 않음 그래서 dot product이용한 nearest neighborhood search로 함
아마도 exponential 연산량이 커서 그런듯??
3.3 Heterogeneous Signals
Example Age
machine learning은 과거로부터 학습해서 future를 예측하기 때문에 과거에 편향된 결과를 도출하기도 함 (즉 과거에 올라온 영상을 더 많이 추천함, 하지만 user들은 새로운 영상을 좋아함)
따라서 training 동안에는 Example age를 반영하고, serving시에는 0이나 약간의 음수로 넣음
(아마도 최근 영상에 더 가중치를 준다는 느낌보다는 과거 영상에 가중치가 더해지는 것을 막는 효과인듯??)
3.4 Label and Context Selection
효과적인 영화 추천을 위해 rating을 정확히 예측해야하는 것처럼 추천시스템은 문제를 직접적으로 최적화하기 보다는 이런식으로 surrogate problem를 푼다.
- Training Example은 단순 recommendation 결과에서 watches들만이 아니라 all youtube watches
- 각 사용자별로 동일한 개수의 training example만 생성
- “withhold information from the classifier”
즉, 사용자가 방금 검색한 내용을 바탕으로 추천하지는 않는다
