[WWW'24]Collaborative Large Language Model for Recommender Systems
Abstract
LLM과 ID 패러다임 사이의 gap을 메우기 위한 연구. 본 연궹서는 LLM의 vocab을 확장해서 user/item ID token
Introduction
기존의 RS를 위한 LLM의 adpatation 방식은 1) natural language기반의 prompt로 item sequence표현 2) prompt를 LLM query로 주고, LLM이 추천을 생성
이런 방식의 문제라함은 NLP기반과 ID 기반 추천 사이의 semantic gap이 존재한다는 것. 토크나이즈한다면, user4332가 있다면 ["user", "", "43", "32"] 이렇게 쪼개지게 됨.
Description based method를 사용한다면 inductiva bias가 생기게 됨..
게다가 autoregressive하게 next token 생성하니까 LLM은 낭비기도 하고, hallucianation 피하려면 prompt에 item candiate줘야함
따라서 본 논무네서 제시한는 CLLM4Rec은 첫번째로 ID 패러다임을 LL기반 추천에 적용함. 첫번째로 LLM의 vocab을 user/item ID token으로 확장시킴. 이때 token embedding이 학습되는 two stage는
1)pretraining stage: 추천 corpora에서 language modeling
흥미로운??점은 item reordering을 통해서 item token 순서를 무시하려고 함 (_??)
2) finetuning: item prediction
Related WOorks
그동안 LLM 추천에서는 textual description으로 ID들을 표현하거나, psudo-ID를 사용하기도 했는데 이런 방식은 관련 없는 item 간의 correlation이 생기게 할 수 있음
또는 새로운 token들을 추가해서 item을 묘사했는데, 이런식이면 여전히 bias가 생길 수 있음. 또 candidate 줘야 hallucination막을 수 있기도 하고, auto-regression으로 추천하는 거는 너무 비효율적임
Methodology
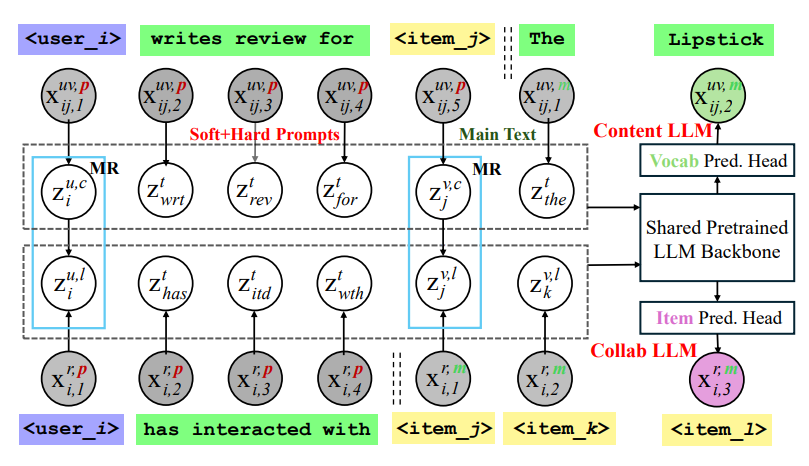

그런데 의문인점은.. 이런 식의 review 를 맞추는게 추천에 도움이 되나??
근데 뭔가... 재미 없음
