M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems
Alibaba에서 쓴 논문이니 읽어보겠당,,
Abstract
open-ended domains and tasks에 적용 가능한 foundation model을 만들고자 한다.
hardware 예산을 맞추기 위해 prompt tuning을 함 ㄷㄷㄷ
Introduction
pretrained foundation model이 있다면 task-specific data에 대해서 따로 학습 시킬 필요가 없음 (근데 이게 되나..)
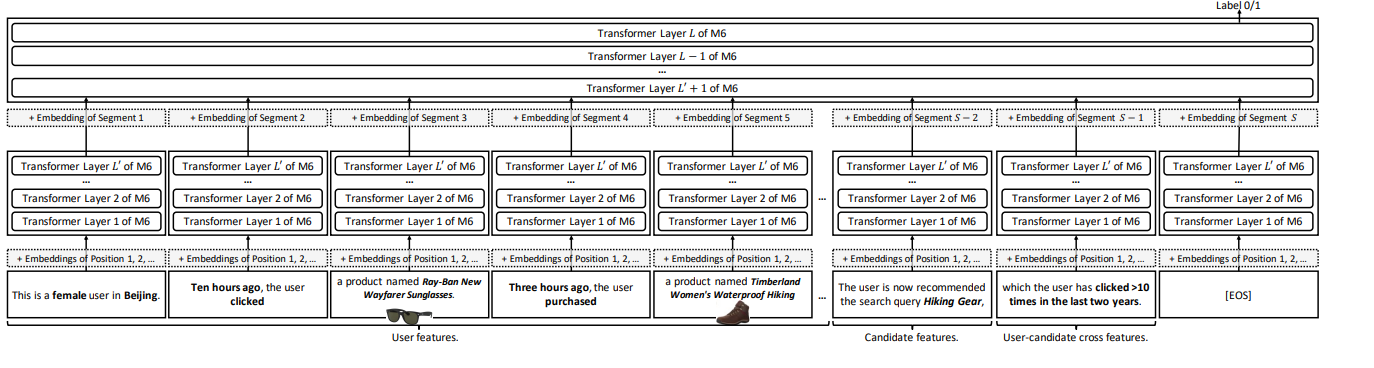
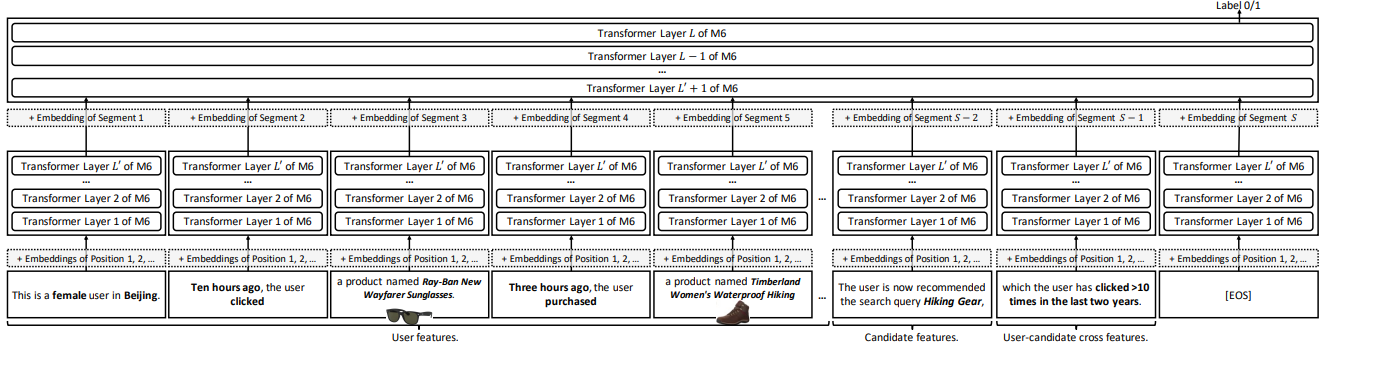
“A male user in Beijing, who clicked product X last night and product Y this
noon, was recommended product Z and did not click it.”
이런 식의 text를 싹 다 모았다고 함...
carbon footprint를 줄이기 위해서 (이 논문은 이게 젤 증요한가 봄)
1) option tuning 제안
prompt tuning의 개선된 방법인데, negligible task-specific parameters을 추가
2) Multi-segment variant of late interaction
Related work
2.1 Pretraining for Recommendation
본 논문의 저자들은 large-scale web corpora에서 얻어지는 knolwedge들이 behavior data를 보완할 수 있다고 생각함.
기존의 방식들은 pretraining을 요구하고 또한 same set of item에 대해서 downstream task를 수행할 수 있음. 본 논문에서는 item ID 대신에 item의 text를 대신 사용하기로 함 -> open-domain recommendation이 가능하도록
또 기존 방식은 점수 매기기만 다루기 때문에 본 논문에서는 text generation을 할 수 있게 함
2.2 Language Models as Foundations
3 METHOD: M6-REC
3.1 M6: An Industrial-Strength Backbone
M6를 backbone으로 썼는데, 이는 중국어와 영어를 모두 지원하고 multi-model model이기 때문임. 그리고 Alibaba그룹 에코시스템에 잘 사용되고 있댕
3.2 Behavior Modeling as Language Modeling
머.. 대충 input text로 다 때려놓고 학습시키겠다.....
