
Model Selection
- 교차검증
- 하이퍼파라미터
1. 교차검증(Cross-validation)
- hold out 교차검증 : 훈련/ 검증/ 테스트 데이터로 나눠서 검증
문제점 : 데이터가 충분하지 않을 경우 부정확한 결과를 초래할 수 있다. - K-Fold 교차 검증
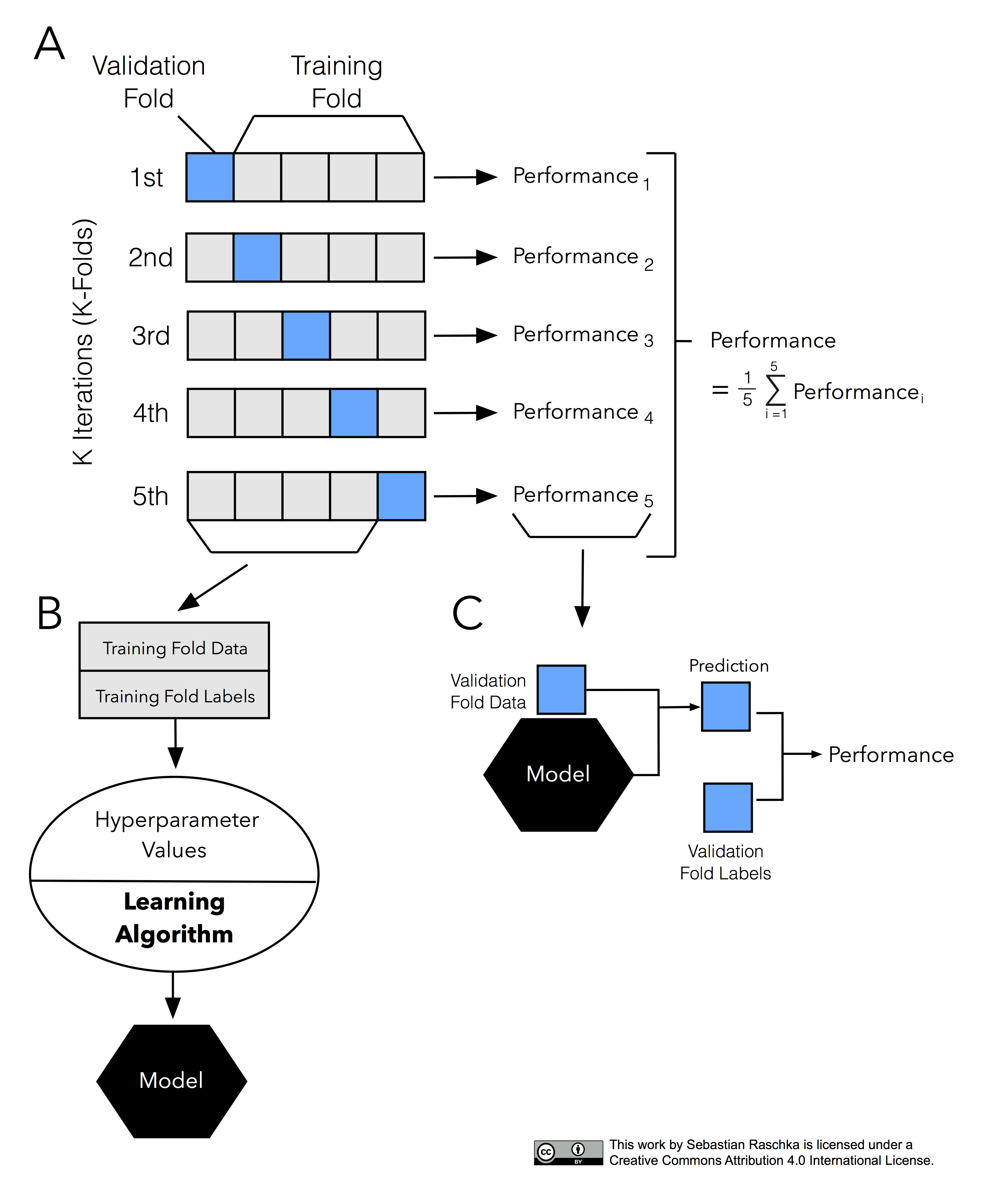
- 데이터를 k개로 k-1개의 훈련데이터와 1개의 테스트데이터로 교차 검증진행
2. 하이퍼파라미터
- 사이킷런을 사용하여 하이퍼파라미터를 최적화 할 수 있습니다.
- Search CV
- Randomized Search CV : 검증하려는 하이퍼파라미터들의 값 범위를 지정해주면 무작위로 값을 지정해 그 조합을 모두 검증합니다.
- GridSearchCV : 검증하고 싶은 하이퍼파라미터들의 수치를 정해주고 그 조합을 모두 검증합니다.
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint, uniform
#하이퍼 파라미터 범위 지정
dists = {
'simpleimputer__strategy': ['mean', 'median'],
'randomforestclassifier__n_estimators': randint(20, 1000),
'randomforestclassifier__max_depth': [20, 30, 50, 100, None],
'randomforestclassifier__class_weight': ['balanced', None],
'randomforestclassifier__max_features': ['auto', 'sqrt', 'log2', None],
'randomforestclassifier__min_samples_leaf' : randint(1, 15)
}
#RandomizedSearchCV
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=50, #시행 횟수
cv=3, #교차검증 횟수
scoring='f1', #f1
verbose=1,
n_jobs=-1
)
#실행
clf.fit(x_train, y_train);
print('최적 하이퍼파라미터: ', clf.best_params_)
print('F1: ', clf.best_score_)
#최적 하이퍼 파라미터로 파이프 만들기
pipe = clf.best_estimator_
3. 회고
이 파트는 하이퍼파라미터 범위조정 때문에 골치아팠다. 범위를 너무 넓게 하면 너무 오래걸리고 너무 좁게 하면 안좋게 나온다. 잘 조절해보면서 나만의 최적의 범위를 찾아야할듯하다.
힘내자!!

미래의 데이터 분석가~@