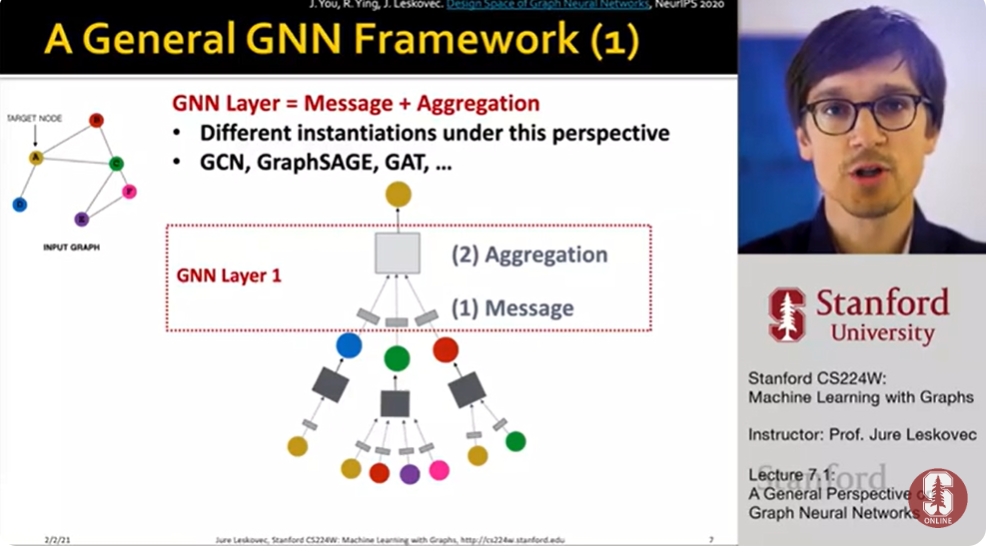


Idea of a GNN Layer
-compress a set of vectors into a single vector
two step process:
1. message
2. Aggregation

1.Message computation
- Intuition: Each node will create a message, which will be sent to other nodes later
- Aggregation
- Intuition: Each node will aggregate the message from the node v's neighbors
GCN


GraphSAGE



GAT





Benefits of Attention Mechanism
Key benefit: Allows for (implicitly) specifying different importance values to different neighbors
Computationally efficient
-computation of attentional coefficients can be parallelized across all eges of the graph
-aggregation may be parallelized across all nodes
Storage Efficient
-Sparse matrix operations do not require more than O(V + E) entries to be stored
-Fixed number of parameters, irrespective of graph size
Localized:
-Only attends over local network neighborhoods
Inductive capability:
-It is ashared edge-wise mechanism
-It does not depend on the global graph structure


Many modern deep learning modules can be incorporated into a GNN layer
-Batch Normalization: stabilize nueral network training
-Dropout: prevent overfitting
-Attention/Gating: Control the mportance of a message
-More: Any other useful deep learning modules




Modern deep learning modules can be included into a GNN layer for better performance
Designing novel GNN layers is still an active research frontier
Reference
Stanford CS224W: Machine Learning with Graphs | 2021 | Lecture 7.2 - A Single Layer of a GNN - Jure leskovec
