Background
많은 Software Company 들은 점점 더 ML을 자사 item에 통합하고 있고, 이에 따라 새로운 데이터 관리 도구의 필요성이 증가하고 있다. 현재 많은 도구들이 ML application의 초기 개발과 배포를 지원하지만, ML 생명주기의 서로 다른 단계나 구성 요소를 목표로 하는 분절된 솔루션들로 이루어진 복잡한 생태계를 구성하고 있다.
이러한 분절성 문제로 인해 production 과 더불어 system 배포 후 발생하는 문제(예기치 못한 출력 값이나 낮은 예측 품질)을 해결하는것이 매우 어렵게 되었다.
내가 리뷰하는 이 논문에서는 기존의 ML 개발도구의 stack을 보완한 end-to-end observability를 제공하는 시스템을 제안하고 있다. prototype과 더불어 MLTRACE라는 독립적인 플랫폼 시스템으로 다음과 같은 기능을 제공한다.
- 구성 요소 실행 시 사전 정의된 테스트 실행 및 ML 특화 메트릭 모니터링
- 전체 파이프라인의 데이터 흐름 추적
- 파이프라인 상태에 대한 post-hoc queries들의 수행
스타트업에서부터 대기업까지 다양한 조직들이 machine learning 기반의 application을 개발하고 배포하는 데 점점 더 많은 자원을 투입하고 있다. 이러한 ML application들은 ETL, 모델학습 등 여러 이질적인 구성 요소들로 이루어진 복잡한 파이프라인을 형성하고 있고, 각 구성요소들 마다 고유한 문제점이 존재한다. 예를들어, 데이터 전처리 문제, covariate shift(공변량 이동), 예측 제공의 어려움, Retraining (주기적 재학습) 등의 문제점이 있다.
현업에서 실무를 뛰는 실무자들의 경우 이러한 문제를 해결하기 위해 여러 도구들을 조합해 사용하는데, 예를들어 Hive Metastore로 자주 변경되는 원시 데이터를 관리하고, Deequ로 데이터 유효성을 검사하며, Weights & Biases로 실험 추적을 수행한다. 하지만 이처럼 분절된 도구들의 조합은 ML 애플리케이션의 sustainability를 위협하고 전체 pipeline 관찰에 어려움을 줄 수 밖에 없다.
특히 ML bug는 pipeline의 어느 구성요소에서든 발생할 수 있고, 그 상호작용에서도 발생할 수 있다. 또, ML pipeline은 단일 모델만 있는 단순한 예측과제라고 해도 매우 복잡할 수 있는데, 배포 이후에도 파이프라인이 지속적으로 변화하며, 같은 작업을 위해 모델이 반복적으로 재학습 및 재배포가 되기 때문이다.
한가지 approach로는 TFX나 overton과 같은 전체 pipeline을 통합하는 framework를 사용하는 것이지만, 전체 애플리케이션을 새로 작성해야 하기때문에 user의 진입 장벽이 높고, 기존 코드와 도구들을 유지하고 싶은 user들에겐 부담스러울 수 밖에 없다.
해당 논문에서는 platform-agnostic하고 기존 도구와 호환되며 전체 ML 애플리케이션의 지속 가능성을 지원하는 시스템인 MLTACE를 제안하는데 이는 기존의 software observability 개념을 ML에 알맞게 확장한 것이라고 말할 수 있다.
Difference between Software observability & ML observability
먼저, software observability란, 제어 이론에서 비롯된 개념이다. runtime에 수집된 telemetry를 활용하여 complex한 software의 동작을 파악하는 것을 의미한다. 하지마, 기존의 software 관측성 도구들은 ML 파이프라인을 제대로 지원 할 수 없는데, 이유는 빈번한 상태의 snapshotting이 필요하고, 이에 따른 새로운 데이터 관리 과제들이 존재하기 때문이다.
일반적인 software 관측성은 log, metric, trace를 통해 metadata를 제공하고 이를통해 시스템 상태를 분석하지만 ML 시스템의 경우, 시스템의 uptime뿐만 아니라 예측 결과의 quality또한 중요한 성능 지표가 된다.
논문에서는 세가지 핵심 요소 (logs, Metrics, traces)를 기반으로 ML 관측성을 확장한다.
1. Logging
전통적 소프트웨어는 오류코드나 stack trace 등 이벤트 기반의 로그를 수집한다. 하지만 ML system은 silent failures covariate shift(공변량 이동), concept drift(개념 드리프트) 등이 발생하며 일반적인 log에 나타나지 않을 수 있다. 따라서 입출력 데이터를 구성 요소별로 기록하고 component간 데이터 흐름을 추적할 수 있어야 한다.
논문에서 제안하는 접근법은 pipeline 내 중간 고성요소들의 입력 및 출력 정보를 모두 포착할 수 있어야 되고, 계산적으로 부담이 크고 대형 DNN model의경우 저장공간도 많이 소모된다.
또한 구성요소들이 서로다른 주기로 실행되므로, 입출력간의 연결관계를 식별하는 기능도 갖추어야 한다. 사용자들의 개입을 최소화한 lightweight manner 방식으로 수행되어야 한다.
예를들어, ETL 단계는 몇 주 전에 실행되고 inference는 실시간으로 실행되어야 한다. 이처럼 각 구성요소의 입력과 출력이 파이프라인 전반에서 어떻게 연결되는지 파악하는 것이 중요하다. 또한 이러한 로그 수집은 사용자 개입을 최소화하면서 경량화된 방식으로 지원되어야 한다.
2. Monitoring
traditional software application에서는 평균 응답 시간과 같은 수치 기반의 metric을 통해 application의 성능을 모니터링하고, 이 값이 미리정한 임계값을 초과할 경우 경고를 발생한다. 이러한 metric은 application 내부에서 쉽게 측정가능하고 집계도 간단하다.
하지만 --> ML application의 성공여부는 model의 performance에 달려있는데, 이는 간단히 측정할 수 없다. 그 이유는, label(정답값)이 production 환경에서는실시간으로 제공되지 않는 경우가 많기 때문이다.
설령, user의 feedback (Ad click 여부)가 있다고 해도 F1score나 t test score과 같은 ML metric은 대규모 환경에서 계산 비용이 매우 높다. 따라서 접근방식은 아래를 만족해야 한다.
- 다양한 ML 중심 metric을 효율적으로 지원
- 사용자 코드 작성을 최소화한 plug-and-play 방식
- pipeline 구성 요소가 반복적으로 실행 될 때, 현장에서 metric 추적
- 사용자가 임계값 alert, trigger, constraint 등을 설정하여 전체 ML pipeline 상태를 보장 가능하도록 지원
3. Querying
ML system을 전체적인 end-to-end perspective에서 debugging하려면, 관측 도구가 수집한 로그와 metric을 query 할 수 있는 기능이 필요하다.
traditional한 system에서는 engineer가 먼저 trace (data point가 system을 거치는 전체 경로)를 추적하여 데이터의 lineage를 이해하고 bug가 어디에서 발생했는지 판단한다. 이러한 trace 추적은 단일 framwork(REST API)에서 변환이 이뤄질 경우 단순할 수 있는데, ML application은 다양한 tool로 구성되어 있는 heterogeous한 stack으로 구축되어 있어, 데이터의 흐름과 출처 정보 접근에 단절되기 쉽다.
해당 논문이 제안하는 시스템의 경우,
- 이절적인 여러 도구들과 통합되면서도 데이터의 계보 추적 가능
- ML bug는 단일 출력이 아니라 특정 집단(slice)에서 발생하므로, 선택된 sub group에 대한 계보 질의(slice-based lineage querying)을 효율적으로 수행
- 금융,법률 등 규제가 엄격한 산업에서는 수개월~수년전의 data에 대한 query가 필요할 수 있기 때문에 이를 위해서는 오랜 기간동안의 meta data 보존이 필요
해당 system의 경우 general software system 처럼 며칠 or 몇 주 단위로 meta data를 유지하는 것과는 차별화된다.
ML Pipeline NEEDS
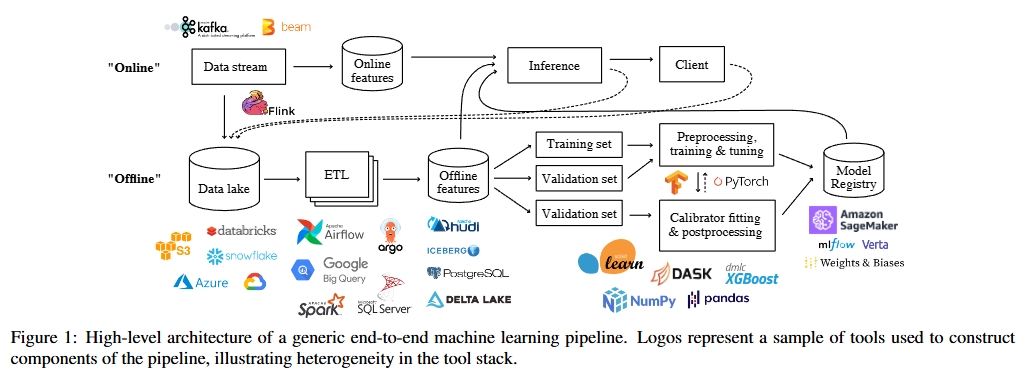
실제 운영 환경에서 사용되는 ML pipeline의 일반적인 특성과, 아직 해결되지 않은 과측성 관련 요구사항에 대해서 설명해 보겠다.
End-to-End ML pipeline의 시작은 가능한 가장 상류(upstream)의 datasource부터 수집되는 data를 의미하는데, 끝은 가장 하류(downstream)의 출력이 된다.
예를들면, 어떤 Ridesharing 회사가 사용자로부터 tip을 받을 가능성을 운전자에게 알려주는 ML Application을 운영한다고 가정해보자,
이경우 pipline의 한쪽 끝은 모바일 앱에서 수집한 telemetry data이고, 다른 한쪽 끝은 운전자에게 보여지는 예측된 팁 확률이다. 작업이 단순해 보일 수 있지만, 이 파이프라인은 여러 구성 요소들로 이루어진 매우 복잡한 구조이다. 여기서의 component라는 개념이 유연하게 적용될 수 있는데, 위 figure 1에 나온 파이프라인의 각 박스는 하나의 구성 요소가 될 수 있다.
Properties of Pipelines
- Pipeline architecture는 dynamic하다.
ML pipeline의 전체 구조는 처음부터 완전히 정의 되어 있지 않다.
실제 운영되는 동안 새로운 구성 요소가 추가되거나 기존 요소가 제거되는 식으로 pipeline이 진화한다.
예를들어, data scientist가 앙상블을 통해 성능을 향상시키기 위해 새로운 model을 pipeline에 추가하는 경우 새로운 전처리, 학습, 추론 구성 요스의 추가로 이어진다. 따라서 logging이 entire pipeline이 아니라 component 단위로 이루어져야 한다.
- component 자체도 dynamic 하다.
pipeline이 변할 수 있을 뿐 아니라 하나의 component 자체도 쉽게 변경 될 수 있는데 World of software에서는 code 변경이 component element 변경을 유발한다.
production code base에 pull request를 보낼 경우 보통 test directory에 별도로 작성된 CI(continuous integration) test가 실행되서 기능을 검증하는데 ML의 경우 code가 아닌 data나 artifect (저장된 함수나 model)의 변화만으로도 component 요소가 변경 될 수 있기 때문에 기존의 software 방식의 CItest는 충분하지 않다.
Deequ나 TFX같은 도구는 component 실행 시점에 데이터 품질 테스트를 작성할 수 있게 해주지만, 이 테스트는 application code 안에 직접 작성되기 때문에 재사용성이 낮다.
User Needs
pipeline을 debugging하기 위해서, 실무자는 component의 다양한 상태에 걸쳐 query를 수행해야 한다.
component 요소의 component state를 다음과 같이 정의하 수 있는데, 입력, 출력, 코드 스니펫, 시작 시간, git hash, 기타 metadata 등 구성 요소 실행 시점에 기로되거나 갱신되는 정보를 의미한다.
일반적인 ML 관측성 관련 query는 complexity 순으로 4가지 유형으로 분류할 수 있다.
- 구성 요소 실행 수준의 질의: 특정 구성 요소 실행에 대한 질의로 입력 값이나 세부적인 실행 실패 원인에 대한 질문이 포함
- 구성요소 history query: 구성 요소의 과거 동작에 대한 질문으로 data drift 가 있었는가? 등
- 교차 구성 요소의 질의: 구성 요소간 상호작용에 대한 질문으로, online or offline pipeline이 일치하지 않는가와 같은 질문이 포함됨
- 교차 구성 요소 history 질의:
과거 파이프라인의 스냅샷, 예를들어 특정 출력 그룹(slice)에 대한 trace를 복원하는질문
이러한 query를 해결하려먼, ML system은 다음을 수행할 수 있어야 한다.
- 구성 component의 history
- 구성 요소간의 상호작용을 계산하고 저장
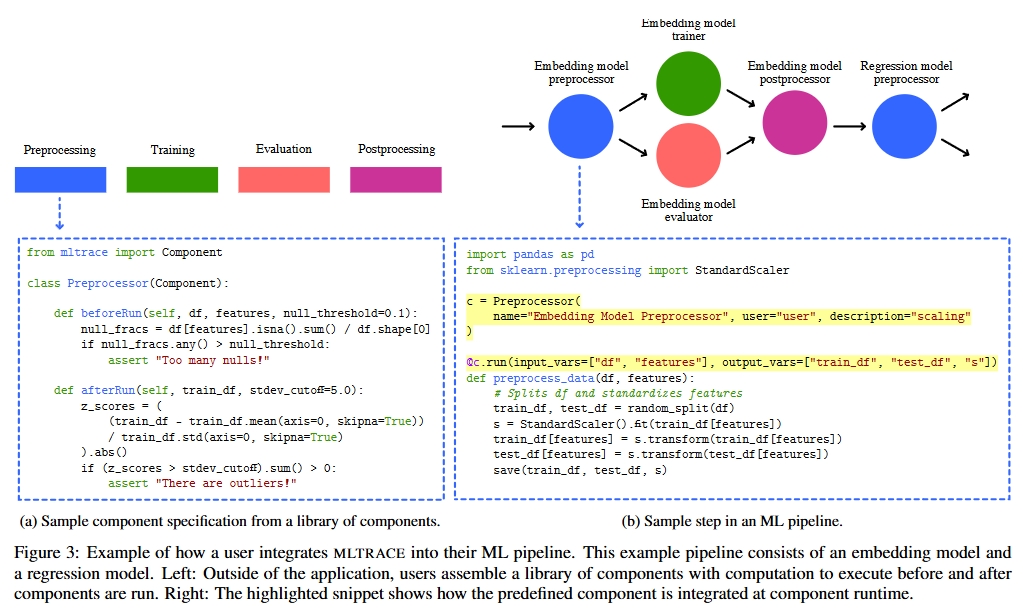
따라서 이 시스템의 경우 component 실행 시점에 state를 기록하고 사용자 정의 trigger를 실행하는 방식을 설계에 채택하였는데 이 후 pipeline 계산 그래프(DAG)를 재구성하여 실무자가 문제를 식별하는데 도움을 준다.

Service Level Agreements, SLAs
software engineering team은 일반적으로 서비스 수준의 계약을 통해 application이 business가치를 제공하도로 보장한다.
예를들면, client가 접근하는 API endpoint에 대해 가동률 99.9%를 보장하는것이 하나의 software SLA가 될 수 있다. 이
System에 대한 자세한 설명을 확인하고 싶다면, 아래 Rerence에 readdocs를 첨부해놓았으니 그걸 확인해보길 바란다. 이 개념을 확장하면, ML SLA의 예시는, 운전자가 팀을 받을 확률을 예측하는 ML Pipeline에서 Recall 90%를 달성하는 것일 수 도 있다. 이러한 비즈니스 핵심 metric(최소 정확도, 클릭률)을 모니터링하는 것은 매우 중요하다고 볼 수 있다.
그러나 실제 산업 현장의 여러 ML 모니터링 솔루션들은 pipeline 중간단계의 분포(feature, 출력)을 지나치게 강조하기 때문에 단편적으로 유의미한 정보가 될수는없다. dubugging에는 도움이 될 수 있다. 예를들어, 사용자가 100개의 feature 중 하나의 평균값이 50% 감소했다는 경고를 받는다고 해도, 그정보만으로 무엇을 해야 되는지 판단하기 어렵다. pipeline 구성요소가 오래되었는지 판단시에는 다라서 중간값보다 오히려 비즈니스 핵심 metric의 하락 여부를 확인하는 것이 훨씬 더 유용하다.
게다가 모든 중간 결과에 대해 경고를 발생시키는 것이 alert fatigue를 유발해 결과적으로 메트릭의 실용성을 떨어뜨릴 수 있다.
이를 해결하기 위해 MLTRACE는 중간집계를 componentrun로그안에 저장하고 경고발생 메트릭은 SLA 또는 기타 비즈니스 핵심 요구사항에 집중한다.
사용자는 구성 요소 정의 시점에서 ML 관련 metric을 미리선언하며 이 metric은 구성 요소가 실행될 때마다 계산되어 SLA가 충족되지 않을 경우에도 경고를 발생한다.

위 그림은 Web UI가 되겠다.
Reference
Towards observability for production machine learning piplines - UC Berkeley (2021)
KGC 2022 기조연설 - Jure lescovec
https://github.com/loglabs/mltrace
https://mltrace.readthedocs.io/en/latest/
