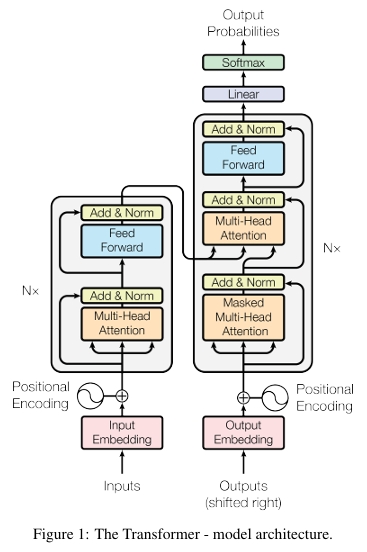
Transformer는 NLP task를 위한 신경망 아키텍처의 구성방식을 완전히 바꾸어 놓았다. 2017년 발표된 획기적인 논문, "attention is all you need"에서 처음 소개되었고, 이후 딥러닝 모델의 표준 아키텍처로 자리잡았다. 이들은 과거의 RNN(순환 신경망)과 그 변형 모델들, GRU(게이트 순환 유닛), LSTM(장단기 기억) 등을 완전히 대체했다. 덕분에 우리는 BERT, GPT, ERNIE 등을 통해 이전보다 훨씬 강력한 성능을 가진 아키텍처들을 사용할 수 있게 되었다. 이들은 더 정확하고 빠르며, 병렬학습 덕분에 학습이 훨씬 용이하고 더 뛰어난 결과물을 만들어낸다. 하지만 한계 또한 존재한다. 바로, 해석 가능성의 저하이다. LSTM 셀은 여전히 텍스트의 순차적인 특성을 모호하게나마 반영했지만, Transformer는 단지 3개의 attention module을 덧입힌 trench coat와 비유 될 수 있다. "attention is all you need"라는 말은 Transformer의 전체 구조를 시각화해보면 그 의미가 명확해 진다. 실제로 신경망 구조라고 할 수 있는 2개의 FFN(Feed-Forward Networks)는 전체 아키텍처에서 극히 일부분만 차지한다.

현재 Transformer는 OpenAI의 GPT, Meta의 Llama, Google의 Gemini와 같은 텍스트 생성 모델에 활용되고 있으며, 텍스트를 넘어 오디오 생성, 이미지 인식, 단백질 구조 예측, 게임 플레이 등 다양한 분야에서 활용되며 versatility(범용성)을 입증하고 있다. 텍스트 생성형 트랜스포머 모델은 다음 단어 예측(next-word prediction) 원리에 기반한다:
사용자로부터 입력된 텍스트 프롬프트를 바탕으로, 그 다음에 올 가장 가능성 높은 단어는 무엇인가?
트랜스포머의 핵심적인 기여는 self-attention mechanism에 있으며, 이를 통해 입력 시퀸스 전체를 동시에 처리하고,
장거리 의존 관계(long range dependency)를 이전 아키텍처보다 훨씬 효과적으로 포착할 수 있다. GPT-2 모델 계열이 대표적인 텍스트 생성형 트랜스포머라고 할 수 있다. 그 중에서 GPT-2 모델은 1억 2400만개의 파라미터를 가지고 있으며 가장 최신이거나 강력한 모델은 아니지만 현재 최첨단 모델들과 핵심 구조와 원리를 공유하고 있기 때문에 기본적인 개념을 이해하기 위해 좋은 예시라고 볼 수 있다.
모든 텍스트 생성형 트랜스포머는 3가지 핵심적인 구성요소로 이루어져 있다.
1. Embedding
- 텍스트 입력은 단어 or sub word 단위의 작은 token들로 나뉘고, 이 token들은 단어의 의미를 수치적으로 표현한 vector인 embedding으로 변환된다.
2. Transformer block
입력 데이터를 처리하고 변형하는 모델의 핵심 연산 단위이다. 각 트랜스포머 블록은 다음의 두가지 구성요소로 이루어져 있다.
- Attention mechanism: 트랜스포머 블록의 핵심 구성요소로, 토큰 간 상호작용을 통해 문맥 정보 및 단어 간 관게를 학습
- MLP (다층 퍼셉트론, Multilayer Perceptron): 각 토큰을 독립적으로 정제하는 feedforward network이다.
어텐션이 토큰간 정보 전달을 담당한다면, MLP는 각 토큰의 표현을 정교화하게 된다.
3. Output probabilities
트랜스포머 블록을 통과한 임베딩은 linear + softmax layer를 통해 다음에 올 토큰에 대한 확률분포로 변환되고, 이를 통해 모델은 다음 단어를 예측하게 된다.

Embedding
예를들어, 트랜스포머 모델에 "Data visualization empowers users to"라는 문장을 입력하면, 이 text는 모델이 이해할 수 있는 형식으로 변환되어야 하고, 바로 이 과정에서 임베딩이 필요하다.
Transformer는 텍스트를 임베딩으로 변환하기 위해 4단계를 거치게된다.
-
Tokenization --> 입력 문장을 단어 or subword token으로 분해
입력 텍스트를 더 작고 관리하기 쉬운 단위인 토큰으로 나누는 과정으로, 이 토큰은 단어일 수 있고, subword 일 수 있다. 모델이 학습되기 전, 전체 토큰 사전 (vocabulary)이 정의되고 GPT-2의 경우 50,257개의 고유토큰을 사전에 포함하고 있다.
입력 텍스트를 토큰으로 분할하고, 각 토큰에 고유한 ID를 부여했다면, 이 ID들을 기반으로 vecter representation(embedding)을 얻을 수 있다. -
Token embedding 추출 --> 각 토큰을 고차원 수치 벡터로 매핑
GPT-2 (small) 모델에서는 각 토큰을 768차원의 벡터로 표현한다. 여기서 이 차원의 수는 모델의 크기에 따라 달라지는데, 이 임베딩 벡터는 (50.257 x 768) 크기의 행렬에 저장되어 있고, 총 약 3900만개의 파라미터를 포함하고 있다. 이 거대한 임베딩 행렬덕분에 모델은 각 토큰에 semantic meaning을 부여할 수 있게 된다. -
positional encoding 추가 --> 순서 정보를 나타내기 위해 각 position에 고유한 encoding 추가
Embedding 층에서는 각 토큰의 의미뿐 아니라 입력 문장에서의 위치 정보도 함께 인코딩하게 된다. 모델마다 위치 인코딩 방식은 다르나, GPT-2는 자체적으로 학습된 위치 인코딩 행렬을 사용하며, 이를 훈련과정에서 직접 통합하여 학습한다. -
token embedding + positional encoding --> 최종 embedding vector 생성
마지막으로 토큰 임베딩과 위치 인코딩을 더해 최종 임베딩 표현을 생성하는데, 이 결합된 벡터는 각 토큰의 semantic와 position정보를 동시에 담고 있어 트랜스포머 모델이 문맥을 더욱 잘 이해하고 예측할 수 있게 한다.
이렇게 트랜스포머는 문자열 형태의 텍스트를 수학적으로 연산가능한 벡터형태로 변환하여 본격적인 처리를 시작한다.
Transformer block
트랜스포머 모델의 핵심은 트랜스포머 블록에 있는데, 이 블록은 다음 두가지 주요 구성요소로 이루어져 있다. Multi head self attention과 MLP (Multi layer perceptron)이다. 대부분의 트랜스포머 기반의 모델은 이 트랜스포머 블록을 여러개 쌓아서 구성한다. 입력 token은 첫번째 block부터 마지막 block까지 순차적으로 처리되며, 각 layer를 거치면서 표현이 점차 정교해지고 의미가 풍부해진다. 이러한 계층적 구조 덕분에 모델은 token의 고차원적 의미와 맥락을 효과적으로 파악할 수 있다. 계속 살펴본 예로 GPT-2 (small) 모델은 총 12개의 트랜스포머 블록으로 구성되어 있다.
1. Multi head self attention
self attention mechanism은 모델이 입력 문장에서 어떤 단어가 중요한지 스스로 판단하여 집중할 수 있도록 한다. 이를 통해 문장 안에서의 의미적 관계나 문법적 의존성을 잘 포착할 수 있게 된다. 멀티헤드 어텐션은 이 메커니즘을 여러개의 주의 집중 head로 동시해 수행하여 여러시점에서 다양한 의미관계를 동시에 파악가능하고, 각 head가 서로 다른 정보를 포착하여 더 풍부한 표현을 생성할 수 있게 된다.
- Query, Key, and Value Matrices

각 토큰의 임베딩 벡터는 3개의 벡터로 변환된다. Q(Query), K(Key), V(Value) 이들은 학습된 Q, K, V 가중치 행렬과 입력 임베딩을 곱하고 편향을 더해 얻는다.
Web search에 쉽게 비유해보자면, Query는 검색창에 입력하는 검색어 (지금 알고싶은 단어)가 되고, Key는 검색 결과의 제목 (어떤 단어들이 참고가능한지 나타냄)이 되고, Value는 검색결과의 실제 컨텐츠로 (관련있는 페이지에서 보고싶은 정보)가 된다. 모델은 이 Q, K ,V 값을 통해 attention score를 계산하고 예측할때 어떤 token에 '집중'할지를 결정하게 된다.
Scaled Dot-Product Attention

스케일 조정 내적 어텐션의 계산 방식은 아래와 같다. 퀴리와 모든 key간의 dot product(내적)을 계산하고 그 값을 나누어 스케일링한 뒤, softmax 함수를 적용해 각 값에 대한 가중치를 얻는다. 실제로, 여러개의 쿼리를 한번에 처리하기 위해 쿼리를 행렬 Q, 키를 K, 값을 V로 행렬로 묶어서 처리한다. 이렇게 하면 출력행렬이 위 공식과 같게 된다.
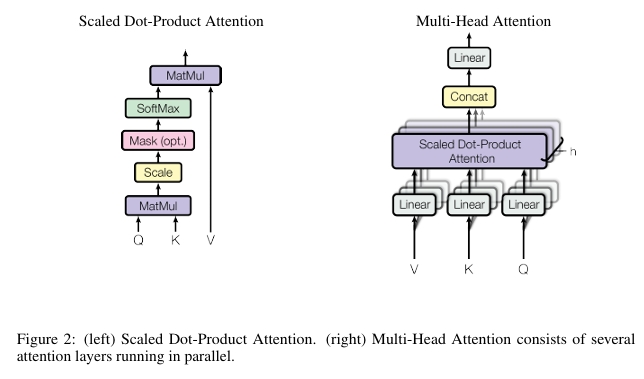
-
Multi head splitting
Query, Key, Value 벡터는 각가 여러개의 head로 분할되는데, GPT-2 (small)의 경우 12개로 나뉜다. 각 head는 입력의 다른 부분을 독립적으로 처리하여, 다양한 의미/문법적 관계를 포착한다. 이러한 구조 덕분에 모델은 병렬적으로 다양한 언어적 특성을 학습할 수 있고, 표현력도 더 강력해진다. -
Masked self-attention
각 head에서 masked self-attention을 수행하게 되는데, 이 과정은 모델이 미래 토큰을 보지 않고 앞부분 정보만을 참고해 다음 토큰을 예측할 수 있도록 돕는다.
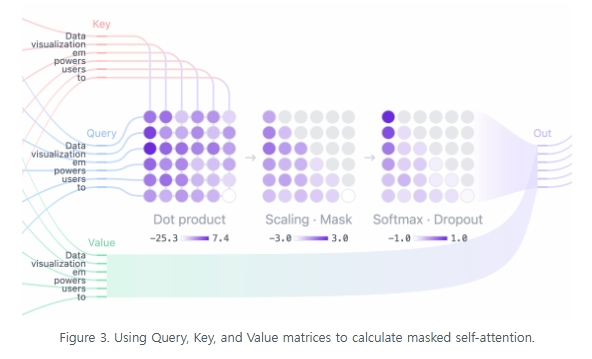
- attention 점수 계산: query와 key의 내적(dot product)를 계산해 각 토큰이 다른 토큰과 얼마나 관련이 있는지 수치화한 정사각 행렬을 만든다.
- masking: 이 행렬의 오른쪽 위 삼각형 부분(future token)은 -∞ 로 설정하여 미래 정보 접근을 차단한다.
- Softmax: masking된 attention score는 softmax 함수를 통해 확률분포로 변환되며 각 행의 합은 1이 된다.
이렇게 계산된 attention 가중치는 각 토큰이 왼쪽에 있는 다른 토큰에 얼마나 집중해야할지를 나타내게 된다.
- Output & Concatenation
각 헤드에서 나온 attention결과를 value 행렬과 곱해 최종 출력을 계산하는데 앞에서 예를 든, GPT-2의 경우 12개의 헤드를 사용하며, 각 헤드는 다른 의미/구조적 관계를 포착하게 된다. 마지막으로 모든 헤드의 출력을 연결(concatenate)한뒤 linear projection을 적용하여 다음 layer로 전달한다.
2. MLP: Multi-Layer Perceptron
multi layer self attention이 입력 토큰들 간의 다양한 관계를 포착한 후, 이 연결된 출력은 MLP층으로 전달되어 모델의 표현 능력(representational capacity)를 강화하게 된다.
MLP block은 두개의 linear transformation과 그 사이에 위치한 GELU 활성화 함수로 구성되는데, 첫번째 선형 변환은 입력의 차원을 768 --> 3072로 (4배 증가)시킨다. 두번째 선형 변형은 차원을 다시 3072 --> 768 (원래 크기로 복원)하여, 다음 층에서도 일관된 차원의 입력을 받을 수 있도록 한다.

self-attention과는 달리, MLP는 각 토큰을 독립적으로 처리하며, 단순히 토큰 표현을 하나의 벡터 공간에서 다른 벡터공간으로 변환한다.
Output Probabilities
입력이 모든 트랜스포머 블록을 거쳐 처리된 후, 최종 출력은 마지막 linear layer를 통해 token 예측을 위한 형태로 변환된다.
이 계층은 최종 표현을 50,257차원의 공간으로 사상하는데, 이 숫자는 GPT-2의 전체 어휘 집합(vocabulary) 크기이며, 각 토큰마다 logit이라는 값이 할당되게 된다. 모든 토큰은 다음 단어가 될 수 있기 때문에, 이 과정은 각 토큰이 다음에 등장할 가능성에 따라 순위를 매길 수 있는 기반을 제공한다. 그 다음 이 logit 값에 softmax함수를 적용하여 총합이 1이되는 확률분포로 변환한다. 이렇게 변환된 확률 분포를 바탕으로, 우리는 각 토큰이 다음에 등장할 확률에 따라 샘플링하여 실제 다음 단어를 생성할 수 있다.
2024년 존스홉킨스 연구팀이 개발한 'Transformer Explainer'를 활용하면 구조를 굉장히 쉽게 파악할 수 있다.

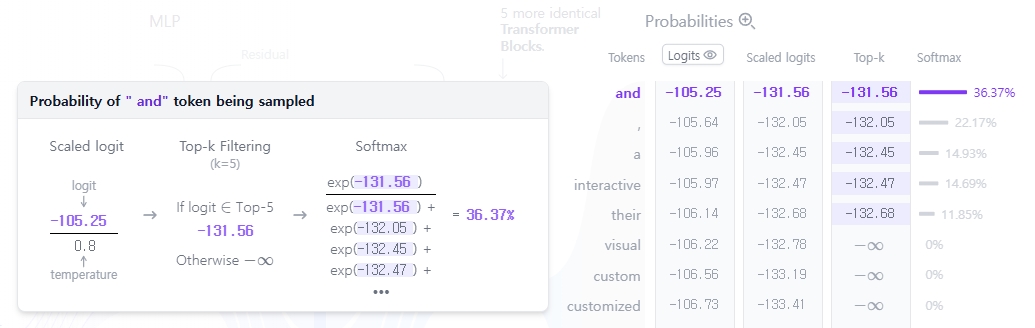
모델의 출력 확률 분포로부터 다음 토큰을 sampling 하여 생성하는 것이 마지막 단계이다. 이때, temperature 하이퍼파라미터가 중요한 역할을 한다. 수학적으로는 아주 간단한 연산인데, 모델의 출력 logits 값을 temperature 값으로 나눈 후 softmax를 적용하는 방식이다.
- temperature = 1: logit을 1로 나누게 되면 softmax 결과에 영향을 주지 않는다
- temperature < 1: 값이 작을수록, 확률분포가 날카로워지고 모델은 더 결정론적이되며 예측 가능한 출력을 생성한다.
- temperature > 1: 값이 클수록, 확률분포가 평탄해지고 무작위성이 커지며 창의적인 출력이 나타날 수 있다.
sampling 기법으로는 top-k와 top-p가 있는데
- top-k samlpling은 확률이 가장 높은 상위 k개의 토큰만 후보로 제한하고 그 외는 제거하는 방식이다.
낮은 확률의 토큰 제거로 안정성을 향상할 수 있다. - top-p nucleus sampling은 누적 확률이 p 이상되는 최소 토큰 집합만을 고려하는데, 확률이 너무 낮은 토큰은 제외하면서도 다양성을 유지할 수 있게 된다.
Adavanced Architectural Features
Transformer model의 성능을 향상시키는 다양한 고급 구조적 기능들이 있다. 아래 내용들은 모델의 학습과 일반화에는 매우 중요하지만, 아케텍처의 핵심 개념을 이해하는데 필수는 아니다. 대표적인 구성요소로, layer normaliazation, dropout, residual conntections(잔차 연결)이 있다.
1. Layer Normalization
각 층의 출력값을 평균과 분산기준으로 정규화하여, 값의 sclae 차이를 줄이고 학습이 더 잘 되도록 돕는다. 내부의 공변량 변화 문제(internal covariate shift)를 완화하여, 초기 가중치에 대한 민감도를 줄인다. Transformer block 안에서 두번 적용되는데, self-attention 앞과 MLP layer 앞에서 적용된다. 이를 통해 모델의 학습과정을 안정화하고 수렴 속도를 높일 수 있게 된다.
2. Dropout
학습 중 일부 뉴련의 출력을 무작위로 0으로 설정해, 특정 뉴런에 대한 의존을 줄이는 방법이다. overfitting을 방지하는 정규화 기법으로, 더 강건하거 일반화된 특성을 학습하도록 돕는다. 하지만 추론 시에는 적용되지 않아, 여러 sub model의 ensemble처럼 동작하여 성능이 향상된다.
3. Residual Conntections
2015년 ResNet에서 처음 제안된 혁신적인 구조로, 입력을 출력에 직접 더해주는 우회경로를 생성하여 vanishing gradient(기울기 소실 문제)를 완화하게 된다. 더 깊은 네트워크로도 학습이 가능해지고, 이전 층까지 gradient가 원활히 흐른다. 마찬가지로 GPT-2를 포함한 Transformer block에서 2번 적용되는데, self attention 이후, MLP이후가 된다.
이 3가지 구성요소들은 Transformer의 성능 향상에 핵심적이 기초 기술로 작용하고, 특히 학습과정에서 큰 차이를 만들어내게 된다.
마지막으로 첨부하는 이 그림은 트랜스포머 구조의 세부적인 부분까지 한 그림에 모두 담고있어 전체적인 숲과 나무를 동시에 보고 이해하는데 매우 도움이 된다.
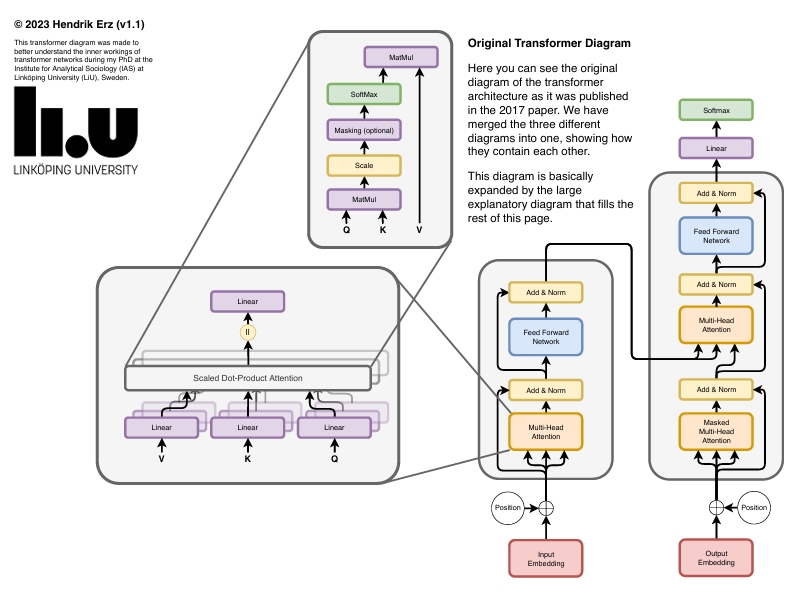
Reference
Transformer Explainer github.io
Transformer Explainer: Interactive Learning of Text-Generative Models (2024) https://arxiv.org/abs/2408.04619
https://cme295.stanford.edu/ - Stanford online lectures
VIP Cheatsheet: Transformers & Large Language Models - AfshineAmidi, ShervineAmidi (2025)
GENAI starter pack -RESHMAWITHAII (linkedin)
Natural language processing with python cheat Sheet (nltk)
Vaswani et al, (2017) Attention Is All You Need. http://arxiv.org/abs/1706.03762
Doshi (2021a) Transformers Explained Visually — Not Just How, but Why They Work So Well. Towards Data Science.
Jay Alammar (2018) The Illustrated Transformer. https://jalammar.github.io/illustrated-transformer/
https://superstudy.guide.
The Transformer Architecture: Institute for Analytical Sociology (IAS) at Linköping University (LiU), Sweden. 2023 Hendrik Erz
