
업스테이지 콘솔에서는 자체 개발한 production model들을 직접 경험할 수 있다. 복잡한 문서작업, Q&A service, 핵심 information extract 등의 작업에 LLM을 활용해보고 싶은 경우 여기서 실험해 볼 수 있다. 왼쪽 상단 메뉴중 "Models"를 클릭하면 아래와 같이 여러 AI model들을 확인해 볼 수 있다.

더불어 "compare" 기능이 있어 모델들을 직접 사용해보고 서로 비교분석이 가능하다. "Playground"에는 모델과 함께 이를 직접 테스트 해볼 수 있게끔 예시 자료들을 제공한다. Document Parse의 경우, Json, HTML 형식 모두 제공한다. 상세 내용을 아래 해당 부분들을 자세히 읽어보면 된다.
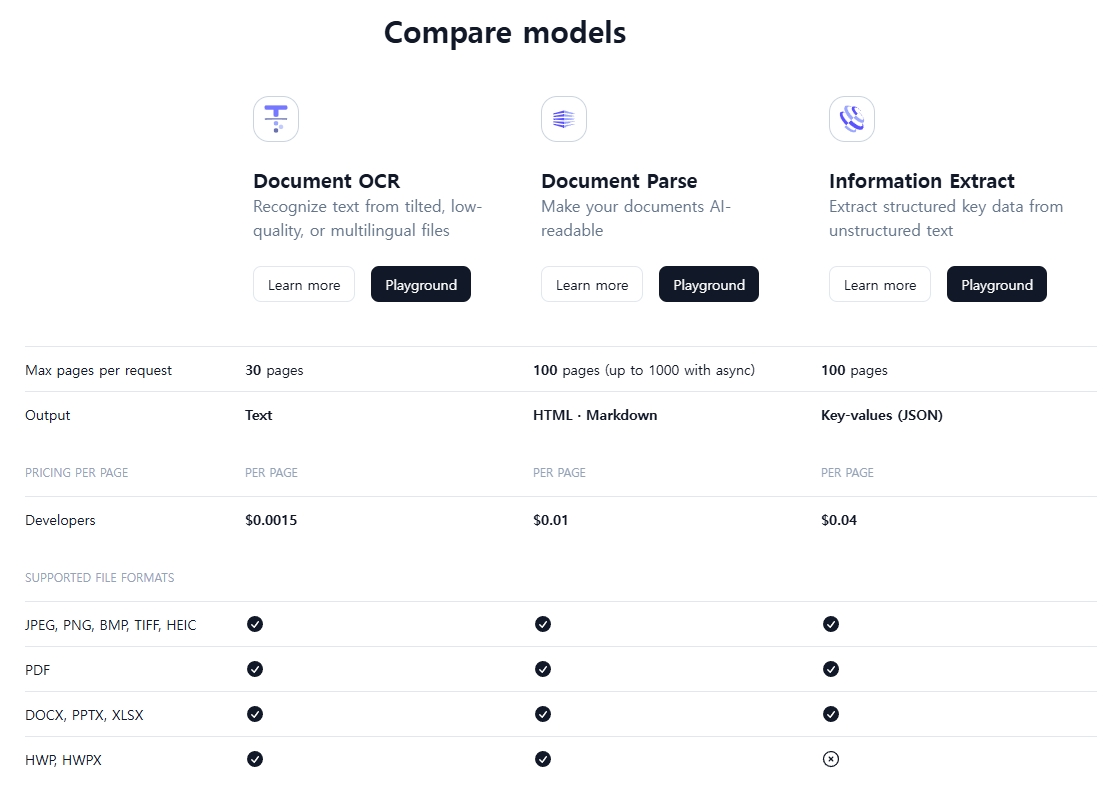
나는 이들 중 Information Extract model을 사용해 보았다. 아래 화면은 내가 읽고 있는 논문을 직접 업로드해본 모습이다.
Set schema 하단에 Auto-generate 버튼을 누르게 되면, 내가 업로드한 문서에 대한 내용들을 손쉽게 잘 정리해 준다. 이 중 에서 Type은 String, Integer, Boolean, Number로 구성되어 있다.


하단의 "Confirm and extract" 버튼을 누르면 다음과 같은 화면이 출력되는데, 나의 경우 다음과 같이 extraction result가 나왔다. 
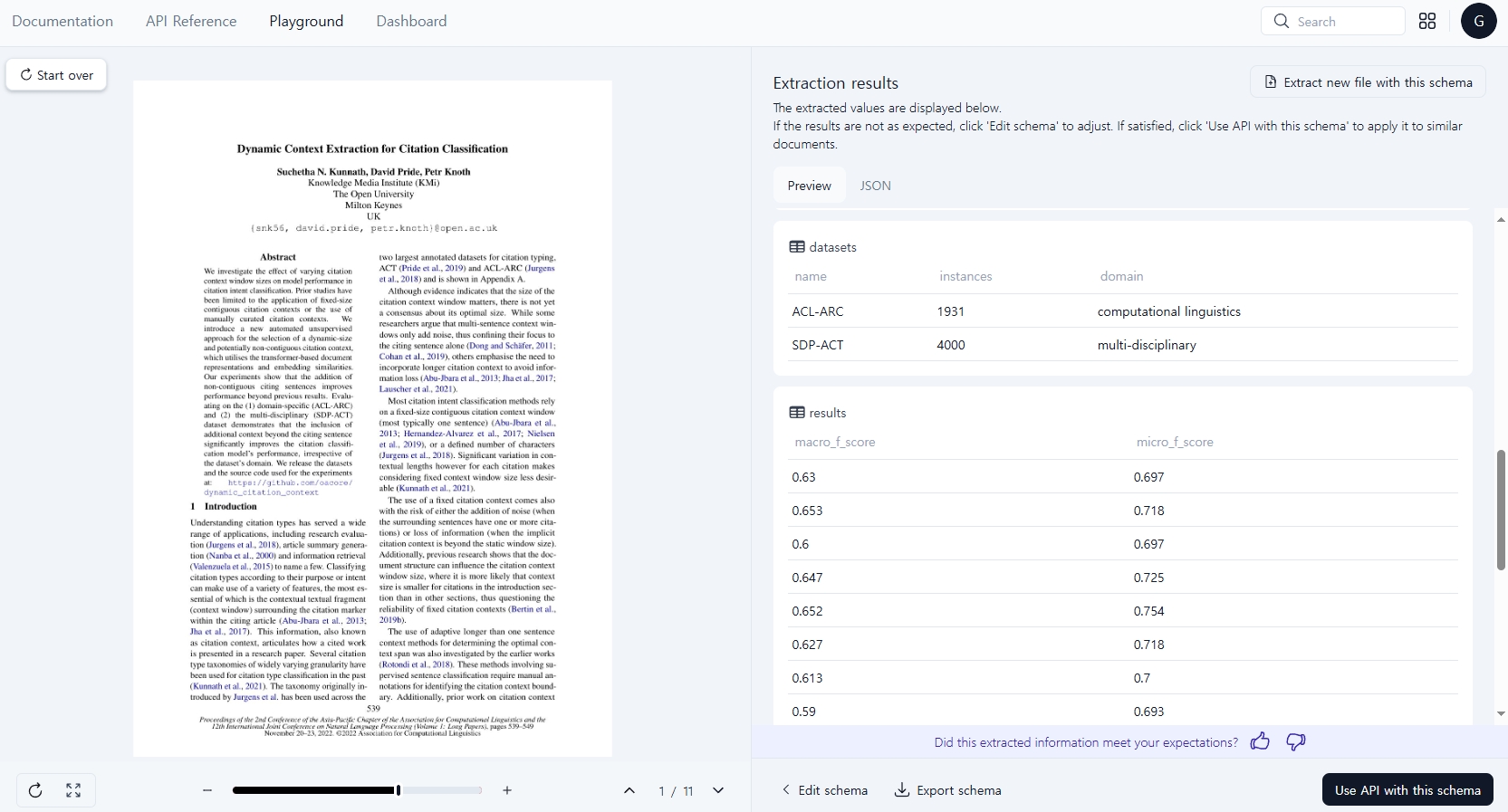

해당 부분이 어디에서 추출된 내용인지 궁금하다면, 클릭하여 해당 위치를 파악할 수 있다. 추가적으로 Json 형식으로도 데이터를 확인해 볼 수 있기 때문에 내가 어떤 작업을 하느냐에 따라서 취사선택이 가능하다. 추가적으로 이 단계까지 마무리 되었다면, 다시 오른쪽 하단에 "Use API with this schema" 버튼을 통해 Upstage API를 사용할 수 있다. Python외에도, cURL, JavaScript를 활용할 수 있다. 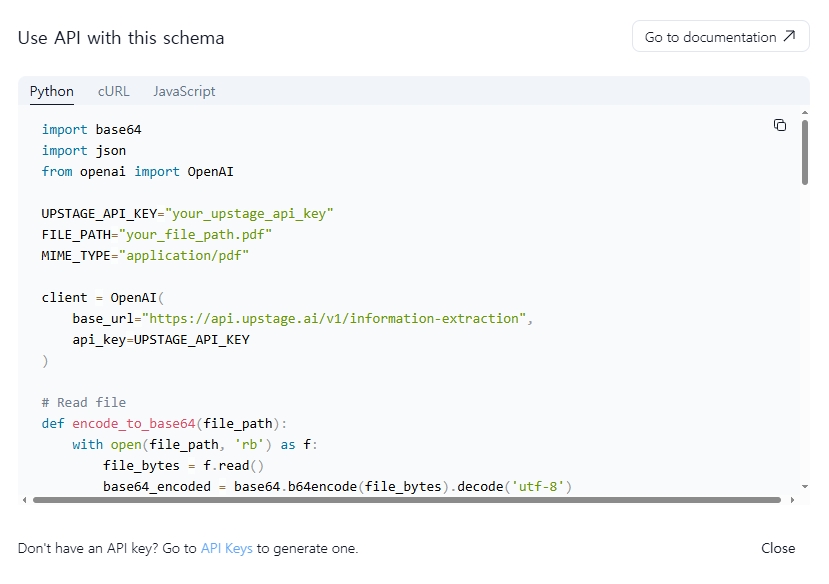
Information extract model 말고도, Document parsing 모델을 사용해 볼 수도 있다. 아래 화면을 보면, Business, General, Government, Foreign languages 들의 보고서들을 Parsing 작업을 토해 HTML, JSON 형식으로 추출 한 것을 확인해 볼 수 있다.
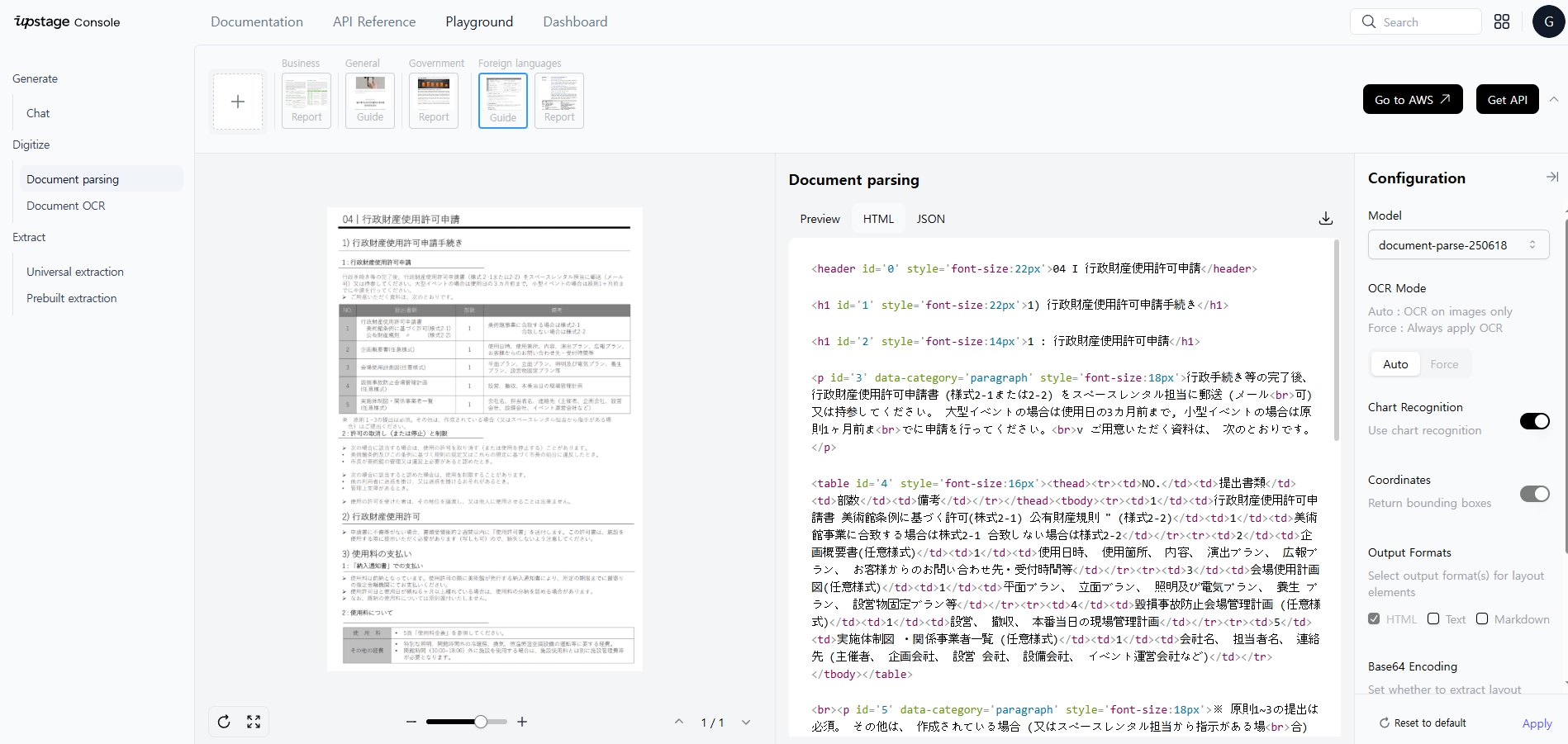
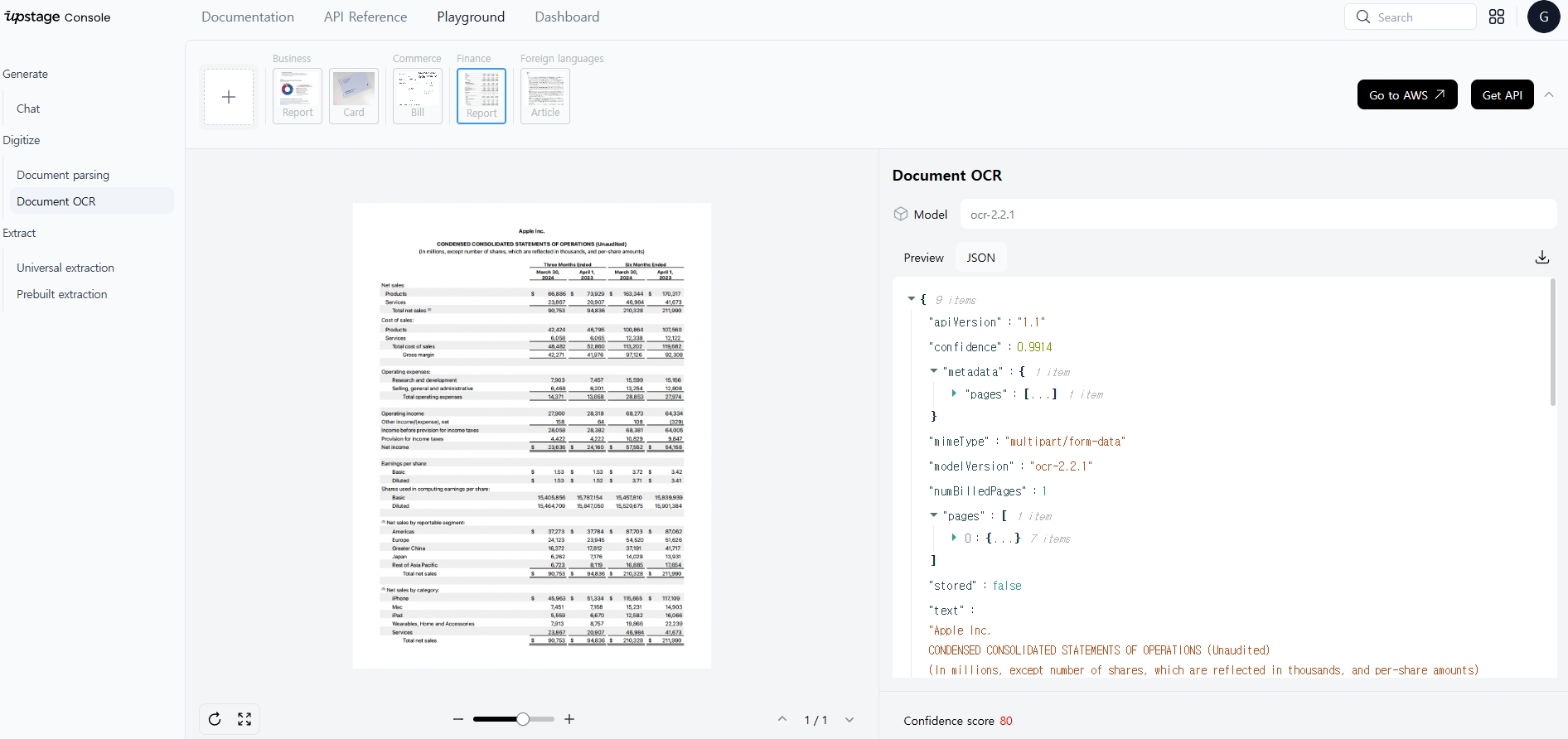
아래 화면은 Document OCR을 활용해본 예시로, 위와 유사하게 Business, Commerce, Finance, Foreign languages 다양한 도메인 영역에 해당 기술을 적용하여 내가 원하는 형태의 데이터를 추출 가능하다.
사용법이 궁금하거나, 이 모델이 어떤 서비스를 제공하는지, 작동원리가 어떻게 되는지, API는 어떻게 사용해야 하는지가 궁금하다면, Upstage console에서는 각 해당 모델마다 Documentation과 API Reference를 제공하므로, 해당문서를 확인하면 상세한 설명을 확인해 볼 수 있다. 하단 Reference에 참고링크를 참조해 두겠다.
Upstage에서 개발한 Document intelligence 기술이 어떤식으로 사회의 다양한 영역에 적용되고 활용될 수 있는지 궁금하다면, 업스테이지 콘솔을 적극적으로 활용해 보길 권한다.
Reference
console.upstage.ai
Document OCR API Reference
Document OCR Documentation
Upstage - hompage
