
RAG?
RAG (Retrieval-Augmented Generation): NLP에서 사용되는 기법으로 Retrieval과 generative model을 결합하여 더 정확하고, 관련성이 높으며, 문맥을 이해한 응답을 생성하는 방법
기존의 언어 생성 작업에서는 Meta의 LLaMMA model이나, IBM의 Granite model과 같은 LLM이 입력된 프롬프트를 기반으로 응답을 생성
이러한 대형 LLM 모델은 주로 chatbot등에 사용
하지만, Knowlege base에 최신정보가 없는 경우에 RAG 가 매우 유용한 도구가 될 수 있다.
AI Agent?
Agentic RAG system의 핵심은 AI agent로 사용자를 대신하거나 다른 시스템을 대신에 스스로 작업을 수행하고, 작업흐름(workflow)를 설계하며, 도구를 활용할 수 있는 자율적인 시스템을 의미한다.
Agentic 기술은 다양한 데이터 소스에서 최신 정보를 수집하고 작업흐름을 최적화하며 복잡한 문제해결을 위한 하위 작업(subtask)를 스스로 생성하는 방식으로 작동
Agent가 사용하는 외부 도구 list
- 외부 데이터셋
- 검색 엔진
- API
- 다른 AI agent 등
Traditional RAG의 경우 vector database에서 문서를 검색해 LLM에 제공하는데 문서검색을 전담하며 제한적이고 단일 에이전트이지만, Agentic RAG의 경우 다양한 도구 사용이 가능하다.
(검색, 계산, 분석, 이메일 작성 등) 다양한 데이터에 접근이 가능하고 검색과 분석 의사결정 보조 등 여러 역할들과 작업들을 수행할 수 있다. 자율적인 계획과 툴 선택이 가능하며 다중 에이전트와의 협업이 가능하여 성능향상이 가능하다.
Agent의 경우 multi-step reasoning을 통해 상황에 따라 적절한 도구를 스스로 선택하기 때문에 다중 에이전트 시스템에서는 에이전트들이 협업하여 단일 에이전트보다 뛰어난 성능을 보일 수 있다.
--> 이러한 scalability(확장성)과 adaptability(적응성)이 traditional RAG에 비해 Agentic RAG의 장점이라고 말할 수 있다.
What is Graph RAG?
- RAG의 고급 버전으로 KG와 같은 graph 구조의 데이터를 통합하여 사용하는 기술
기존의 RAG system은 vector search를 통해 의미적으로 유사한 텍스트를 검색하는 반면, GraphRAG는 도메인 특화 쿼리에 따라 그래프의 관계 구조를 활용하여 정보를 검색하고 처리함.
GraphRAG는 2024년 Microsoft Research에 의해 도입되었으며, LLM의 한계를 극복하기 위해 탄생하였다,.
기존 LLM은 특히 비공개 데이터나 구조화된 데이터에 대한 복잡한 추론 작업에서 어려움을 겪는데, 이러한 이유가 생기는 것은 LLM이 entity간의 관계를 이해할 수 있는 능력이 부족하기 때문이다.
GraphRAG의 경우 graph database를 활용하여 이러한 관계를 modeling함으로써, 복잡한 질의 처리, 문맥적 정보 검색, 생성형 AI의 정확도 향상이 가능해진다.
RAG 작동방식
- vector database, 외부 지식 소스, 내부 지식 베이스로부터 유사도 기반의 관련 정보를 검색한다.
- 이후, 해당 정보를 LLM과 결합하여 문맥을 고려한 응답을 생성한다.
하지만 기존 RAG의 limitations는 아래와 같다.
- 데이터간의 복잡한 관계를 이해하지 못함
- 멀티홉 추론(multi-hop reasoning)이 어려움 --> 여러 소스의 정보를 논리적으로 연결하거나 간접 추론이 어려움
- 계층적 정보나 관계 기반의 문맥 처리 부족
예를 들어, "누가 상대성 이론을 발명 하였는가?" 에대한 질문은 Entity 간의 관계에 대한 이해와 추론이 필요하기 때문에 기존의 RAG로는 어려울 수 있다.
Graph RAG는 어떻게 이를 개선하는가?
Graph RAG는 말그대로 graph structured dat를 도입함으로써 이러한 한계를 극복한다.
graph는 다음과 같은 구성으로 정보를 표현한다.
1. nodes: 사람, 장소, 개념, 엔티티 등
2. edges: node 간의 관계
3. labels: node나 edge를 정의하는 attribute
예를들어, "알버트 아이슈타인 - 발명 - 상대성 이론" 이 정보를 graph structure로 표현하면, node: 알버트 아인슈타인, 상대성 이론 edge: 발명

이처럼 graphRAG는 정보를 network 형태로 구성하고 관계를 기반으로 정보를 검색하고 처리함으로써 보다 정확하고 복잡한 질의에 대한 응답 생성이 가능하다.
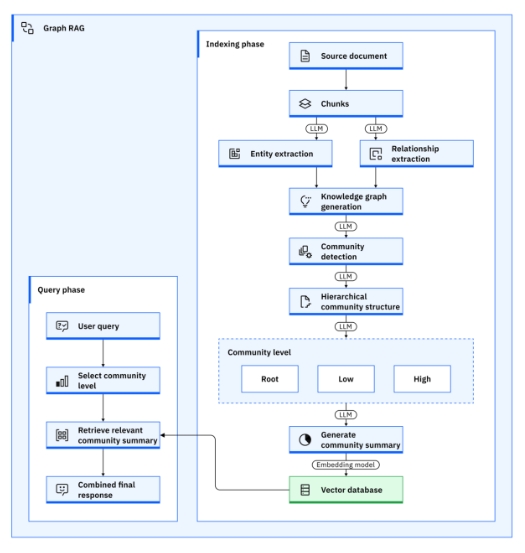


--> Transforming data into knowledge graph creates a network of connected and linked entities, and the linked multilayed knowledge graph then supports a wide range of applications and generating targeted questions to craftin rich and contextually relevant summairies ultimately providing a depth of insights that traditional RAG cannot achieve alone
Benefit of using graph RAG
Develop: maintainance
Production: Higeher accuracy / complete
Governance: Explainability

Components of GraphRAG
graphRAG는 4지의 주요 구성 요소로 되어 있다.
- Query Processor
- Retriever
- Organizer
- Generator
-
쿼리 프로세서
사용자의 질문을 전처리하여, 그래프 구조에서 관련 있는 주요 엔티티(개체)와 관계를 식별
NER( Named-Entity Recognition) 개체명 인식
Relational Extraction (관계추출)
Cypher 같은 그래프 질의 언어를 통해 지식 그래프에서 도메일 특화 데이터를 조회 -
검색기
전처리된 질의를 바탕으로 외부 그래프 데이터 소스에서 관련 정보를 탐색하고 추출
- 기존 RAG는 텍스트나 이미지의 vector embedding기반 검색에 의존하지만, GraphRAG는 그래프 구조를 활용하여 의미적 + 구조적 신호를 함께 사용 (leveraging both semantic and structural signals)
사용 기술:
그래프 탐색 알고리즘: BFS(너비 우선 탐색), DFS(깊이 우선 탐색)
GNN(그래프 신경망): 그래프 구조를 학습하여 정보검색
Adaptive Retrieval: 탐색 범위를동적으로 조절해 불필요한 정보 제거
그래프 임베딩 모델 사용
- 조직자
검색된 그래프 데이터를 정제하고 불필요한 node나 edge를 제거하여 더 간결하고 문맥적으로 의미 있는 정보를 유지
사용기술
Graph pruning (그래프 가지치기)
Reranking(재정렬)
Augmentation(보강)
- 생성기
정제된 그래프 데이터를 바탕으로 최종 응답을 생성
사용방식
텍스트 기반 응답 생성(LLM을 활용한 자연어 응답)
과학적 응용에서는 새로운 그래프 구조 생성(ex: 분자설계, 지식그래프 확장)
Applications
- QFS(Query-focused Text summarization)
- 사용자의 질문에 직접적으로 답하기 위해, 텍스트를 그래프 구조로 표현하여 관련 정보를 추출하고 요약
- Personalized Recommendations
- 전자상거래, 엔터테인먼트 등에서 사용자의 과거 상호작용을 그래프로 모델링하여 맞춤형 경험 제공
핵심 기술: 사용자 행동을 반영한 subgraph 추출, multi retriever를 활용해 추천 품질향상, 고객 서비스 QA시스템 개선
- Decision Support
- 의료 분야에서 복잡한 증상을 분석하고 질병-증상-치료간의 관계를 그래프로 모델링
사용사례: 관련 논문, 증례보고, 약물정보 검색, 진단제안, 치료 옵션 추천, 약물 상호작용 경고 제공 --> 출처가 있는 신뢰도 높은 응답 생성
- Fraud Detection and Prevention
- 금융 서비스 등에서 비정상 패턴을 식별하고, 분산된 거래를 연결해 대규모 사기 행위 탐지 ex) 여러 계좌에 걸친 소액 거래를 분석해 사기 연결고리 발견으로 리스크 관리 향상과 개인화된 서비스 제공
- Knowledge Management and Retrieval
문서간의 관계를 분석하여 문맥 기반 검색 및 정리를 가능하게 함
ex) 법률 사무소에서 수천건의 문서 간 관계를 분석하여 관련 판례, 법적 참고자료를 빠르고 정확하게 검색, 법률 리서치 자동화 및 정확도 향상
Challenges of GraphRAG
- Scalability: 대용량 데이터를 처리할 때, 그래프 저장, 쿼리 최적화, 하드웨어(GPU 가속)등의 문제 발생
- Streamlining: 쿼리 처리기, 검색기, 조직자, 생성기 간 원활한 연결이 복잡
- Reliability: 다단계 추론에서의 누적 오류 발성 가능성 존재
- Privacy & Safety: 그래프 구조 특성상 민감한 정보 노출의 위험있고, 공격 가능성 존재
- Explainability: 노드간 관계는 명시적이지만, 추론 경로를 명확히 설명하는 것은 여전히 어려움
Frameworks for building a GraphRAG system
- Llamaindex: 문서 인덱싱, 엔티티/관계 추출, 벡터 임베딩 생성, GPT등과 연동
- Neo4j: 그래프 저장/관리, 그래프 탐색 및 의미 기반 검색 지원
- LangChain, OpenAI: LLM 연동 및 생성형 응답 생성 지원
- Github: 다양한 오픈소스 예제와 튜토리얼 제공
--> 의미기반 검색, 메타 데이터 처리 및 투명성 확보 문맥 인식 응답 생성을 가능하게 함
Conclusion
Traditional RAG가 직선적인 검색 방식에 한정되었다면, GraphRAG는 지식그래프, 의미검색, LLM을 결합하여, 더 풍부한 관계성 기반의 응답을 제공 --> 미래에는 더 똑똑하고 동적으로 적응 가능한 정보시스템을 위한 핵심 기술이 될것으로 기대됨
Reference
IBM agentic-rag github
IBM Developer
https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
MIT Technology Review Insights sruvey. 2025
