문서 분류와 문서 클러스터링 문제
머신러닝 방법론
- text 문서 분류: KNN, NB, SVM, Random Forest(자연어처리) <-> vision에서는 조금 다를 수 있음
- 문서 클러스터링: K-means, DBscan
Main issue
- 문서 벡터를 어떻게 구성할 것인가?
- 유사도 계산 기법은?
문서 vector의 구성
- 문서의 특징을 가장 잘 표현하는 feature vector
- keyword 추출 및 키워드 가중치 계산: TF-IDF
ex) SVM 학습데이터: example1.tar.gz -- 로이터 뉴스기사
- train.dat (2천개), test.dat (600개)
- words: 9,947 terms are extracted
문서 벡터 구성의 문제점
- 문세 벡터의 차원수 문제
- feature(keyword) 개수: 수십만 ~ 수백만개
- 저장공간의 문제
차원축소 (Dimensionality reduction)
- Feature selection (문서를 구분하는 데에 중요한 특성들만 추출)
- 고차원 데이터를 저차원 공간으로 투영: PCA, LDA, LSA
Deep neural network를 이용한 차원축소
-입력벡터 -> 은닉층 -> 출력 벡터
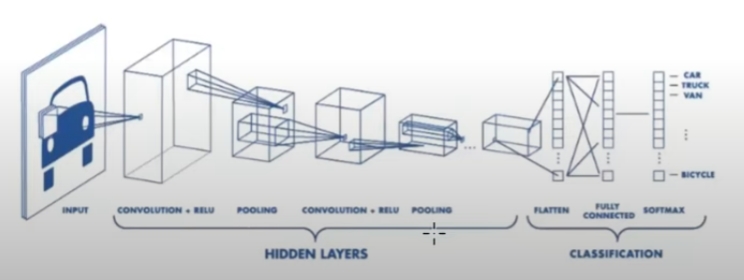
- CNN
Deep neural network --> Deep learning (computing power, GPU, Memory가 증가하면서 다층 layer 구성이 가능해짐)
Word embedding: word vector 구성
"You shall know a word by the company it keeps", J.R. Firth (1957)
"Efficient Estimation of Word Representations in Vector Space"
단어 벡터의 차원수: 모든 단어
- 단어의 특징을 가장 잘 표현하는 vector
- 대규모 텍스트 말뭉치로부터 단어 벡터 학습
- DNN (Deep neural network)으로 구현
'Word2vec': CBOW, skip-gram = 'PageRank algorithm' 과 매우 유사함
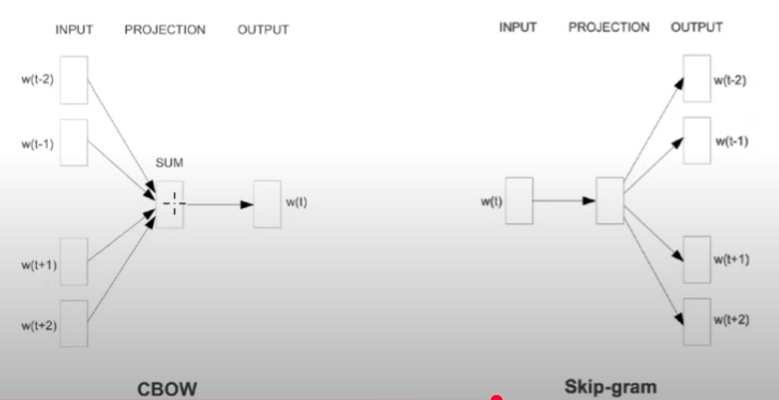
CBOW (Continuous Bag-of-words): 좌우 문맥으로부터 현재 단어 예측
-학습속도 빠름
-대규모 학습말뭉치에 적합
Continuous Skip-gram
-Skipgram: n-gram with a gap(현재 단어)
-빈도가 높은 단어 vector를 잘 표현함
-학습 속도가 느림
Python Library: gensim,Glove
visualizaion: scikit-learn t-SNE
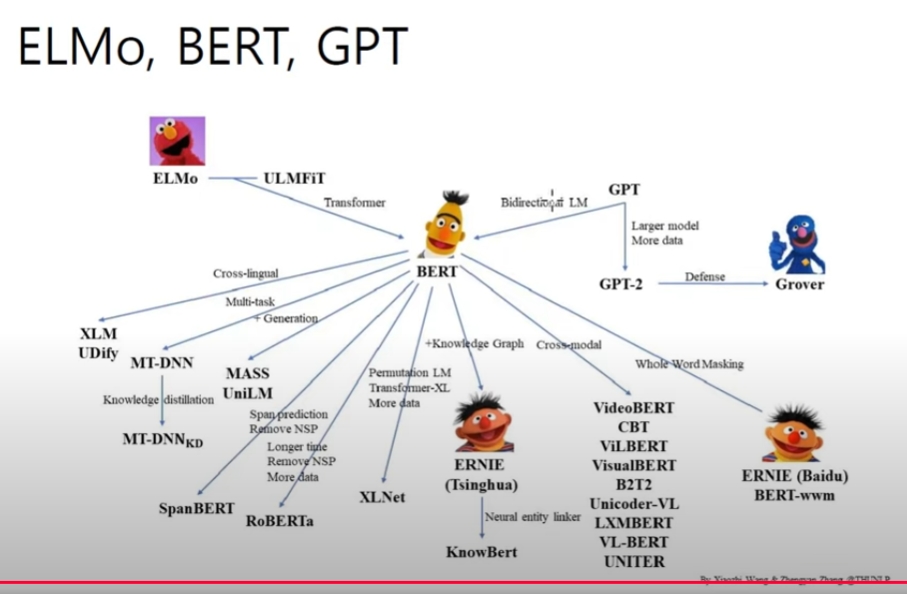
Word Embedding Methods
Word2vec
Glove
FastText
ELMo
BERT: ALBERT,RoBERTa
XLNet
ELECTRA
GPT-2
단어의 출현 문맥(좌,우)을 반영해야 더 정교한 vector를 만들 수 있다.
Evaluation(MRC): SQuAD, RACE, GLUE, etc
Pre-trained Language Representations
-
Feature-based approach: ELMO (Peters et al, 2018a)
-pre-trained representations as additional features -
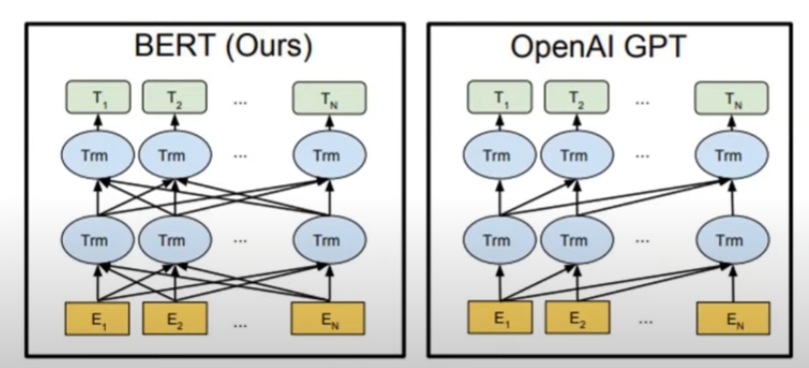
Fine-tuning approach: OpenAI GPT (Radford et al, 2018) - 단방향
-introduces minimal task-specific parameters
-simply fine-tuning all pretrained parameters -
Two approaches use unidirectional language models to learn general language representations
BERT: focused on bidirectional pre-training - 양방향
- Improve the fine-tuning based approahc by using
masked language model (MLM)
-randomly masks some of the tokens from the input and predicts the original vocabulary
next sentence prediction
-jointly pretrains text-pair representations

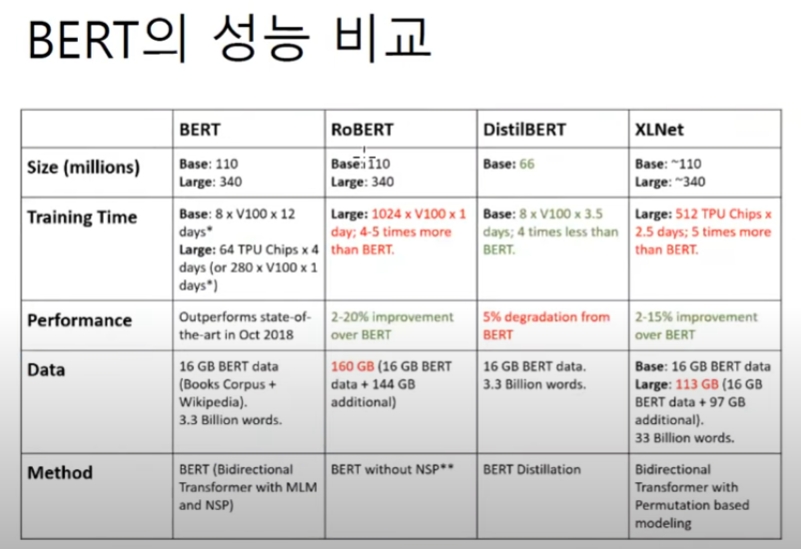
Reference
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Soace. In proceedings of Workshop at ICLR, 2014
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPs, 2013
Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic Regularities in Continuous Space Word Representations. In Proceedings of NAACL HLT, 2013
GLoVE: Global Vectors for Word Representation
XLNet: Generalized Autoregressive Pretraining for Language Understanding
SQuAD
GLUE: A Multi-Task Benchmark and analysis Platform for Natural Language Understanding
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (NAACL, 2019)
워드임베딩 개요 - 강승식 교수
