Natural Language Processing
1.Word Embedding
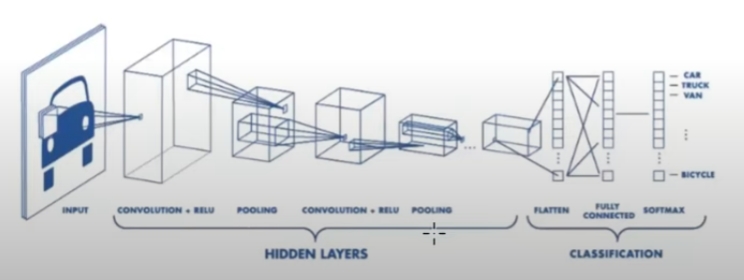
text 문서 분류: KNN, NB, SVM, Random Forest(자연어처리) <-> vision에서는 조금 다를 수 있음문서 클러스터링: K-means, DBscan문서 벡터를 어떻게 구성할 것인가?유사도 계산 기법은?문서의 특징을 가장 잘 표현하는 fea
2025년 5월 20일
text 문서 분류: KNN, NB, SVM, Random Forest(자연어처리) <-> vision에서는 조금 다를 수 있음문서 클러스터링: K-means, DBscan문서 벡터를 어떻게 구성할 것인가?유사도 계산 기법은?문서의 특징을 가장 잘 표현하는 fea