Explin Plan
=> "실행 계획을 보지 않고 튜닝을 하는 것은 환자의 낯빛만 보고 병명을 진단하는 것과 같다"
[1] 개념 정리
1) 인덱스 핵심만
Index = 정렬된 색인(ROWID 바로 찾기) → I/O(버퍼) 절감이 목적.
복합 인덱스는 선두 컬럼이 특히 중요. 선두 컬럼에 조건이 안 걸리면 우회 스캔/FTS(= FULL TABLE SCAN) 로 기울기 쉬움.
B-Tree(일반적), Bitmap(값 종류가 적고 집계/분석에 유리) 정도만 기억.
2) WHERE “순서” vs “인덱스 순서”
WHERE 절에 적는 순서 자체는 영향 거의 없음(옵티마이저가 재배치).
인덱스 정의 순서(복합 인덱스의 컬럼 순서)가 성능을 좌우.
3) SARGable ( = 칼럼을 "인덱스 타게" 활용하라) : “컬럼을 가공하지 않는다”
컬럼에 함수/연산/형변환을 걸면 인덱스 정렬을 활용하지 못함.
나쁨(컬럼 가공) 좋음(상수만 가공)
trunc(dt)=date '2025-08-01' dt >= date '2025-08-01' and dt < date '2025-08-02'
substr(code,1,3)='ABC' code like 'ABC%'
salary*12=100000000 salary = 100000000/12 (스케일 주의)
num_col='123' (암시적 변환) num_col=123 (타입 맞춤)
LIKE는 접두(prefix)만 인덱스탐색 가능: col like 'KIM%' ⭕ / '%KIM%' ❌
숫자 ‘접두’는 범위식으로 바꾸기(예: 6자리): emp_no between 101000 and 101999.
4) OR 대신 UNION ALL
A OR B는 FTS/비트맵 결합으로 기울 수 있음.
분해하면 각 분기가 자기 인덱스 Range Scan을 탈 확률↑
-- Before
... where emp_no like '101%' or emp_no like '103%';
-- After
select ... where emp_no >= '101' and emp_no < '102'
union all
select ... where emp_no >= '103' and emp_no < '104';
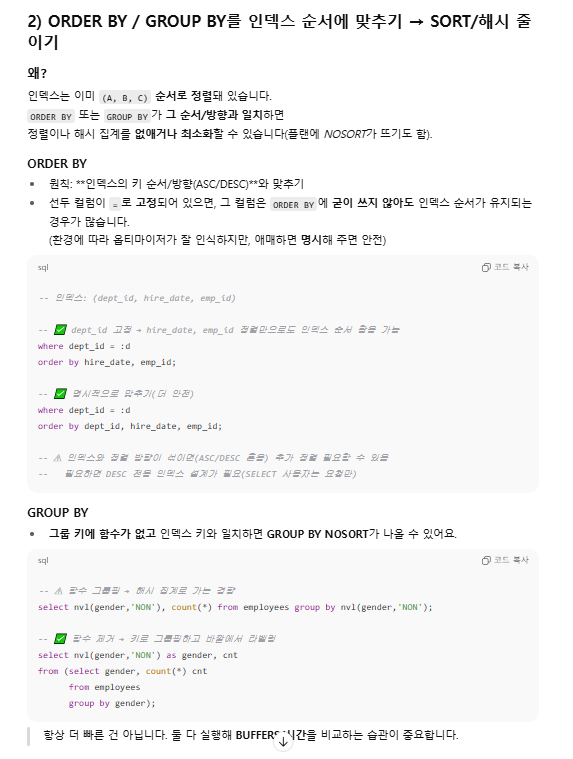
5) ORDER BY / GROUP BY
인덱스 컬럼 순서/방향과 맞추면 정렬 비용↓.
GROUP BY도 함수를 빼고 키 자체로 그룹핑하면 NOSORT 가능성이 생김.
-- 함수로 그룹핑 (해시집계로 가기 쉬움)
select nvl(gender,'NON'), count(*) from employees group by nvl(gender,'NON');
-- 키로 먼저 그룹핑 → 바깥에서 라벨링
select nvl(gender,'NON') gender, cnt
from (select gender, count(*) cnt from employees group by gender);
항상 더 빠른 것은 아님. BUFFERS/시간을 실측해서 판단.
6) “테이블 액세스” 줄이는 법
커버링(인덱스에 있는 컬럼만으로 결과 충족) 노리기 → SELECT * 지양.
TOP-N은 SQL에 명시:
... order by col fetch first 50 rows only → STOPKEY로 조기 종료.
페이지네이션은 키셋 권장:
SQL
select ...
from t
where (id) > (:last_id)
order by id
fetch first :page rows only;7) 인덱스 손익분기점(감 잡기)
선택도 낮을수록(적게 뽑을수록) 인덱스 유리.
Rough: 동등조건이면 ~5–10% 이하, 범위면 그보다 더 좁아야 인덱스가 이득인 경우 多.
정렬을 인덱스로 충족하면 인덱스 이득구간이 더 넓어질 수 있음.
8) Index Scan 종류 감
INDEX RANGE SCAN: 가장 이상적(필요 구간만).
INDEX FULL SCAN: 인덱스 정렬 유지 전범위 훑기(단일 블록 I/O).
INDEX FAST FULL SCAN: 정렬 없이 인덱스를 통으로(멀티블록/병렬, 집계/커버링에 유리).
9) 실행계획 읽기(요령)
DBMS_XPLAN:
EXPLAIN PLAN + DBMS_XPLAN.DISPLAY()
실측: /+ gather_plan_statistics / 후 DBMS_XPLAN.DISPLAY_CURSOR(NULL,NULL,'ALLSTATS LAST')
읽는 법: 안쪽(들여쓰기 깊은) 노드부터, Starts/BUFFERS가 큰 곳이 병목.
E-Rows vs A-Rows: 추정이 크게 빗나가면 통계 갱신 고려.
BUFFERS(논리 I/O)가 많이 쓰인 구간을 찾아 그 원인(FTS/정렬/형변환/조인)을 제거하는 리라이트가 목표.
Predicate Information에서 TO_CHAR(col)/TO_NUMBER(col)가 보이면 암시적 변환 의심(= 인덱스 방해).
10) 실전 케이스 요약
emp_no like '101%' or '103%'
암시적 변환 발생 시 TO_CHAR(emp_no)가 잡혀 FTS.
문자형: 반개구간으로, 숫자형: 자릿수 범위로 + UNION ALL → Range Scan 유도.
필요 시 FETCH FIRST n ROWS ONLY로 STOPKEY.
DBA_PROCEDURES Top-N 조회
COUNT STOPKEY + Index Scan → 좋음.
가능하면 USER_PROCEDURES 사용으로 더 가볍게.
group by nvl(gender,'NON')
INDEX FAST FULL SCAN + HASH GROUP BY + 커버링 → 이미 가벼움.
실험용으로 함수 제거 후 GROUP BY gender로 NOSORT 유도 비교.
11) 인덱스 구성 빠르게 확인
-- 인덱스 목록
select index_name, index_type, uniqueness
from user_indexes
where table_name = 'EMPLOYEES';
SQL
-- 인덱스 컬럼/순서
select index_name, column_position, column_name, descend
from user_ind_columns
where table_name = 'EMPLOYEES'
order by index_name, column_position;
-- (있다면) 함수 기반 인덱스
select index_name, column_position, column_expression
from user_ind_expressions
where table_name = 'EMPLOYEES';[2] 실행 계획 예시
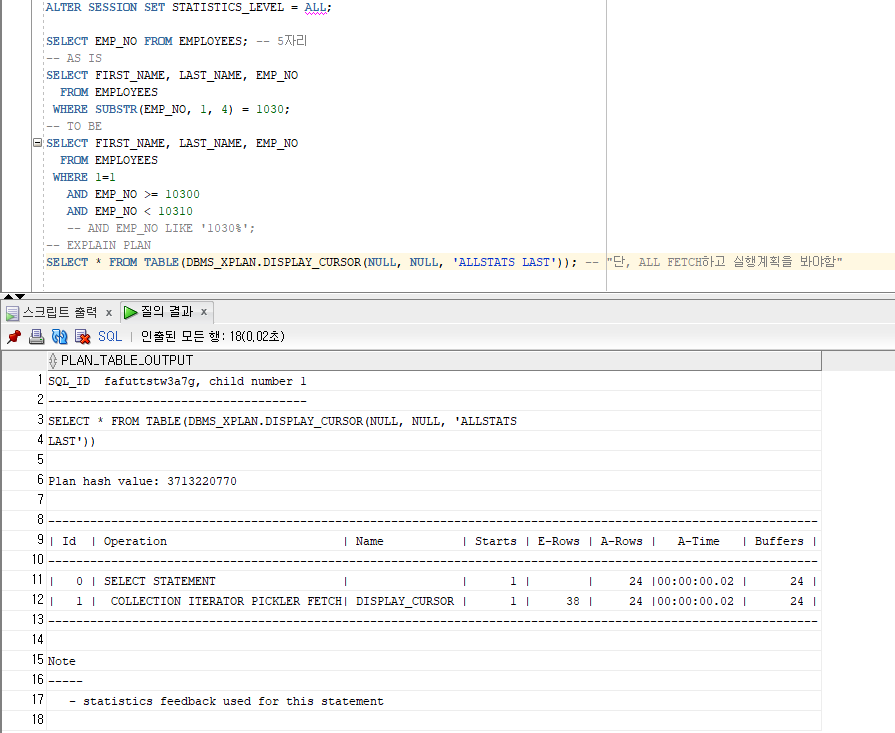
- 실행계획 읽는방법 : DBMS_XPLAN 패키지 사용하기
- 'Operation' 부분을 보면서 들여쓰기 젤 깊게 되어있는것부터
- 동일하게 들여쓰기 되어있는건 위에거를 먼저
- 위 순서에 따라 BUFFERS 가 누적으로 사용되는걸 보면된다
- 실질적으로 중요한건 BUFFERS가 얼마나 감소됐냐가 중요한것이고, A-TIME이나 BUFFERS가 어느구간에서 크게 잡혔는지를 확인해서 병목을 파악할수있다 (그 구간에서 COST를 많이 쓰고있는셈)
[3] 실무 꿀팁 핵심 요약(SELECT 전용)
A. “플랜에서 이렇게 보이면 → 이렇게 고쳐라”
TABLE ACCESS FULL가 병목
컬럼 가공 제거 + 타입 맞춤 → SARGable
OR → UNION ALL 분해
접두 LIKE / 반개구간 사용
예시
SQL
-- Before
where to_char(emp_no) like '101%' or to_char(emp_no) like '103%';
-- After(문자형)
where (emp_no >= '101' and emp_no < '102')
union all
select ... where (emp_no >= '103' and emp_no < '104');INDEX RANGE SCAN 뒤 TABLE ACCESS BY ROWID가 많다
SELECT * 금지 → 필요 컬럼만(커버링 유도)
필터를 더 선택적으로(동등/좁은 범위)
TOP-N 있으면 FETCH FIRST n으로 STOPKEY
예시
SQL
-- Before
select * from orders
where customer_id=:cid
order by order_dt fetch first 50 rows only;
-- After(커버링 가정)
select customer_id, order_dt, status
from orders
where customer_id=:cid
order by order_dt
fetch first 50 rows only;INDEX FULL SCAN이 무겁다(전 범위+정렬 유지)
불필요한 ORDER BY 제거 또는 필터 강화로 RANGE SCAN 유도
예시
SQL
-- Before
select order_id, order_dt from orders order by customer_id, order_dt;
-- After
select order_id, order_dt
from orders
where customer_id=:cid
order by order_dt;INDEX FAST FULL SCAN + HASH GROUP BY
보통 커버링 집계엔 좋음(그냥 두는 게 빠를 때 多).
하지만 정렬/NOSORT로 더 이득이면 아래처럼 시도
예시
SQL
-- Before
select nvl(gender,'NON'), count(*) from employees group by nvl(gender,'NON');
-- Try
select nvl(gender,'NON') gender, cnt
from (select gender, count(*) cnt from employees group by gender);Predicate Information에 TO_CHAR(col)/TO_NUMBER(col)
암시적 변환 제거(바인드/리터럴 타입 맞추기)
예시
SQL
-- Before
where num_col = '123';
-- After
where num_col = 123;SORT ORDER BY / GROUP BY가 큰 병목
인덱스 순서/방향에 맞춰 ORDER BY 정렬 키 재구성
불필요한 정렬 삭제
예시
SQL
-- 인덱스 (region, sale_dt, id)
select ...
from sales
where region=:r
order by region, sale_dt, id; -- 정렬키를 인덱스 순서에 정렬E-Rows ↔ A-Rows 오차 큼 / dynamic sampling 표시
통계 갱신 요청(DBA): 테이블/인덱스 통계 최신화
B. 현장에서 바로 쓰는 체크리스트(요약)
-
컬럼 가공 금지(함수/연산/암시적 변환)
-
선두 컬럼 = + 다음 컬럼 좁은 범위
-
OR → UNION ALL, IN ↔ EXISTS 목적에 맞게
-
필요 컬럼만 SELECT(커버링)
-
ORDER BY/ GROUP BY = 인덱스 순서
-
Top-N은 FETCH로 STOPKEY
-
Keyset 페이징 사용
-
플랜은 ALLSTATS LAST로 실측(E/A/BUFFERS)
-
버퍼 많이 먹는 노드를 찾아 그 원인을 없애는 리라이트
-
통계 최신화로 계획 안정화
"마지막 요약"
목표는 간단합니다. 인덱스가 “필요한 구간만” 읽게 하고(범위 최소화), 테이블을 “가능하면 안 가게” 하라(커버링/Top-N).
이를 위해 쿼리는 SARGable하게 작성한다.
EX) 풀스캔 없이 인덱스 기반 + Top-N 조기 종료 + 낮은 Buffers → 좋은 상태!
[4] ChatGPT를 통한 내용 복습
Q1. 아래 내용에 대해서 풀어서 설명해주고, 각 경우에 대한 예시도 설명.
- 복합 인덱스는 선두 컬럼부터 조건을 잡기.
- ORDER BY/ GROUP BY를 인덱스 순서에 맞춤 → SORT/해시 줄이기.
- 테이블 스캔 종류 : TABLE ACCESS FULL, TABLE ACCESS BY INDEX ROWID, INDEX RANGE SCAN, INDEX UNIQUE SCAN 중 어떤 순서대로 의도해서 작업하는게 좋은지. 테이블 스캔별에 대한 숙지와 팁.
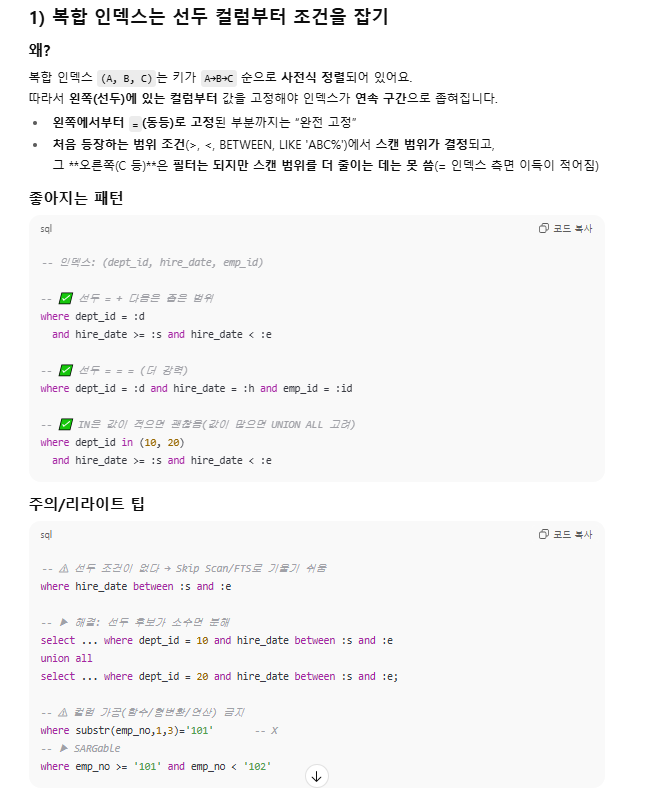

한 줄 요약
- 선두부터 꽉 잡고(=), 처음 나오는 범위에서 스캔을 끝내라.
- 정렬/그룹은 인덱스 순서에 맞추고,
- 테이블 방문은 최소화(커버링/Top-N).
- 플랜에서 FTS·대형 SORT·암시적 변환이 보이면 그 지점을 리라이트로 없애면 됩니다.
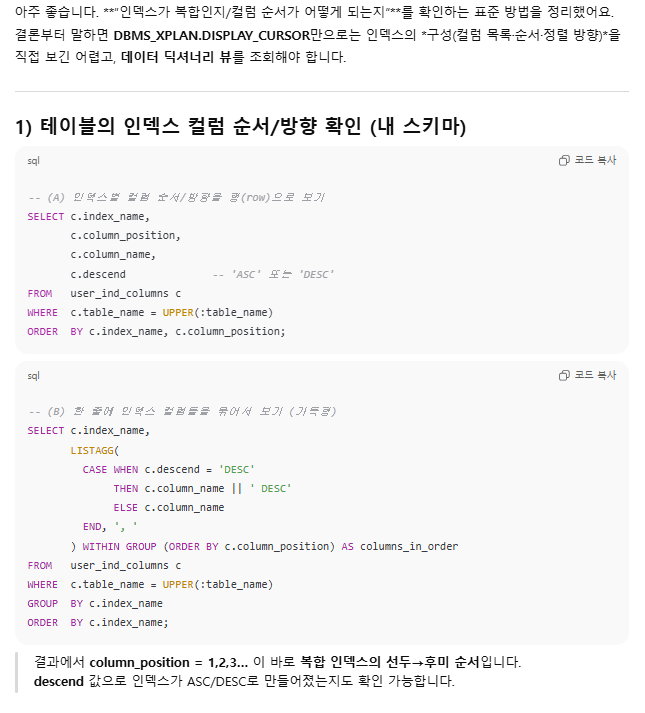
Q2. 아래 본문을 보고 '인덱스가 복합되어있는지, 그 경우 어떤 순서로 되어있는지 확인하는 쿼리문'을 알려줘.
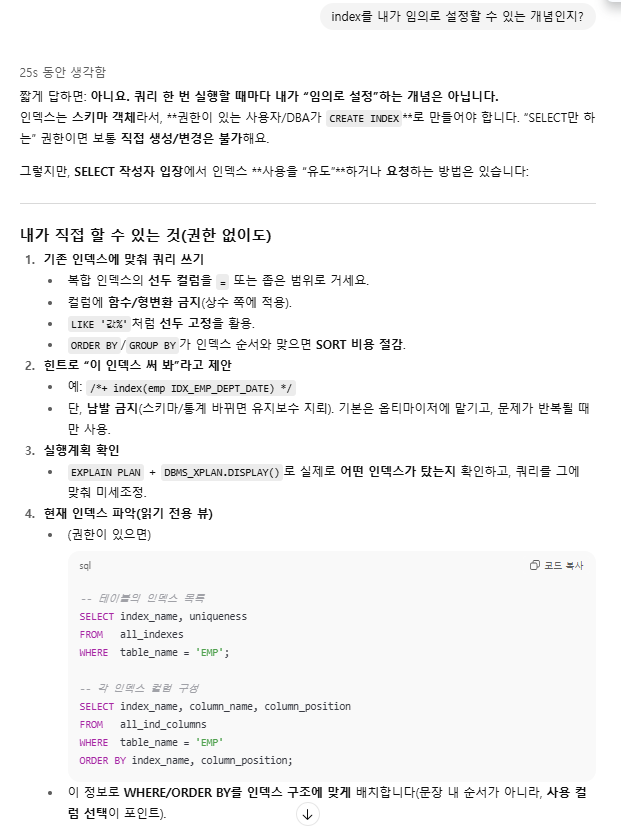
- 혹시 SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')) 이 쿼리문으로는 확인을 못하는지?
- ORDER BY / GROUP BY를 인덱스 순서에 맞추기 → SORT/해시 줄이기 왜? 인덱스는 이미 (A, B, C) 순서로 정렬돼 있습니다. ORDER BY 또는 GROUP BY가 그 순서/방향과 일치하면 정렬이나 해시 집계를 없애거나 최소화할 수 있습니다(플랜에 NOSORT가 뜨기도 함).