Oracle Hint
=> "옵티마이저가 잘못된 판단을 한다고 생각될 때에는 Hint를 주어 올바른 방향으로 수행하도록 유도할 수 있다"
[1] 아키텍쳐 기본개념
- 기초개념
- SGA: 도서관의 공용 열람실(모든 세션이 함께 쓰는 큰 메모리)
- PGA: 내 자리의 개인 책상(각 세션/프로세스별 개인 메모리)
- Redo Log: “무슨 변경을 했는지” 기록하는 보안 CCTV(앞으로 되살리는 용도)
- Undo Log: “변경 전 상태”를 저장한 책 페이지 복사본(되돌리기 & 과거 시점 읽기)
- 트랜잭션/COMMIT/ROLLBACK: “대출 업무 하나의 묶음/확정/취소 -> 하나의 논리업무 단위”
- COMMIT: “확정”. Redo가 디스크로 안전히 기록되었음을 보장.
- 당장 내 세션에서 보면 commit 없이도 delete 등 변동상태가 적용된것처럼 보이지만 실제 적용을 위해서는 꼭 commit을 해야함
- ROLLBACK: “취소”. Undo로 변경 전 상태로 복구.
- SELECT 입장: 직접 COMMIT/ROLLBACK을 하진 않지만, 다른 세션의 COMMIT 여부가 내가 보는 데이터의 “버전”과 관련됨(아래 MVCC).
- MVCC: git 처럼 다중버전 제어 컨셉 -> 읽기 일관성을 위한 임시 과거보기 장치(쿼리 시작 시점의 일관된 스냅샷을 보여주기 위한 임시 메커니즘.) vs Git = 영구 버전 관리.
- ROLLBACK은 미커밋만 되돌린다.
- 항상 복원 가능 X — Undo가 살아있을 때만 Flashback으로 “잠깐” 과거를 볼 수 있다.
- SELECT만 써도 MVCC를 알면 일관된 결과/긴 쿼리 튜닝(Undo 소모↓)에 큰 도움이 된다.
- 읽기 일관성: 내가 실행한 긴 SELECT는 시작 시점 상태로 고정되어 중간에 다른 사람이 COMMIT해도 결과가 흔들리지 않음.
- ORA-01555 (snapshot too old): 긴 FTS 등으로 오래 걸리면, 필요한 Undo가 없어져 에러.
- 예방: 인덱스를 타게(SARGable), 집합을 줄이기(OR→UNION ALL, 반개구간), Top-N 명시 등으로 쿼리 시간을 줄이기.
[2] JOIN 최적화
[2-1] Nested Loop Join
1) 개념 한 줄 요약
NLJ = 중첩 for문
바깥(Driving)에서 한 행씩 뽑고 → 안쪽(Driven)을 인덱스로 찔러 매칭 행을 찾는다.
2) Driving / Driven 의미와 선택 기준
Driving: 먼저 읽는 테이블(바깥 루프). “조인당하는 메인”이 아니라 루프의 기준.
Driven: 나중에 읽는 테이블(안쪽 루프). 조인 키 인덱스가 있어야 빠르다.
실무 선택 규칙
Driving = 필터로 작아지는 쪽(선택도 높음, Top-N, 기간 좁음)
Driven = 조인키(+ 추가 필터) 인덱스 보유(선두 = + 다음 컬럼 범위)
3) 조인 순서가 왜 중요한가
NLJ 비용 ≈ (Driving 결과 행수) × (Driven 탐색 비용)
→ 바깥을 최대한 작게, 안쪽은 인덱스 Range Scan으로.
4) 힌트: ORDERED, USE_NL
반드시 USE_NL가 있어야 NLJ가 되는 건 아님. 옵티마이저가 상황 따라 NL/해시를 선택.
계획이 자꾸 틀리면:
/+ ORDERED USE_NL(별칭) INDEX(별칭 인덱스명) / 로 순서·방식·인덱스를 부드럽게 유도.
5) 인덱스는 NLJ의 생명선
Driven 쪽에 조인키(+ 필터 컬럼) 복합 인덱스가 있어야 한 번 탐색 비용이 작다.
SARGable: 컬럼에 함수/형변환 금지, 반개구간(>= AND <) 사용.
6) WHERE 필터가 있을 때의 차이
Driving 필터: 바깥 행수↓ → 전체 루프↓(효과 큼)
Driven 필터: 인덱스와 결합 시 한 번 탐색 범위↓
둘 다 컬럼 가공 금지가 기본
7) 은행 도메인 예시 (간결·핵심만)
7-1. 이상적 NLJ (고객⇢거래, 기간 좁음)
/*+ ORDERED USE_NL(t) INDEX(t IDX_TXN_ACCT_DT) */
SELECT t.txn_id, t.acct_id, t.txn_amt
FROM customers c, transactions t
WHERE c.region = :r -- Driving을 작게 만드는 강한 필터
AND t.acct_id = c.acct_id -- 조인 (Driven)
AND t.txn_dt >= :d1
AND t.txn_dt < :d2; -- 반개구간 (Range Scan 유도)
Driving = customers(지역으로 소수만)
Driven = transactions((acct_id, txn_dt) 인덱스 가정) → INDEX RANGE SCAN**7-2. 잘못된 패턴 → 리라이트
**-- Bad: Driven 컬럼 가공으로 인덱스 무력화
WHERE t.acct_id = c.acct_id
AND TO_CHAR(t.txn_dt,'YYYYMM') = :yyyymm; -- X
-- Good: SARGable 반개구간
WHERE t.acct_id = c.acct_id
AND t.txn_dt >= :m
AND t.txn_dt < :m_next; -- O8) 실무 체크 포인트(짧게)
Driving: 강한 필터/Top-N으로 작게
Driven: 조인키(선두 =) + 범위 컬럼 인덱스, SARGable
힌트: 틀릴 때만 ORDERED + USE_NL(Driven)(+ INDEX)
피해야 할 것: Driven 컬럼에 TO_CHAR/TO_NUMBER, TRUNC, %값% 등
플랜에서 볼 것:
NESTED LOOPS 아래 Driven의 INDEX RANGE SCAN 유무
Starts(내부 호출 수) 급증, BUFFERS 급증 지점
한 줄 결론
작게 뽑는 테이블을 Driving으로, Driven은 인덱스로 ‘정확히’ 찌른다.
안쪽 컬럼 가공 금지, 반개구간·UNION ALL로 Range Scan을 확보하고, 필요 시 ORDERED/USE_NL로 의도를 고정하자.
[2-2] Hash Join
1) Hash Join 한 줄 정의 & 언제 쓰나
정의: 작은 쪽을 메모리에 해시 테이블(build)로 만들고, 큰 쪽을 연속 스캔(probe)하며 해시로 매칭.
→ 인덱스 없어도 빠름, 랜덤 I/O 대신 순차 스캔.
바로 쓰는 기준
조인키 인덱스가 없음 / 컬럼 가공으로 인덱스 못 탐
인덱스가 있어도 Driving→Driven 랜덤 접근이 많아 NLJ가 비쌀 때
둘 다 큼(필터 후 수십만~수백만 로우), 리포트/일회성 집계(OLAP 스타일)
반대로, 바깥(Driving)이 매우 작고 Driven에 인덱스가 잘 잡히면 NLJ가 유리.
2) 인덱스가 뭔지 & 있는지 빠르게 확인
인덱스: 특정 컬럼(들)을 정렬된 색인으로 만들어 ROWID를 빠르게 찾는 구조.
존재 확인
-- 내 스키마: 테이블/컬럼 인덱스 확인
SELECT index_name
FROM user_ind_columns
WHERE table_name = 'TRANSACTIONS'
AND column_name = 'ACCT_ID';
복합 인덱스 순서
SELECT index_name, column_position, column_name
FROM user_ind_columns
WHERE table_name = 'TRANSACTIONS'
ORDER BY index_name, column_position;3) 실무 힌트 세트 (짧고 강하게)
기본 유도: /+ ORDERED USE_HASH(별칭) / (+ 필요 시 FULL(별칭))
Build 쪽(해시 테이블)은 작은 집합이 유리. 필요하면 /+ SWAP_JOIN_INPUTS(별칭) /로 바꾸기.
SARGable 유지(컬럼 가공 금지), 반개구간(>= AND <)로 범위 좁히기.
조인키 타입 일치(암시적 변환 방지).
큰 해시가 TEMP로 스필하면 느려짐 → 지나치게 큰 집합이면 필터 더 좁히거나 시간대 조정/병렬은 DBA 협의.
4) 은행 예시 (오라클 전통 문법, 최소 예시만)
A. 조인키 인덱스가 없거나 NLJ 랜덤 I/O가 큰 경우
/*+ ORDERED USE_HASH(t) FULL(t) */
SELECT t.txn_id, t.acct_id, t.txn_amt
FROM accounts a, transactions t
WHERE t.acct_id = a.acct_id
AND a.region = :r -- Driving을 작게(강한 필터)
AND t.txn_dt >= :d1
AND t.txn_dt < :d2; -- 반개구간 (SARGable)해석: accounts를 먼저 작게 만든 뒤, transactions는 해시 조인 + 연속 스캔. 인덱스 없거나 NLJ가 랜덤 I/O 폭탄이면 이쪽.
B. 대용량 리포트/일회성 집계(OLAP 성격)
/*+ ORDERED USE_HASH(t) FULL(a) FULL(t) */
SELECT a.branch_id, SUM(t.txn_amt) AS sum_amt
FROM accounts a, transactions t
WHERE t.acct_id = a.acct_id
AND t.txn_dt >= :m
AND t.txn_dt < :m_next
GROUP BY a.branch_id;해석: 월간 대량 집계. 둘 다 큼 → 해시 조인 + 풀스캔이 안정적.
C. OUTER JOIN(+) + Hash Join 유도
/*+ ORDERED USE_HASH(k) */
SELECT a.acct_id, k.kyc_level
FROM accounts a, kyc_info k
WHERE k.acct_id(+) = a.acct_id -- LEFT OUTER JOIN
AND a.status = 'ACTIVE';해석: 활성 계좌 기준, KYC는 있을 수도 없을 수도. USE_HASH(k)로 k를 해시로 붙임.
5) “크다”의 감(룰 오브 썸)
절대 기준은 없음. 아래는 체감용:
NLJ 적합: Driving 결과 수천~수만 행 이하 + Driven에 좋은 인덱스 → 랜덤 접근 총량이 작음.
Hash 적합: Driving 결과가 수십만 이상이거나, Driven 인덱스가 무의미/없음, 양쪽 모두 큼.
애매하면 /+ gather_plan_statistics / + DBMS_XPLAN.DISPLAY_CURSOR('ALLSTATS LAST')로 A-Rows/BUFFERS 비교.
6) OLTP vs OLAP, 일회성 추출에서는?
OLTP(거래계): 짧고 잦은 소량 조회. NLJ + 인덱스 선호, 풀스캔 자제.
OLAP(분석/리포트): 큰 집합, 집계. Hash + 풀스캔이 안정적.
일회성 대량 추출(업무시간 외 권장): Hash Join OK. 다만
필터 확실히(기간/지점 등),
컬럼 가공 금지,
가능하면 오프피크. (병렬/작업창은 DBA와 협의)
7) 언제 Hash, 언제 NL — 초간단 결정표
상황 추천
Driving 작고 Driven 인덱스 좋음 NLJ
조인키 인덱스 없음/무의미 Hash
둘 다 큼(필터 후 수십만+) Hash
Top-N/즉시반환 필요 NLJ 쪽이 유리
함수/형변환으로 인덱스 무력화 리라이트(SARGable) 또는 Hash
8) 마지막 체크리스트
ORDERED + USE_HASH(별칭) 로 유도, 필요 시 FULL(별칭)
Build = 작은 쪽, 필요 시 SWAP_JOIN_INPUTS
SARGable / 반개구간 / 타입 일치
A-Rows/BUFFERS로 실제 비교 (ALLSTATS LAST)
OLTP는 NLJ 위주, OLAP/일회성 대량은 Hash 위주
한 줄: 인덱스가 힘 못 쓰거나 랜덤 I/O가 커질 땐 Hash로 “크게 훑고 맞춘다”.
필터로 집합을 줄이고, 힌트로 순서와 방식만 가볍게 고정해주면 됩니다.
[3] 쿼리 리타이트
[3-1] WHERE 절에서의 MAX => EXISTS 로 대체
AS-IS
SELECT EMP_NO, FIRST_NAME, LAST_NAME
FROM EMPLOYEES
WHERE EMP_NO < 20000
AND (SELECT MAX(SALARY)
FROM SALARIES
WHERE EMP_NO = EMPLOYEES.EMP_NO) > 140000;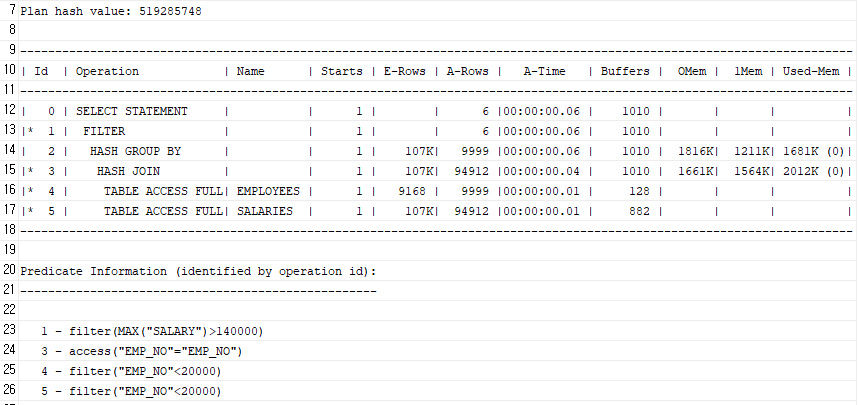
- 목적: 급여 테이블에서 해당 사원의 최고 연봉이 14만 초과인지 확인
- 문제: MAX() 집계 함수를 쓰면 조건 확인을 위해 전체 데이터를 끝까지 훑음 → 비효율적
TO-BE
SELECT e.emp_no, e.first_name, e.last_name
FROM employees e
WHERE e.emp_no < 20000
AND EXISTS (
SELECT 1 -- 단순 존재여부만 보는거라 더미값. 1말고 어떤 값을 써도 상관없음
FROM salaries s
WHERE s.emp_no = e.emp_no
AND s.salary > 140000
)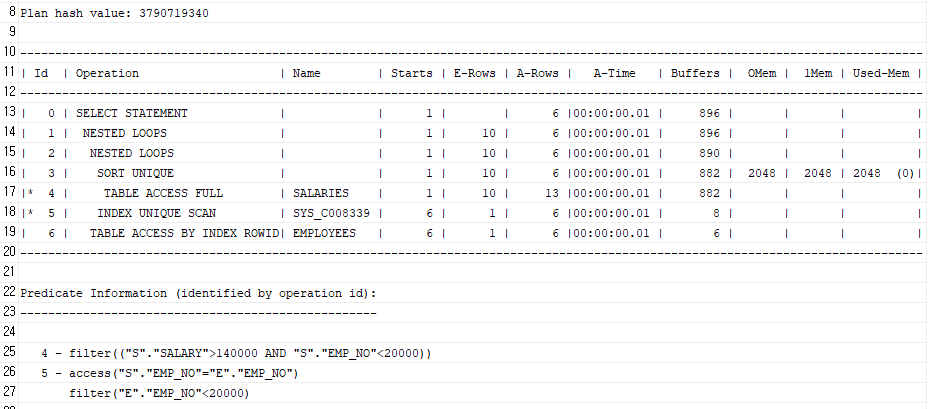
- WHERE 절의 MAX(...) > n 조건은 → EXISTS로 바꿀 수 있음
- 성능: 집계 연산 제거, 빠른 단축 평가 가능
- 실무에서 집계 대신 존재 여부 확인일 때는 무조건 EXISTS 고려