해당 포스팅은 다음의 위키독스를 읽고 정리한 개념임을 밝힙니다
워드 임베딩(Word Embedding)
-
희소 표현 (Sparse Regresentation)
- 원핫인코딩 처럼 단어 집합의 크기가 전체 차원이고 인덱스만 1 나머지는 0
- cos 유사도로 하면 전부 0100 1000 이런식이 돼서 값이 전부 0임. 유사성을 전부 무시하게 됨.
- 코퍼스의 단어가 10,000개 경우
- Ex) 강아지 = [ 0 0 0 0 1 0 0 0 0 0 0 0 ... 중략 ... 0] # 이때 1 뒤의 0의 수는 9995개.
=> 공간낭비 & 순서나 관계 표현 못함
- 원핫인코딩 처럼 단어 집합의 크기가 전체 차원이고 인덱스만 1 나머지는 0
-
밀집 표현 (Dense Representation)
- 단어 집합의 크기가 전체 차원이 아니고, 사용자 지정 값이 차원 수가 됨
- 0,1 binary 값말고 실수 값도 가짐
Ex) 강아지 = [0.2 1.8 1.1 -2.1 1.1 2.8 ... 중략 ...] # 이 벡터의 차원은 128
⇒ 이렇게해서 단어를 표현하는거를 워드 임베딩 이라고 함
⇒ 이 과정을 통해 나온 결과를 임베딩 벡터라고 함
⇒ LSA, Word2Vec, FastText, Glove 등이 있음
-
- Word2Vec 신경망은, input값을 각 단어별 원핫형태고 output을 이웃한정도로 줘서 오차역전파를 통해 hidden layer를 결과로 얻는형식
- 그리고 학습이 끝난뒤 샘플들어오면 학습된 word2vec 에 넣었을때의 hidden layer state 값이 임베딩 벡터가 됨
Word2Vec
-
(토큰화된 단어, 차원 수, 윈도우 크기 등의) 인자로 주면 단어를 임베딩해주는 모델로 학습시키는 방식.
-
학습 후 저장 및 로드하여 사용
-
영어의 경우에는 사전 훈련된 임베딩 모델을 이용할 수 있음
-
그리고 이렇게 임베드 된 벡터를 이용해서 문서 간 유사도 구하는거를 'WMD'라고 함
-
예시 (이미지 출처 : 유튜브 허민석 님)

- 원핫인코딩의 단점은 순서나 근처 관계를 표현하지 못하는 것

- 임베딩은 주변 이웃과의 유사도를 보는 것
- 윈도우 사이즈 1은 양옆 한칸짜리의 이웃을 보겠단 의미
- 고로 brave가 인풋이면 king, man이 아웃풋
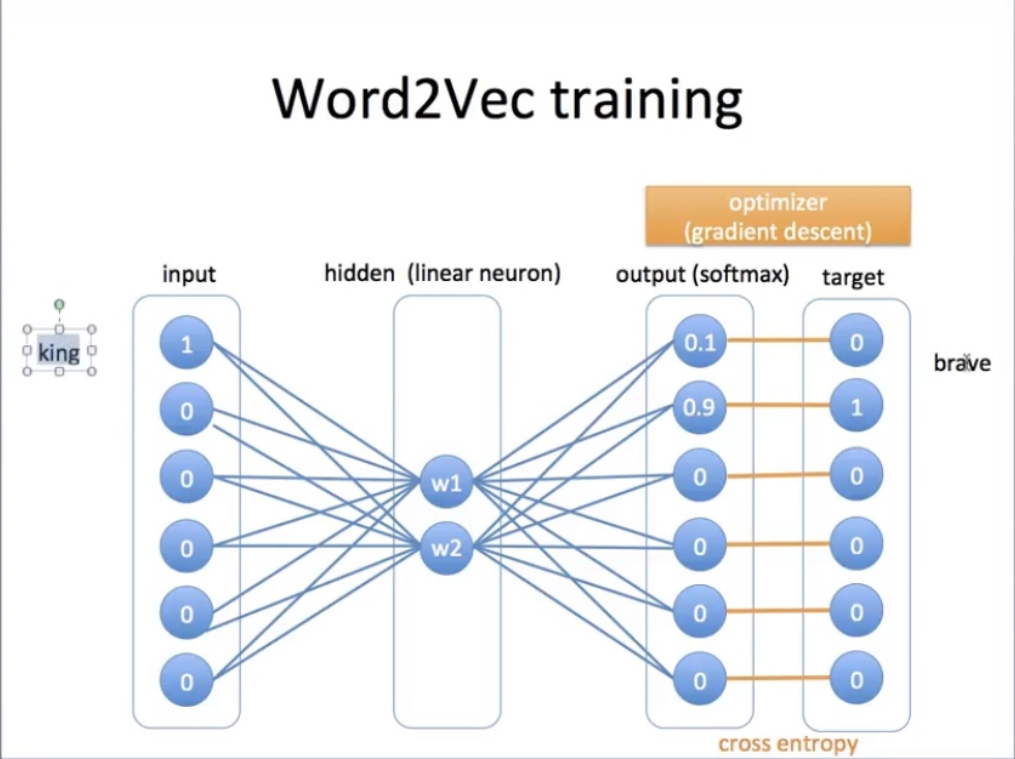
- 입력값 원핫인코딩
- 히든레이어 가중치 : 임베딩값
- supervised learning 방식으로, 역전파해서 w값 줄임 -
CBOW
- 주변을 입력으로 중간 단어 예측
-
Skip-Grame
- 중간을 입력으로 주변 단어 예측⇒ 윈도우 : 주변을 볼 때 몇개까지 볼지에 대한 사이즈 개념
⇒ 표현 : gensim의 Word2Vec
-

금융권에 가고싶은 김코다입니다. 취업을 하면 기타치며 조르바처럼 살고파요. -> 금융권 왔다. 취업도 했다. 그러나 여전히 조르바처럼..