해당 포스팅은 다음의 위키독스 (https://wikidocs.net/book/2155)를 읽고 정리한 개념임을 밝힙니다
토큰화된 문장에서 각 토큰에 대해 값으로 나타낼 때 단어간의 어울림을 고려하느냐에 따라 두가지 방법으로 분류 될 수 있다
-
국소 표현( = Local = Discrete), 분산 표현( = Distributed = Continuous)
-
국소 표현 : 주변 단어와의 어울림은 고려하지않고 오로지 그 단어자체만 보고 매핑
- puppy , cute, lovely : 걍 1,2,3이렇게 맵핑
-
분산 표현 : 주변 단어와의 어울림도 고려해서 맵핑
- puppt, cute, lovely : 주변으로 정의함 puppy는 cute, lovely한 느낌이다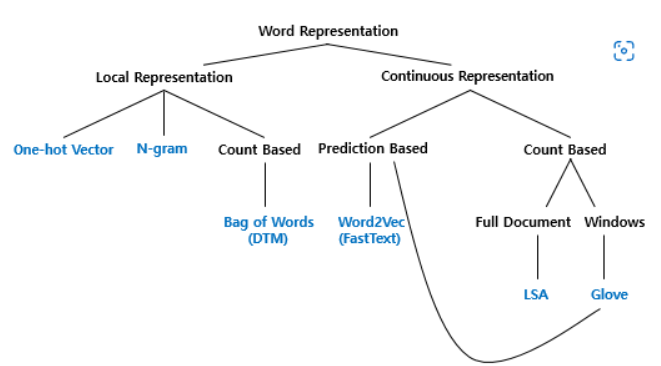
-
-
Bag of Word(BoW)
- 순서같은거 고려하지않고 오로지 빈도로만 표현
- 표현 => CountVectorizer (한국어는 없음)
- BoW하기전 불용어 제거 필수
- 예시 (이하 이미지 출처 : 유튜브 허민석님)

- 사용된 단어를 전부 가방 (하나의 커다란 리스트) 에 unique하게 넣는다
- 그리고 단어별 사용횟수로 값을준다
- 비교하고자 하는 문장의 요소별 곱의 합이 클수록 유사도 크다고 판단
- 단점
- 데이터 많아질수록 가방의 용량 증가
- 빈출 단어의 영향력이 무의미하게 계속 커짐
- 단어의 순서 미반영
- 새로운 단어의 성능이 떨어짐
- 데이터 많아질수록 가방의 용량 증가
-
문서 단어 행렬(Document-Term Matrix, DTM)
-
다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것임.
=> 각 문서에 대한 BoW를 하나의 행렬로 만든 것 (sklearn CountVectorizer)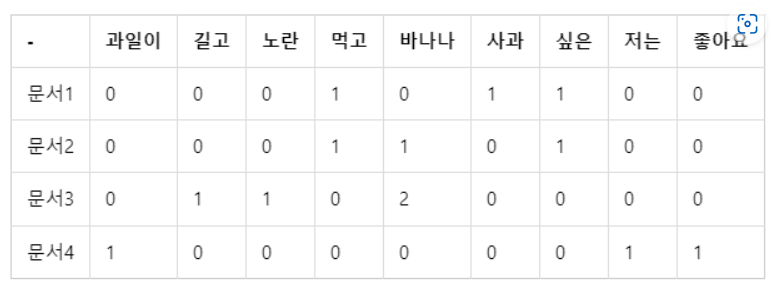
-
-
TF-IDF
=> 각 단어가 문서와 얼마나 연관성이 있는가
- BoW의 단점을 극복하고자 나옴.
- 표현 => 사이킷런 TfidfVectorizer
- 예시

- TF = 문장에서 단어가 출현한 빈도
-> 다만 관사같이 쓸데없이 많이 등장하는 애들이 성능에 방해할 수 있음
-> 보완하기위해 IDF 라는 값을 곱해준다

- 분자 : 문장의 개수 (2)
- 분모 : 두 문장에서 몇번등장 했는가 (0,1,2) <- 분모 0되는거 피할려고 분모 +1 해주기도

- 최종적으로 이렇게 연산됨

금융권에 가고싶은 김코다입니다. 취업을 하면 기타치며 조르바처럼 살고파요. -> 금융권 왔다. 취업도 했다. 그러나 여전히 조르바처럼..