해당 포스팅은 다음의 위키독스 (https://wikidocs.net/book/2155)를 읽고 정리한 개념임을 밝힙니다
-
토큰화(Tokenization)
-
크롤링 등으로 얻어낸 raw 데이터 (=말뭉치=코퍼스) 를 분석하기 위해 토큰단위로 분해해야
- 1. 문장 토큰화 (문단 ⇒문장)
- 그냥 ?, ! 있으면 이 기준이 좋다.
- 다만 마침표(.)는 사람들이 의미가 지속되어도 중간에 그냥 쓰는경우가 많아서 막 쓸수 없음
- 영어 => NLTK의 sent_tokenize 쓰면됨
- 한국어 => kss라는 거 쓰면된다!
- 2. 단어 토큰화 (문장 ⇒ 단어) (흔히 word, 의미 있는 단위로 토큰 정의함)
- 영어와 달리 한글은 무지성으로 띄어쓰기로 토큰구분이 안됨
- 구두점이나 특수문자 제거만으로 끝나는거 아님
- 어퍼스트로피, 줄임말 등의 이슈때문에 표준 토큰화 방법인 ‘Penn Treebank Tokenization’ 과 같은 규칙도 있음 (영어 자연어의 경우)
- 한국어는 그냥 영어처럼 단어로 자르는게 아니라 조사나 어미 이런것도 다 따로 잘라줘야함 그래서 word 기준이 아니라 ‘형태소’기준이라 생각하면됨
- koNLPY 패키지에서 형태소 분석기인 Okt, Mecab, Komoran, Hannanum 등을 사용할 수 있음
- 1. 문장 토큰화 (문단 ⇒문장)
-
이후 단어로만 갖고있는게 아니라 숫자로 바꾸는게 컴퓨터가 인식하기엔 좋으므로 단어별로 숫자로 일대일 매칭해서 정수로 변환하여 저장한다.
-
이게 word in bag 개념일 것임 (보통 빈도별로 내림차순 정렬)
-
keras의 Tokenizer : [ [문장1의 토큰], [문장2의 토큰], [문장3의 토큰] ] ⇒ 빈도만큼 인덱스를 알아서 부여함.
-
"원-핫 인코딩"
-
단어 집합(vocabulary) : 모든 단어들이 unique하게 들어가 있는 목록, 정수매칭
- book과 books를 서로 다르게 취급
-
단어 집합에 들어가있는 정수를 인덱스로 취급하여 해당 인덱스를 1, 나머지는 0으로 채운 벡터로 관리한다
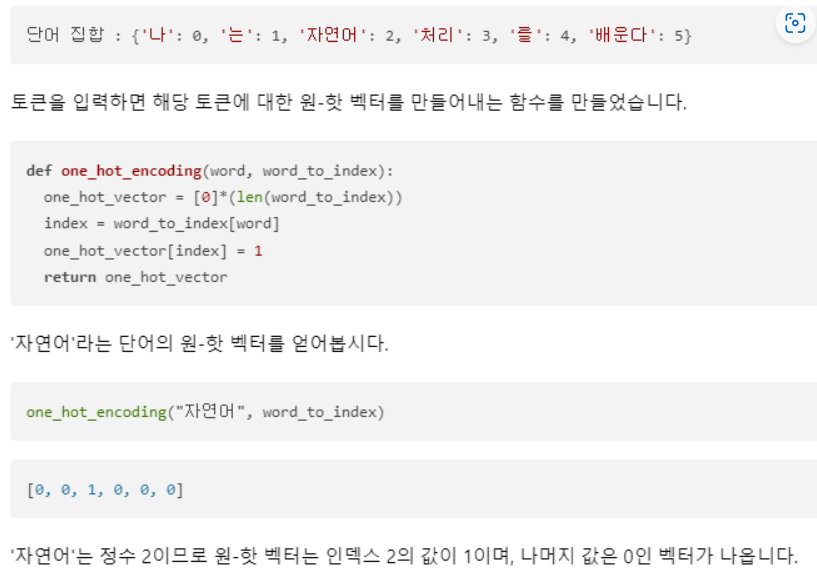
-
단점
- 단어 개수 늘어날수록 벡터 저장하기위한 공간이 계속 늘어남
- 단어의 유사도 표현 불가 ⇒ 단어의 잠재 의미를 반영하여 벡터화
-
카운트 기반 : LSA, HAL
-
예측 기반 : NNLM, RNNLM, Word2Vec, FastText
⇒ '카운트 기반' & ‘워드 임베딩 챕터’ 참고.
-
-
-
"패딩"
- 각 문장(또는 문서)별 길이를 동일하게 맞춰줌. 짧은 길이는 0으로 채워서 전부 동일한 길이로 맞춰준다
- keras : pad_sequences있음
-
-
-
정제(Cleaning) and 정규화(Normalization)
=> 토큰화 전후로 정제 및 정규화는 항상 함께한다
- 정제 : 노이즈 제거
- 아무 의미 안갖는 문자 제거 (특수문자)
- 목적에 맞지않는 불필요 단어 제거 : 빈도적은, 길이짧은 단어
- 단 한국어는 길이짧은 단어를 삭제하는건 유의미 하지 않을 수 있음
- 불용어 (Stopword)
- 영어 => nltk에서 불용어 사전이 정의되어 있어서 걍 쓰면 됨
- 한국어 => 개인이 임의 정의 : 코드에서 직접 정의하거나 txt나 csv로 정의 후 불러오는 식
- 코퍼스에서 노이즈의 특징을 정리 할 수 있다면 정규표현식을 잘 쓰게됨
- html 문서로부터 갖고왔다면 html 태그 제거
- 뉴스 기사 크롤링 했다면 기사마다 개제 시간 제거 등
- 정규화 : 표현 방법 다른 단어들을 하나로 만들어 준다
- 대소문자 통합
- 어간 추출(stemming), 표제어 추출(lemmatization)
- 표제어
- 기본 사전형 단어 라는 의미. am are is → be / running → run
- 영어 : nltk의 WordNetLemmatizer
- 어간추출 formalize → formal allowance → allow electricical → electric
- 표제어
- 정제 : 노이즈 제거
-
유용한 한국어 전처리 패키지
- PyKoSpacing
- 띄어쓰기 x 문장 ⇒ 띄어쓰기 o 문장
- 딥러닝 기반 모델임. 성능 준수
- Py-Hanspell
- 맞춤법 및 띄어쓰기 교정 (띄어쓰기 성능은 위 꺼가 더 좋음)
- 네이버 한글 맞춤법 검사기 바탕으로 만들어짐
- SOYNLP
- 한국어 단어 토큰화 해주는 아이인데 신조어나 형태소 분석기에 등록되지 않은 단어의 경우 제대로 구분 못해주었던 기존의 단점을 극복한 아이
- ㅋㅋㅋㅋㅋ ⇒ ㅋㅋ 이런식으로 반복되는 문자를 다 정규화 (통합화) 해버림
- Customized KoNLPy
- 토큰화 해줄때 경우에 따라 특정 단어 같은거는 뭐 형태소 구분안되도록 이런식으로 커스터마이징 해줄 수 있음
- PyKoSpacing

금융권에 가고싶은 김코다입니다. 취업을 하면 기타치며 조르바처럼 살고파요. -> 금융권 왔다. 취업도 했다. 그러나 여전히 조르바처럼..