해당 포스팅은 다음의 위키독스 (https://wikidocs.net/book/2155)를 읽고 정리한 개념임을 밝힙니다
-
언어 모델이란
-
‘단어 시퀀스’(문장)에 확률을 할당하는 것 : 가장 자연스러운 단어 시퀀스를 찾아내는 것
⇒ 이를 구현하는 가장 보편적 방법 : 이전 단어를 통해 다음 단어를 예측하기 -
언어 모델이 단어들의 조합이 얼마나 적절, 문장이 얼마나 적합한지를 알려주는 것
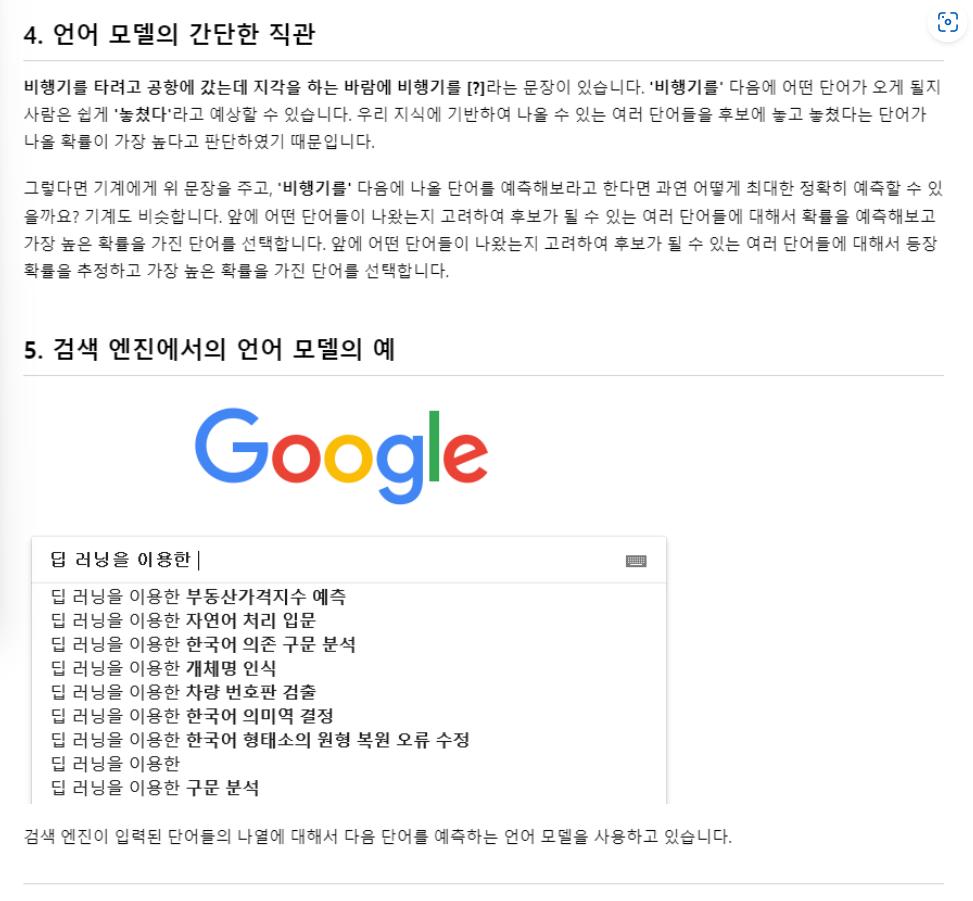
-
모델 생성 방법
- 통계 이용 방법 (SLM)
- 인공 신경망 방법 : GPT, BERT 등
-
-
N-gram
이것도 통계기반인 SLM의 일종이며 n 이란게 클수록 좋은게 아니다 (tradeoff)
얘도 인공 신경망을 이용한 언어 모델로 대체되었다 -
한국어에서의 언어 모델
-
한국어는 어순이 중요하지 않음
-
한국어는 교착어이다 (조사, 접사)
-
띄어쓰기가 제대로 지켜지지 않는다
⇒ 그래서 모델이 예측하기가 쉽지 않음
-
-
펄플렉서티(perplexity, PPL)
=> 언어 모델 간의 서로 성능 비교시, 모델 별 실제 작업 돌려보고 비교하는 건 시간낭비
테스트 데이터에 대해서 성능을 표현하는 빠른 공식이 '펄플렉서티'라고 보면됨.

금융권에 가고싶은 김코다입니다. 취업을 하면 기타치며 조르바처럼 살고파요. -> 금융권 왔다. 취업도 했다. 그러나 여전히 조르바처럼..