1. Consumer Group
consumer instance를 대표하는 그룹.
- consumer instance: 하나의 프로세스, 서버의 개념
- offset: partition 안에 데이터의 위치를 유니크한 숫자로 표시한 것. consumer는 자신이 어디까지 데이터를 가져갔는지 offset을 이용해서 관리함.
2. Consumer Group의 목적
2-1. 안전성 확보를 위해서
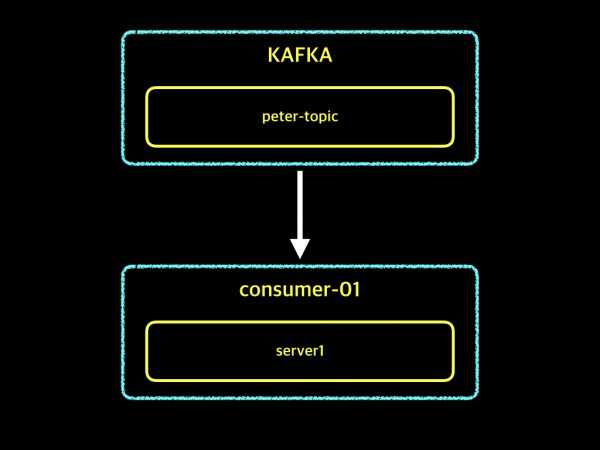
peter-topic의 데이터를 consumer-01 group이 가져가는 예시. server1에 장애가 발생한 경우, 데이터를 가져오는 작업이 중단됨.
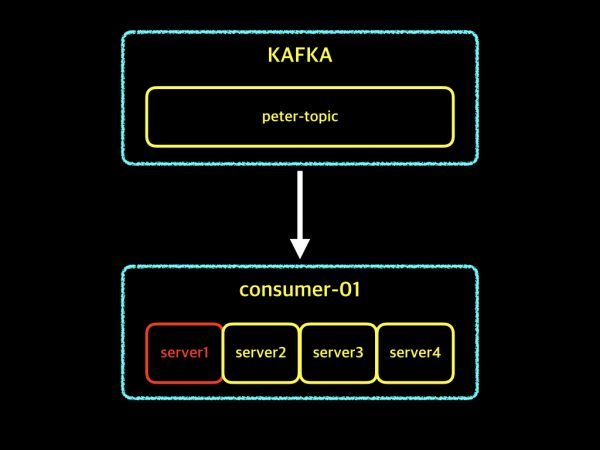
consumer group에서 4대의 server(consumer instance)를 가동한 경우? server1에 장애가 발생하더라도 나머지 3개의 server에서 작업을 이어나갈 수 있음.
2-2. 하나의 topic을 여러 consumer group이 독립적으로 소비 가능
consumer group들은 자신의 group에 대한 offset을 관리하기 때문에, 여러 consumer group들은 구분되어 독립적으로 topic을 소비할 수 있음.
consumer group이 없고, A, B 사용자가 데이터를 소비하려고 할 때.
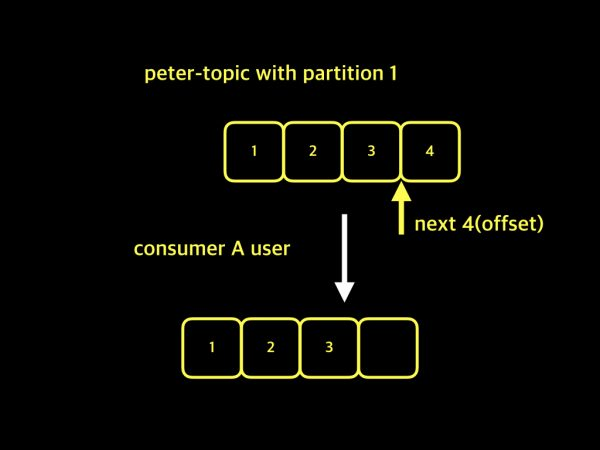
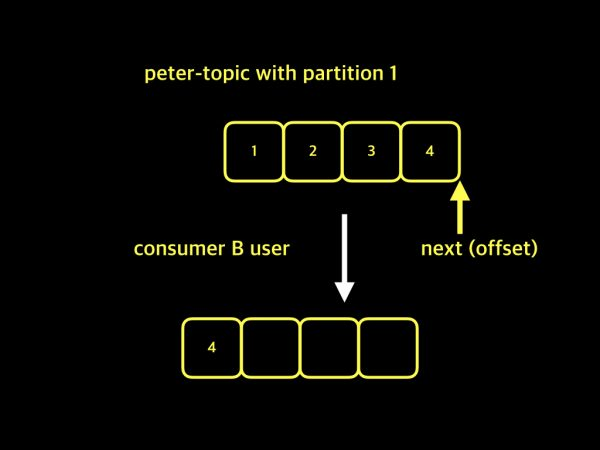
kafka에서는 consumer들을 구분할 수 없고, 또한 consumer들은 자신들만의 offset을 유지할 수 없음.
consumer group이 존재한다면,
consumer group으로 데이터를 소비할 주체를 분리하고, 각각의 consumer group이 offset을 관리하면, 동일한 topic을 여러 consumer group이 소비하더라도 서로 다른 offset을 가지고 데이터를 손실 없이 소비할 수 있다.
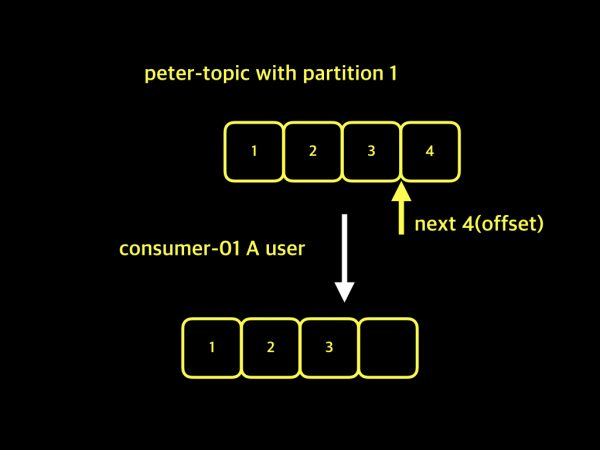
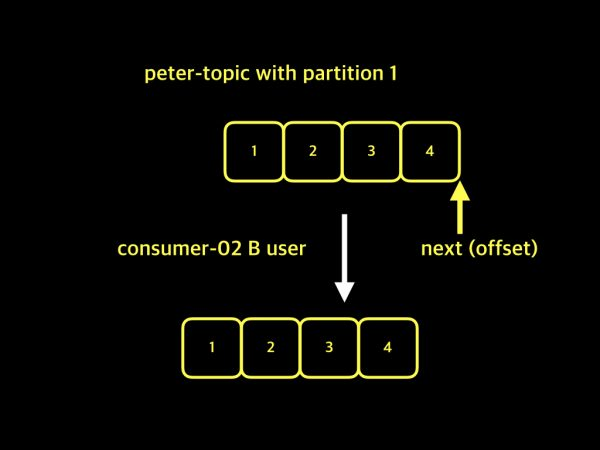
3. Consumer Group과 Partition 수의 관계
Kafka에서 제약사항: 하나의 partition에 대해 consumer group 내 하나의 consumer instance만 접근할 수 있다. -> partiton에 대해 하나의 reader만 허용함 -> partition 데이터의 읽기 순서를 보장함.
3-1.
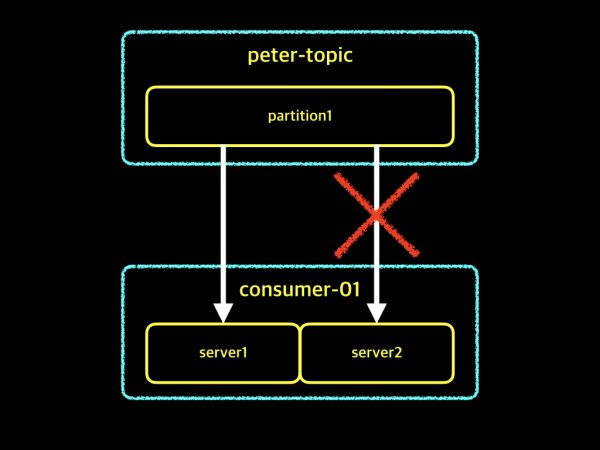
하나의 partiton으로 구성된 peter-topic, consumer-01 그룹에 두 개의 consumer instance가 존재. 하나의 partition은 consumer group 내부에서 하나의 consumer instance만 접근 가능함. 따라서 하나의 consumer instance는 대기중이고, 효율적인 상황은 아님.
3-2.partition 4개, consumer instance 2개
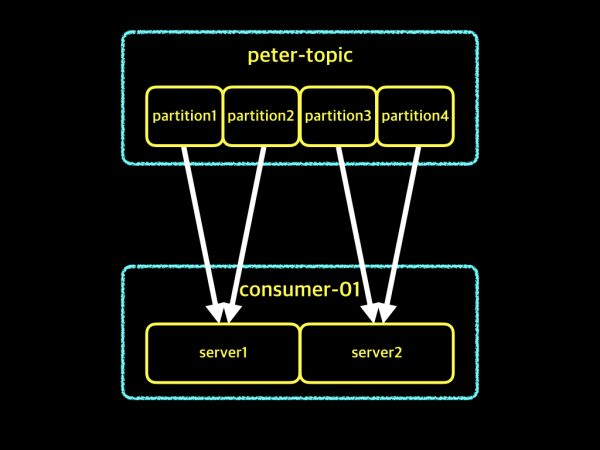
partition 수 > consumer instance 수 이기 때문에, 하나의 consumer instance에서 여러 개의 partition에 대한 가져오기를 수행함.
3-3.partition 4개, consumer instance 4개
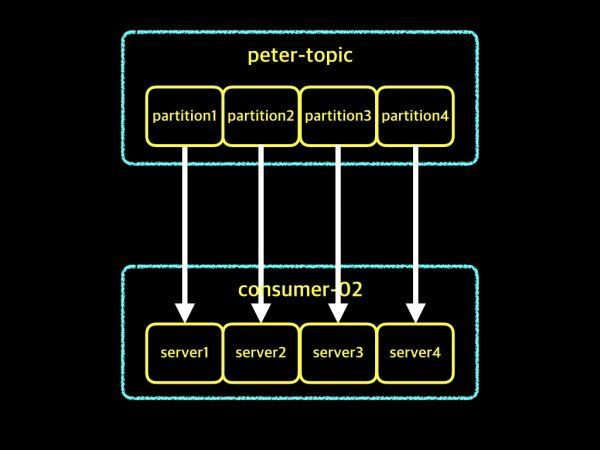
partition과 consumer instance가 1대1로 매칭됨. 3-2의 예시보다 데이터를 가져오는 속도가 2배 빠름.
topic의 partition 수가 많을 경우 그 만큼 consumer instance를 늘리면 데이터를 빠르게 가져올 수 있음. 하지만 topic의 partition 수는 늘릴 수만 있고 줄일 수는 없음. 따라서 일방적으로 partition 수를 늘리지 말고 사전 테스트를 통해 어느 정도 consumer instance 수를 유지했을 때 데이터를 가져오는데 밀리는 현상이 없는지를 찾아 해당 수 만큼의 partition을 만드는 것이 효율적.
3-4. 하나의 topic에 2개의 consumer group
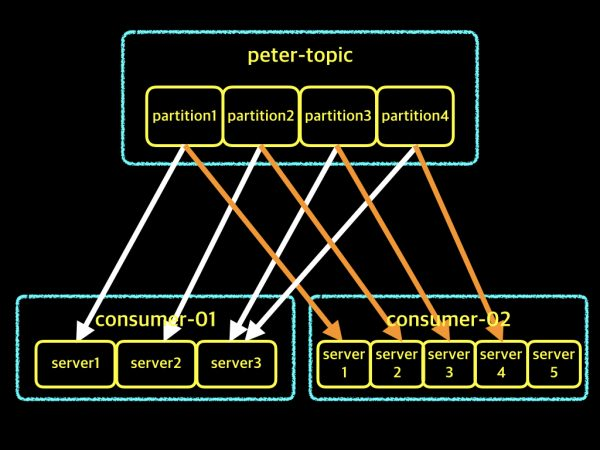
consumer-01과 consumer-02 group에서 똑같은 topic의 데이터를 독립적으로 가져올 수 있음.
출처
