Kafka
1.Apache Kafka란

1. Kafka란? > 여러 대의 분산 서버에서 대량의 데이터를 처리하는 분산 메세징 시스템. 메시지(데이터)를 받고, 받은 메시지를 다른 시스템이나 장치에 보내기 위해 사용됨. 2. Kafka의 특징 > 높은 데이터 처리량, 실시간으로 데이터 취급. 여러 서버
2.Kafka Producer, Consumer
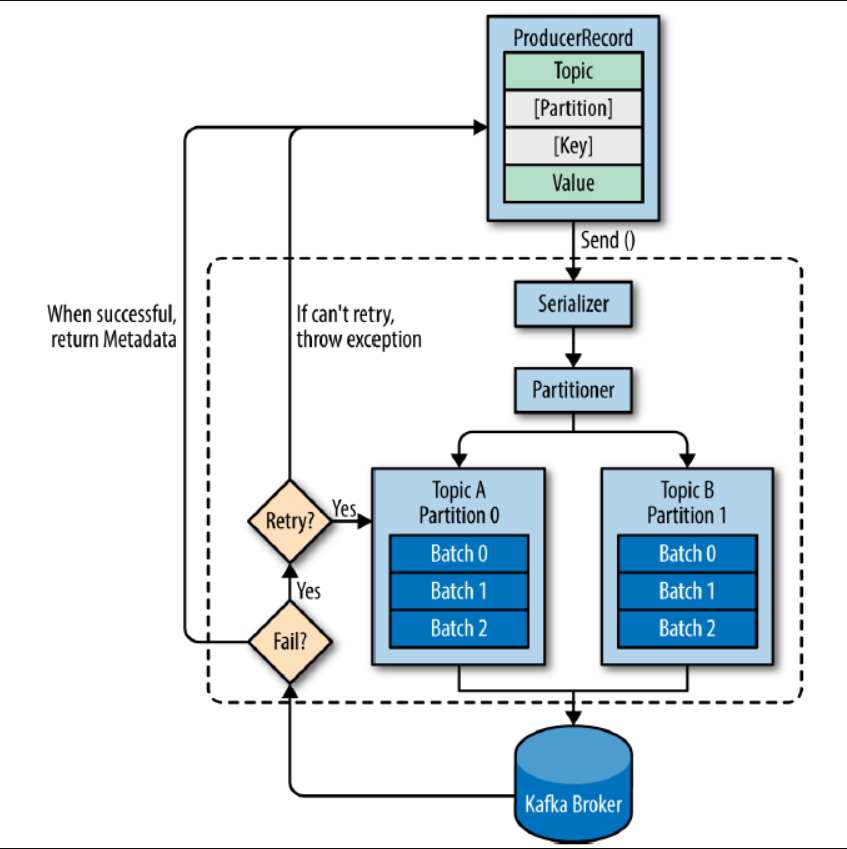
Kafka의 토픽으로 메시지를 전송함.ProducerRecord: Kafka로 전송하기 위한 실제 데이터. topic, partition, key, value로 구성.producer가 kafka로 record를 전송할 때, 특정 topic으로 메시지를 전송함.recor
3.Kafka에서 partition 수와 메시지 순서
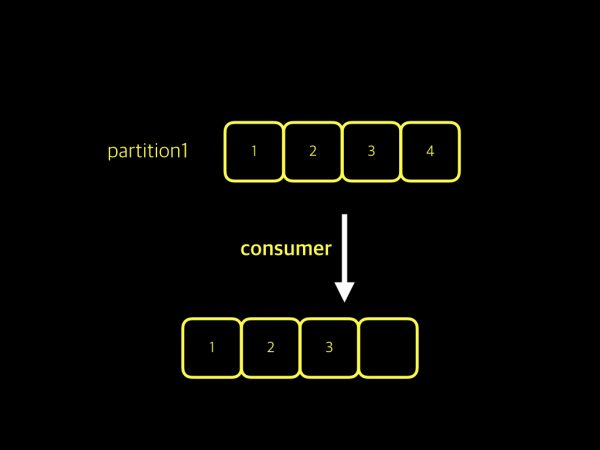
메시지를 순서대로 consume하는 것이 보장됨.topic에 대해 모든 데이터의 순서를 보장받고 싶다면, topic 생성 시 partition의 수를 1로 지정해야 함.consumer는 1 3 2 순으로 메시지를 가져왔음.consumer는 각각의 partition에서
4.Consumer Group
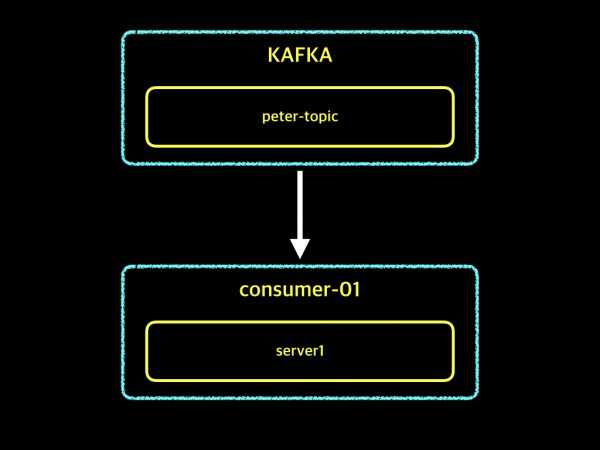
consumer instance를 대표하는 그룹.consumer instance: 하나의 프로세스, 서버의 개념offset: partition 안에 데이터의 위치를 유니크한 숫자로 표시한 것. consumer는 자신이 어디까지 데이터를 가져갔는지 offset을 이용해서
5.Kafka Zookeeper
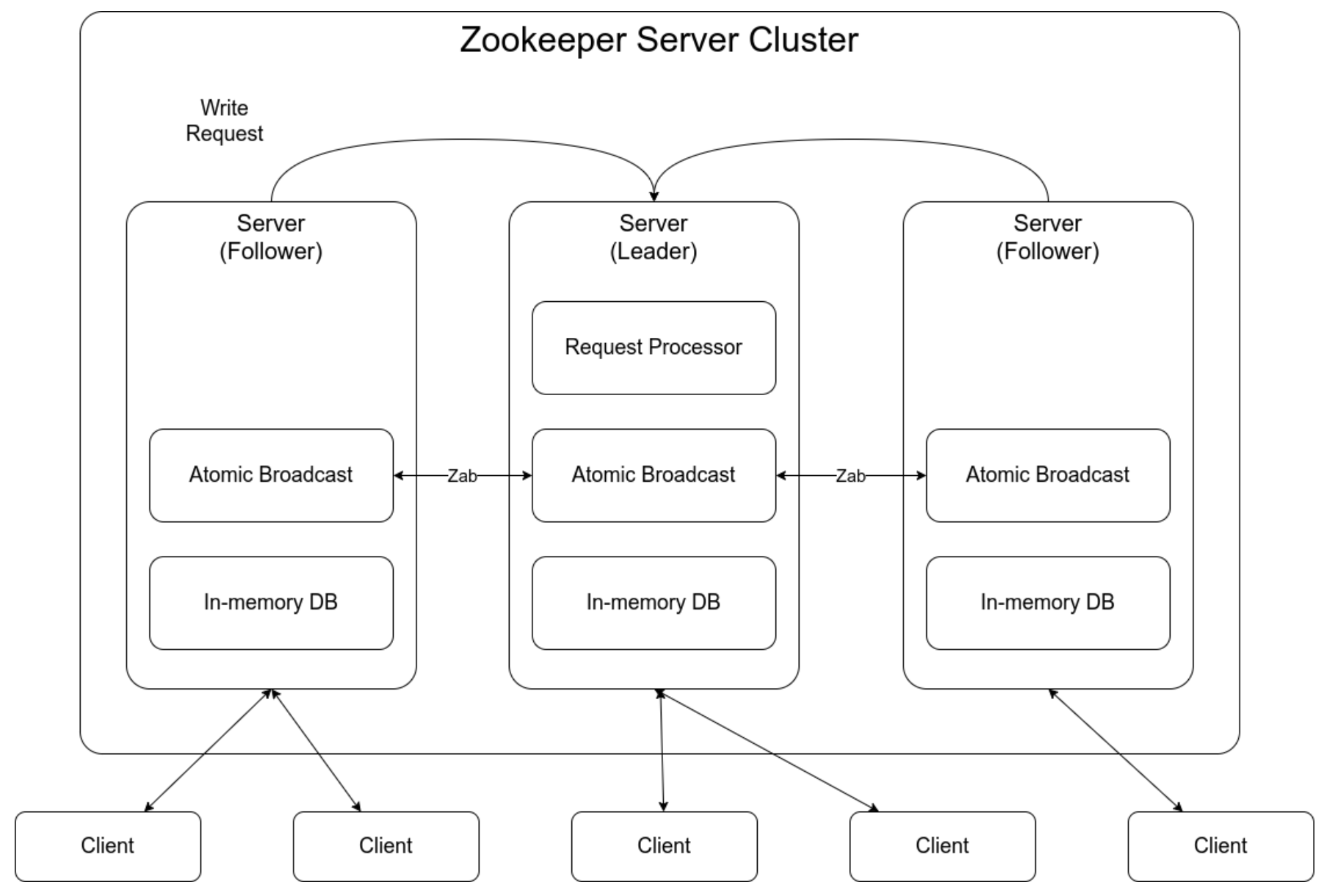
분산 처리 시스템에서 분산된 시스템들 간의 정보를 어떻게 공유할 것인가? 클러스터 시스템에서 하위 노드를 관리하기 위해서는각 하위 노드들의 HealthcheckLock Processing이 필요하다.이러한 문제를 해결하는 시스템이 coordination system이고
6.bootstrap.servers
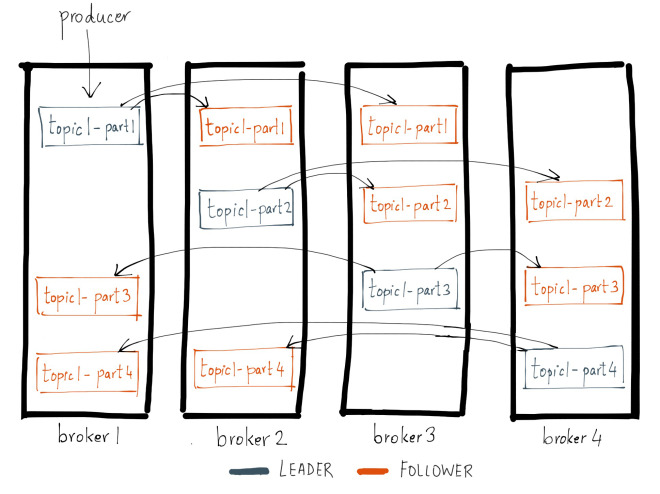
위 예시에서 kafka cluster는 4대의 broker로 구성되어 있고, 1개의 topic이 있다. topic은 여러 개의 partition으로 쪼개져 구성되어 있고, partition은 replication을 통해 복사되어 여러 broker에 분산되어 있다.위 그
7.Kafka 전달 보증
broker가 메시지를 수신했을 때, producer에게 수신 완료했다는 응답.consumer가 수신한 메시지를 정상 처리했다면 처리(수신) 완료 기록을 broker에게 보내는 것.Offset commit은 메시지를 받아 정상적으로 처리를 완료한 다음 offset을 업
8.Kafka 메시지 데이터 형태
kafka에서 취급하는 데이터 형태는 producer와 consumer에서 일치해야 한다.producer에서 송신되는 메시지의 key, value의 데이터 형태는 각각 producer 앱에서 지정되고, 데이터를 직렬화해서 송신함.consumer는 미리 producer에
9.Kafka Connect
kafka와 다른 시스템과의 데이터 연계에 사용되며, kafka에 데이터를 넣거나, kafka에서 데이터를 추출하는 과정을 간단히 하기 위해 만들어짐.producer와 consumer 양쪽 모두 구성할 수 있음.Kafka Connect와 다른 시스템을 연결하는 부분을
10.Schema Registry
kafka는 broker를 통해 producer와 consumer의 직접적인 관계를 끊음으로써 구조적인 결합도를 낮춤.하지만 직접적인 관계가 끊어짐에 따라 발생하는 이슈가 생김.producer는 어떤 consumer가 메시지를 가져갈지 모르고, 더 중요한 것은 cons
11.Kafka Streams
broker 외부에서 메시지가 생성되고, broker 외부로 읽어짐.메시지 파이프라인 구성은 producer와 consumer를 직접 개발하거나, kafka connect를 사용해서 source -> sink 형태로 구성할 수 있음.kafka 내부에서 메시지 파이프라인