1. 메타데이터가 필요한 이유
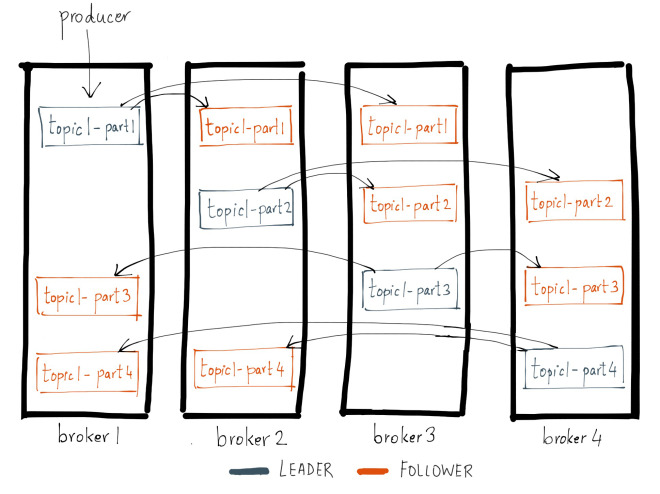
위 예시에서 kafka cluster는 4대의 broker로 구성되어 있고, 1개의 topic이 있다. topic은 여러 개의 partition으로 쪼개져 구성되어 있고, partition은 replication을 통해 복사되어 여러 broker에 분산되어 있다.
위 그림에서 알 수 있듯, 개별 broker는 cluster 전체 데이터를 가지고 있지 않다. 따라서 kafka client(producer, consumer)는 broker과 연결하여 broker 내부 자원에 접근하기 위해서, 접근하고자 하는 데이터의 위치를 알아야 한다.
그래서 kafka는 client가 처음 연결될 때, 데이터들의 메타데이터를 공유하기 위해 bootstrap.servers 설정을 요구한다.
2. bootstrap.servers
bootstrap.servers 설정은 client가 접근하는 topic의 메타데이터를 요청해서 원하는 broker를 찾기 위한 설정이다. 간단히 말해서, kafka broker의 list이다.
그렇다면 bootstrap.servers 설정에는 몇 개의 broker host를 등록해야 할까? 클러스터 운영 환경에 따라 다르지만, 너무 적게 입력하면 다른 broker가 멀쩡히 구동 중임에도 불구하고 설정에 등록한 너무 적은 수의 broker들이 중단된다면, client는 kafka 클러스터와 연결할 수 없게 된다.
client는 bootstrap.servers 설정에 입력된 broker host 정보를 이용하여 메타데이터를 요청한다.
메타데이터 요청 과정
- client가 broker와 연결
- 연결 성공 시, client에 등록된 모든 broker와 topic, partiton의 메타데이터 전송
- client는 메타데이터에서 topic partition의 위치(broker)를 찾음
- client는 해당 broker로 데이터 요청
producer, consumer, streams, connector 등 kafka와 연계된, 즉 broker 자원에 접근하는 모든 client는 공통적으로 bootstrap.servers 설정이 필요하다.
3. zookeeper vs bootstrap.servers
kafka consumer는 본인이 어디까지 메시지를 읽어왔는지 알기 위해서 kafka에게 offset을 보내고 받아와야 한다.
- kafka 구버전(0.9.0)에서는 모든 offset 관련 정보(partition offset)가 zookeeper에 저장되었다. 따라서 kafka client는 zookeeper와 kafka broker 둘 다 호출해야 했다.
- kafka 현재버전(0.10.0 이상)에서는 모든 topic 메타데이터(total partition, partition offset 등)가 kafka server의 __consumer_offset topic에 저장된다. 결과적으로 kafka broker만 zookeeper와 통신하면 되고, kafka consumer는 kafka broker를 통해서 메타데이터를 얻을 수 있다.
zookeeper: kafka와 통신하며 분산 시스템이 잘 작동하도록 관리함.
bootstrap.servers: client가 접근하는 topic을 가지고 있는 broker를 찾기 위한 메타데이터를 요청하기 위해 필요한 설정.
출처
https://velog.io/@pha2616/Apache-Kafka-bootstrap.server
https://stackoverflow.com/questions/46173003/bootstrap-server-vs-zookeeper-in-kafka
https://always-kimkim.tistory.com/entry/kafka101-configuration-bootstrap-servers
