K8S에서 GPU를 사용하는 JOB 수행하기
1.Overview
이전 글에서 K8S-Nvidia Plugin 설치를 통해 GPU를 파드에서 사용하고, 파드를 GPU 서버에 스케줄링 하는 방법을 알아봤습니다. 더 나아가 K8S에서 Job을 통해 학습을 시키고, Jupyter notebook을 파드로 실행하는 과정을 알아보겠습니다.
2. K8S Job 알아보기
쿠버네티스의 리소스 중 Job에대해 알아보겠습니다. Deployment의 경우 파드의 무조건적인 동작을 보장합니다. 파드의 오류가 발생할 경우 뿐 아니라 성공적으로 파드가 완료되어도 다시 재시작됩니다. 하지만 Job은 파드가 성공적으로 완료되면 더 이상 실행되지 않습니다. GPU를 사용해 학습을 시키기 위해서 Deployment로 수행 할경우 학습이 계속 실행되기 때문에 Job을 통해 test를 진행했습니다. 다음은 Job 예제 매니페스트입니다.
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4restartPolicy: Never/OnFailure - Job이 재시작하는 경우를 나타냅니다..spec.completions: 양수 - 완료 횟수를 지정합니다..spec.parallelism: 음수가 아닌 값 - 잡의 병렬 실행을 나타냅니다.backoffLimit: 양수 - 잡이 실패할 경우 재시도 하는 횟수를 나타냅니다..spec.activeDeadlineSeconds: 양수 - 잡이 완료되고 파드를 정리하는 초를 설정합니다.
잡이 완료된 후 파드의 로그와 에러 등 상태 확인을 위해 자동으로 삭제 되지 않습니다. 사용자가 직접 삭제를 하거나 .spec.activeDeadlineSeconds 설정을 통해 자동으로 삭제되도록 합니다. 설정된 초가 지나면 파드는 종료되고 잡의 상태는 reason: DeadlineExceeded 와 함께 type: Failed 가 됩니다.
3. 실행 환경
쿠버네티스 클러스터 환경은 다음과 같습니다.
- 211.214.88.174 (host206) —- Master node
- 211.214.88.172(host204) —- Worker node1
- 211.214.88.176 (v100) —- Worker node2
4.Job 실행시키기
Job을 실행시키기 위한 매니페스트 파일은 다음과 같습니다.
#pytorch-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pytorch-pod
spec:
ttlSecondsAfterFinished: 10
template:
spec:
containers:
- name: pytorch-container
image: pytorch/pytorch
command:
- "/bin/sh"
- "-c"
args:
- cd ./mnist && pwd && python3 main.py && echo "complete"
resources:
limits:
nvidia.com/gpu: 2
volumeMounts:
- name: examples
mountPath: /workspace
volumes:
- name: examples
hostPath:
path: /home/seokbin/examples
type: Directory
restartPolicy: OnFailurenvidia plugin을 통해 GPU 두개를 사용하도록 지정하였습니다. pytorch 이미지를 사용해 컨테이너를 생성하고 이후 볼륨으로 마운트된 파일로 이동해 mnist를 실행하는 구조 입니다. mnist 학습파일은 다음 github를 사용하였습니다.
kubectl apply -f pytorch-job.yaml 명령어를 통해 Job을 생성합니다.
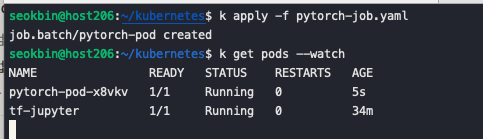
pod가 정상적으로 실행 중인 것을 확인 할 수 있습니다. kubectl logs -f pytorch-pod-x8vkv
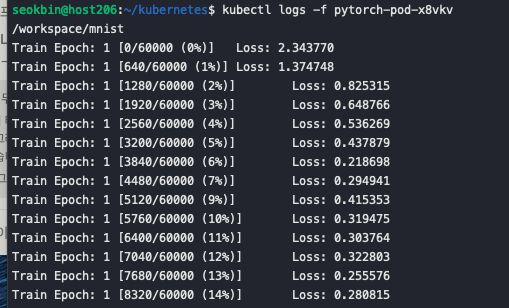
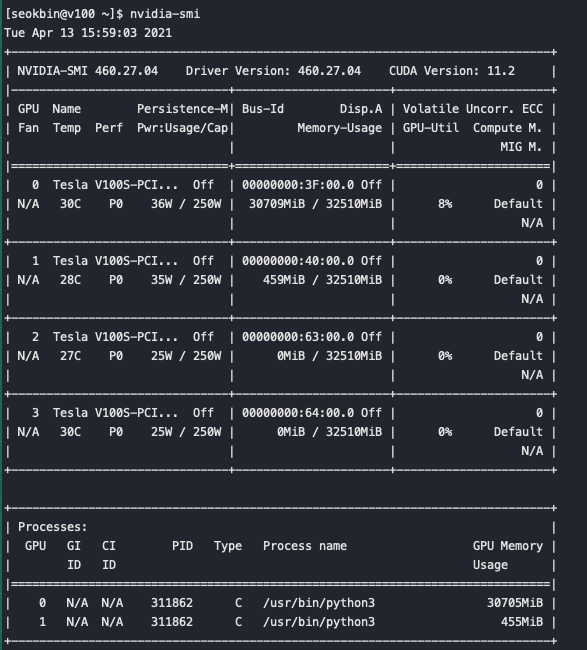
를 통해 학습이 진행 중인 것을 확인 합니다.또한 v100 서버에서 GPU 사용 현황을 확인했을 때 GPU 2대가 학습을 진행하고 있습니다.
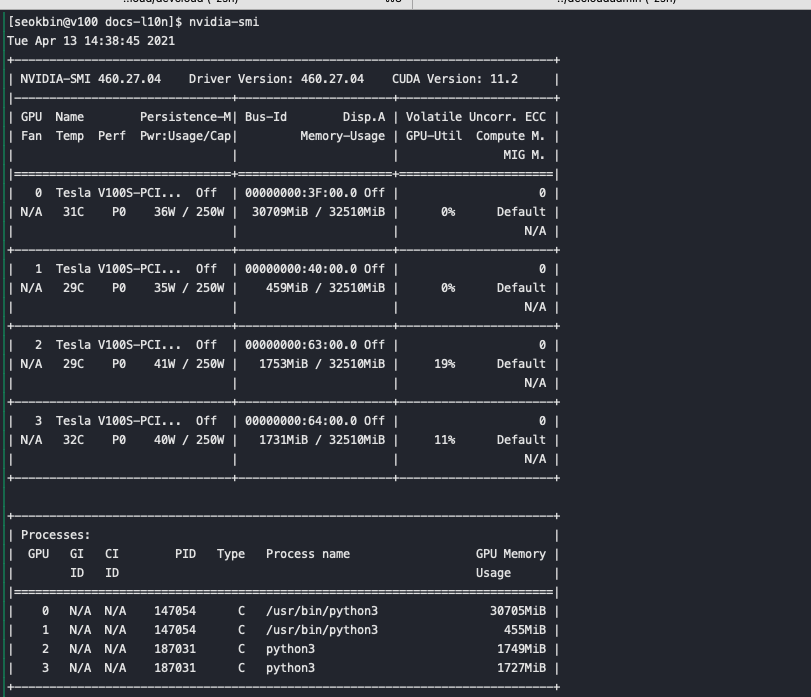
잡이 완료된 후 파드가 종료 되고 GPU 사용도 종료 된것을 확인 할 수 있습니다
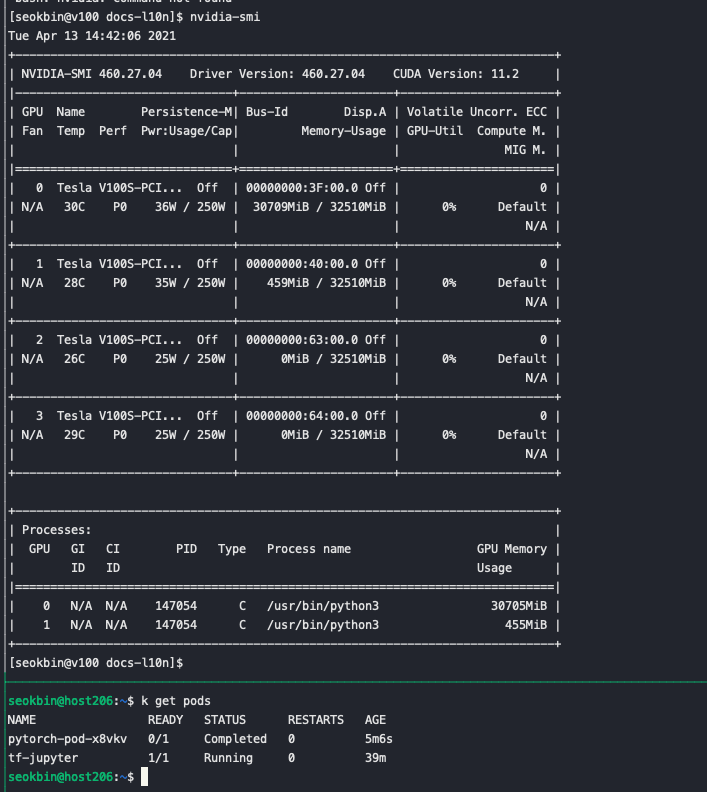
K8S Jupyter-notebook 실행시키기
사용자가 웹 브라우저를 통해 라이브 코딩을 수행 할 수 있는 Jupyter notebook을 파드로 생성해보겠습니다. Tensorflow 환경과 GPU 2개를 할당 해 코드 작업을 할 수 있도록 제공합니다. 쿠버네티스에서 생성된 파드를 외부에서 접속할 경우 서비스(네트워크) 작업이 필요합니다. 현재 할당 가능한 외부 IP가 없어 NodePort라는 서비스 타입을 통해 외부 접속을 허용해 보겠습니다.
-
Pod 생성
다음은 파드를 생성하는 매니페스트 입니다.
#jupyter-tf.yaml apiVersion: v1 kind: Pod metadata: name: tf-jupyter labels: app: jupyter spec: containers: - name: tf-juypter-container image: tensorflow/tensorflow:latest-gpu-jupyter volumeMounts: - mountPath: /notebooks name: host-volume resources: limits: nvidia.com/gpu: 2 # requesting 2 GPUs command: ["/bin/sh"] args: ["-c","jupyter notebook --no-browser --ip=0.0.0.0 --allow-root --NotebookApp.token= ","echo complete"] #args: ["-c","pip install --upgrade pip && pip install jupyterlab && jupyter lab --no-browser --ip=0.0.0.0 --allow-root --NotebookApp.token= ","echo complete"] #jupyter lab 실행할 경우 volumes: - name: host-volume hostPath: path: /home/seokbin/docs-l10n/ type: DirectoryOrCreatetensorflow에서 공식적으로 지원하는 jupyter 이미지를 사용해 컨테이너를 생성합니다. 이후 컨테이너에 접속해 노트북 명령어를 실행합니다(
args) . 해당 명령어는 notebook의 외부 접속을 허용하고 token인증을 일시적으로 해제합니다. 예제 코드는 다음 github 를 이용했습니다.k apply -f jupyter-tf.yaml를 통해 Pod를 생성합니다.
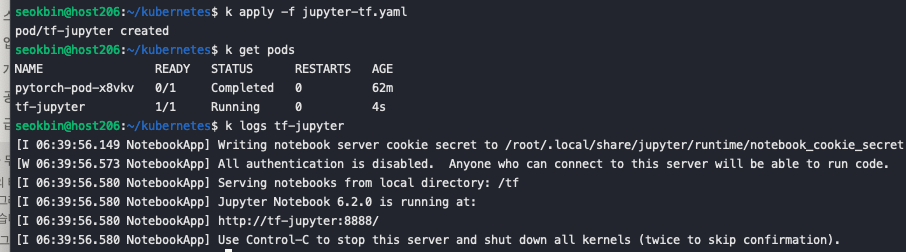
정상적으로 실행되었다면 다음과 비슷한 출력을 얻을 수 있습니다. -
Service 생성
NodePort를 생성하는 매니페스트입니다.
#jupyter-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: jupyter-svc
spec:
type: NodePort
selector:
app: jupyter
ports:
- protocol: TCP
port: 80
targetPort: 8888
nodePort: 30000위의 매니페스트로 생성된 서비스의 경우 selector를 기준으로 Pod와 연결합니다. Jupyter Pod에 동일하게 app:jupyter 로 연결했기 때문에 Jupyter 파드와 연동됩니다. nodePort 를 30000으로 설정합니다. 이를 통해 서버에 30000포트가 열리게됩니다. 사용자가 v100:30000 으로 접속하게 되면 Pod를 찾아 containerIP:8888 포워딩 됩니다.
kubectl apply -f jupyter-svc.yaml 명령어를 통해 서비스를 생성합니다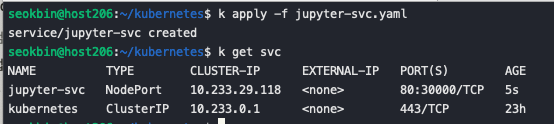 kubectl describe svc jupyter-svc 명령어를 통해 endpoinsts가 Jupyter Pod임을 확인 할 수 있습니다. IP와 Ports 는 서비스 자체의 ClusterIP와 포트를 의미합니다. 클러스터 내부에서만 접속이 가능합니다.
kubectl describe svc jupyter-svc 명령어를 통해 endpoinsts가 Jupyter Pod임을 확인 할 수 있습니다. IP와 Ports 는 서비스 자체의 ClusterIP와 포트를 의미합니다. 클러스터 내부에서만 접속이 가능합니다. 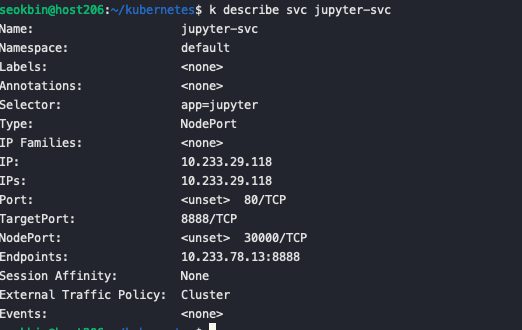 웹브라우저에서
웹브라우저에서 node ip:30000 로 접속하면 Jupyter notebook 화면은 확인 할 수 있습니다.
volume으로 마운트된 ipynb 파일을 실행시 GPU를 사용해 정상적으로 실행됩니다.