
1. Overview
쿠버네티스 기반 AI Platform 개발을 마치고 운영하던 도중 kube-apiserver의 메모리 사용량이 지속적으로 증가하면서 Master node가 down 되는 현상이 반복되었습니다. 문제를 해결하기 위해 시도한 내용을 기록합니다. 회사 보안 상 문제 화면을 외부로 가져오지 못해 비슷하게 구현해 본 글에서 보이는 그림은 정확하지 않을 수 있습니다. 현재 클러스터의 버전 정보는 다음과 같습니다.
- kubernetes - v1.18.16
- kube-apiserver,kube-scheduler,kube-proy - v1.18.16
- etcd - v3.4.3
- CoreDNS v1.6.7
- kubeflow v1.2
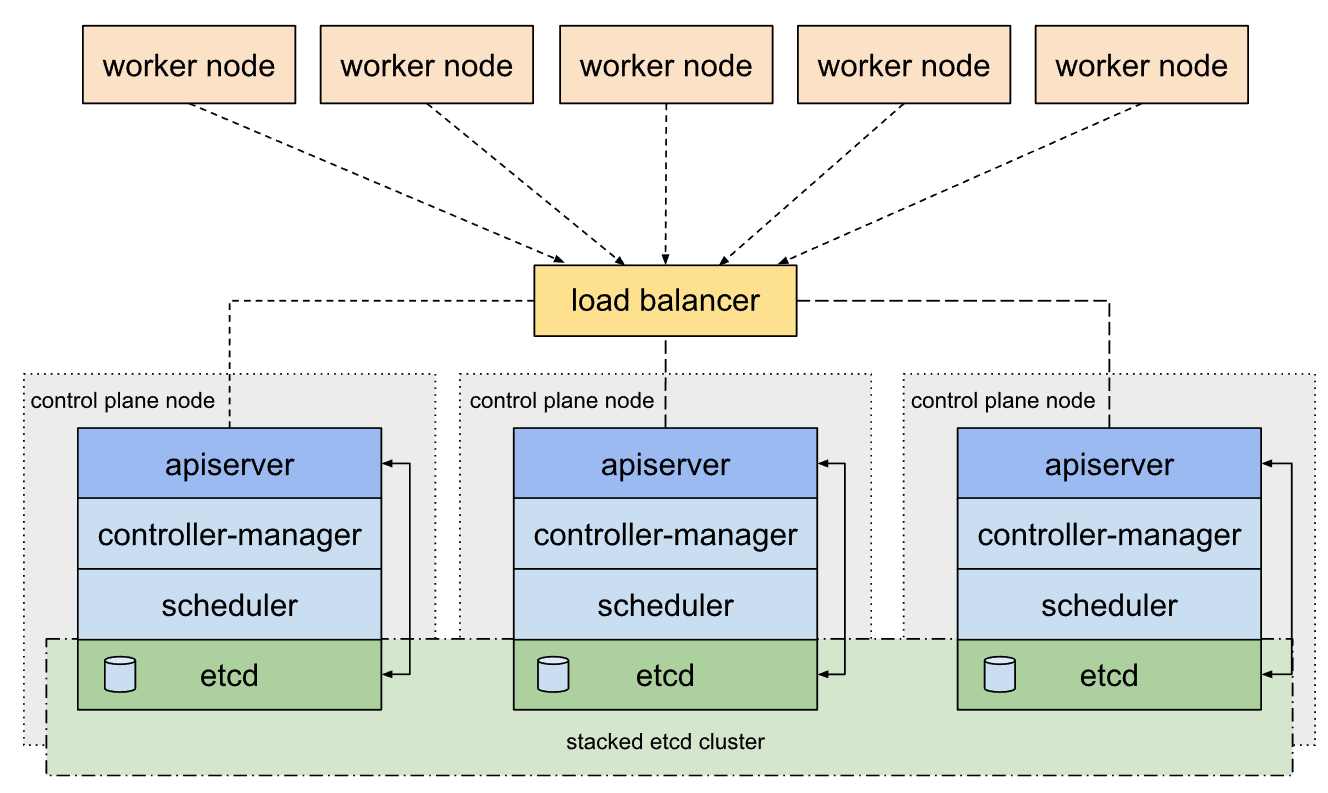
물리적인 구성은 Master Node 3대, Worker Node 3대로 구성되어있으며 Master Node 앞에 LoadBalancer를 배치에 kube-apiserver로 오는 request를 분산해서 받고 있는 HA 구성입니다. 현재 클러스터 규모는 약 800개의 Pod, 1000개의 Namespace를 가지고 있습니다.
2. 장애 상황 및 원인 파악
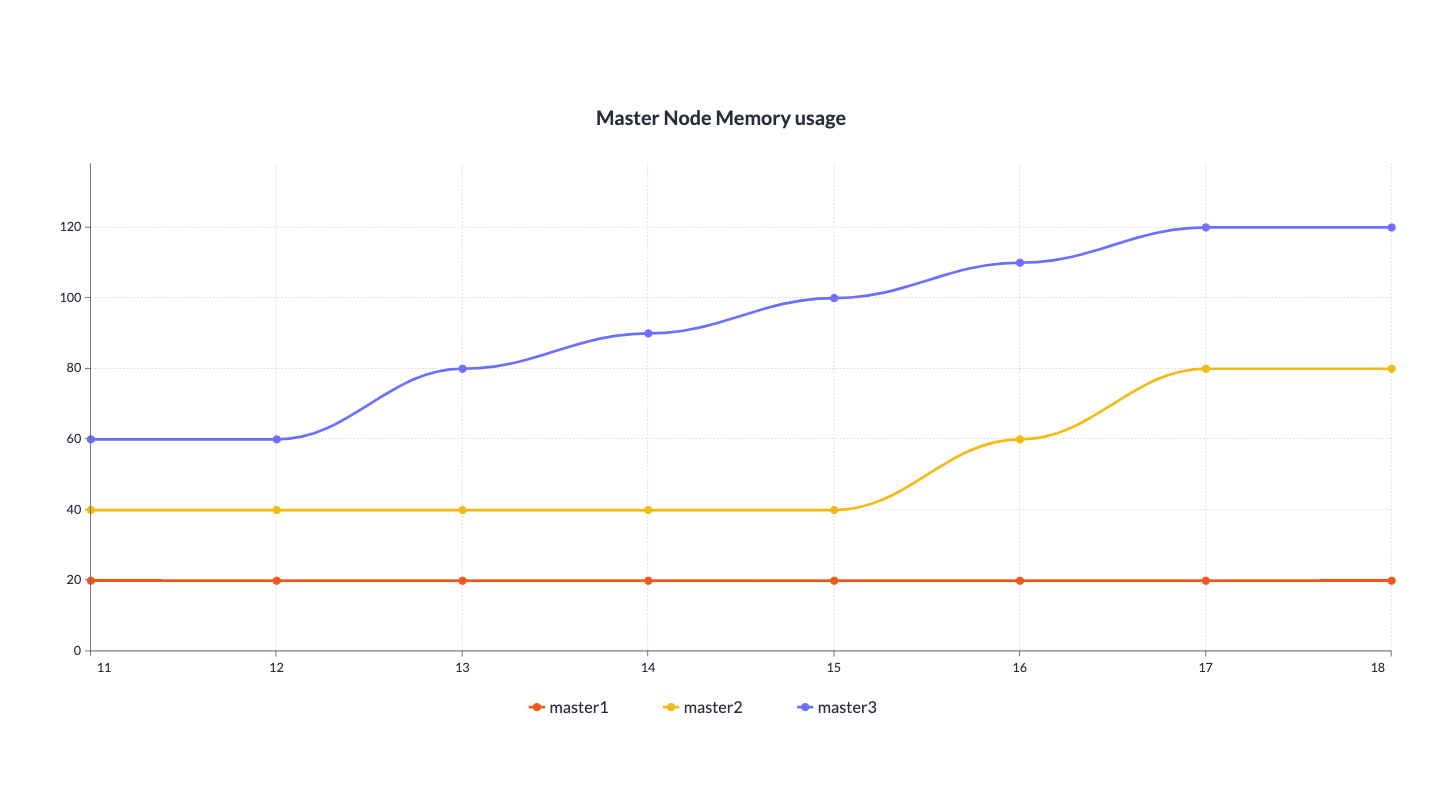
Prometheus로 모니터링 환경을 구축하였기 때문에 node 별 메모리 사용량을 확인해 보았습니다. 마스터 노드 한 개의 메모리 사용량이 지속적으로 증가하다가 120GB까지 오르게 되면서 OOM이 발생해 NotReady 상태가 됩니다. 임시적으로 kubelet을 재시작하면 메모리 사용량이 떨어지고 다른 마스터 노드가 다시 지속적으로 증가하게 되며 이러한 상황이 반복됩니다.
 kubectl top pod 명령어를 통해 파드 별 메모리 사용량을 확인 했을 때 증가하는 노드의 apiserver가 약 80%로 가장 높은 메모리를 사용하고 있고 그 다음 etcd가 높은 사용량을 차지해 두 파드에서 원인을 찾기 위해 노력하였고 다음과 같은 문제로 예상했습니다.
kubectl top pod 명령어를 통해 파드 별 메모리 사용량을 확인 했을 때 증가하는 노드의 apiserver가 약 80%로 가장 높은 메모리를 사용하고 있고 그 다음 etcd가 높은 사용량을 차지해 두 파드에서 원인을 찾기 위해 노력하였고 다음과 같은 문제로 예상했습니다.
1. ETCD DB size
ETCD DB 의 경우 초기 유력한 원인 중 하나였습니다. API server OOM 장애 직전에 DB가 초과되어 클러스터가 다운되었던 적이 있어 비슷한 이유일 것이라고 생각했습니다. 하지만 DB 사이즈를 2GB에서 8GB로 늘린 상황으로 여유로웠고 보통 2.1GB를 유지했습니다. 또한 revision제거, DB compact , defrag를 진행한 후 특별한 반응이 없었습니다.
2. Prometheus에서 api server로의 부하
Prometheus에서 수집하는 메트릭이 많아 부하를 줄 수 있을 거라 생각했습니다. Node exporter, blackbox exporter, DCGM exporter 등 메트릭을 발생시키는 exporter가 많고 이를 보통 15초 주기로 발생하고 수집하고 과도한 모니터링은 memory에 영향을 줄 수 있을거라 생각했습니다. 하지만 Prometheus 파드를 잠시 내리고 운영해도 메모리는 꾸준히 증가한 것을 확인했습니다.
3. kube-apiserver Memory leak bug
kube-apiserver 1.18.16 버전의 memory leak에 대한 이야기가 나와 upgrade를 고려했습니다. 하지만 현재 운영중인 서버에서 업그레이드로 인행 다른 파드의 영향을 예측 할 수 없어 실제로 진행하지는 못했습니다. 또한 1.18.16의 경우 port-forwd에 대한 memory leak이기 때문에 큰 영향은 없을거라 판단했습니다만 현재 1.19 버전까지 나왔기 때문에 향후 upgrade는 고려 해야할 거 같습니다. 아래내용은 1.18.18의 bug fix 내용입니다.
Bug or Regression
Fixed port-forward memory leak for long-running and heavily used connections. (#99839, @saschagrunert) [SIG API Machinery and Node]
4. dex application에서 과부하(유력)
현재 상황에서 가장 유력한 원인입니다. apiserver와 etcd에서 dex관련 오류 log를 확인 하였습니다. 플랫폼에서 사용자가 로그인을 할 때 dex에서 토큰이 발급되는데 이 토큰이 계속 쌓이고 있고 etcd DB에 저장되어있는 것을 확인했습니다. 이를 apiserver에 request를 요청하는 것으로 추정됩니다. 현재 25만개의 토큰이 저장되어있고 expire 되지 않고 있습니다. 이를 해결하기 위해 expire 정책을 설정하였으나 version이 낮아 적용이 안된 상황입니다. dex upgrde와 token을 직접 지우는 행위 또한 3번과 같이 다른 pod에 어떤 영향을 줄 수 있을지 정확하기 파악하기 힘들기 때문에 현재 수행하지 못하고 보류된 상황입니다.
5. Master Node resource 부족
현재 마스터노드가 설치된 VM의 메모리는 125GB로 리소스는 클러스터 사이즈에 충분합니다. 아래는 Openshift의 마스터 노드 구성 권장 사항으로 2000개의 파드를 운영할 때 16GB의 메모리를 추천합니다. 이를 통해 현재 규모의 클러스터를 운영할 때 필요한 물리적인 리소스부족은 아닐거라 판단했습니다.
In a highly available OpenShift Container Platform cluster with external etcd, a master host needs to meet the minimum requirements and have 1 CPU core and 1.5 GB of memory for each 1000 pods. Therefore, the recommended size of a master host in an OpenShift Container Platform cluster of 2000 pods is the minimum requirements of 2 CPU cores and 16 GB of RAM, plus 2 CPU cores and 3 GB of RAM, totaling 4 CPU cores and 19 GB of RAM.
6. Load Balancer 정상 작동 확인
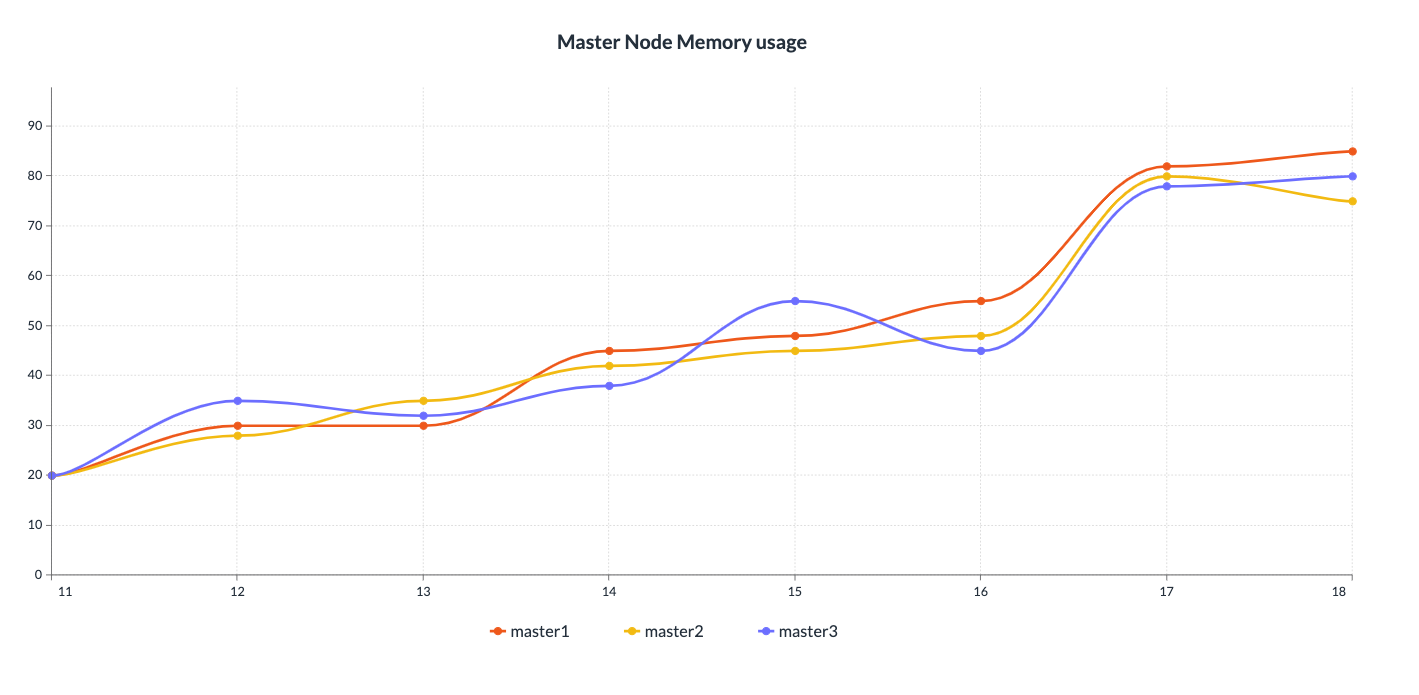
마스터 노드 앞에 LB가 배치되어있기 때문에 마스터 노드 1개만 지속적으로 증가하는 추세는 잘못됬다고 판단했습니다. apiserver가 과부하가 걸려 메모리 사용량이 많아져도 세개가 비슷하게 증가해서 사용하는 그래프가 올바른 그림이라고 생각했습니다. 실제로 아래의 그래프처럼 3개의 마스터노드가 비슷하게 사용하는 순간을 확인할 수 있었습니다. 하지만 인프라팀에서는 LB의 정상동작은 확인하고 정상동작 한다고 가정하여도 Memory사용량이 비이상적이게 높기 때문에 내부에서 원인 파악을 진행하였습니다.
3. 해결 방법
1. ETCD DB size compact
-
1-1 ETCDCTL 설치
우선 ETCD를 관리하기 위한 CLI tool인 ETCDCTL을 설치 해야합니다. 현재 클러스터에서는 etcd가 pod로 설치되어있기 때문에 파드안에서만 etcdctl을 사용할 수 있습니다. 이를 외부에서 사용할 수 있도록 etcdctl을 설치하는 과정입니다. 우선 파드안에서 버전을 확인합니다.

ETCD_VER=v3.5.0 wget https://storage.googleapis.com/etcd/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz tar xzvf etcd-${ETCD_VER}-linux-amd64.tar.gz mv etcd-${ETCD_VER}-linux-amd64/etcdctl /usr/local/bin/etcdctl etcdctl --version rm -rf etcd-${ETCD_VER}-linux-amd64/ rm -f etcd-${ETCD_VER}-linux-amd64.tar.gzetcdctl 설치가 정상적으로 돼었을 경우 help 화면이 나옵니다. 하지만
etcdctl member list명령어를 수행할 경우context deadline exceed에러가 발생합니다 . 이는 etcd가 secured 모드로 되어있어 인증과정이 필요합니다. bashrc에 alias로 다음과 같은 내용을 설정하였습니다.
alis etcdctl='etcdctl --endpoints=https://[ip]:2379,https://[ip]:2379,https://[ip]:2379 \\
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt \
--key=/etc/kubernetes/pki/etcd/healthcheck-client.key 이후 다시 수행했을 때 다음과 같이 정상적으로 명령어가 수행되었습니다.
-
1-2 ETCDCTL Compact
ETCD는 kubernetes config, pod의 상태 등의 대부분의 정보를 key-value 값으로 저장되는 데이터베이스입니다. 그렇기 때문에 안정적인 유지를 위해 주기적인 keyspace 관리가 필요합니다. 그러한 방법으로 revision을 제거하는 comapct, defrag 방법이 있습니다. revision이란 key-value 값이 변경 된 history를 말합니다. value 값이 변경 될 때마다 revision이 증가 하게 되는데 이에 대한 관리가 없다면 etcd storage가 full 상태가 될 것입니다
key value revision foo bar 1 foo bar1 2 foo bar2 3 etcdctl compact [revision-number]을 통해 compact를 진행할 수 있으며 etcd 에서 auto compaction을 설정할 수 있습니다.compact를 진행하기전 DB 사이즈를 확인합니다. 다음 명령어를 통해 current revision을 확인 합니다.이후 compact를 통해 revision을 제거 하였습니다. 하지만 compact이후 DB 사이즈의 변화가 없습니다. defrag을 진행하여 DB 공간을 확보 해야합니다. etcdctl defrag DB size가 커서 context deadline exceeded 에러가 발생했습니다 이는 timeout 옵션을 길게 주어서 해결하였습니다.
다음 명령어를 통해 current revision을 확인 합니다.이후 compact를 통해 revision을 제거 하였습니다. 하지만 compact이후 DB 사이즈의 변화가 없습니다. defrag을 진행하여 DB 공간을 확보 해야합니다. etcdctl defrag DB size가 커서 context deadline exceeded 에러가 발생했습니다 이는 timeout 옵션을 길게 주어서 해결하였습니다.c_revision=$(etcdctl endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9].*') echo ${c_revision}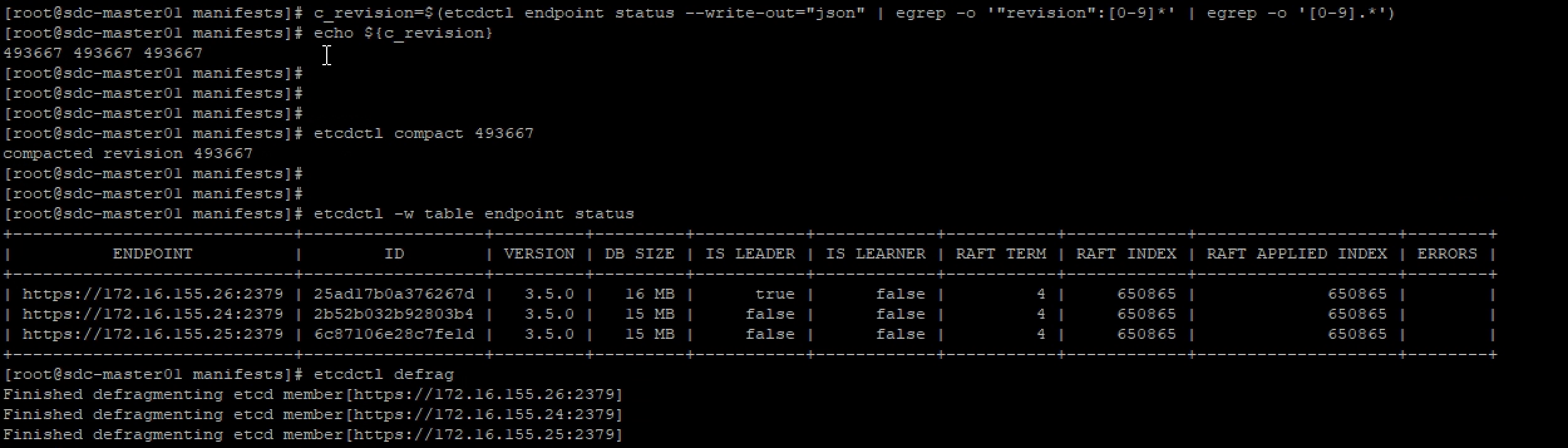
 이후 DB 사이즈를 확인하니 줄어드는 모습을 볼 수 있었습니다. 실제 클러스터에서는 2.1GB 에서 1.5GB로 줄어들었습니다.하지만 곧바로 다시 DB사이즈가 2.1GB까지 증가하는 모습을 확인 할 수 있었습니다. 이는 DB 공간을 확보해도 계속 dex에서 etcd로 request를 날려서 이 방법은 해결책이 될 수 없을거라 판단했습니다.
이후 DB 사이즈를 확인하니 줄어드는 모습을 볼 수 있었습니다. 실제 클러스터에서는 2.1GB 에서 1.5GB로 줄어들었습니다.하지만 곧바로 다시 DB사이즈가 2.1GB까지 증가하는 모습을 확인 할 수 있었습니다. 이는 DB 공간을 확보해도 계속 dex에서 etcd로 request를 날려서 이 방법은 해결책이 될 수 없을거라 판단했습니다. -
1-3 auto compact
etcd v3.3.0 이상부터 auto compact 모드가 두가지로 지원됩니다. 주기적으로 compact를 지정하는 periodic(default) 모드와 revision 모드가 지원됩니다.revision mode의 경우
--auto-compaction-mode=revision과--auto-compaction-retention=1000과 같이 revision 양을 지정합니다. 5분만다 마지막 revision - 1000만큼 compact 가 지정됩니다.periodic mode의 경우
--auto-compaction-mode=periodic과--auto-compaction-retention=72h의 경우 10으로 나눈값인 7.2h 마다 compact를 진행합니다.이를 설정하기 위해 etcd.yaml 파일에 설정합니다.
#1h 마다 compact 진행
#spec.containers.command.etcd
- --auto-compaction-retention=10h2. ETCD Monitoring 구성
초기 Prometheus 모니터링 시스템을 설치 하면서 kube-state-metric을 구성하며 기본 설정으로 설치 하며 control plane에 대한 세부적 내용은 확인 할 수 없었습니다. 그 중 Etcd에 대한 모니터링 페이지가 필요하다고 생각해 이에 대한 내용을 설정하였습니다.
-
2-1 etcd metric setting
etcd의 경우 기본적으로 prometheus 형식으로 metrics을 발생시킵니다.클러스터에서 ETCD는 Static Pod로 생성되기 때문에 etcd.yaml에서 metric port에 대한 내용을 확인할 수 있었습니다. 이후 해당 주소로 조회시 metrics을 확인 할 수 있었습니다. 기존에 설정되어있는 127.0.0.1(liveness probe에서 이를 참조하기 때문에 내용을 지우면 해당 부분도 같이 수정해야합니다) 과 Prometheus pod 내부에서 접속 할 수 있도록 외부 ip 주소를 설정합니다.#etcd.yaml spec: containers: - etcd - --listen-metrics-urls=http://127.0.0.1:2381,http://172.16.155.24:2381/metrics 이후 위에서 설정한 주소 조회 할 경우 다음과 같이 Prometheus 형식으로 메트릭이 발생하는 것을 확인 할 수 있습니다. 이후 Prometheus에서 접근하기 위해 Endpoint, Service를 생성합니다.
이후 위에서 설정한 주소 조회 할 경우 다음과 같이 Prometheus 형식으로 메트릭이 발생하는 것을 확인 할 수 있습니다. 이후 Prometheus에서 접근하기 위해 Endpoint, Service를 생성합니다.apiVersion: v1 kind: Endpoints metadata: name: etcd-metrics namespace: monitoring labels: app: etcd-metrics subsets: - addresses: - ip: 172.16.155.24 - ip: 172.16.155.25 - ip: 172.16.155.26 ports: - name: etcd-metrics port: 2381 --- apiVersion: v1 kind: Service metadata: namespace: monitoring name: etcd-metrics labels: app: etcd-metrics spec: type: ClusterIP ports: - name: etcd-metrics port: 2381 targetPort: 2381Kube-prometheus에서 Prometheus target을 추가하기 위해 Servicemonitor를 생성합니다.
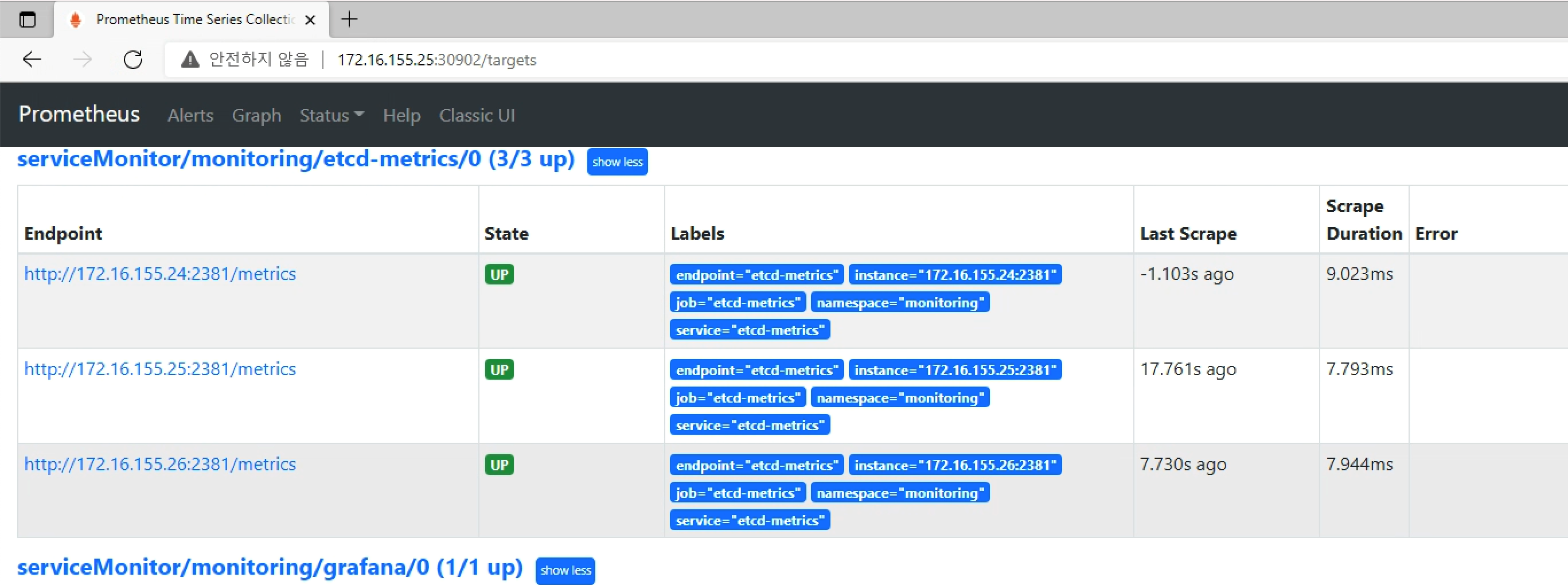
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: etcd-metrics namespace: monitoring labels: k8s-app: etcd-metrics spec: endpoints: - interval: 30s port: etcd-metrics selector: matchLabels: app: etcd-metrics성공적으로 설정이 완료되면 Prometheus→Status→Target 화면에서 다음과 같이 Metrics이 수집되고 있는 것을 확인 할 수 있습니다.
3. K8S audit log
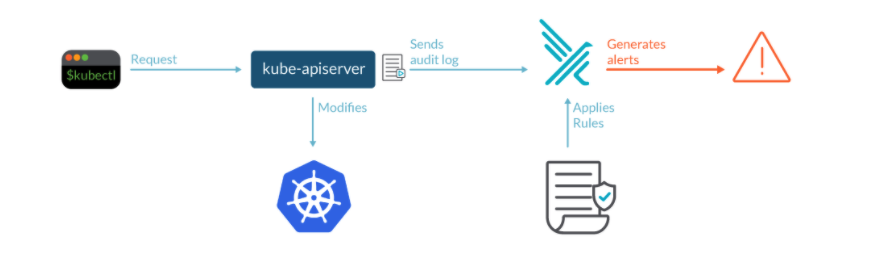
kubernetes에서는 audit이라는 기능을 제공합니다. kube-apiserver는 HTTP 통신을 통해서 이루어지는데 이에 대한 세부적은 로그를 확인하기 위해서 사용합니다. log Level이나 기록하는 시점 또한 설정할 수 있습니다. 아래 메니페스트는 공식 사이트에 있는 예제 중 일부를 가져온 내용입니다.audit 으로 알 수 있는 정보는 다음과 같습니다.
-
What happend : 어떤 새로운 파드가 생성되었나
-
who did it : 누가 이벤트를 발생시켰나(user,user group, service account)
-
When did it happend: Event Timestamp
-
where did it occure: namespace
 다음과 같이 audit 로그를 발생시키면서 기록하는 시점을 설정할 수 있습니다. 또한 클러스터에서 발생하는 활동을 전부 기록하는것은 무리가 있으므로 resource에 따른 level을 적절히 설정해야합니다.
다음과 같이 audit 로그를 발생시키면서 기록하는 시점을 설정할 수 있습니다. 또한 클러스터에서 발생하는 활동을 전부 기록하는것은 무리가 있으므로 resource에 따른 level을 적절히 설정해야합니다. -
RequestReceived: audit handler 처리 없이 event가 발생하자마자 기록 -
ResponseStarted: Response header가 보내진 후 (body는 보내기 전) 주로 watch 같은오래 걸리는 request에서 사용 -
ResponseComplete: response body를 보낸 후 -
Panic: panic이 발 생하였을 때 기록apiVersion: audit.k8s.io/v1 kind: Policy # RequestReceived stage에 대한 기록 제외. omitStages: - "RequestReceived" rules: # RequestResponse level: metadata,request,response body 포함 - level: RequestResponse resources: - group: "" resources: ["pods"] # Log "pods/log", "pods/status" at Metadata level # Metadata level: requesting user, timestamp, resource, verb, etc - level: Metadata resources: - group: "" resources: ["pods/log", "pods/status"]위와 같이 정책을 설정 하고 해당 파일을 참조할 수 있도록 apiserver에 적용합니다.
#kube-apiserver.yaml - --audit-policy-file=/etc/kubernetes/audit-policy.yaml - --audit-log-path=/var/log/containers/audit/audit.log --audit-log-maxsize=100m . . . volumeMounts: - mountPath: /etc/kubernetes/audit-policy.yaml name: audit readOnly: true - mountPath: /var/log/containers/audit/ name: audit-log readOnly: false . . . volumes: - hostPath: path: /etc/kubernetes/audit-policy.yaml type: File name: audit - hostPath: path: /var/log/containers/audit/ type: DirectoryOrCreate name: audit-log정상적으로 yaml파일이 수정되면 apiserver가 재시작되면서 audit에 적용됩니다. 다음과 같이 log 파일을 확인 할 수 있습니다.
 기본 설정으로 audit을 설정하였으나 이에 대한 세부적인 정책이나 Falco같은 audit log tool과의 연동도 고려를 해야할 거 같습니다. 이에 대한 자세한 설정은 향후 테스트를 진행해보도록 하겠습니다.
기본 설정으로 audit을 설정하였으나 이에 대한 세부적인 정책이나 Falco같은 audit log tool과의 연동도 고려를 해야할 거 같습니다. 이에 대한 자세한 설정은 향후 테스트를 진행해보도록 하겠습니다.
향후 계획
현재 Apiserver에서 발생하는 OOM을 해결하고 결과적으로 보았을 때 원인은 dex가 맞았습니다. kubeflow 설치 시 기본 인증 방법으로 dex를 사용하게 되는데 사용자들이 로그인 하는 과정에서 token을 발급하게 됩니다. 이를 kubernetes configmap으로 생성하는데 이에 대한 관리가 제대로 되어있지 않았습니다. 이 토큰이 끊임 없이 생기면서 부하를 받는 거였습니다. dex 파드 내에서도 이러한 문제 방지를 위해 자체적인 Garbage Collector가 존재하였으나 제대로 동작하지 않아서 생긴는 문제였습니다. 이 부분의 코드를 수정해 문제를 해결 할 수 있었습니다. 문제 해결을 시도하며 kubernetes, kubeflow의 버전이 낮아 upgrade의 필요성을 느꼈습니다. 이를 위해 향후 현재 버전의 클러스터를 구성해 순차적으로 upgrade를 진행하며 현재 운영하는 서비스에 영향을 끼치는지 확인이 필요할 거 같습니다. 또한 logging Archetecture를 고민해봐야 될 거 같습니다.
