앞선 글에서 트랜잭션이 무엇이고 왜 이용해야하는지에 대해서 예시를 통해서 살펴보았습니다.(이전 글 보기 : Transaction은-무엇일까) 트랜잭션은 DB의 논리적인 작업 단위를 나타내는 것이고 데이터의 일관성을 유지하기 위해서 이용한다는 것을 알 수 있었습니다. 이번 글에서는 트랜잭션의 특징과 트랜잭션의 격리 수준에 대해서 알아보겠습니다.
트랜잭션의 특징
트랜잰션의 특징은 4가지로 ACID라고 불리웁니다.
- 원자성 (Atomicity) : 원자성은 트랜잭의 작업 결과가 데이터베이스에 모두 반영되거나 반영되지 않는 것을 의미합니다.
- 일관성 (consistency) : 모든 트랜잭션의 작업 처리 결과가 항상 일관성이 있어야 한다는 것을 의미합니다.
- 독립성 (Isonation) : 여러 트랜잭션이 실행될 때 어떤 하나의 트랜잭션이 다른 트랜잭션 연산에 끼어들 수 없다는 것을 의미합니다.
- 영구성 (Durability) : 트랜잭션이 성공적으로 완료가 된 경우 결과가 영구적으로 반영되어야 한다는 것을 의미합니다.
트랜잭션의 격리 수준
트랜잭션의 격리 수준은 여러 트랜잭션이 실행될 때 작업 내용을 어떻게 보여주고 차단할 것인지를 결정하는 것입니다. 트랜잭션의 격리 수준에는 4가지로 구분됩니다.
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ
- SERIALIZABLE
격리 수준이 SERIALIZABLE에 가까워 질 수록 트랜잭션 간 격리 수준이 높아져 일반적으로 동시 처리 성능이 떨어집니다. 트랜잭션 격리 수준에 따라서 발생할 수 있는 부정합의 문제가 있는데 이는 Dirty Read, Non-Repeatable read, phantom read가 있습니다. 트랜잭션 각 단계에 알아보기에 앞서서 먼저 세 가지의 부정합 문제에 대해서 알아보겠습니다.
💡데이터 부정합 문제인 Dirty Read, Repeatable Read, Phantom Read 란?
Dirty Read : 한 트랜잭션에서 변경된 작업이 커밋되지 않는 상태에서 다른 트랜잭션이 이 변경 사항에 접근할 수 있는 문제
Repeatable Read : 한 트랜잭션에서 조회가 여러번 발생할 때 그 결과가 일정하지 않는 문제
Phantom Read : Repeatable Read의 한 종류로 반복되는 조회에서 데이터의 개수가 일정하지 않는 문제(데이터가 추가되어 있거나 사라져 있는 상태)
트랜잭션의 격리 수준에 대해 정리하기에 앞서서 앞으로 설명시에 이용되는 테이블은 이름과 잔액정보를 가지고 있는 계좌 테이블을 기준으로 설명하겠습니다. (현재 데이터는 (사람1, 10000)만 존재하는 상항입니다.)
| name | money |
|---|---|
| 사람1 | 10000 |
Read Uncommitted
read Uncommitted는 트랜잭션간의 격리가 가장 적은 단계로 각 트랜잭션의 변경 내용이 커밋 혹은 롤백 여부에 상관없이 다른 트랜잭션에서 보인다는 특징을 가지고 있습니다. 그 예시를 통해서 알아보겠습니다.
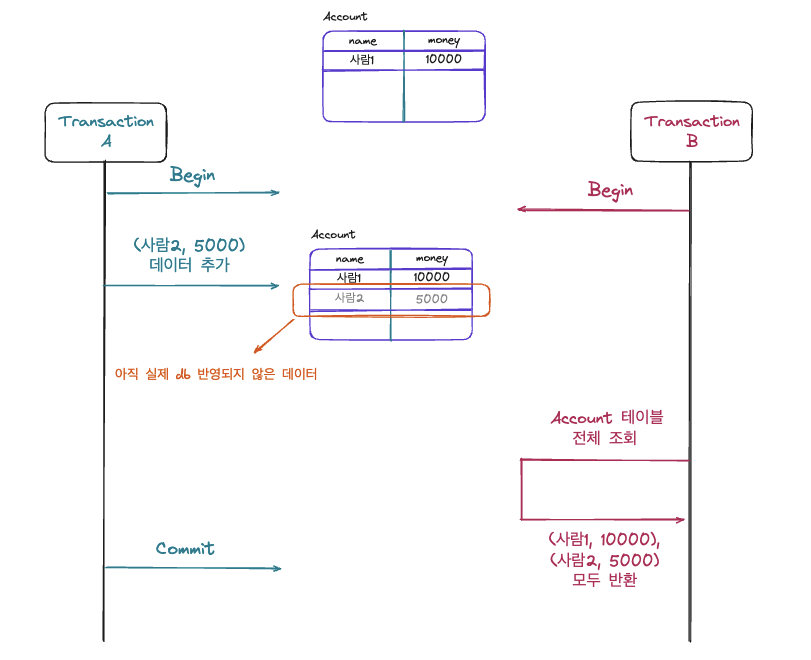
Account 테이블에 Transcation A와 Transaction B가 접근한 상황으로 Transaction A가 Account 테이블에 새로운 데이터 (사람2, 5000)을 추가하고 아직 커밋을 하지 않은 상태입니다. 이후 Transaction B가 Account 테이블의 모든 데이터를 조회를 했고 이 때 (사람1, 10000) 데이터만 조회되는 것이 아닌 아직 커밋되지 않은 (사람2, 5000)이 모두 조회되었습니다. 즉, Transaction B가 Transaction A의 변경작업까지 접근한 상황이 발생한 것입니다.
이렇듯 Transaction B가 아직 커밋되지 않은 변경사항에 접근이 가능하기에 Dirty Read가 발생한 것을 알 수 있습니다. 또한 만약 아래의 그림과 같이 Transaction B의 조회과정이 Transaction A 작업 과정 이전에 발생하는 경우가 추가된다면 다른 문제를 발생시킬 수 있습니다.
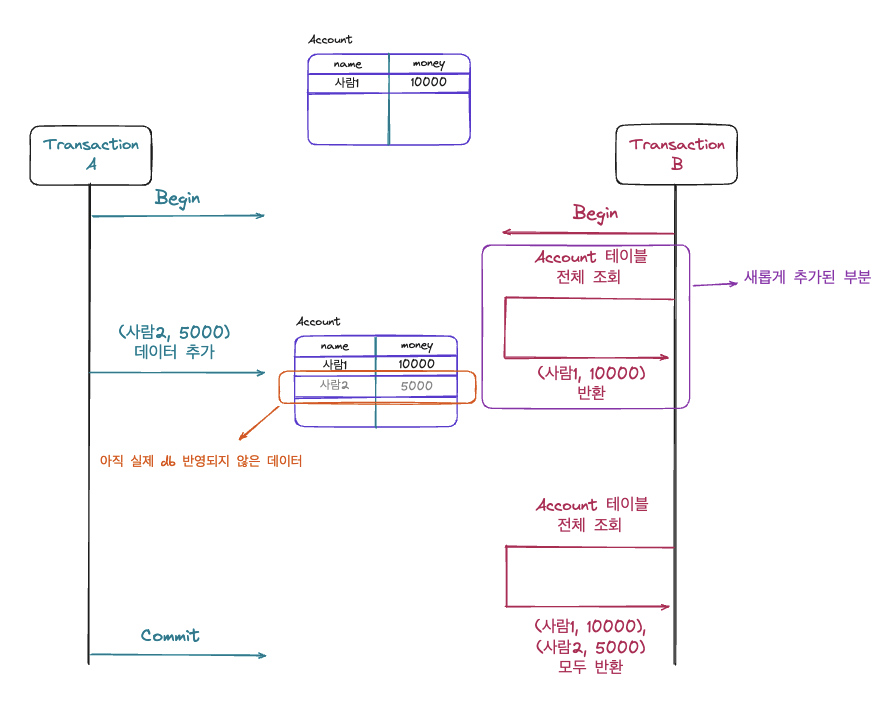
새롭게 추가된 부분을 보면 Transaction A 작업 전에 Account 테이블을 조회하는 경우 (사람1, 10000) 데이터만 조회되는 상황이 발생합니다. 즉, Transaction B의 경우 조회를 두번 진행했지만 그 때마다 결과값이 다르기 때문에 Non-Repeatable Read 문제가 발생하는 것을 알 수 있습니다. 또한 Transaction B 기준으로 두 번째 조회 과정이 발생할 때에는 갑자기 새로운 데이터가 조회되는 것이기에 Phantom read가 발생하는 것을 알 수 있습니다. 이렇듯 Read Uncommited는 Dirty Read, Non-repeatable Read, Phantom Read가 모두 발생하는 것을 알 수 있습니다.
Read Committed
Read Committed는 하나의 트랜잭션에서 발생한 변경사항이 커밋이 된 이후에야 다른 트랜잭션들이 그 변경사항에 접근이 가능한 격리 수준입니다. 그렇기에 기본적으로 Read Uncommitted에서 발생하는 Dirty Read는 발생하지 않습니다. 또한 이름 그대로 커밋된 정보들을 읽어오는 것이기에 큰 문제가 없는 것처럼 느껴지기도 합니다. 예시를 통해서 Read Committed가 어떻게 동작하는지 알아봅시다.
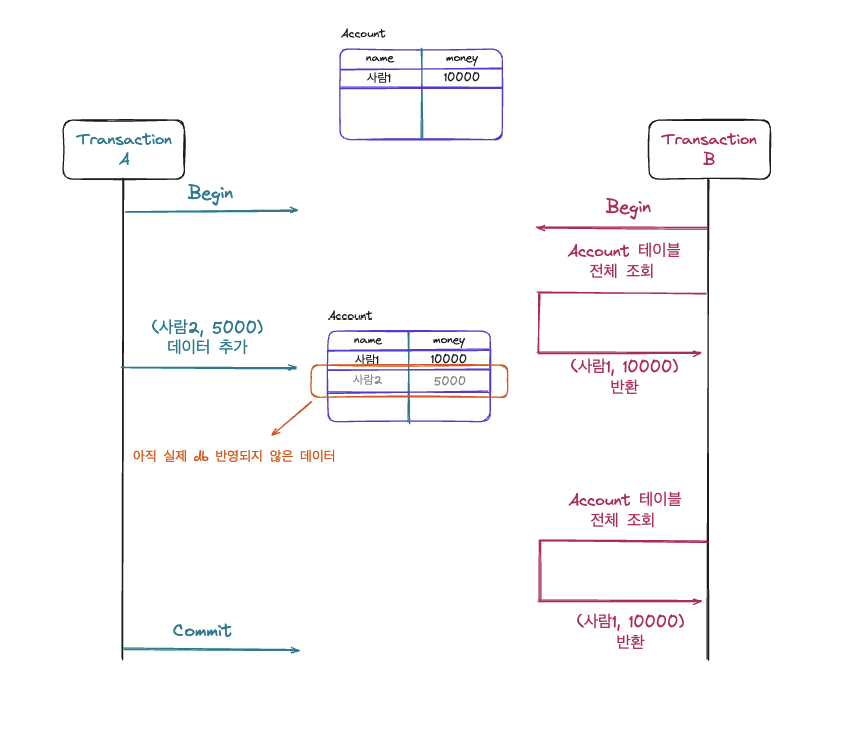
예시는 앞선 Read UnCommitted에서 설명한 예시와 같은 상황이지만 Transaction A의 변경작업이 커밋이 되지 않아 Transaction B가 반복적으로 Account 테이블을 조회하더라도 조회결과가 변화되지 않아서 큰 문제가 없는 것처럼 보이지만 문제의 시작은 Transaction A가 커밋 후에 발생합니다.
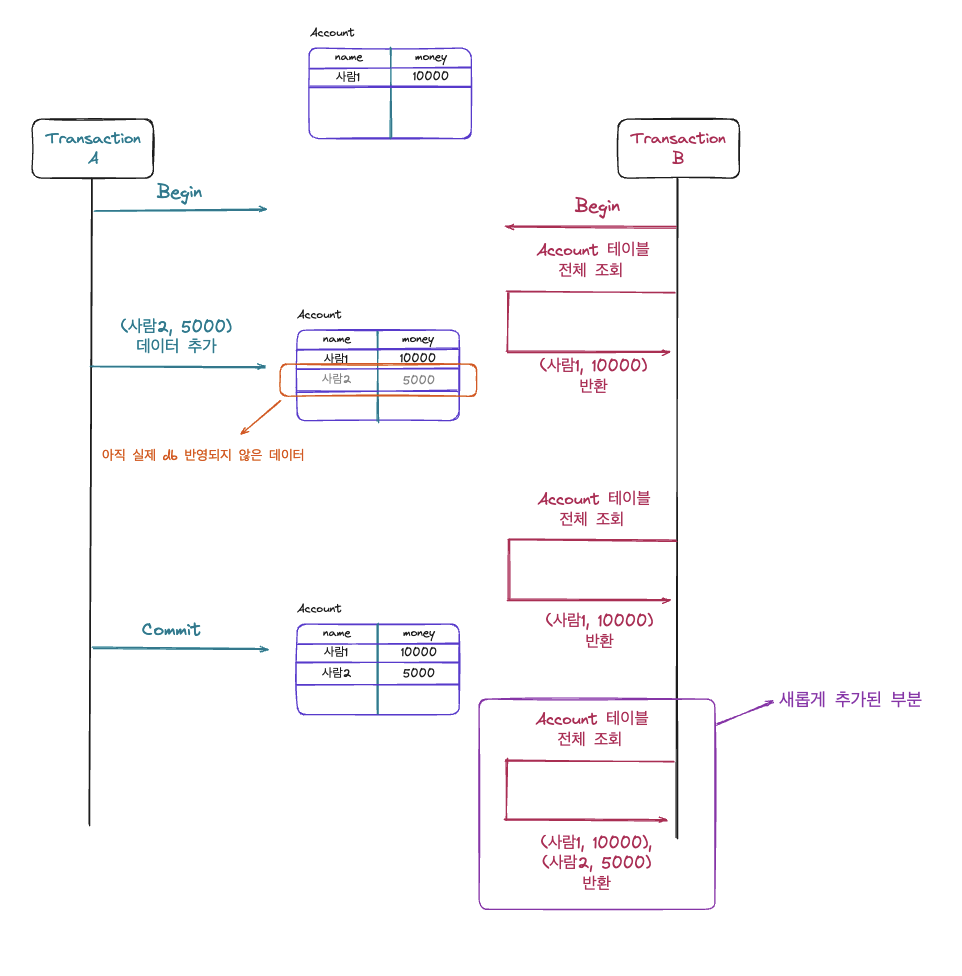
Transaction A가 종료된 이후에 Transaction B에서 Account 테이블을 조회하는 경우 (사람1, 10000), (사람2, 5000) 데이터가 모두 조회됩니다.(Transaction A가 변경사항을 커밋했기 때문) 따라서 Read Committed의 단계에서는 Dirty Read는 발생하지 않았지만 중간에 다른 트랜잭션에서 변경사항을 커밋을 하는 경우 결국 반복적인 조회 과정에서 조회 결과가 일정하지 않는 Non-repeatable Read와 Phantom Read가 발생합니다.
Repeatable Read
Repeatable Read의 격리 단계는 MySQL에서 기본으로 채택하고 있는 격리 수준으로 Non-repeatable Read가 발생하지 않는다는 특징을 가지고 있습니다. 그 이유는 InnoDB 스토리지 엔진의 경우 트랜잭션이 rollback 될 수 있는 가능성에 대비해서 undo 영역에 이전버전에 대한 정보(레코드)들을 담아두고 데이터를 불러오기 때문입니다. 간단하게 예시로 보면 좋을 것 같습니다. 이번에는 데이터를 변경하는 상황을 예시로 보겠습니다.
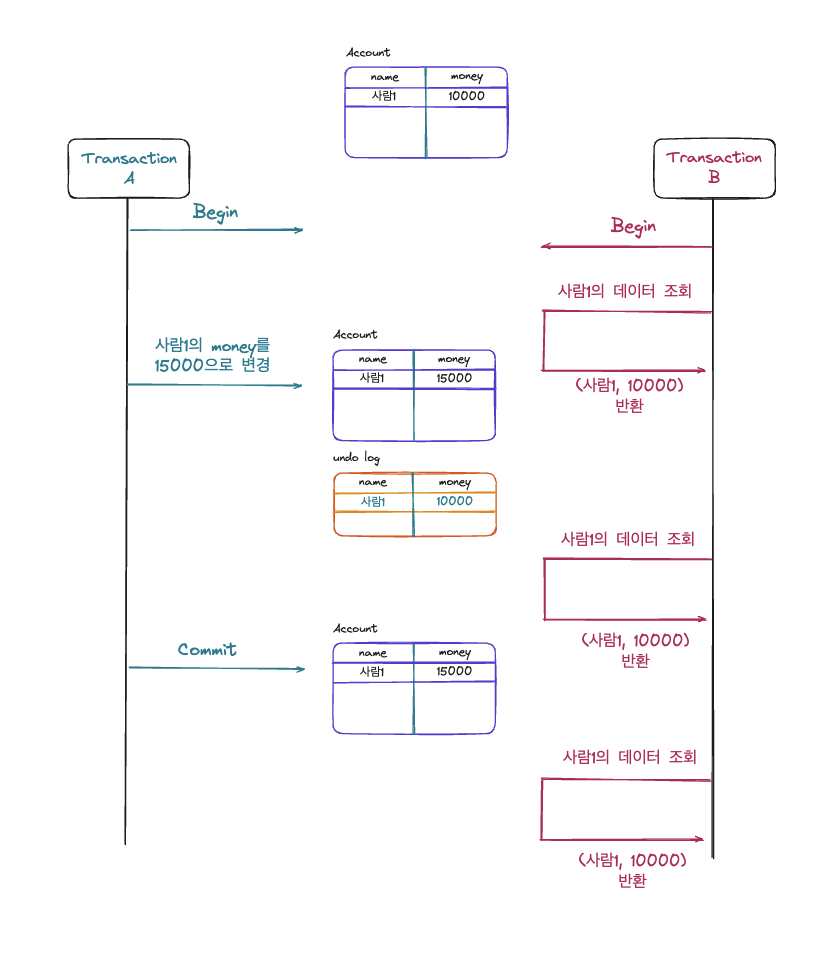
TransactionA에서 사람1의 money를 15000으로 변경하는 요청을 보내고 이를 commit한 상황입니다. TransactioB의 경우 사람1의 데이터 요청을 TransactionA가 요청을 보내기 전, 보내고 commit 되기전 commit이 된 후 총 3번의 요청을 보낼 때마다 모두 같은 결과인 (사람1, 10000) 받아옵니다. 그 이유는 Repeatable read 격리 수준에서는 transaction이 시작된 시점의 undo log를 보면서 데이터를 읽어오기 때문에 다른 트랜잭션에서 데이터를 변경한 후 commit을 하더라도 일관된 읽기가 가능해 Non-Repeatable read가 발생하지 않습니다. 그러면 우리는 이제 Phantom Read에 대한 여부를 확인해봐야 하는데요? 결론부터 말하면 특수한 상황에서 Phatom Read가 발생합니다. 이는 그림과 함께 살펴보겠습니다.
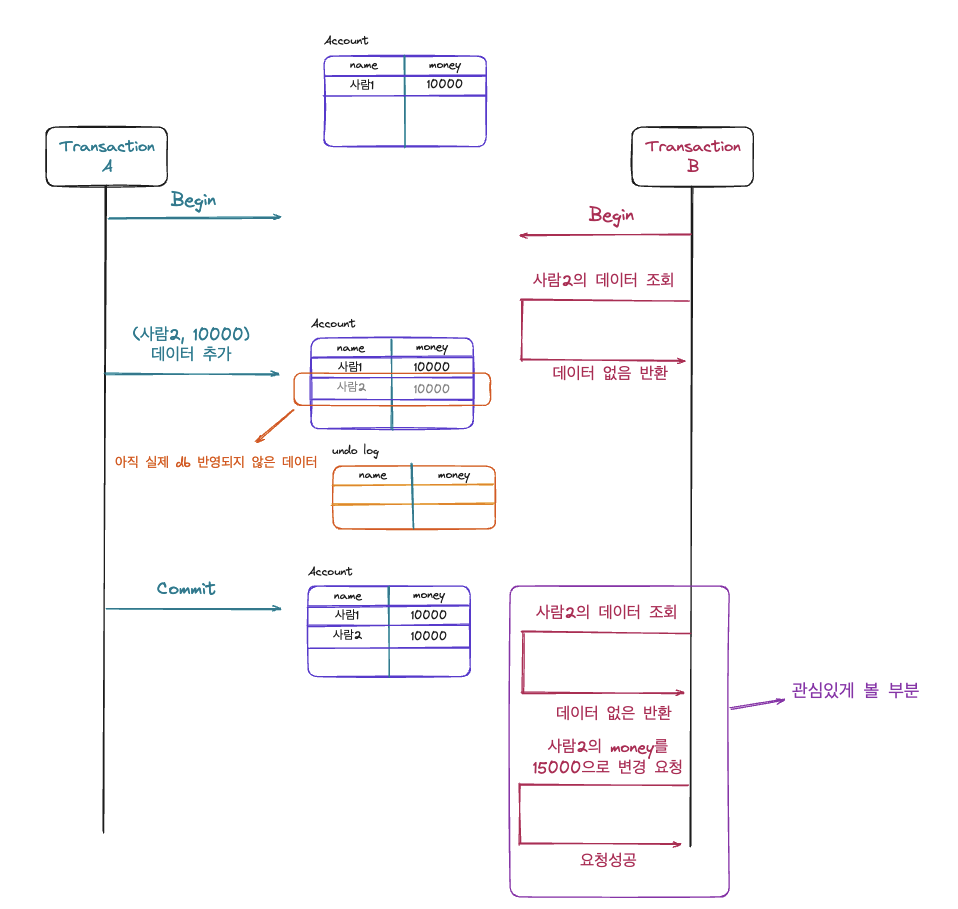
이번에는 TransactionA에서는 (사람2, 10000) 데이터를 추가하고 commit을 한 상태이고 TransactionB의 경우에는 사람2에 대한 데이터를 조회 및 수정을 하는 상황입니다. 여기서 살펴볼 것은 TransactionB에서 사람2에 대한 데이터를 조회를 하더라도 나타나지 않았던 데이터가 업데이트 처리는 성공한 것입니다. 즉, 없던 데이터가 갑자기 생겨 변화 요청이 성공한 것인데 이는 Phantom Read가 발생한 것으로 볼 수 있습니다.
undo log를 통해서 일관된 읽기는 보장이 되지만 Phantom Read가 발생한 이유는 무엇일까?
일단 undo log에서는 lock을 걸 수 었는데 update를 하게 되면 기본적으로 테이블이나 데이터에 lock을 걸어야 합니다. 즉 account 테이블에 lock이 걸리면서 조건에 해당하는 데이터(즉, 이전 트랜잭션에 의해 반영된 데이터)가 변화하게 되고 이 데이터가 undo log에 쌓이게 된다. 이 때 undo log 데이터는 해당 트랜잭션에서 생성된 것이기에 조회를 한다고 하더라도 조회가 됩니다.
💡undo log는 Repeatable Read에만 이용되는 것이가?
undo log는 innodb에서는 이용되는 것이기에 모든 격리수준에서 이용되며 각 격리 수준에 따라서 undo log를 활용하는 방법이 다른 것입니다.
Serializable
트랜잭션 격리 수준 단계에서 가장 높은 단계로 각 트랜잭션이 순차적으로 동작하게 되는 것입니다. 이전 단계의 격리 수준에서는 트랜잭션에서 데이터를 읽을 때 따로 lock을 걸어두지 않습니다. 그래서 다른 트랜잭션에서 데이터를 수정할 수 있었지만 serializable의 경우 데이터에 접근(읽기)하는 경우에도 lock를 걸어두기에 다른 트랜잭션에서 데이터에 대한 접근은 가능하나 수정하는 작업이 이루어지려면 lock이 헤제될 때까지 기다려야 합니다. 그렇기에 동시 처리 능력이 가장 떨어져서 대용량 트래픽에서는 성능 저하 문제를 발생할 수 있습니다.
정리
트랜잭션에는 원자성(Atomicity), 일관성(Consistency), 독립성(Isolation), 지속성(Durability)가 있고 여기서 대량의 트래픽이 발생하는 상황에서는 트랜잭션의 격리 수준이 중요한 역할을 합니다. 트랜잭션의 격리 수준은 4가지로 Read Uncommitted, Read Committed, Repeatable Read, Serializable 로 나누어지며 각각의 데이터 부정합 발생 여부는 아래 표와 같습니다.
| DirtyRead | Non-Repeatable Read | Phantom Read | |
|---|---|---|---|
| Read Uncommitted | O | O | O |
| Read Committed | X | O | O |
| Repeatable Read | X | X | O |
| Serializable | X | X | X |
