AI
1.데이터과학

비지도학습: 문제만 주어지는 것을 비지도 학습이라고한다.군집화는 데이터셋을 비슷한것들끼리 묶는 문제인데 군집화의 경우 학습하는 과정이 있고 정해진 답이 없기때문에 비지도 학습에 속한다.과적합: 새로운 데이터가 들어왔을때 예측력이 안좋은경우를 말한다.문제와 답을 달달외워
2.확률
확률: 0과 1사이의 수로 가능성을 표시하는것 , 상대도수적 및 기하학적으로 정의 가능하다.상대도수적 확률의 정의:n번의 시행중 사상 A가 a번 발생했을때 사상 A가 일어날 확률P(A)P(A)= a/nex1) 랜덤한 대상이 남자일 확률 한국 인구통계 = 49705663
3.머신러닝
관측값 x_n과 이에 해당하는 표적값 t_n이 훈련집합으로 주어졌을 때 회귀모델의 목표는 새 변수 x의 표적값 t를 예측하는 것인데(입력이 주어졌을때 타겟변수를 예측하는것), 이때 회귀모델로 선형함수를 사용하면 선형회귀라고 한다.다차원의 입력이 들어왔을때 타겟 스칼라변
4.확률의 성질
표본 공간: 실험으로 나온 모든 결과를 담고 있는 집합입니다.실험: 데이터 집합을 생성하는 과정입니다.사건: 표본 공간의 부분집합 입니다.표본 공간에는 두 종류가 있습니다.이산형 표본 공간: 이산형 데이터를 담고 있는 표본 공간연속형 표본 공간: 연속형 데이터를 담고
5.컴퓨터란?
컴퓨터란 대량의 정보를 사전에 정의된 절차에 따라 입력 데이터를 자동으로 처리하여 정보를 생산하는기계이다. 즉 데이터를 처리하기위해 만들어졌다.제어장치, 연산 장치, 기억장치, 저장장치, 입력장치, 출력장치로 구성됨.하드웨어:컴퓨터 부품소프트웨어: 하드웨어를 제어하고
6.jupyterlab 설치
명령 프롬프트를 관리자 권한으로 실행pip install jupyterlab만약using pip version 19.2.3, however version 23.0.1 is available. You should consider upgrading via the 'pyth
7.통계학개론
as.factor(1:4)= 1 2 3 4 각 숫자 객체를 각각의 카테고리로 인식as.character(1:4) = "1" "2" "3" "4" string형식으로 인식rep(10,5) repeat함수 10을 5번 반복행렬 만들기 n<-rep(10:5)o<-
8.r 패키지 설치 및 ggplot2 사용해 그래프 그리기
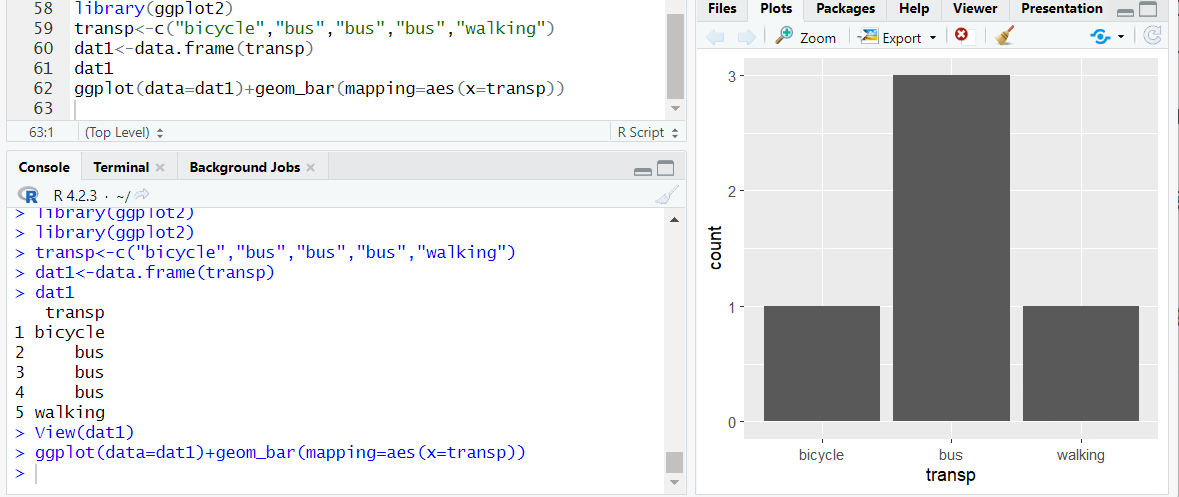
r studio에서 우측 하단을 보면 packages라는 버튼이 있다 클릭하면 검색창이 나오는데 그곳에 원하는 패키지 이름 입력하면하단에 비슷한 이름을 가진 패키지들이 쭉 나오는데 그것들중 원하는걸 체크 후 인스톨 버튼 클릭 r studio 상단에 tools 메뉴 클릭
9.python lecture1
"hellow world"파이썬에서는 에코 기능이라고 부름화면에 나타내기위해서는 print 사용print("어쩌구")print("저쩌구")어쩌구저쩌구들여쓰기 함부로 하면 에러남함수 내부에서 이런식으로 연결될때나 들여쓰기 가능근데 또 저상황에 들여쓰기 안하면 안돌아감내부
10.python lecture2
특정 메모리에 값을 지정하고 할당하는것이다.문자, 숫자, 밑줄로 구성되며 숫자로는 시작할 수 없다.키워드와 동일 불가. 길이제한 Xex) radius, Test,\_22,x,y,\_\_name불가능 ex) A+B, 4변수1,변수2=값1, 값2 로 할당할수있다.특이점변
11.machine learning lecutre5
신경망에서, 출력함수를 적절히 선택하면 각 노드의 가중치에 대한 출력값의 미분을 해석적으로 구할 수 있는데, 보통 그 입력, 출력에 모두 의존하게 된다. 따라서 오류함수의 기울기를 구할 때, 맨 마지막단부터 차례대로 거슬러 올라가면서 모든 은닉유닛의 매개변수에 대한 오
12.machine learning lecture6
한 공간에서 다른 공간으로 데이터포인트들을 이동시킬 수 있고, 새로운 공간에서의 조작이 원 공간에서 충분히 유의미할 때, 그 이동하는 함수를 커널이라고 부른다. 당연히, 아무런 변환이나 되는 것은 아니고, 유효한 커널의 조건이 존재한다.데이터들을 다른차원으로 비선형변환
13.python lecture2
작은따옴표(‘) 또는 큰따옴표(“)로 둘러싸인 복수개의 연속된 문자문자열은 단일 글자로 이루어진 복수의 연속된 문자가 작은따옴표(‘) 또는 큰따옴표(“)로 감싸진 데이터 타입이다.문자열의 연결 또는 반복을 나타내기 위해 사용되는 더하기(+)나 곱하기(\*) 연산자연산자
14.python lecture 5
프로그램의 실행 흐름을 결정하는 구조파이썬을 포함한 일반적 프로그래밍 언어는 순차, 선택, 루프 3가지의 제어구조를 제공한다. 병렬 구조는 슈퍼 컴퓨터 등 특수 목적을 수행하는 컴퓨터와 프로그램에서 사용된다.제어 구조란 프로그램의 실행 흐름을 상황에 따라 임의로 제어하
15.python lecture 9
원소의 순서화된 집합을 저장할 수 있는 데이터 타입리스트(list)는 원소의 순서화된 집합체를 저장할 수 있는 가변 크기의 시퀀스 타입(sequence type)이며 수정, 삽입, 삭제가 가능하다.원소의 나열을 저장할 수 있는 타입리스트의 첫 번째 원소 인덱스는 0부터
16.machine learning lecture 10
정규직교는 여러 벡터가 서로 내적이 0이고 크기가 1인 성질을 갖는 경우를 말합니다. 정규직교벡터는 서로 독립적이며 직교하는 성질을 가지고 있어서 많은 수학적 및 기계학습 알고리즘에서 활용됩니다.퍼셉트론은 다수의 입력으로부터 하나의 출력을 내는 연산을 지칭합니다. 보통
17.machine learning lecture 11
순차 데이터에서 가장 중요한 모델 중 하나인 은닉 마르코프 모델(Hidden Markov Model, HMM) HMM은 관찰 변수와 그를 야기시키는 은닉 변수들을 추정하는데 사용되는 모델이다.HMM을 학습하기 위해서는 먼저 HMM의 구조와 가능도 함수를 식으로 이해해야
18.python lecture 10
다차원 리스트, 인덱스 연산자를 사용하여 다차원 리스트의 생성과 접근 방법.다차원 리스트는 실생활에서 다양한 데이터를 그대로 저장하고 활용할 수 있다. 다차원 리스트의 구조와 접근하는 방법,다차원 리스트를 활용한 데이터 활용 방법을 알아보자.다차원 리스트의 구조를 이해
19.금융과 AI
의료, 제조, 광고 등과 같은 다른 영역에서의 AI 활용과 금융 영역에서의 AI 활용을 비교해보겠습니다. 먼저 각각의 분야에서의 AI 활용 방식과 차이점을 살펴보고, 금융 도메인에서의 한계를 알아보겠습니다.AI는 의료 영상 데이터를 분석하여 질병을 진단하거나 환자의 건
20.클라우드 컴퓨팅
클라우드 컴퓨팅의 등장까지 IT 환경은 큰 변화를 거쳤습니다. 초기에는 각 기업이나 개인이 자체적으로 컴퓨터 자원을 보유하고 운영하는 것이 일반적이었습니다. 하지만 이러한 방식은 비용과 유지보수의 부담을 초래하였습니다. 이런 문제점을 해결하고자 클라우드 컴퓨팅이 등장하
21.Deep Learning
인공 신경망을 기반으로 한 머신 러닝의 한 분야로, 복잡한 패턴을 학습하고 데이터에서 유용한 특징을 추출하는 데 사용되는 알고리즘의 집합입니다. 딥러닝은 특히 이미지 인식, 음성 인식, 자연어 처리 등의 영역에서 매우 뛰어난 성과를 보이며, 최근 몇 년 동안 많은 분야
22.클라우드 컴퓨팅
퍼블릭 클라우드프라이빗 클라우드멀티 클라우드클라우드 공급업체가 컴퓨팅 리소스를 소유 및 운영하고 인터넷을 통해 이를 여러 테넌트에 공유하는 클라우드 구축 모델이다.퍼블릭 클라우드를 통해 조직은 자체 하드웨어와 인프라에 대한 투자 및 관리 비용을 절약할 수 있다.퍼블릭