맛집 프로젝트를 위해서는
블로그 내용을 파싱해야 합니다! 우선 글자를 파싱해서 업체에서 받았는지를 검사해야 하고, 글자에서 안잡히면 사진을 분석해서 찾아야 합니다.
우선 첫번째 방법, 글자를 분석하려면 우선 HTML을 분석해서 글자를 추출해야 하기 때문에 자바에서 HTML을 파싱하는 방법을 찾아보았다!
jsoup
가장 흔히 쓰는 라이브러리 같았다! 그래서 우선 사용해서 크롤링 시간을 측정해보았다.
코드
코드는 생각보다 간결하다! 예전에 파이썬으로 수강신청 매크로를 selenium을 통해 만든 적이 있었는데, 그와 비슷한 느낌이었다.
주의해야할 점이 있는데, 네이버 블로그 elements는 iframe 안에 있는데 이걸 읽기 위해서는 블로그 id를 알아야 하고 때문에 두번 파싱해야한다 ...
Connection connection = Jsoup.connect(searchResponse.link());
Document iframeDocument = connection.get();
Elements iframes = iframeDocument.select("iframe#mainFrame");
String src = iframes.attr("src");
String postURL = "http://blog.naver.com" + src;
Document document = Jsoup.connect(postURL).get();
String html = document.html();
String[] splits = src.split("&");
String[] logSplits = splits[1].split("=");
String postNumber = logSplits[1];
Elements items = document.select("#post-view" + postNumber + " > div > div > div.se-main-container");이렇게 포스트 넘버와 로그넘버를 가져온 다음 다시 크롤링을 해야 정상적으로 HTML을 볼 수 있다.
if (items.size() == 0) {
items = document.select("#post-view" + postNumber + " > div > div.se-main-container");
}
StringBuilder text = new StringBuilder();
items.forEach(item -> {
text.append(item.text());
});
result.add(
new TextExtractResponse(
searchResponse.link(),
text.toString()
)
);이렇게 해서 분석해야할 텍스트를 크롤링했다!! 하지만 ... 최소 5초 이상이라는 라는 긴 시간이 걸렸다 .....ㅜㅜㅜ
1차 리팩토링
우선, 두번째 크롤링하는 주소는
이런 구조를 하고 있는데, 실질적으로 연결에 필요한 파라미터들은
http://blog.naver.com/PostView.naver?blogId={블로거ID}&logNo={로그넘버}
이거다 !!! 여기서 블로그 ID는 네이버에서 검색 결과를 받아올 때 blogurl에 포함되어 있는 정보이다. 왜냐하면 <bloggerlink>http://blog.naver.com/yoonbitgaram</bloggerlink> 이렇게 블로거 링크를 API에서 응답으로 주는데, 맨 마지막에 붙는 주소가 바로 블로거 아이디이기 때문 !!! 그리고 로그 넘버는 검색 주소를 받아올 때 블로그 링크의 맨 마지막 주소이다. 이를 활용하면 추가적인 크롤링을 막을 수 있다 !!!
String [] splits = searchResponse.link().split("/");
String postId = splits[splits.length - 1];
String postURL = "http://blog.naver.com/PostView.naver?blogId=" + searchResponse.blogId() + "&logNo=" + postId;
Connection connection = Jsoup.connect(postURL);
Document document = connection.get();
Elements items = document.select("#post-view" + postId + " > div > div > div.se-main-container");
if (items.size() == 0) {
items = document.select("#post-view" + postId + " > div > div.se-main-container");
}
StringBuilder text = new StringBuilder();
items.forEach(item -> {
text.append(item.text());
});
result.add(
new TextExtractResponse(
searchResponse.link(),
text.toString()
)
);이렇게 한번의 크롤링으로 완료할 수 있다!! 이를 통해서 최초에는 5개의 포스트를 크롤링하기 까지 5.5초 이상이 걸리던 반면, 리팩토링을 한 후에는 동일한 포스트를 크롤링하는 시간이 4 ~ 4.5초로 1초 이상이 줄어들었다 !!
하지만 ... 그래도 여전히 느리다!
2차 리팩토링 방향
아직도 너무 느린 속도라서 HTML 파싱 성능에 관해 찾아보았는데, 구글에서 좋은 정보를 찾을 수 있었다.
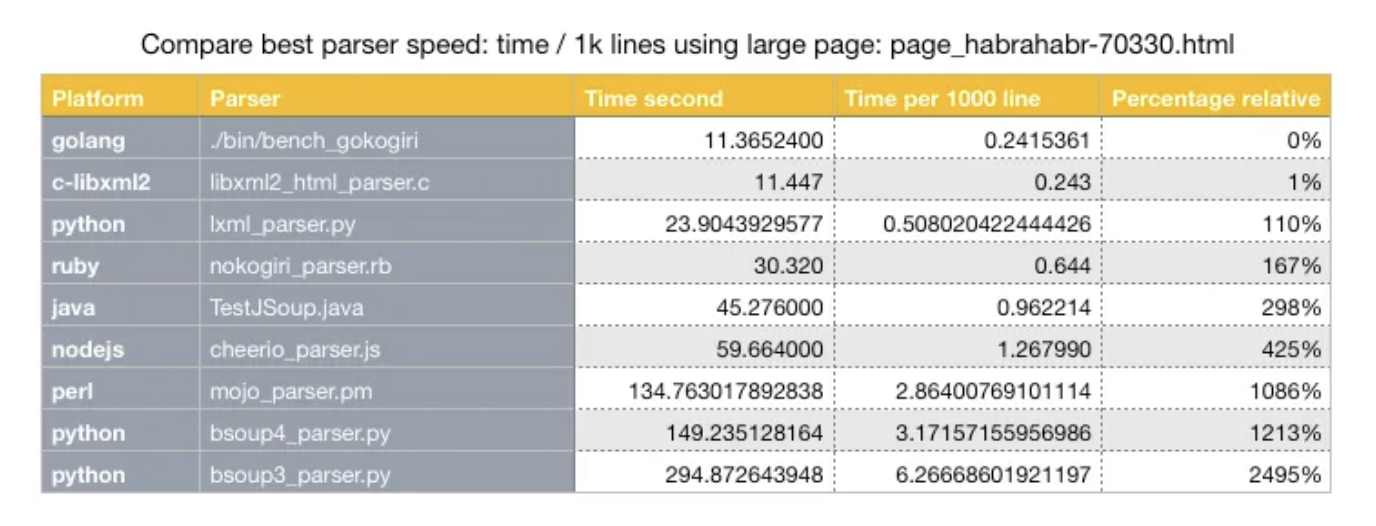
자바는 1000라인당 평균 시간이 확연하게 차이를 보였다 .... 그래서 자바말고 c언어로 크롤링하는 코드를 대체해볼까 한다 !!
자료 출처
크롤링 성능 자료 : https://medium.datadriveninvestor.com/fastest-html-parser-available-now-f677a68b81dd
