Thread Scheduling
쓰레드는 유저-레벨 쓰레드와 커널 -레벨 쓰레드로 구분됩니다. 쓰레드를 지원한다면, 사실 프로세스 스케줄이 아니라 쓰레드 스케줄 을 지원하는 것 입니다. 그리고 Many-to-one 그리고 Many-to-Many 모델의 경우, 쓰레드 라이브러리는 유저-레벨 쓰레드를 LWP(Light-weight process)를 실행하기 위한 스케줄을 진행합니다. 이처럼 프로세스 내에서 스케줄링 경쟁이 발생하는 것을 Process-Contention Scope (PCS) 라고 합니다.
비슷하게, 커널 쓰레드를 CPU에 스케줄링 하는 것을 System-Contention Scope (SCS) 라고 합니다. 그리고 이는 시스템에 있는 모든 쓰레드들 사이의 경쟁입니다.
Pthread Scheduling
API는 쓰레드 생성 시에 PCS, SCS 두 방법 중 하나를 선택할 수 있습니다.
-
PTHREAD_SCOPE_PROCESS : PCS 스케줄링을 사용합니다. M:1 모델과 유사하게 사용자 스레드가 동작합니다.
-
PTHREAD_SCOPE_SYSTEM : SCS 스케줄링을 사용합니다. 이 경우에는 커널 스레드와 1:1 매핑과 동일하게 작동한다고 볼 수 있습니다.
하지만, 반대로 OS에 의해서 제한될 수 도 있습니다. 리눅스와 맥OS에서는 PTHREAD_SCOPE_SYSTEM 만을 지원합니다.
Pthread Scheduling API
API 에서의 예시입니다.
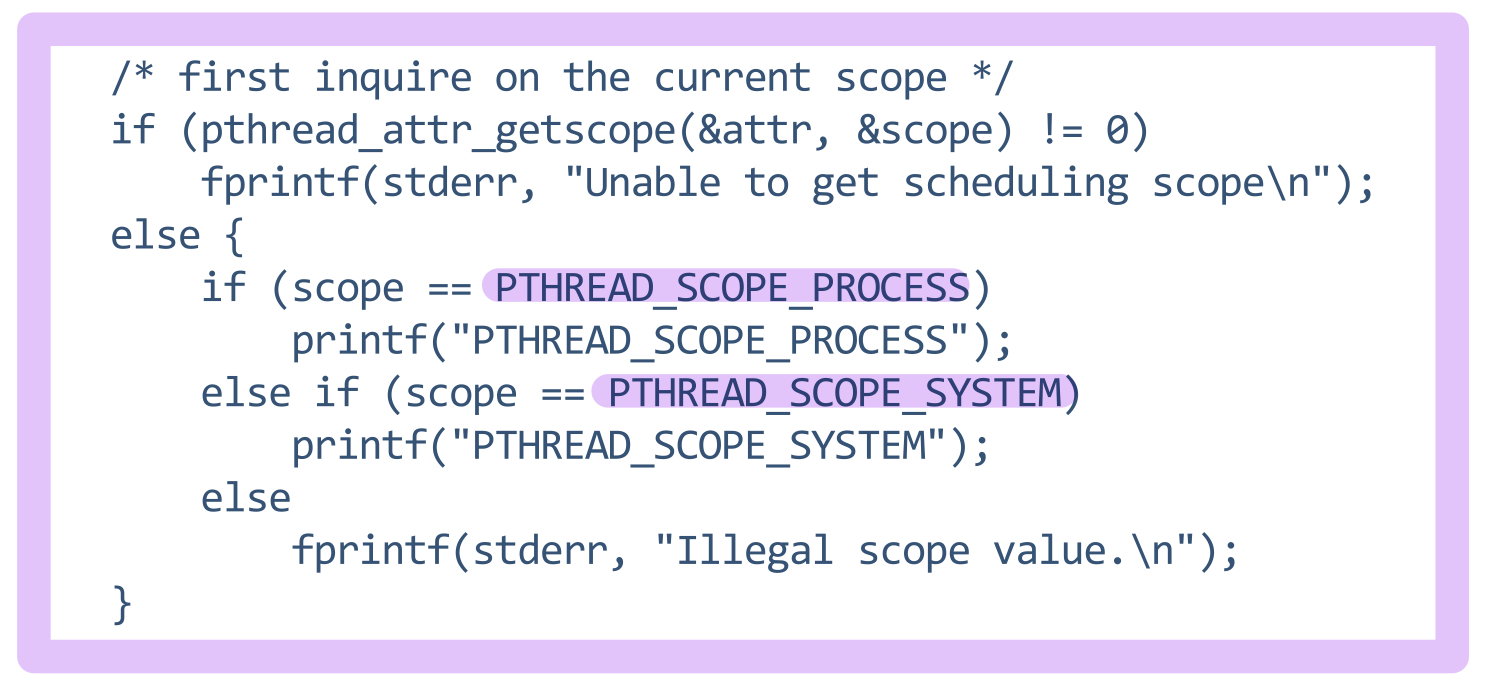
아래처럼 설정도 할 수 있습니다.

Multi-Processor Scheduling
멀티-프로세서 아키텍쳐의 스케줄링 입니다. 여러 개의 CPU를 사용할 수 있는 상황이라면, CPU 스케줄링은 더 복잡해집니다. 멀티-프로세서 아키텍쳐에는 4가지가 있습니다.
- Multi-Core CPU
- Multi-Threaded Cores (하나의 코어에서 여러 개의 스레드를 동시 실행 가능한 시스템)
- NUMA (Non-Uniform Memory Access) systems
- Heterogeneous Multi-Processing
스케줄링
Symmetric Multi-Processing (SMP) 는 각 프로세서가 스스로 스케줄링을 합니다. 스케줄링 방법에는 2가지가 존재합니다.
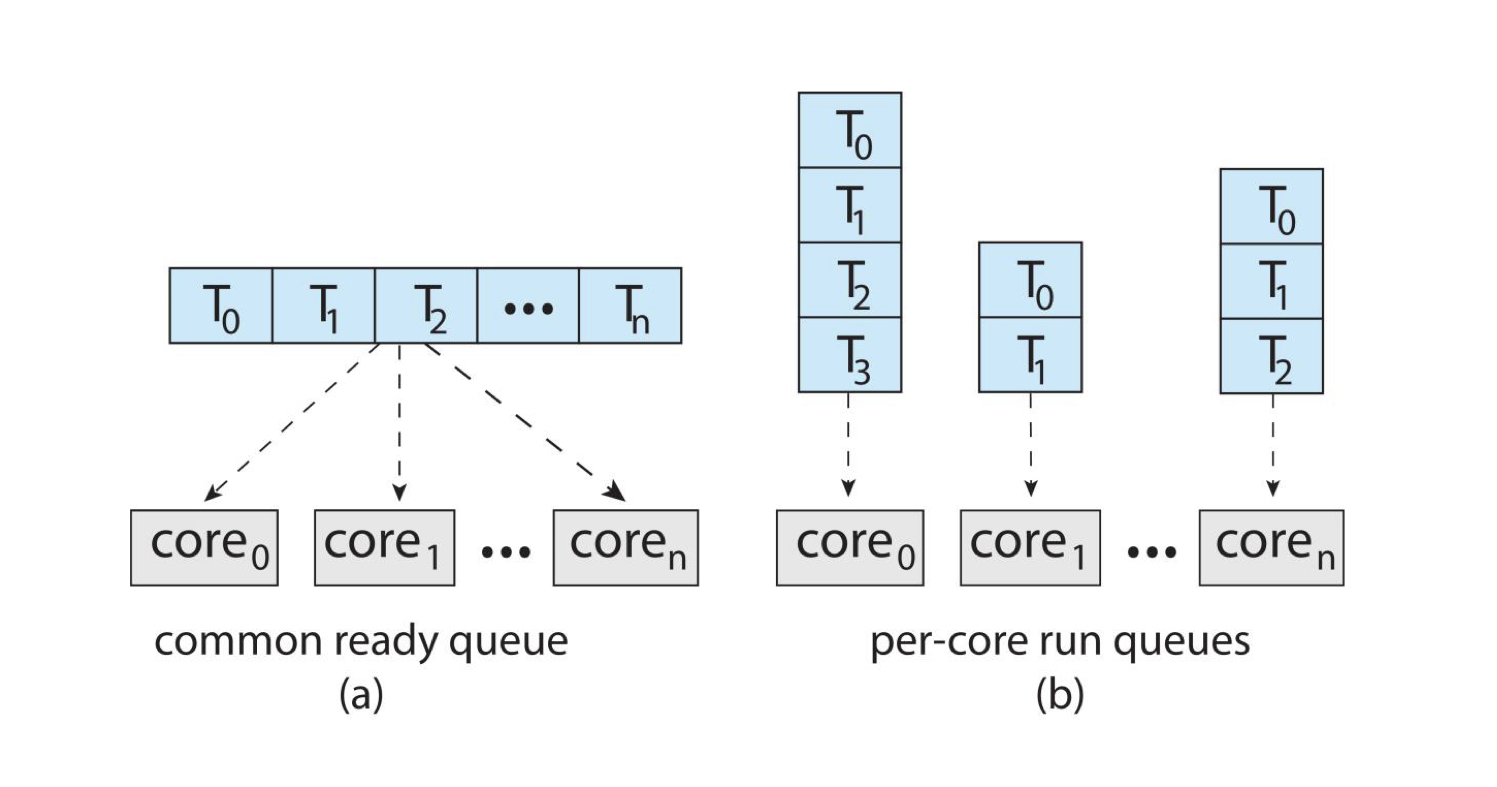
-
(a) : common ready queue 방식입니다. 하나의 ready queue만 존재합니다.
-
(b) : per-core run queues 방식입니다. 각 프로세서 별로 큐를 두어 스케줄링합니다.
Multi-Core Processors
최근 트렌드는 하나의 물리적인 칩 안에 여러개의 코어를 배치하는 구조를 많이 사용하고 있습니다. 이 구조는 보다 빠르고, 전력 소모가 적습니다. Multiple Threads per Core (Hyper-Threading) 방식도 점점 쓰이고 있습니다.
하이퍼 스레딩은 컴퓨터의 프로세서가 하나의 물리적은 코어를 사용하여 두개 이상의 가상 스레드를 동시에 실행하는 기술입니다. 이때, 메모리에서 데이터를 가져오는 작업은 종종 메모리 스톨(memory stall) 이라는 현상을 유발합니다. 메모리 스톨은 프로세서가 메모리에서 데이터를 가져오기 위해 기다리는 시간을 말합니다. 하이퍼 스레딩 방식은 이를 이용하여, I/O 작업을 수행하거나 데이터를 기다리는 동안 다른 가상 스레드의 계산 작업을 수행합니다.
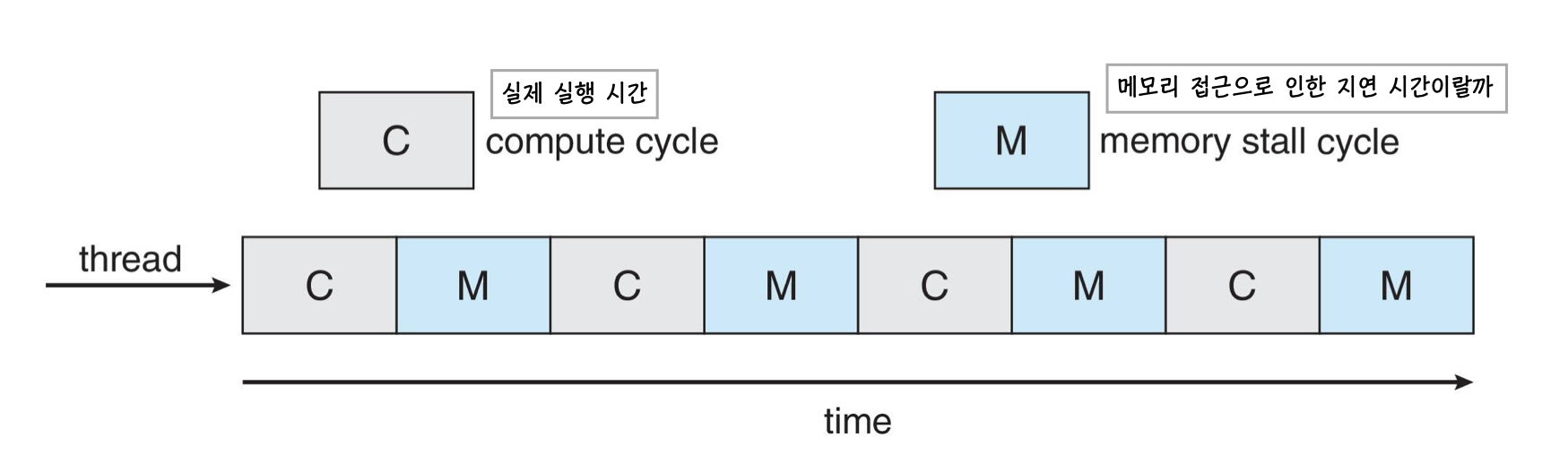
실제 CPU burst time은 위 그림처럼 구성되어 있습니다. 실제로 실행하는 시간 후에 메모리 접근으로 인한 대기 시간이 따라오는 구조입니다. 메모리 처리를 대기하는 과정에서 CPU는 다른 쓰레드의 계산 작업을 수행합니다.
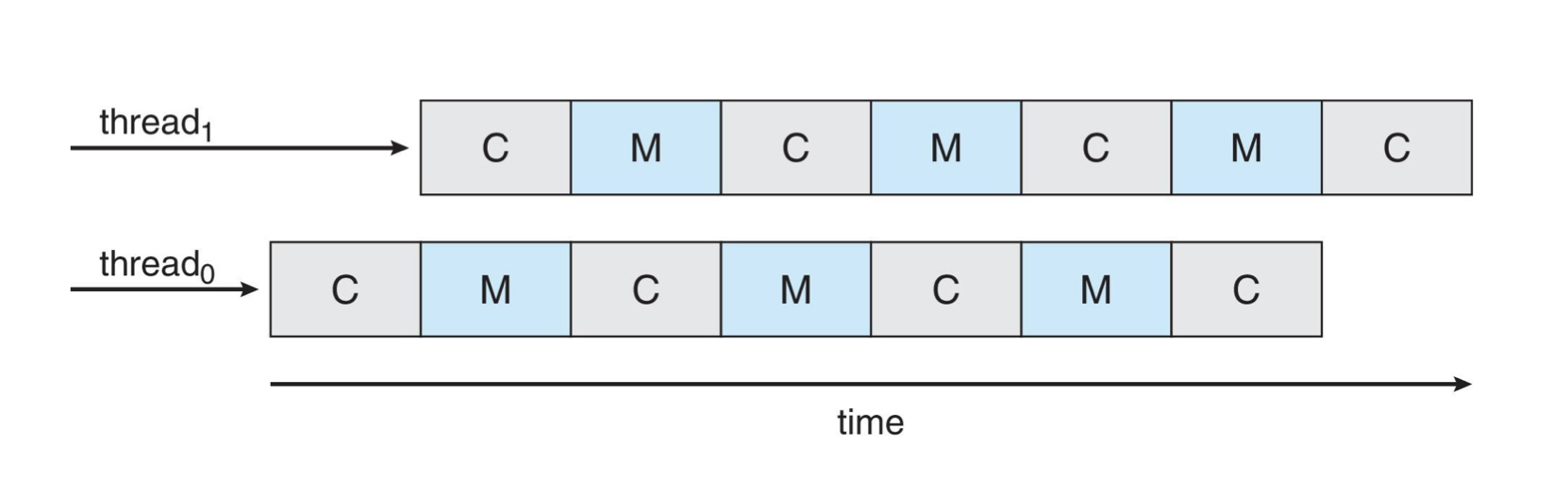
이렇게 어긋나게 처리를 하면, CPU는 항상 데이터 처리 중이고 동일한 시간에 2개의 스레드를 처리할 수 있습니다.
Multi-Threaded Multi-Core System
Chip-Multi-Threading (CMT) 라고도 합니다. 각 코어에는 하드웨어 스레드가 할당되어 있습니다. (인텔은 이를 하이퍼 스레딩이라고 부릅니다) 각 하드웨어 스레드에는 자체적인 레지스터 및 execution resource 세트가 있어 CPU가 스레드 간 빠르고 효율적으로 전환할 수 있도록 합니다.
Quad-Core 시스템에서 각 코어마다 2개의 하드웨어 스레드가 있다면, 해당 운영체제는 논리적으로 8개의 프로세서가 있는 것 처럼 보입니다.
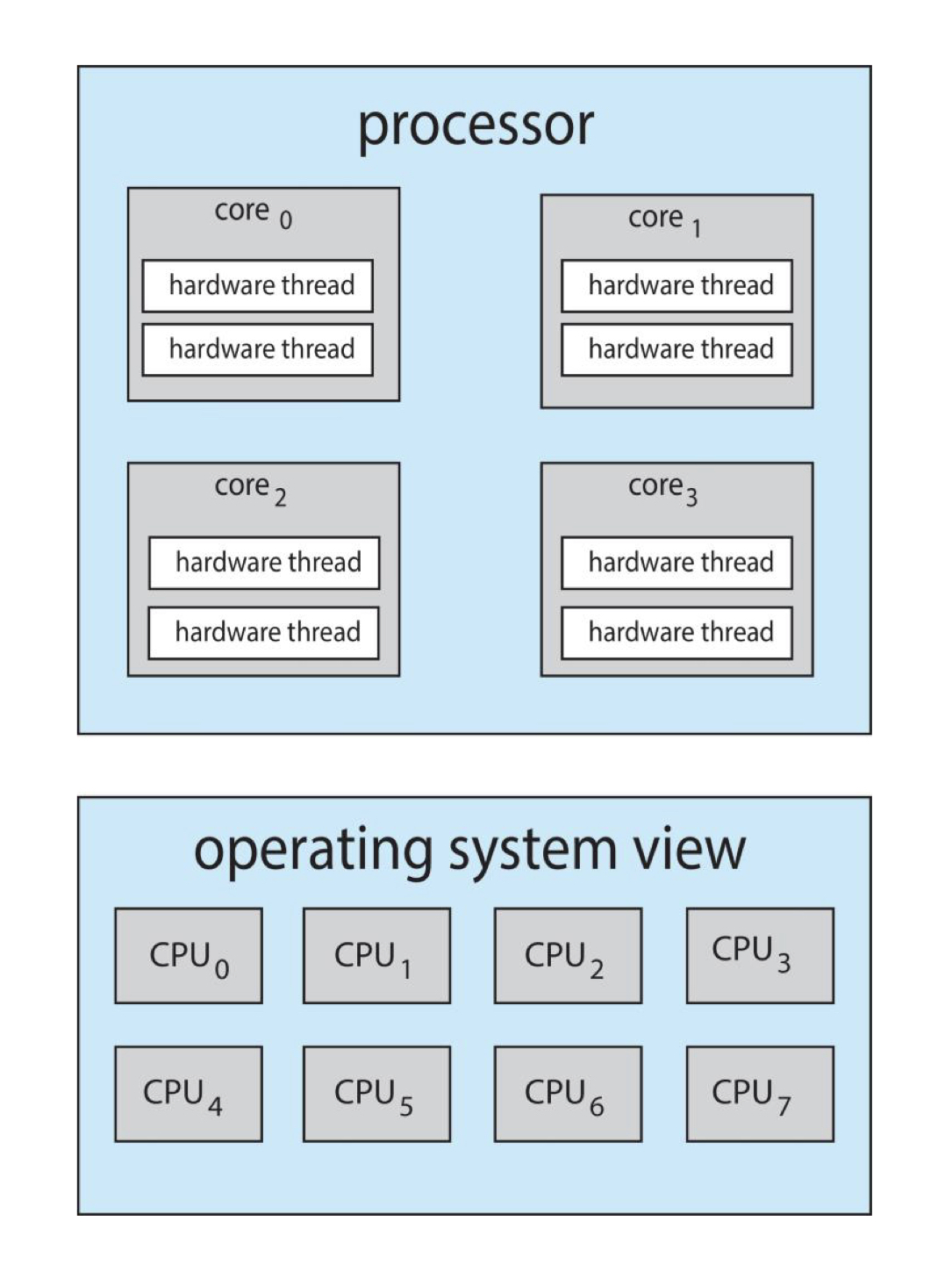
2단계 스케줄링
운영체제는 소프트웨어 스레드들 중에서 하드웨어 스레드로 올릴 스레드를 선택해야 합니다.
Multiple-Processor Scheduling
Load Balancing
SMP 시스템의 경우, 모든 CPU에 효율적으로 로드해야 합니다. 이를 위해 Load Balancing 은 작업 부하를 균등하게 분산시키는 시도를 합니다. 2가지 방법이 있습니다.
-
Push migration : 주기적인 task가 각 프로세서의 부하를 확인하고, 만약 과부하 상태인 프로세서를 발견했다면, 해당 프로세서의 작업을 다른 프로세서로 이동시킵니다.
-
Pull migration : 휴식 중인 프로세서는 바쁜 프로세서의 작업을 가져와 실행합니다.
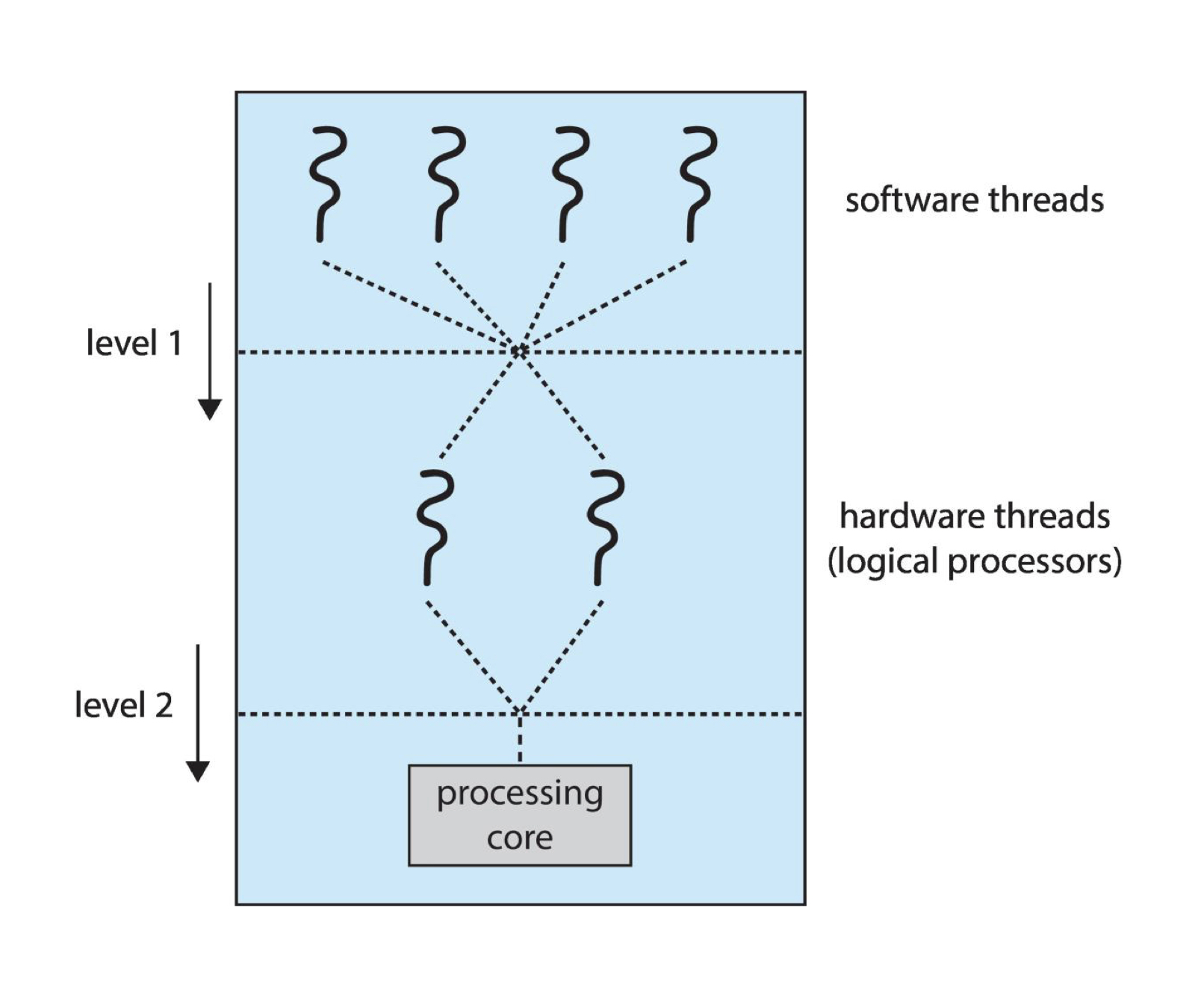
Processor Affinity (선호도)
하드웨어 스레드에도 캐시가 존재합니다 !! 결국, 프로세스가 CPU에 올라가 작업을 한다는 것은, 관련 데이터가 캐시에 올라간다는 것입니다. 이 때, 자료들은 매번 다 비우고 새로 채우는 것이 아니라서 만약 다음에 동일한 스레드를 실행한다면, 이전에 실행했던 프로세서에서 실행시킬 경우 데이터 로드의 횟수가 줄어들어 보다 효율적입니다. 이를 processor affinity 라고 합니다.
Load balancing 은 Processor affinity 에 영향을 줍니다. 프로세스가 다른 프로세서로 이동한다면, 캐시에 저장된 데이터를 활용하지 못하여 데이터 로드 시간이 더 걸릴 수 있습니다.
이를 위해 2가지 방법이 존재합니다.
-
Soft affinity : 이전과 같은 프로세서에 스레드를 할당하려고 하지만, 이를 보장하지는 않습니다.
-
Hard affinity : 특정 프로세서에 고정되도록 하는 방식입니다.
NUMA 의 CPU 스케줄링
NUMA 시스템에서도 똑같습니다. 올라갔던 CPU에 올라가면 좋고, 근데 너무 바쁘면 다른 CPU에 올라갑니다.
Real-Time CPU Scheduling
정해진 응답시간 이내에 무조건 응답이 도착해야만 하는 시스템을 Real-Time System 이라고 합니다. 2가지 방식이 있습니다.
-
Soft real-time systems : real-time 내의 실행이 중요한 작업들에게 높은 우선순위를 부여합니다. 하지만, 이를 완벽히 보장하지는 못합니다.
-
Hard real-time systems : 반드시 deadline 이내에 서비스되어야만 합니다.
Event Latency
이벤트가 발생한 시점부터 그것이 서비스될 때까지의 경과 시간입니다. 두가지 분류가 있습니다.
-
interrupt Latency : 인터럽트 도착 후 인터럽트 서비스 루린이 실행될 때까지의 시간입니다.
-
Dispatch Latency : 스케줄러가 현재 프로세스를 중지하고 다른 프로세스를 시작하기까지 필요한 시간입니다.
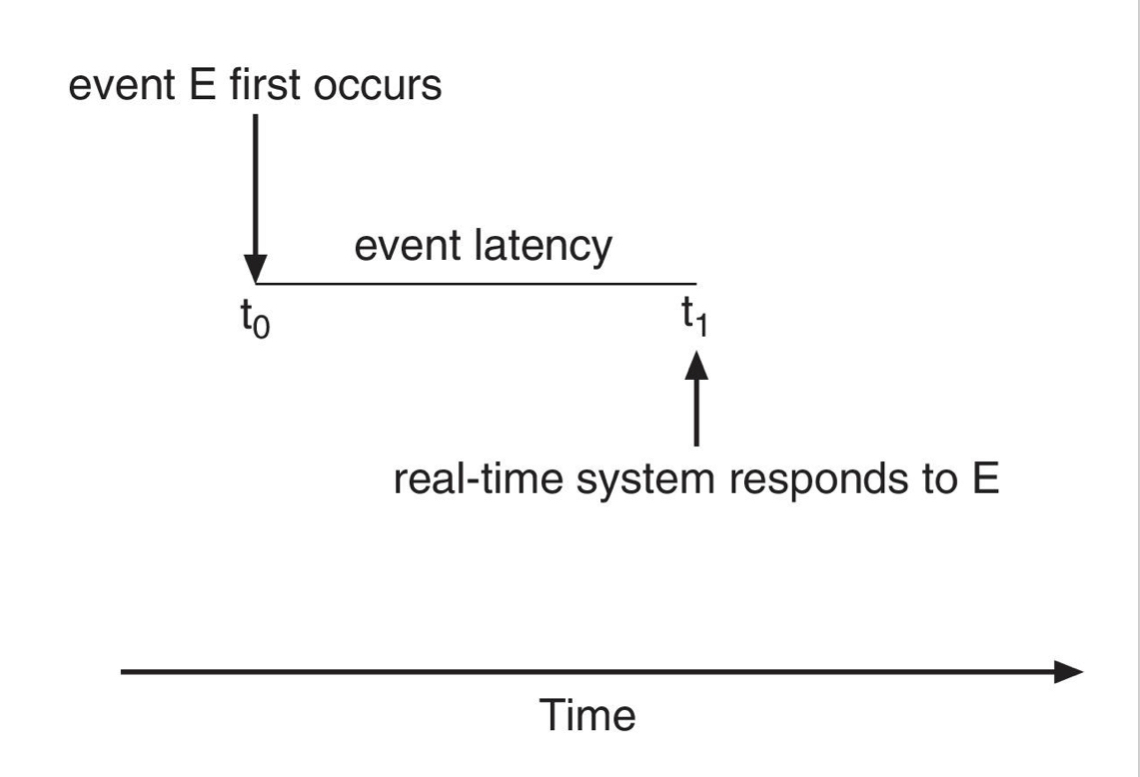
Interrupt Latency
3가지 시간의 합입니다.
- 명령어 처리 파이프라인 중 인터럽트 여부 확인까지의 시간
- 인터럽트 여부 확인 후 인터럽트 유형 확인
- 인터럽트 서비스 루틴을 실행하기 위한 context-switch
이 외에도 Kernel data structures가 업데이트되는 동안 인터럽트가 비활성화된 시간도 포함됩니다. Real-time OS에서는 인터럽트 비활성화를 매우 짧은 시간 동안만 지정해야 합니다.
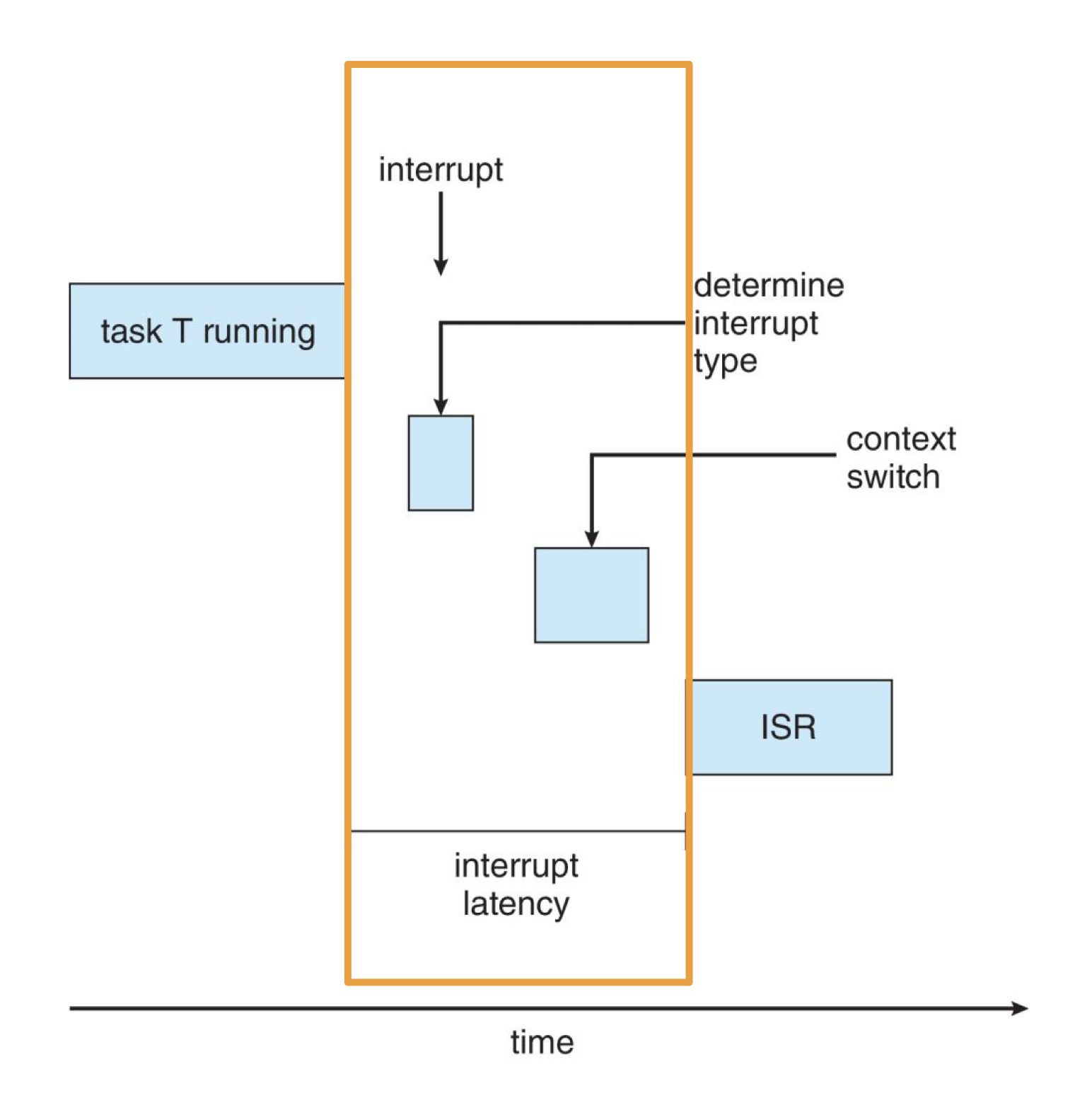
Dispatch Latency
Periodic real-time task의 경우, 이벤트가 주기적으로 발생합니다. 이 때, 커널 모드에서 실행할 프로세스 선점 시간과 앞선 프로세스를 중단시키는 시간이 소요되고 이를 묶어 Conflict Phase 라고 합니다.
이 후, 우선순위가 높은 프로세스를 사용 가능한 CPU로 스케줄링하는 시간이 필요합니다. 이를 Dispatch Phase 라고 합니다.
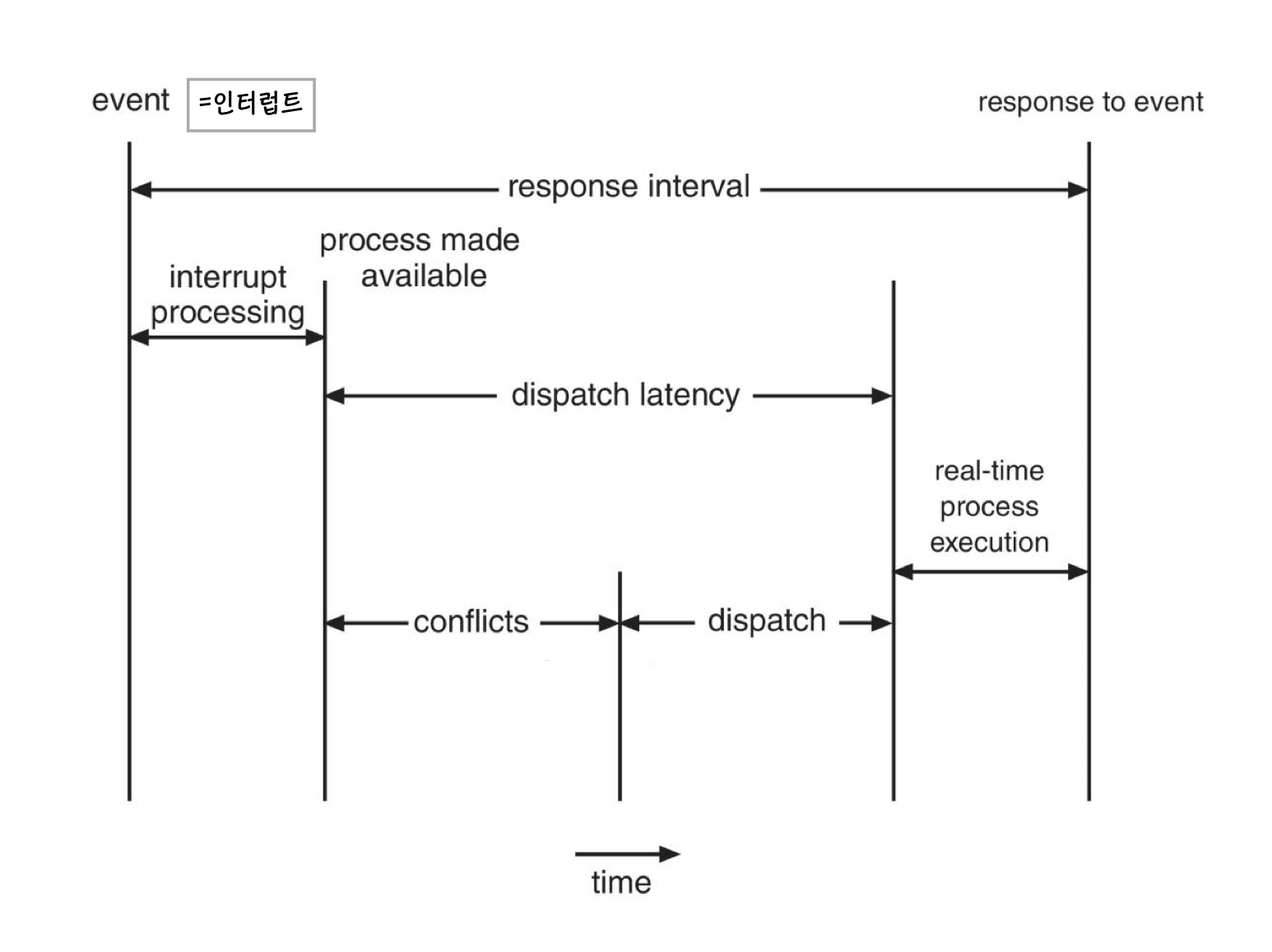
Priority-based Scheduling
Real-time 스케줄링에서, 스케줄러는 응답을 제시간에 완료하는 것이 중요하기 때문에 preemptive, priority-based scheduling 이 매우 중요합니다. (하지만 soft real-time의 경우에는 이를 보장하지 못합니다) Hard real-time 스케줄링의 경우에도, deadline 안에 끝나야만 합니다.
그래서 아래와 같은 새로운 특성들을 추가합니다.
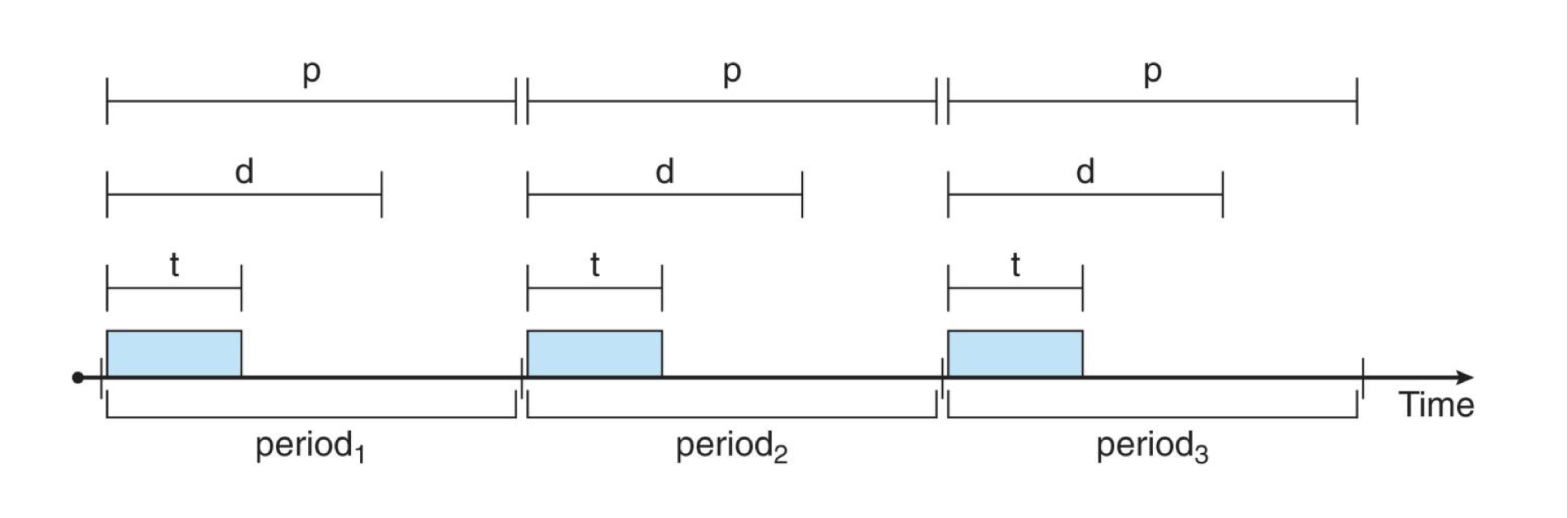
- t : processing time
- d : deadline
- p : period
위 값들은 항상 인 관계를 만족해야 합니다. 최악의 경우, 일 때 deadline을 맞추기 위해 다른 프로세스는 실행되지 못하는 상황이 발생하기도 합니다. 따라서 실시간 스케줄러는 아리 둘 중 하나를 수행해야만 합니다.
- 프로세스를 승인하여 프로세스가 제시간에 완료될 수 있도록 보장
- 데드라인까지 작업을 서비스할 수 없다고 보장할 수 없는 경우에는 요청 거부
Rate-Monotonic Scheduling
우선순위를 주기의 역수로 두어 스케줄링합니다. 주기가 짧을수록 우선순위가 높습니다. (CPU를 더 자주 요구하는 작업에 더 높은 우선순위를 할당합니다)
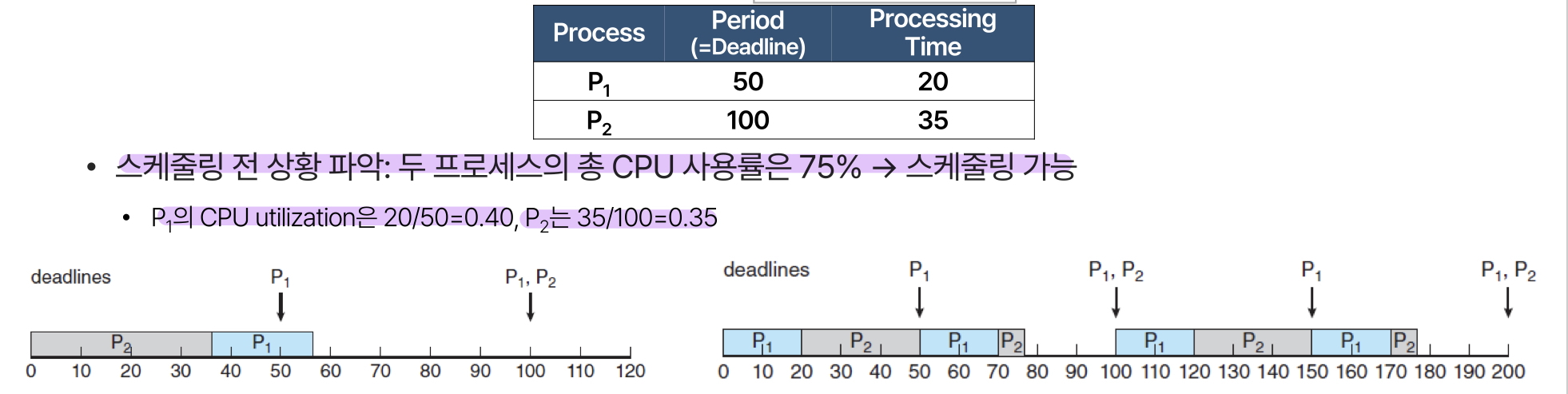
이런 느낌입니다! 실행시간이 아닌 period를 기준으로 스케줄링을 진행합니다. 하지만 이 방법이 항상 deadline을 맞출 수 있는 것은 아닙니다. P2의 주기가 80으로 줄어들게 되면,
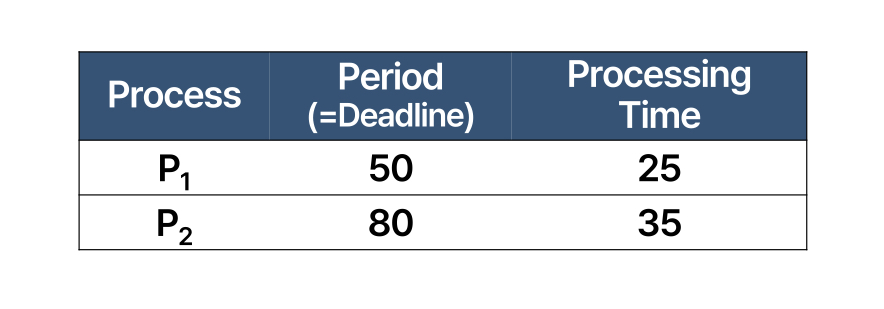
이렇게 됩니다. 이때 CPU 사용률을 계산해보면 로 스케줄링이 가능해 보입니다. 하지만 실제로는
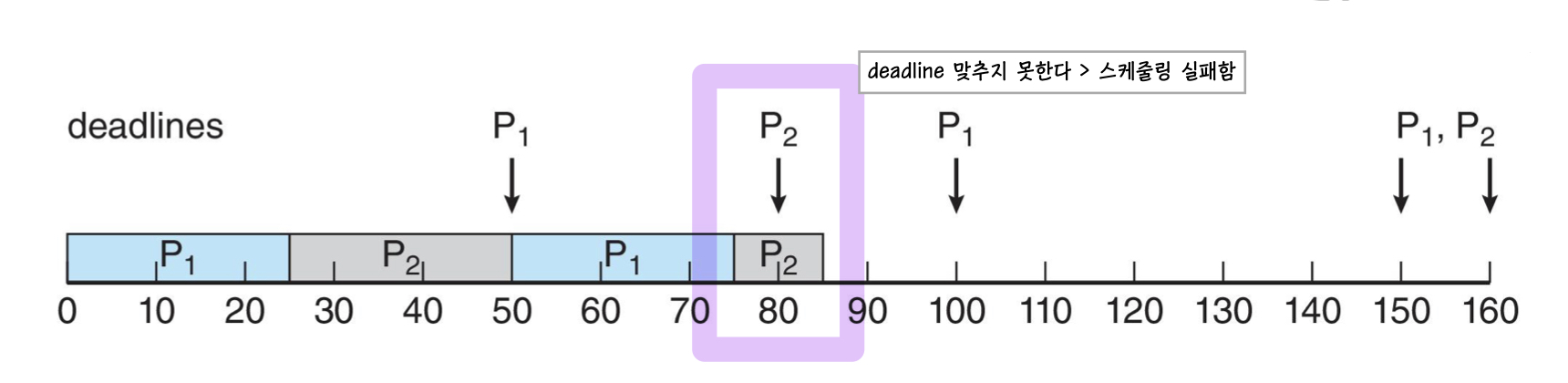
스케줄링을 할 수 없습니다!!! P2의 deadline을 맞출 수 없기 때문입니다. 이를 보완하기 위한 방법이 Earliest Deadline First Scheduling (EDF) 입니다.
Earliest Deadline First Scheduling (EDF)
deadline이 빨리 다가오는 프로세스 먼저 실행하는 스케줄링 방식입니다. 프로세스가 실행 가능한 상태가 되면 (실행 주기가 돌아올 때마다) 스케줄러에게 deadline을 업데이트합니다.
이 스케줄을 따른다고 할 때,
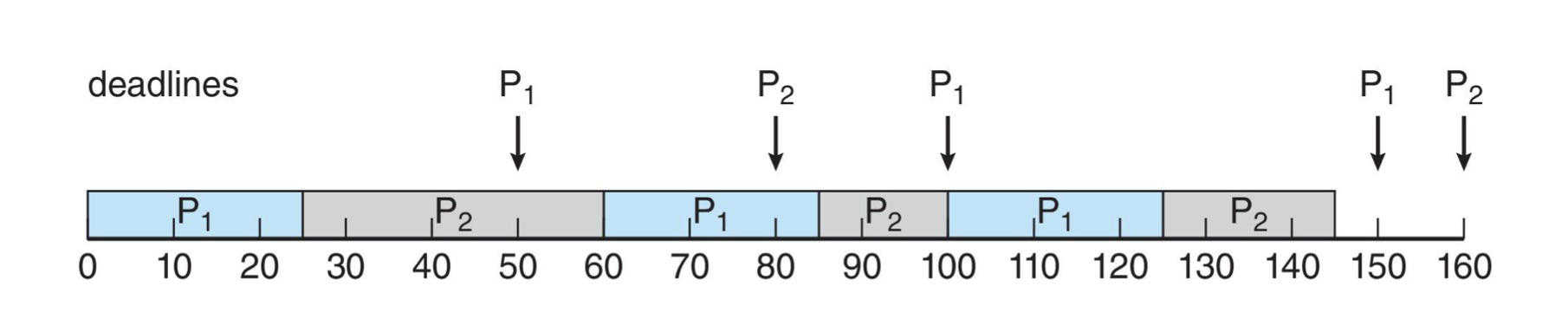
이런 결과가 나옵니다. 예를 들어
t = 0
P1 = 50, P2 = 80 이므로 P1을 실행합니다. 실행을 완료하면 P2를 실행합니다.
t = 50
P1의 주기가 돌아왔습니다. 이때, P2의 deadline은 아직 80이고 P1의 deadline은 100 이므로 P2를 실행합니다. 실행 후 남은 시간동안 P1을 실행합니다.
t = 80
P2의 주기가 돌아왔습니다. 이때, P1 = 100, P2 = 160 이므로 P1을 실행합니다.
t = 100
P1의 주기가 돌아왔습니다. P1 = 150, P2 = 160 이므로 P1을 실행합니다.
Propertional Share Scheduling
프로세스들이 할당받을 시간을 정합니다. 만약 T = 100, A = 50, B = 15, C = 20 이라고 하면, A는 총 프로세스 시간의 50%를, B는 15%, C는 20%를 할당받습니다. 이러한 상태에서 D라는 프로세스가 30%의 공유를 요청한다면, 시스템은 이를 거부합니다.
