스케줄링 알고리즘 종류
종류
- FCFS (First Come First Served; 선입 선처리)
- SJF (Shortest Job First; 최단작업 우선)
- SRTF (Shortest Remaining Time First; 최소 잔여시간 우선)
- Priority Scheduling; 우선순위 스케줄링
- RR (Round-Robin)
- MLQ (Multi-Level Queue; 다단계 큐)
- MFQ (Multilevel Feedback Queue; 다단계 피드백 큐)
Gantt Chart

이런게 바로 간트 차트입니다. 프로세스별 시작과 끝을 표시한 바(bar) 입니다.
FCFS (First Come First Served) 스케줄링
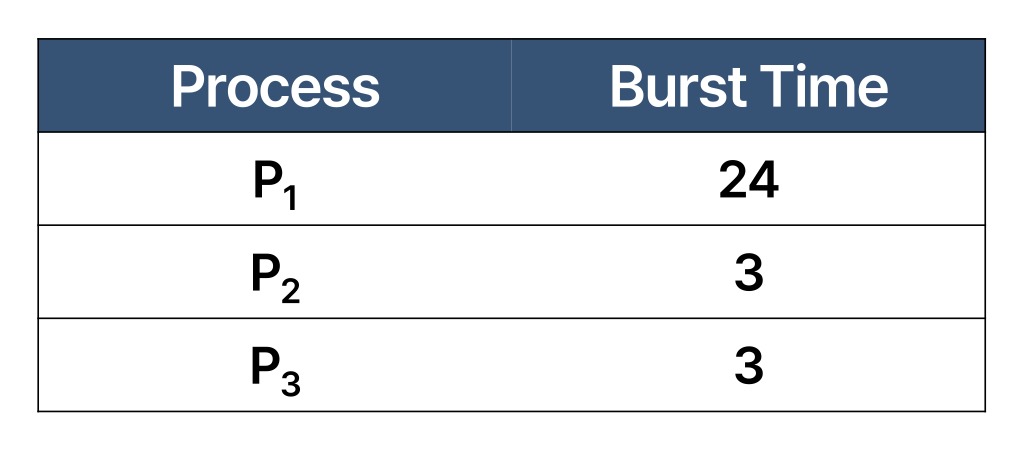
이렇게 3개의 프로세스가 실행중이고, 각각의 CPU burst 는 표와 같습니다. arrival time 이 모두 0이고 P1, P2, P3 순서로 도착해서 처리한다고 가정한다면, 간트 차트는 다음과 같습니다.

이를 통해 Waiting time, turnaround time을 계산해보면

이렇계 계산됩니다. 공정한 방법입니다. 하지만, 그러기엔 기다리는 시간이 너무 깁니다. P2, P3를 먼저 실행 후 P1을 계산한다고 하면

이렇게 절반 이상 개선될 수 있습니다!!!! 이렇게 CPU burst 시간이 짧은 프로세스들이 CPU burst 시간이 큰 프로세스들의 영향을 받는 상황을 Convoy Effect 라고 합니다.
SJF (Shortest-Job-First) 스케줄링
CPU burst 가 짧은 프로세스 먼저 실행하는 방식입니다. 이는 optimal 한 결과를 도출하는 방법입니다. 주어진 프로세스 집합에서 평균 대기 시간이 항상 최소인 결과를 도출합니다. 그리고 SJF는 비선점형 기법 입니다.
예를 들어
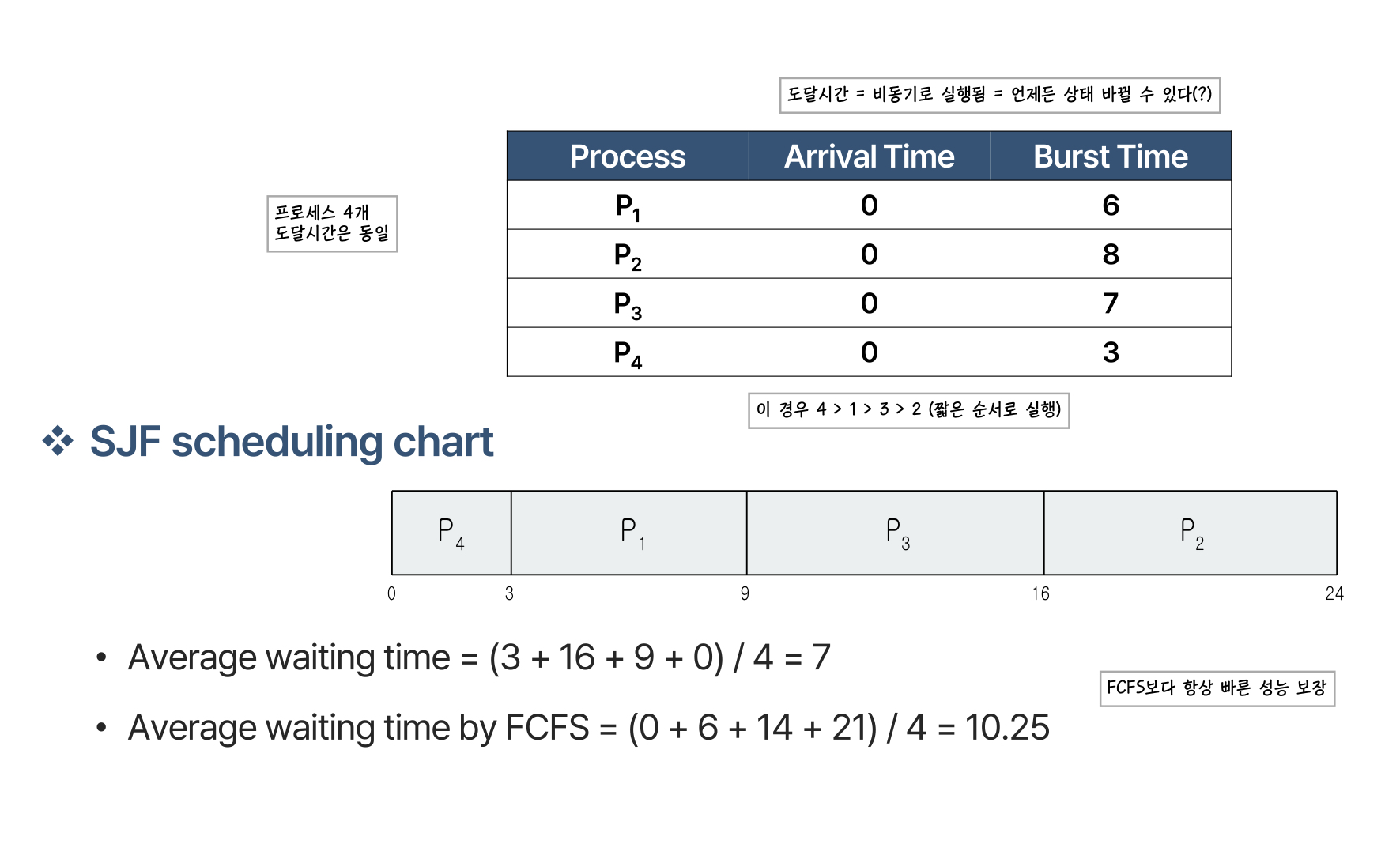
4개의 프로세스를 실행할 때, burst time을 계산하여 짧은 순서인 4 > 1 > 3 > 2 순서로 실행합니다. FCFS보다 항상 빠른 성능을 보장합니다.
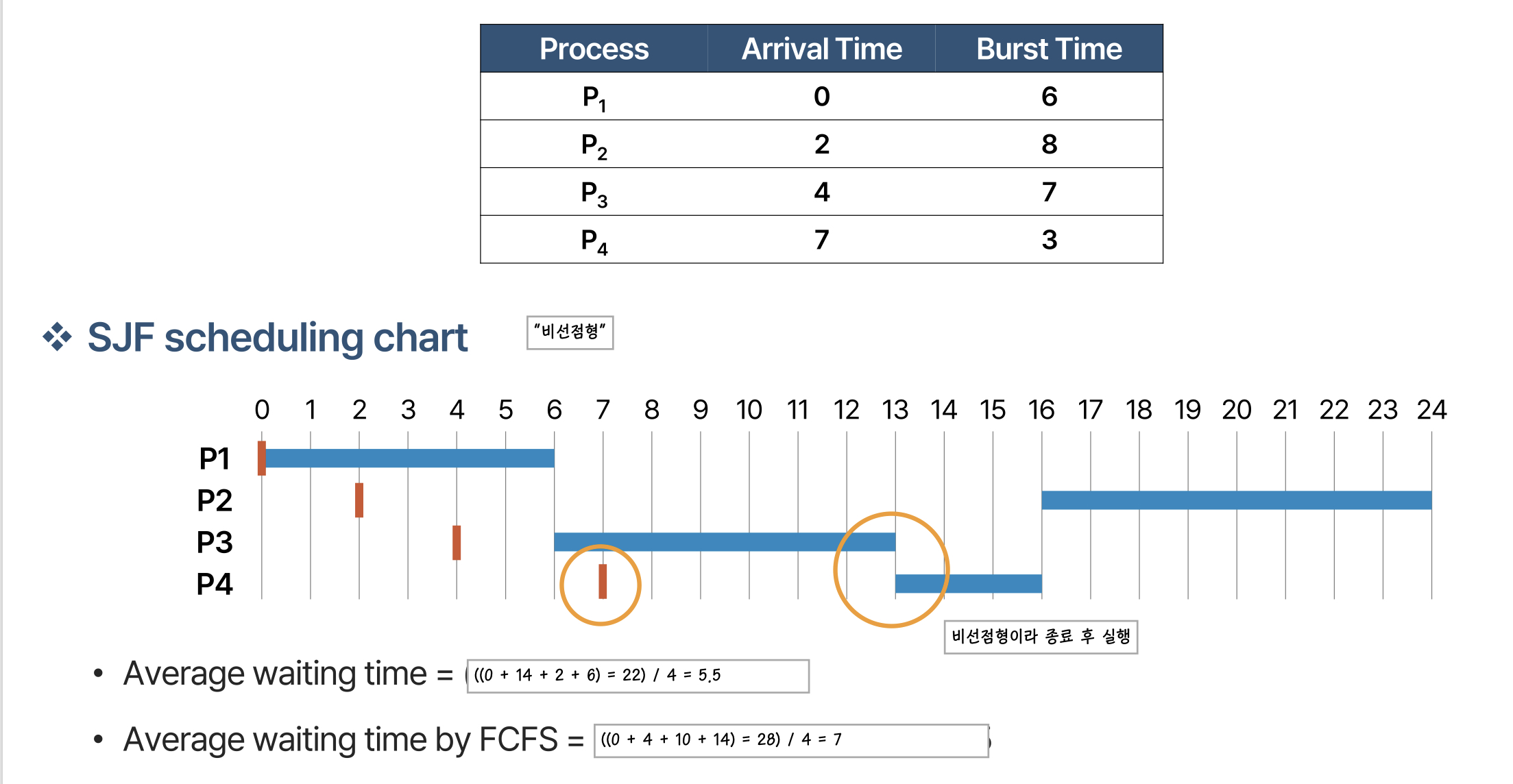
도착 시간이 다른 경우에도 동일하게 진행됩니다. 비선점형이기 때문에 프로세스 종료 후 실행해야할 프로세스들 중 가장 짧은 burst time을 가진 프로세스를 실행합니다.
여기서 문제가 있습니다. CPU burst 시간을 계산해야 하는데, 이를 계산하는 것이 더 오래걸립니다. 사실상 next CPU burst time을 알 수는 없습니다. 그래서 이전까지의 기록들을 가지고 다음 CPU burst time을 추정합니다.
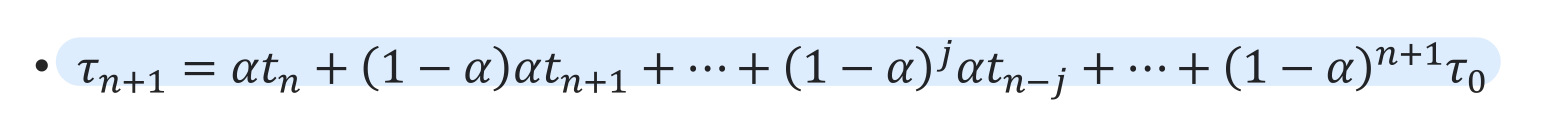
이 식에 따라 결정됩니다. 알파가 0이면, 과거를 계산하지 않습니다. 알파가 1일 경우, 직전 값만 참조합니다. 보통, 알파값은 0.5를 많이 사용합니다.
SRTF (Shortest-Remaining-Time-First) 스케줄링
매 순간마다 남아있는 burst time이 가장 적은 프로세스를 선택합니다. 현재 진행중인 프로세스의 완료와 관계 없이 버스트 타임이 가장 낮은 프로세스로 바꾸어 실행합니다.
이런 경우를 생각해 보면 간트 차트는 다음과 같습니다.

이 때 평균 대기 시간은 입니다.
RR (Round-Robin)
굉장히 많이 사용하는 방법입니다. CPU Time을 작은 단위로 나눈 Time Quantum 을 정합니다. 보통 10~100 milli-second 입니다. 해당 시간이 지나면, 해당 프로세스는 ready queue로 돌아갑니다.
ready queue에 만약 n개의 프로세스가 있다고 하고 time quantum이 q라고 주어졌을 때, 모든 프로세스의 대기 시간은 를 넘지 않습니다. Timer interrupt 가 매 quantum 마다 발생하여 다음 프로세스로 스케줄링 됩니다.
RR 방식의 경우, q 값이 크면 FCFS 가 되고 q 값이 너무 작으면, context-switch 시간 보다 일정수준 이상이 되어야 합니다. 그러지 않으면 오버헤드가 너무 커집니다.
예를 들어

이 경우, 평균 대기 시간은 입니다. RR 방식의 경우 SJF 보다 평균 turnaround time은 길지만, response time은 빠릅니다.
time quantum 에 따라 context-switch 가 일어나는 횟수를 생각해보면 다음과 같습니다.
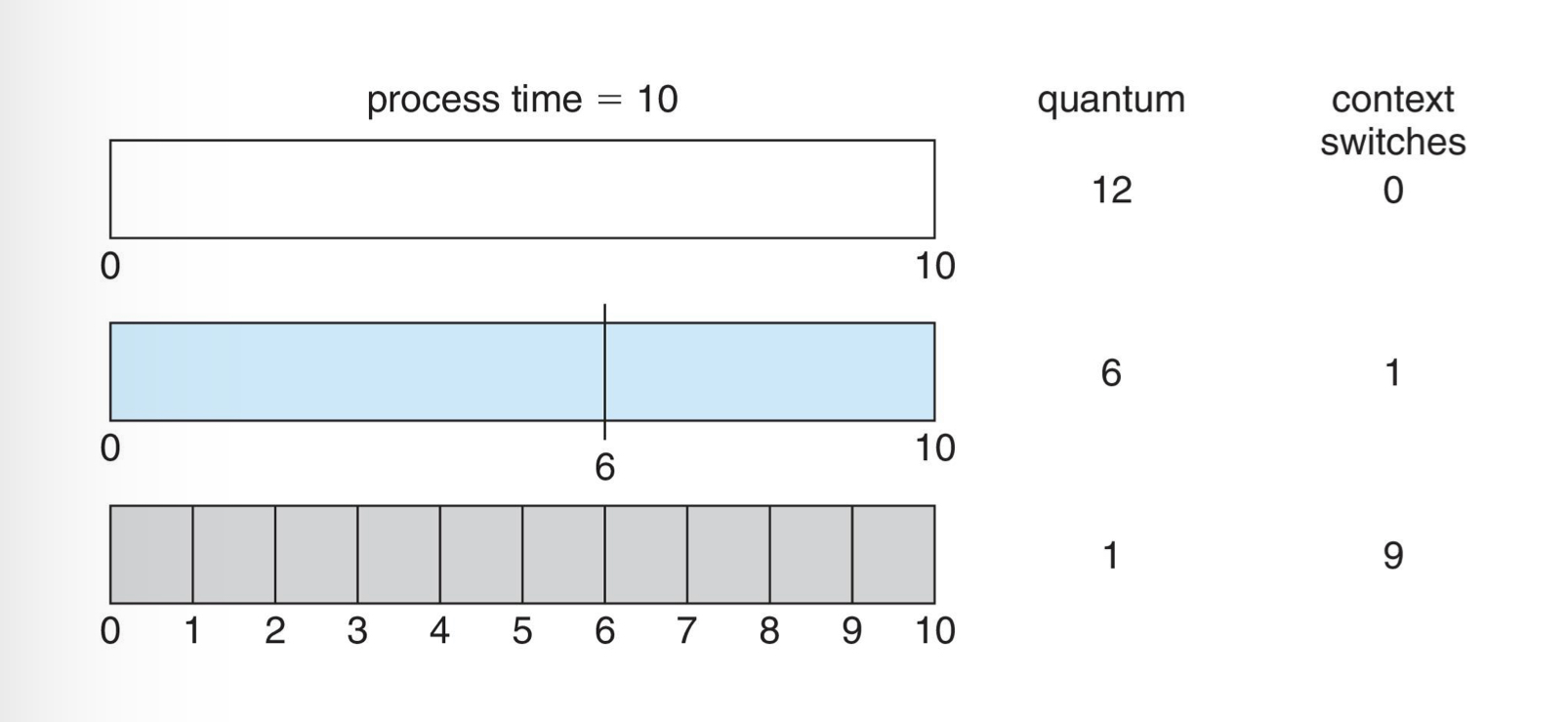
Quatum이 줄어들수록, 더 많은 context-switch 가 발생합니다. 이로 인해 프로세스 실행이 딜레이되고, quantum이 긴 경우보다 더 오랜 시간이 걸릴 수도 있습니다. 따라서 일반적으로 10~100 milli-second 사이 값을 많이 사용합니다. 이렇듯, 적절한 quantum 값을 찾기란 매우 어려운 일입니다. 경험적으로 CPU burst의 80%는 quantum보다 짧아야 합니다.
Priority 스케줄링
커널, foreground 프로세스의 경우에는 많이 할당받아야 하고, 백그라운드와 같은 경우에는 비교적 덜 할당받아도 됩니다. 이렇게 각 프로세스 별로 우선순위를 정하여 할당하는 방식입니다. SJF 의 경우에는 우선순위가 다음 CPU burst time인 priority 스케줄링 이라고 볼 수 있습니다.
하지만 이 경우에, Starvation (기아) 이라는 문제가 발생할 수 있습니다. 낮은 우선순위에 있는 프로세스들이 실행되지 않는 문제입니다. 이를 해결하기 위한 방법이 Aging 입니다. CPU에 머문 시간만큼 우선순위가 감소합니다.
예시를 살펴보면
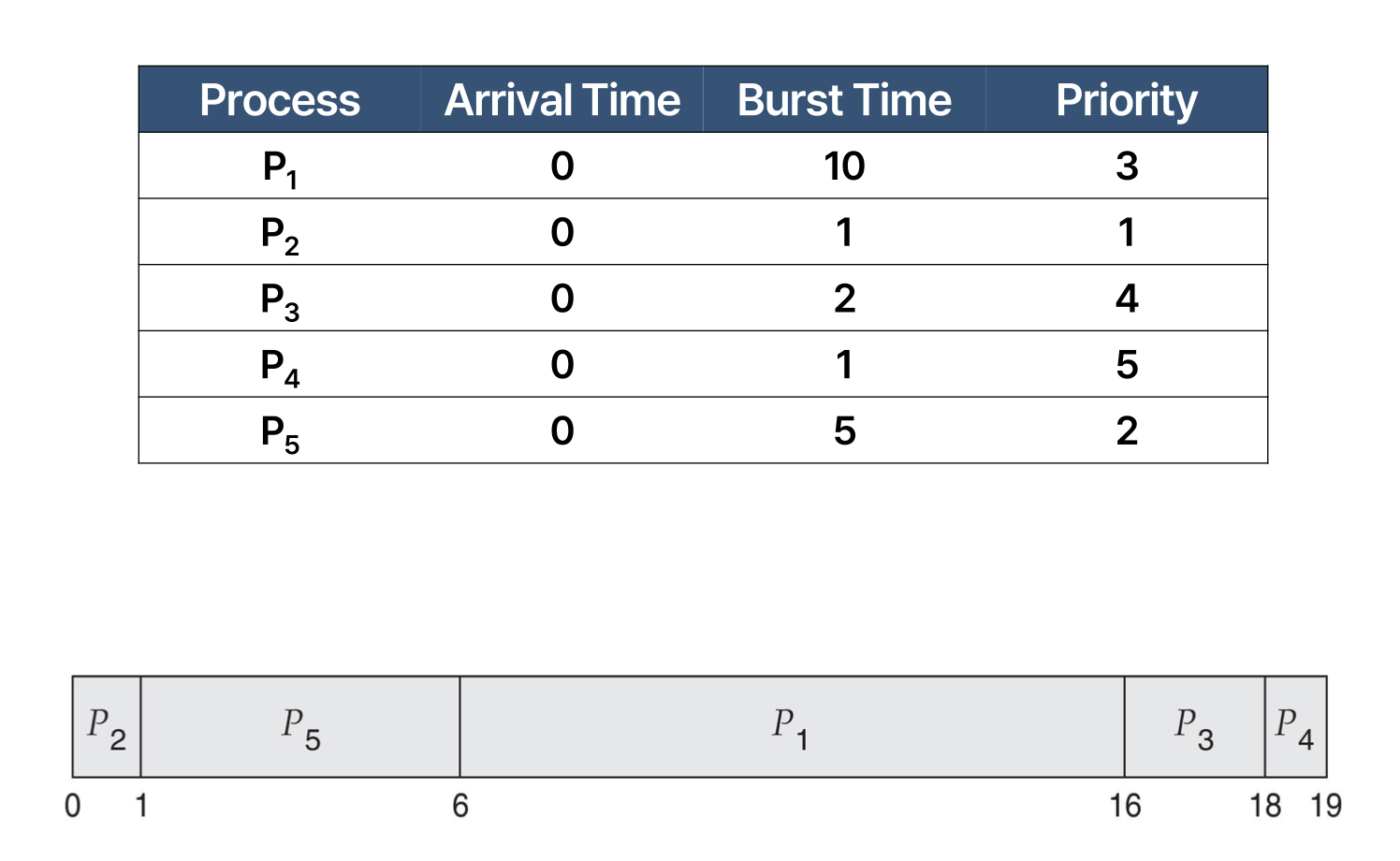
이런 경우입니다. 이때 평균 대기 시간은 8.2 입니다. 다음으로 Priority - RR 스케줄링을 살펴보면
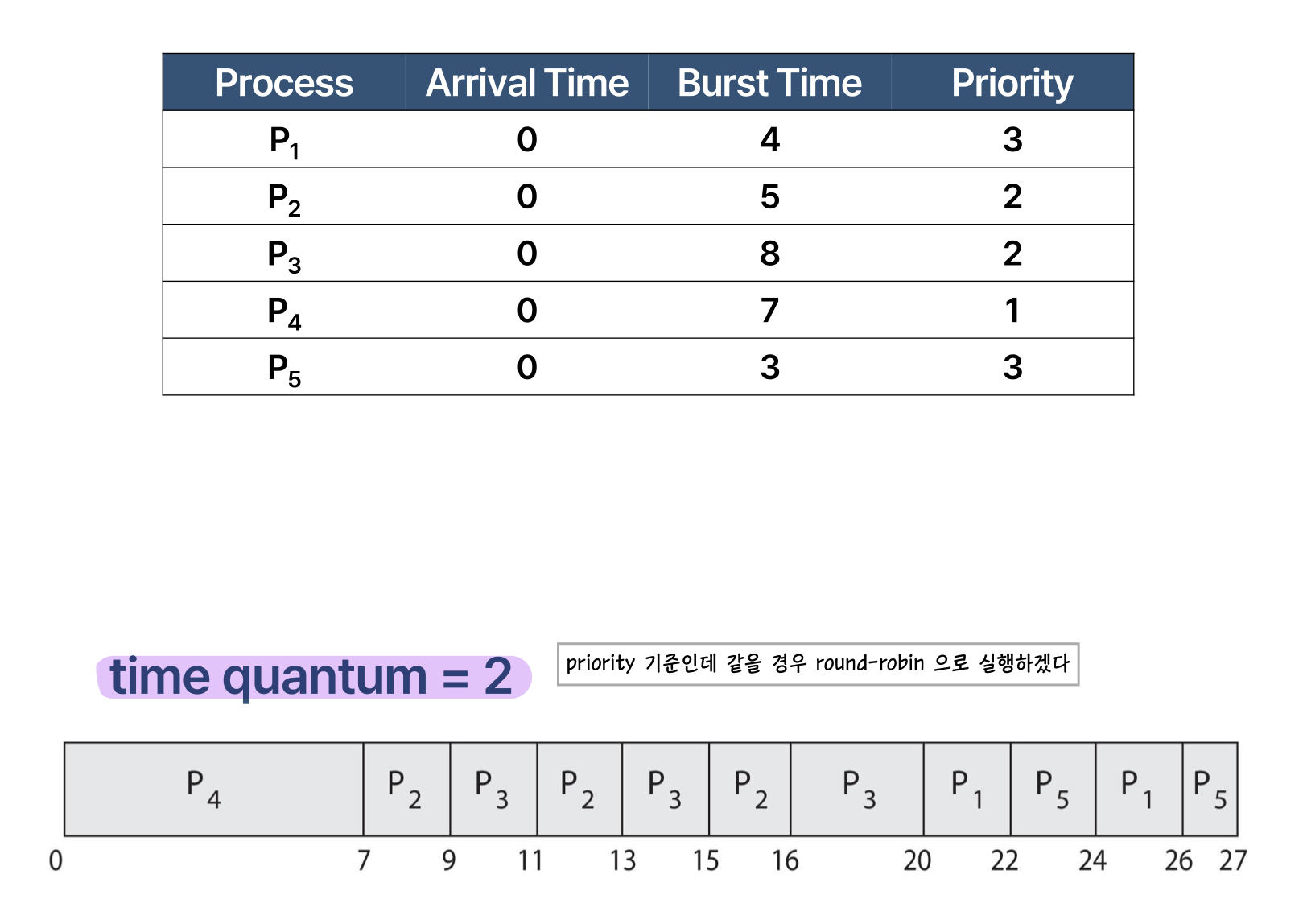
이런식으로 간트 차트를 얻을 수 있습니다.
Multi-level Queue 스케줄링
우선순위에 따라 여러 개의 큐로 분할하는 방식입니다. 프로세스는 지정된 큐에 영원히 존재하며, 각 큐는 각자의 스케줄링 알고리즘이 정해져 있습니다. 즉,
- 큐를 나누는 정책 = 우선순위
- 큐에서 프로세스를 선택하는 정책 = 각자 다름
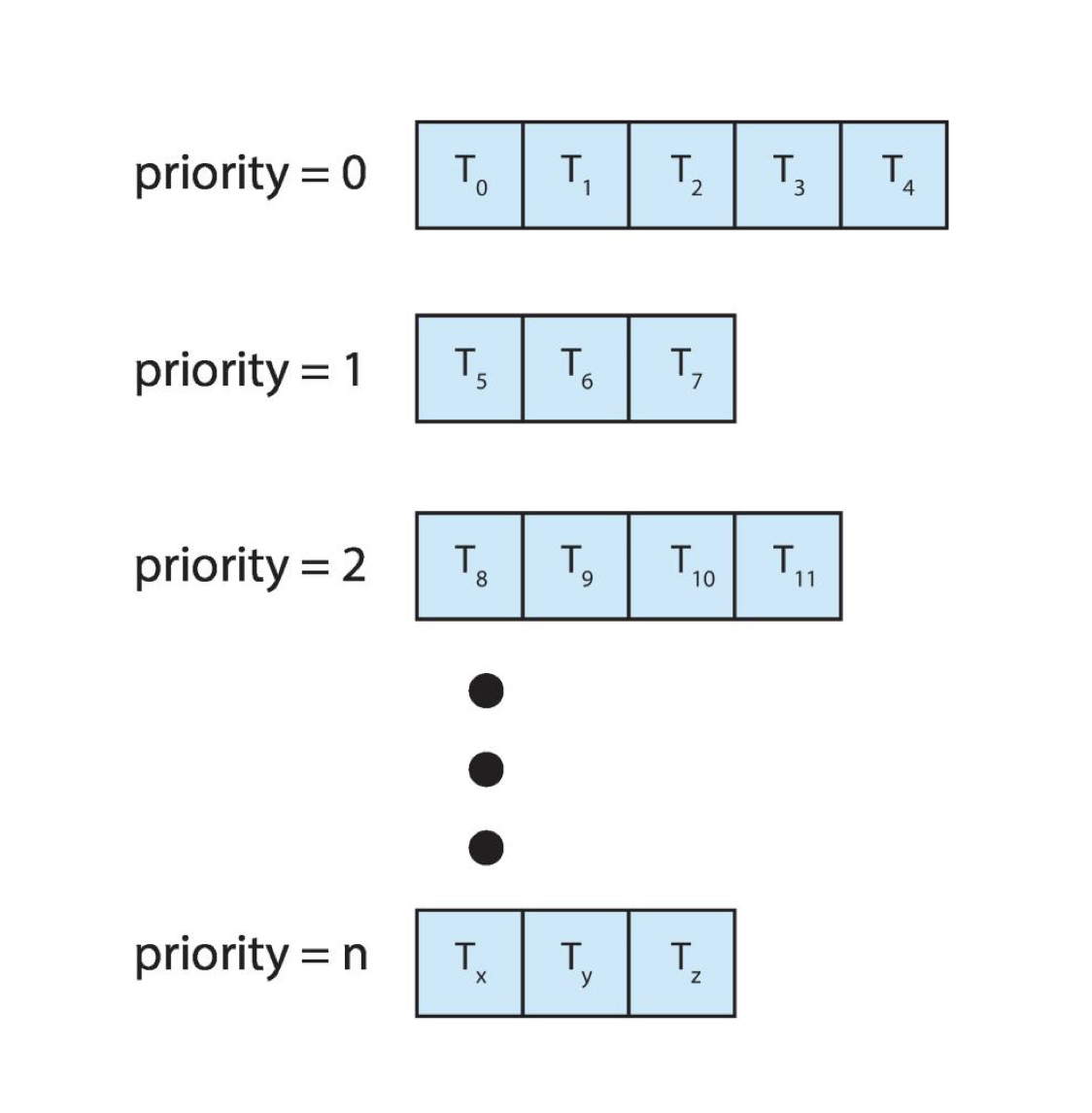
이렇게 우선순위가 같은 프로세스들끼리 같은 큐에 담깁니다. 보통은 아래 그림처럼 큐를 나눕니다.
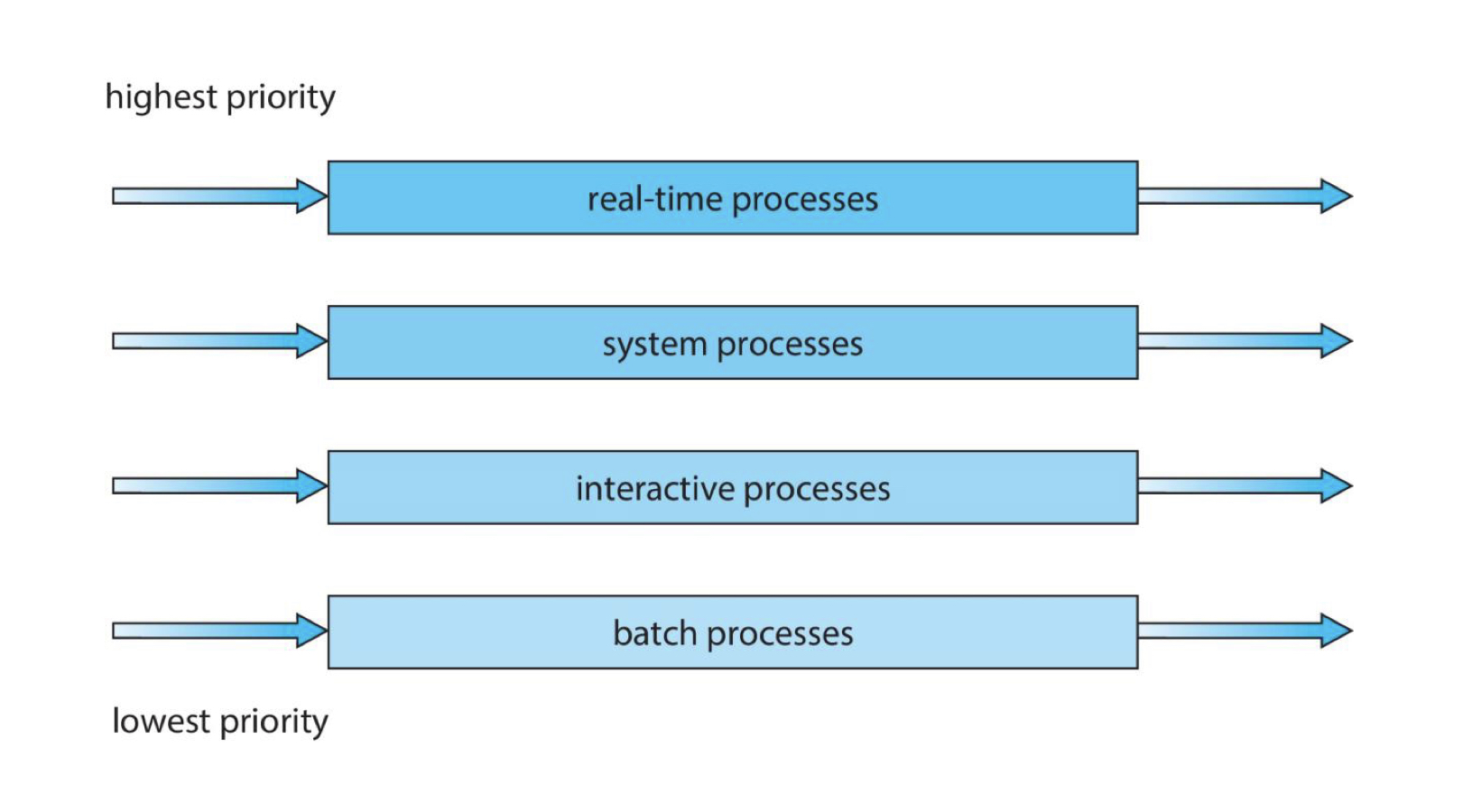
Multi-level Queue 에서는 큐와 큐 사이의 스케줄링도 정해야 합니다. 2가지 정책이 있습니다.
-
고정 우선순위 스케줄링 : 하나의 큐를 모두 스케줄한 후 다음 큐로 넘어가는 방식입니다. 이 경우, 기아 프로세스가 발생할 수 있습니다.
-
시간 할당 : 각 큐는 일정량의 CPU 시간을 할당 받습니다. 할당 받은 시간 단위로 해당 큐의 프로세스를 스케줄 할 수 있습니다. 예를 들어 foreground 큐는 80%의 시간을 할당받아 RR 방식으로 스케줄을 하고, background 큐는 20%의 시간을 할당받아 FCFS 방식으로 스케줄 할 수 있습니다.
Multi-level Feedback Queue
멀티레벨 큐를 좀 더 유연하게 사용하기 위해 프로세스가 큐 사이를 이동할 수 있도록 하는 방식입니다. 예를 들어
- 프로세스가 CPU 시간을 너무 많이 사용하면 낮은 우선순위 큐로
- 입출력 중심의 프로세스와 대화형 프로세스들은 높은 우선순위 쿠로
- 낮은 우선순위 큐에서 너무 오래 대기하는 프로세스는 높은 우선순위로 : Aging
앞서 발생했던 기아 프로세스 문제는 Muti-level Feedback Queue 로 해결할 수 있습니다.
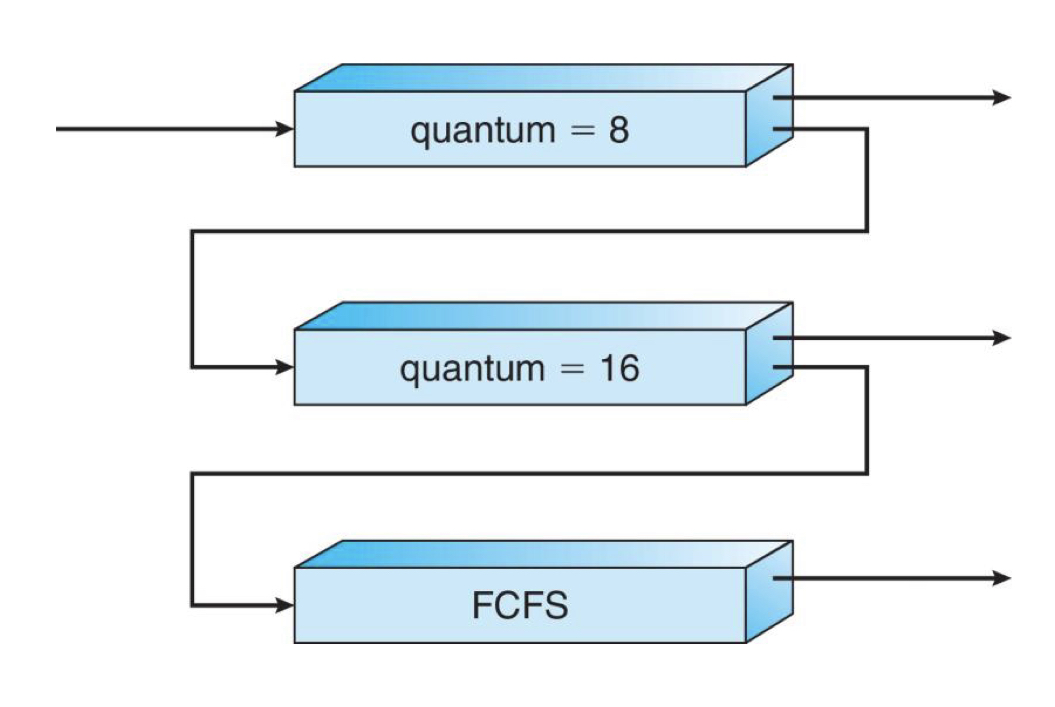
새 프로세스는 Q0 큐에서 Quantum = 8 인 Round-Robin에 따라 스케줄링 됩니다. 만약 8 milli-second 안에 끝나지 않았다면, Q1 큐로 이동합니다. Q1 큐에서 Quatum = 16 인 Round-Robin 에 따라 스케줄링 됩니다. 16 miiili-second 이후에도 완료되지 않을 경우, Q2 큐로 이동하여 FCFS 방식에 따라 스케줄링됩니다.
