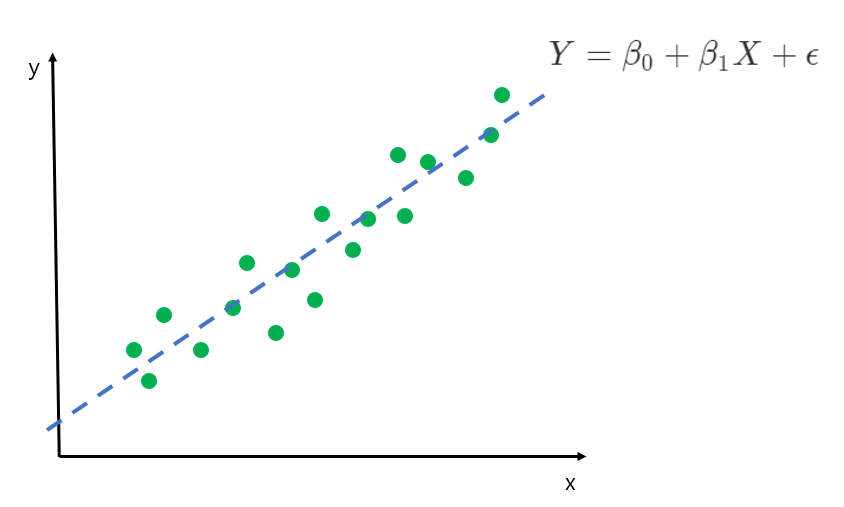
1. 선형 회귀
1) 선형 회귀란?
알려진 다른 관련 데이터 값을 사용하여 알 수 없는 데이터의 값을 예측하는 데이터 분석 기법
이 과정에서 선형 방정식을 수학적으로 모델링한다.
선형 회귀 모델은 비교적 간단하며, 예측을 생성하기 위한 해석하기 쉬운 수학 공식을 제공한다. 다양한 분야에서 예비 데이터 분석을 수행하고 미래 추세를 예측하는 데 사용된다.
2) 선형 회귀의 종류
(1) 단순 선형 회귀
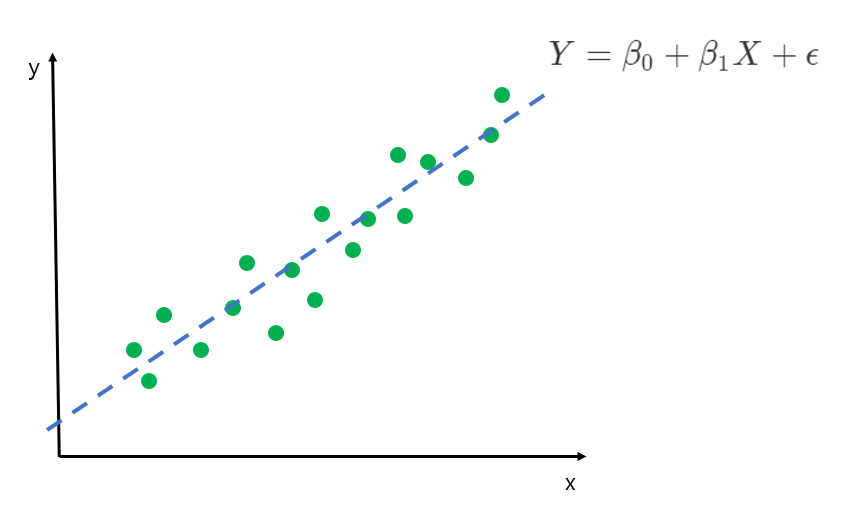
하나의 독립 변수와 하나의 종속 변수 간의 관계를 모델링한다. 이는 2차원 공간에서 선형 함수로 표현 가능하며, 가장 기본적인 형태의 선형 회귀다.
(2) 다중 선형 회귀
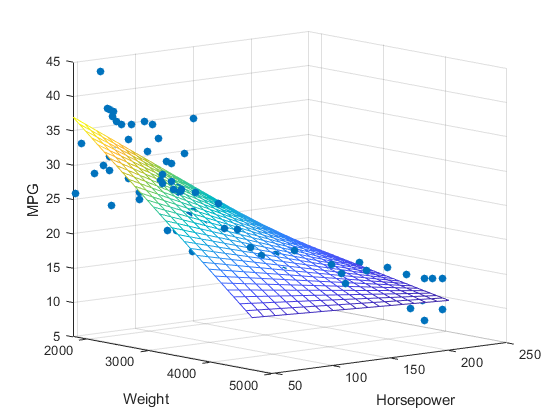
두 개 이상의 독립 변수와 하나의 종속 변수 간의 관계를 모델링한다. 실제 문제 해결에 있어서 다중 선형 회귀가 더 자주 사용된다.
3) 선형 회귀의 수학적 모델
선형 회귀의 기본 공식은 Y = β0 + β1X1 + β2X2 + ... + βnXn + ε로 표현된다. 여기서 Y는 종속 변수, X1, X2, ..., Xn은 독립 변수, β0, β1, ..., βn은 회귀 계수, 그리고 ε는 오차항을 나타낸다
4) 선형 회귀의 적용
활용 분야
선형 회귀는 비즈니스 인텔리전스, 생물학, 행동과학, 환경과학, 사회과학 등 다양한 분야에서 활용된다. 이를 통해 데이터로부터 유의미한 인사이트를 도출하고 미래를 예측할 수 있다.
선형 회귀는 그 구조가 단순함에도 불구하고 강력한 예측력을 가지고 있다. 이러한 선형 회귀 분석을 통해 우리는 복잡한 현상 속에서 변수 간의 관계를 이해하고, 미래의 값을 예측할 수 있다. 따라서 데이터 과학과 인공지능 분야에서 선형 회귀는 매우 중요한 도구로 자리 잡고 있다.
2. CNN(합성곱 신경망)
1) CNN이란?
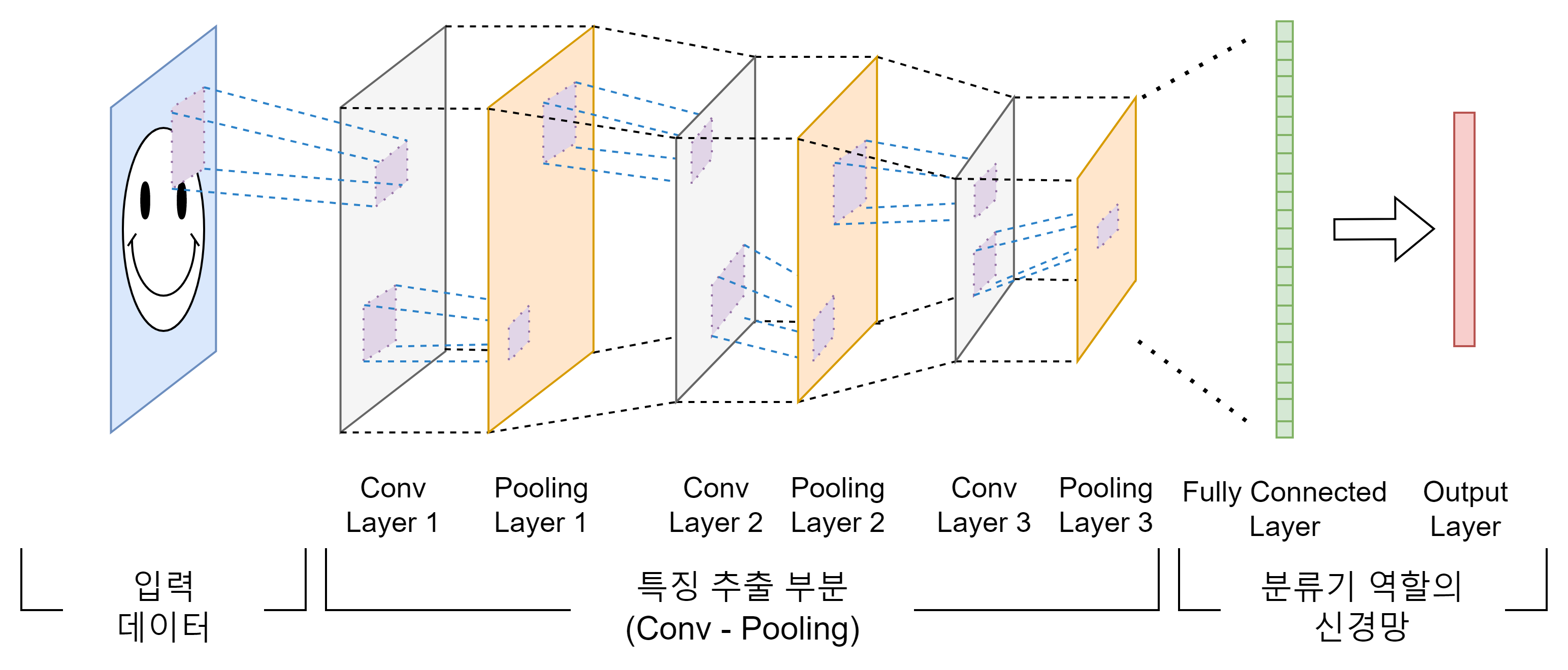
딥러닝에서 이미지나 영상 데이터를 처리할 때 주로 사용되는 인공 신경망 구조
CNN은 이미지 인식, 분류, 객체 감지 등 다양한 컴퓨터 비전 문제를 해결하는 데 탁월한 성능을 보인다.
2) CNN의 기본 구조와 원리
(1) 핵심 개념
CNN은 인간의 시신경 구조를 모방하여, 이미지를 인식하기 위해 패턴을 찾는 데 특히 유용하다. 이는 데이터를 직접 학습하고 패턴을 사용해 이미지를 분류하는 방식으로 작동한다.
(2) 구조적 특징
CNN은 여러 계층(layer)으로 구성되며, 주요 계층은 합성곱 계층(Convolutional Layer), 풀링 계층(Pooling Layer), 완전 연결 계층(Fully Connected Layer) 등이 있다. 이 계층들은 이미지의 특징을 추출하고, 이를 바탕으로 분류나 인식을 수행한다.
3) CNN의 핵심 기능
(1) 합성곱 계층
이미지의 특징을 추출하는 주요 계층으로, 필터(또는 커널)를 사용하여 입력 이미지와의 합성곱 연산을 수행한다. 이 과정에서 이미지의 중요한 특징이 강조된다.
(2) 풀링 계층
합성곱 계층을 통해 추출된 특징 맵(feature map)의 크기를 줄이는 역할을 한다. 이는 계산량을 감소시키고, 과적합을 방지하는 데 도움을 준다.
4) CNN의 활용 분야
자율주행 자동차, 얼굴 인식, 객체 인식 등 컴퓨터 비전이 필요한 다양한 분야에서 활용된다. CNN은 이미지의 공간 정보를 유지한 채로 학습을 하게 하여, 높은 인식률과 분류 성능을 제공한다.
3. 전이학습과 전이학습 예제
1) 전이학습이란?
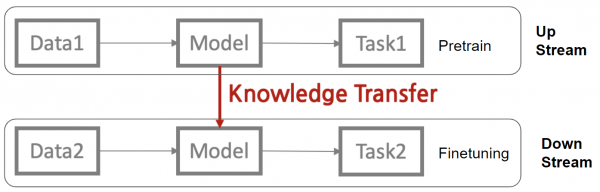
이미 학습된 모델의 지식을 새로운 문제에 적용하여 학습 시간을 단축시키고, 학습이 필요한 데이터의 양을 줄이는 기법이다. 이 방법은 특히 데이터가 부족한 상황에서 유용하게 사용된다.
2) 전이학습의 기본 원리
전이학습은 한 작업에서 학습된 모델을 새로운 관련 작업에 재사용한다. 이를 통해 새로운 작업에 대한 모델의 성능을 향상시킬 수 있다.
전이학습을 사용하면 적은 데이터로도 높은 성능의 모델을 빠르게 학습시킬 수 있다. 이는 이미 학습된 모델이 가지고 있는 지식을 활용하기 때문이다.
3) 전이학습의 예제
(1) 이미지 분류
사전에 대규모 이미지 데이터셋으로 학습된 모델(예: ImageNet)을 기반으로 새로운, 더 작은 데이터셋에 대한 이미지 분류 작업을 수행할 수 있다. 이 경우, 사전 학습된 모델의 일부를 재사용하고, 최종적인 분류 계층만 새로운 데이터셋에 맞게 조정하여 학습한다.
import sys
import numpy as np
import cv2
filename = 'data/beagle.jpg'
img = cv2.imread(filename)
if img is None:
print('Image load failed!')
exit()
# Load network
net = cv2.dnn.readNet('data/bvlc_googlenet.caffemodel', 'data/deploy.prototxt')
if net.empty():
print('Network load failed!')
exit()
# Load class names
classNames = None
with open('data/classification_classes_ILSVRC2012.txt', 'rt') as f:
classNames = f.read().rstrip('\n').split('\n')
# Inference
inputBlob = cv2.dnn.blobFromImage(img, 1, (224, 224), (104, 117, 123))
net.setInput(inputBlob)
prob = net.forward()
# Check results & Display
out = prob.flatten()
classId = np.argmax(out)confidence = out[classId]
text = '%s (%4.2f%%)' % (classNames[classId], confidence * 100)
cv2.putText(img, text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 1, cv2.LINE_AA)
cv2.imshow('img', img)
cv2.waitKey()
cv2.destroyAllWindows()
(2) 자연어 처리(NLP)
BERT와 같은 사전 학습된 언어 모델을 사용하여 특정 NLP 작업(예: 감정 분석, 질문 응답 시스템)에 적용할 수 있다. 이때, 사전 학습된 모델의 구조와 가중치를 초기 상태로 사용하고, 특정 작업에 맞게 미세 조정을 진행한다.
4. 손가락 욕 모자이크 프로그램 만들기
!python -m pip install --upgrade pip
pip install opencv-python mediapipe
pip install google import cv2
import mediapipe as mp
# 손 인식 모델 초기화
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(static_image_mode=False, max_num_hands=1)
# 모자이크 함수 정의
def mosaic(img, x, y, w, h, size=30):
for i in range(int(w / size)):
for j in range(int(h / size)):
xi = x + i * size
yi = y + j * size
img[yi:yi + size, xi:xi + size] = cv2.blur(img[yi:yi + size, xi:xi + size], (23, 23))
# 카메라 연결
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
continue
# 화면 반전
frame = cv2.flip(frame, 1)
# 손 인식
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(rgb_frame)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
# 중지 손가락 끝 좌표 추출
index_finger_tip_y = hand_landmarks.landmark[mp_hands.HandLandmark.INDEX_FINGER_TIP].y * frame.shape[0]
middle_finger_tip_y = hand_landmarks.landmark[mp_hands.HandLandmark.MIDDLE_FINGER_TIP].y * frame.shape[0]
# 중지 손가락을 올린 경우에만 손에 모자이크 적용
if index_finger_tip_y > middle_finger_tip_y:
# 손의 경계 상자 추정
x_min, y_min = int(min(l.x * frame.shape[1] for l in hand_landmarks.landmark)), int(min(l.y * frame.shape[0] for l in hand_landmarks.landmark))
x_max, y_max = int(max(l.x * frame.shape[1] for l in hand_landmarks.landmark)), int(max(l.y * frame.shape[0] for l in hand_landmarks.landmark))
# 손에만 모자이크 적용
mosaic(frame, x_min, y_min, x_max - x_min, y_max - y_min)
# 화면 표시
cv2.imshow('Hand Gesture Mosaic', frame)
# 종료 키 설정
if cv2.waitKey(10) & 0xFF == ord('q'):
break
# 리소스 해제
cap.release()
cv2.destroyAllWindows()
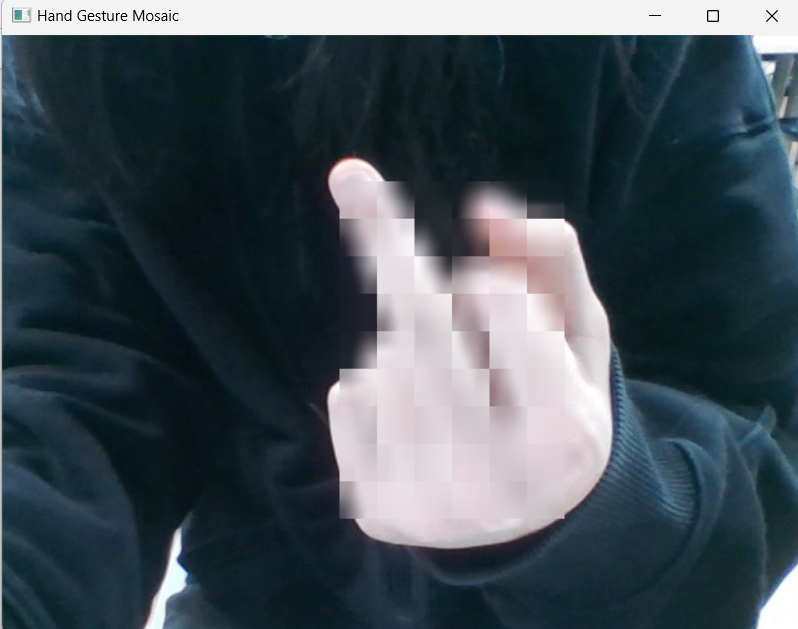
손가락 욕이 모자이크 되는 모습이다.
