
일상적인 대화 & 연애 관련 주제의 한국어 대화 데이터셋과 'BERT'모델을 이용하여, 입력된 한국어 대화가 일상적인 대화인지 연애 관련 대화인지 분류하는 모델을 만들어 보았다😊
그 전에 BERT 모델에 대해 공부한 내용을 이 글에 정리하고, 코드에 대해서는 다음 글에서 적으려고 한다🥰 (너무나 정리가 잘 되어있는 이 글과 BERT논문을 보고 공부&정리를 한건데 이 글을 읽는 것이 훨씬 더 도움이 된다ㅎ)
👉블로그👈에도 프로젝트 관련 글을 작성해놓았는데, 프로젝트다운 글이다..ㅎ (코드가 다 있긴 한데 복붙을 쉽게 하기 위해선 깃허브(관리x) 참고!)
👇이론 START!👇
BERT란?

BERT는 Bidirectional Encoder Representations from Transformers의 약자로 말 그대로 Transformers 라는 기계번역 모델의 Encoder 구조를 갖는 기계번역 모델이다. 즉, Transformers 라는 모델의 일부분을 사용하고 성능을 업그레이드한 모델이 BERT인 것이다(쿠키몬스터, 엘모 등이 있는 세서미 스트리트의 캐릭터 BERT에서 따오기도 했다고 한다!). 2018년 10월 구글에서 발표한 BERT는 NLP 분야에서 매우 훌륭한 성능을 보여주었고, 현재 굉장히 촉망받는 기계번역 모델이라고 한다!
BERT의 구조 및 특징
이론을 공부할 때는 논문의 Abstract를 읽는 편인데, BERT논문에서 첫 페이지 Abstract을 보면, 개발자들이 강조하는 BERT의 특징과 구조를 살펴볼 수 있다.
Abstract
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models (Peters et al., 2018a; Radford et al., 2018), BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).
(1) Transformer란?
위 Abstract에서도 알 수 있듯이 BERT는 Transformer 라는 모델의 인코더 구조를 여러 층으로 쌓은 형태의 구조를 가지고 있는데, 아래 이미지는 Transformer 모델의 구조로, 왼쪽에는 인코더 역할을 하는 구조와 오른쪽에는 디코더 역할을 하는 구조를 갖고 있다. 따라서 BERT는 Transformer의 인코더 구조를 이용하기 때문에 왼쪽 부분의 구조만을 이용한다.
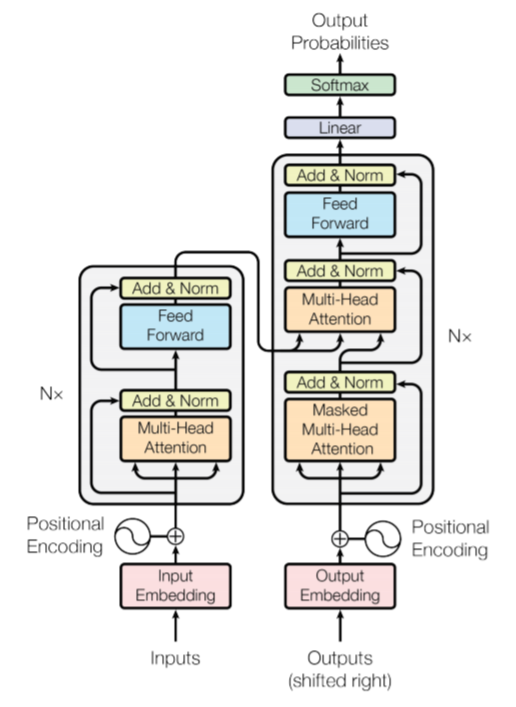
간략하게 Transformer의 인코더 부분을 설명하자면, Transformer는 인코더와 디코더로 이루어져 있고, n개의 인코딩 층을 갖고 있다. 그리고 하나의 인코더 층에는 서브층이 크게 2개로 나누어져 있는데, 각각 셀프 어텐션, 피드 포워드 신경망 구조로 이루어져 있다. 여기서 중요한 게 바로 셀프 어텐션인데, 셀프 어텐션이란 문장 내의 단어들의 유사도를 구하는 것을 말한다. 따라서 한 문장이 이러한 구조를 가지는 BERT의 인코더를 거치면 입력된 문장은 문맥의 정보를 모두 가진 문장으로 출력되는데, 즉 겉으로는 입력된 문장이 그대로 출력된 것으로 보이지만 실제론 문맥의 정보를 갖고 있는 문장으로 출력되는 것이다.
(2) BERT의 입력 - 문맥을 반영하는 임베딩(Contextual Embedding)
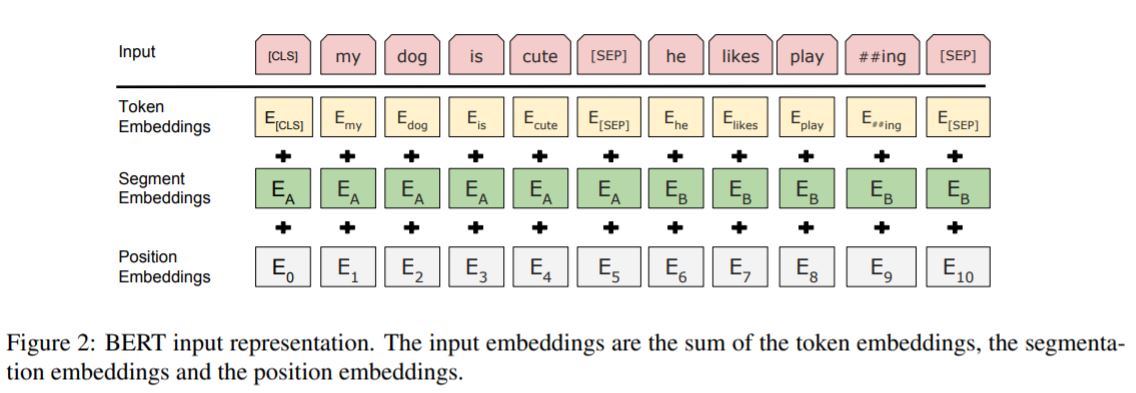
한편, 임베딩 벡터들이 BERT의 입력으로 들어가게 되는데, BERT의 연산을 거친 후의 출력 임베딩은 위에서도 언급했듯이, 문장의 모든 문맥이 반영된 임베딩이 된다. 예를 들어, [CLS], I, like, coffee, 라는 문장이 들어가게 되면 그대로 [CLS], I, like, coffee 라는 단어 벡터들이 출력되는데, 이 단어 벡터들 하나하나 모두 [CLS], I, like, coffee라는 단어 벡터들을 참고(연산)한 벡터가 된다.
이렇게 단어를 참고하도록 만드는 연산은 BERT 모델의 12개의 층에서 이루어지는데, 이 연산은 바로 위에서 잠깐 언급했던 '셀프 어텐션'을 통해 이루어진다.
(3) 셀프 어텐션(self attention)이란 뭘까?
셀프어텐션은 트랜스포머에서 등장하여 크게 주목받기 시작했는데, 어텐션을 자기 자신에게 수행하는 것을 셀프 어텐션이라고 한다. 그렇다면 어텐션이란 뭘까? 어텐션에서도 다양한 종류가 있는데 간단하게 말하자면, 어텐션 함수는 쿼리(Query)가 주어졌을 때, 이 쿼리와 여러 개의 키(key)와의 유사도를 각각 구하고, 구한 유사도를 가중치로 설정하여 각각의 값(value)을 구한 뒤, 이 값(유사도가 반영된 값)들을 모두 가중합하여 반환하는 함수를 말한다. 예를 들어, 한 텍스트 문장이 쿼리로 입력될 때, 각 단어 벡터들과의 유사도를 계산해 이 유사도를 가중합하여 반환된 값이 그 문장의 어텐션 값이 된다. 어텐션에 대해서는 다음 논문을 참고하면 좋을 것 같다.
그렇다면, 셀프 어텐션 값을 구하기 위해서 입력된 문장의 단어 벡터(쿼리)에 대해 쿼리(query), 키(key), 값(value) 벡터가 정의되어야 할 것이다. 그 과정은 아래 이미지(출처)를 통해 쉽게 이해할 수 있다.
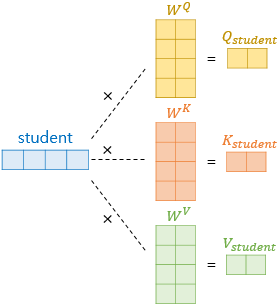
'student'라는 단어 벡터가 입력되었을 때, 각각 쿼리, 키, 값의 가중치 행렬을 곱해주어 쿼리, 키, 값 벡터를 얻어낸다. 이렇게 쿼리 벡터, 키 벡터, 값 벡터를 얻어냈다면 쿼리 벡터는 모든 키 벡터에 대해 어텐션 스코어(attention score)를 구하게 되고, 이를 이용하여 모든 값 벡터를 가중합하여 어텐션 값을 구하게 된다.
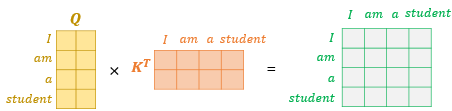
한편, 이러한 연산은 각 단어마다가 아닌 문장 전체에 대해 행렬 연산으로도 일괄적으로 연산이 가능한데, 위와 같이 문장에 대한 쿼리 벡터, 키 벡터의 연산을 통해 값 벡터 행렬을 구할 수 있게 된다.
마지막으로, 쿼리 벡터와 키 벡터가 연산되어 나온 행렬에 전체적으로 특정값(key벡터 차원의 제곱근값)을 나누어 준 뒤, 소프트맥스 함수를 적용해주고, 가중치가 계산된 값 벡터를 곱하게 되면 최종적으로 각 단어의 어텐션 값을 가지는 어텐션 값 행렬이 도출된다.
앞에서 '어텐션 함수는 쿼리(Query)가 주어졌을 때, 이 쿼리와 여러 개의 키(key)와의 유사도를 각각 구하고, 구한 유사도를 가중치로 설정하여 각각의 값(value)을 구한 뒤, 이 값(유사도가 반영된 값)들을 모두 가중합하여 반환하는 함수를 말한다' 라는 설명을 했는데, 다시 읽어보면 무슨 말인지 어느정도 이해가 될 것이다.
(4) WordPiece
한편, 어떠한 모델이든, 단어 자체를 텍스트 형식으로 입력할 수 없으니 단어를 토큰으로 만든 뒤 정수 인코딩, 패딩 과정을 거쳐야 한다. 따라서 BERT에서는 WordPiece라는 서브워드 토크나이저를 사용하는데, WordPiece는 기본적으로 자주 등장하는 단어를 단어 집합에 추가한다는 점에서 다른 토크나이저와 비슷하다. 하지만 빈도가 낮은 단어는 더 작은 단어인 서브워드로 분리되어 단어 집합에 추가된다는 특징을 갖고 있다.
예를 들자면, 아래와 같은 문장이 있다고 할 때, 일반적인 토크나이저는 다음과 같이 토큰화 될 것이다.
I am rewriting the posts
'I', 'am', 'rewriting', 'the', 'posts'
하지만 BERT가 사용하는 WordPiece는 다음과 같이 토큰화 한다.
'I', 'am', 're', '##writ', '##ing', 'the', 'post', '##s'
여기서 알 수 있듯이, 단어 집합에 단어가 존재하지 않으면 단어를 더 쪼개려고 하고, 서브워드로 쪼개졌다는 것을 '#'를 붙여 표시를 하게 된다. 이렇게 표기를 함으로써 해당 서브워드가 단어의 중간부터 시작된 단어라는 것을 알려주고, 또, 다시 원래 단어로 쉽게 복원을 할 수 있게 된다. 이렇게 토큰화를 하는 것은 BertTokenizer 라이브러리를 import해서 사용할 수 있다(코드에서 다시 설명!). 아무튼 이러한 방식으로 토큰화가 이루어지고, BERT의 입력으로 들어가게 된다.
(5) Pre-training
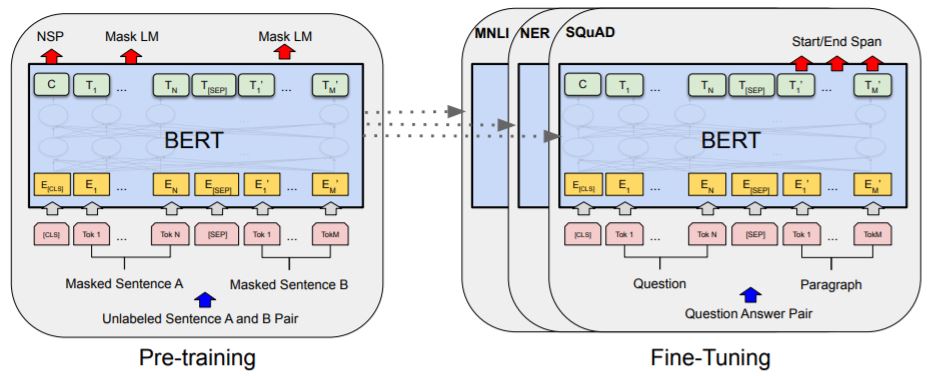
위에서 언급했던 논문의 Abstract에 강조되어 있듯이, 기계번역 성능이 좋은 BERT의 가장 큰 특징은 방대한 양의 데이터(약 33억개 단어/레이블X)로 pretrain 되어 있다는 것이다. 이는 많은 양의 데이터로 먼저 학습이 이루어졌다는 것을 의미하는데, 많은 양의 데이터가 먼저 학습되어 있기 때문에 BERT를 사용하는 누구든지 33억개의 단어를 학습시킬 시간을 단축할 수 있게 된다.
그렇다면 BERT의 사전 훈련(Pre-triaining)은 어떻게 이루어졌는지 조금만 더 살펴보도록 하겠다.

위 이미지는 BERT 논문에서 다른 알고리즘과 학습 방식의 차이를 나타낸 이미지로, BERT의 경우 "bidirectional Transformer" 구조를 갖는다. 여기서 'bidirectional'이란 양방향을 의미하는데, 즉, 단어를 예측할 때 모든 문맥의 단어를 참고하여 단어를 예측한다는 것이다. 이에 반해, OpenAI GPT는 이전 단어들로만 다음 단어를 예측하고, ELMo의 경우 정방향 LSTM, 양방향 LSTM 알고리즘을 이용하여 단어를 예측하는 방식을 사용한다. 이렇게 보면, BERT의 양방향 언어 모델이 심플하면서도 가장 적당해 보인다.
한편, BERT가 양방향으로 단어를 참고하여 다음 단어를 예측한다 했는데, 그렇다면 어떠한 방법으로 학습되는 것일까? 바로 말하자면, BERT는 (1)Masked Language Model(MLM)과 (2)Next Sentence Prediction(NSP)의 방식으로 훈련된다.
(1) Masked Language Model (MLM)
The masked language model randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked arXiv:1810.04805v2 [cs.CL] 24 May 2019 word based only on its context. Unlike left-toright language model pre-training, the MLM objective enables the representation to fuse the left and the right context, which allows us to pretrain a deep bidirectional Transformer
BERT 논문에서 MLM에 대한 내용이다. MLM이란 입력으로 들어가는 단어 토큰의 일부분을 랜덤으로 마스킹 한 뒤, 모델이 문맥을 통해서 원래 단어를 예측하도록 하는 학습 모델을 말한다. 마스킹을 하는 것도 어느정도의 규칙이 있는데, 결과적으로 약 15%의 단어만 마스킹한다. 한편, 문맥을 양방향으로 예측하는데, 이는 단방향으로 예측하는 것보다 훨씬 강력하다고 논문에서는 계속 강조하곤 한다.
(2) Next Sentence Prediction (NSP)
두 번째로 Next Sentence Prediction(NSP)이라는 것을 학습하는데, 두 개의 문장을 주고 이 문장들이 이어지는 문장인지를 맞추도록 학습시키는 것이다. 문장마다 문장의 끝에 [SEP]이라는 토큰을 붙여 문장을 구분하는데, BERT는 이를 기점으로 해당 문장이 이어지는 문장인지 이어지지 않는 문장인지 판별하는 학습을 하게 된다.
(6) Fine-tuning(파인 튜닝)
여기까지, BERT가 MLM, NSP을 통해서 pre-training 하는 것을 살펴보았는데, 위에서도 언급했듯이 BERT는 이미 BooksCorpus의 800 milion 단어들을 학습시킨 모델이다. 따라서 일부분의 데이터만 추가로 학습시켜주고, 자신의 목적 또는 용도에 따라 output layer를 추가해주면 되는데, 이러한 것을 바로 파인튜닝(finetuning)이라고 한다. 즉, 파라미터를 재조정하고 output layer를 추가함으로써 원하는 목적에 맞게 사용할 수 있고, 다양한 질의응답의 챗봇을 만들 수 있다.
예를 들어, BERT를 이용하여 전자기기 서비스 상담원 챗봇을 만들고자 할 때, 상담시 자주 하는 질문 텍스트들을 추가로 학습시킨 뒤, 적절한 답변이 도출되도록 하는 output layer를 추가하여 multi-classification 모델을 만들면 되는 것이다. 어느정도 데이터가 많아야 겠지만 이미 많은 단어들이 학습되어 있기 때문에 정확도가 상당히 높을 수 있다.
BERT Project Description
이렇게 BERT에 대해 공부한 것을 나름대로 적어보았다. 많은 부분이 빠져있긴 하지만 모든 것을 정리하려면 Transformer를 설명해야 하고, Transformer를 설명하려면 Attention, Attention에 대해 설명하자니 seq2seq2까지 이어진다.. 따라서 핵심적인 내용 위주로 정리한 것이다.
한편, BERT를 이용하여 만들기 쉽겠다 생각한 모델이 바로 이진분류 모델이었다. 한 문장이 주어지면 'A' 또는 'B'라는 결과값이 나오게 하는 모델이 적합하겠다 생각했고, 2개의 노드가 있는 output layer 층을 추가로 만들어주기만 하면 되기 때문이다.(하지만 사실 이진분류용 BERT 라이브러리가 있어 그것을 사용했다..)
한편, 추가 학습 데이터가 필요하기 때문에 우선 데이터를 찾아보았다. 한국어 대화 데이터가 AIHUB 플랫폼에 몇 개 있는 것을 제외하고는 잘 못봤는데, 깃허브에서 제공되는 한국어 대화 데이터가 있었다. 해당 데이터에 대해 알아보니, 사람들이 챗봇 모델을 만들 때 많이 참고한 데이터 같았다. 이 데이터는 크게 3가지 유형의 한국어 대화 문장을 갖는데, 일상다반사, 연애(긍정), 이별(부정)과 관련된 문장이었다. 하지만 이진분류를 할 예정이기 때문에 연애(긍정) 문장과 이별(부정) 문장을 합쳐 연애와 관련된 문장을 통일하고, 일상 대화 문장과 함께 이진분류 모델을 만들어 보게 되었다.
이렇게 BERT 이론과 프로젝트 설명에 대해 간단히 글을 적었는데, 다음 글에서는 수행한 프로젝트의 코드를 보며 BERT를 좀 더 이해하고자 한다!🥰
