✔️ EDA 기본 환경
- conda
- jupyter notebook
- vscode
- colab
Conda
- miniconda (교육용으로 적절한 anaconda의 간소화된 가상 환경)
- 실습을 위한 기본(base) 환경이 아닌 'ds_study'의 이름으로 새로운 가상환경 생성
Jupyter Notebook
- 오픈 소스 소프트웨어
- 여러 개의 프로그래밍 언어에 걸쳐 인터랙티브 컴퓨팅을 위한 서비스 개발
<주피터 노트북 단축키>
- shift + Enter : 현재 셀 실행 및 다음 셀 생성
- esc 키 : 실행 셀 타이핑 모드 빠져나가기
- m 키 : 현재 코드 셀을 마크다운 셀로 변경
- a 키 : 이전 셀 추가
VSCode
- visual studio code
- 소스 코드 편집기
- miniconda Prompt에서 생성할 폴더 경로로 이동(cd) 후 실행(code .)
Google Colab
- google에서 만든 jupyter 기반의 웹용 서비스
- 별도의 설치 없이 온라인으로 사용가능하며, 개인 google drive와 연동하여 사용가능
✔️ Pandas 기초 ⭐
- python에서 R만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
- 누군가 스테로이드를 맞은 엑셀로 표현함
import
import pandas as pd
import numpy as np- 모듈 약어(alias) 설정
- pandas는 통상 pd
- numpy는 통상 np
- Series
- index와 value로 이루어져 있습니다
- 한 가지 데이터 타입만 가질 수 있음
- int, float, object, category, datetime
pd.Series([1, 2, 3, 4], dtype=np.float64)
# 출력
# 0 1.0
# 1 2.0
# 2 3.0
# 3 4.0
# dtype: float64pd.Series(np.array([1, 2, 3]))
# 출력
# 0 1
# 1 2
# 2 3
# dtype: int32pd.Series({'Key':'Value'})
# 출력
# Key Value
# dtype: objectdates = pd.date_range("20210101", periods=6)
dates
# 출력
# DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04',
# '2021-01-05', '2021-01-06'],
# dtype='datetime64[ns]', freq='D')- DataFrame
- pd.Series() : index, value
- pd.DataFrame() : index, value, column
# 표준 정규분호에서 샘플링한 난수 생성 : np.random.randn(행, 열)
datas = np.random.randn(6, 4)
df = pd.DataFrame(datas, index=dates, columns=['A', 'B', 'C', 'D'])
df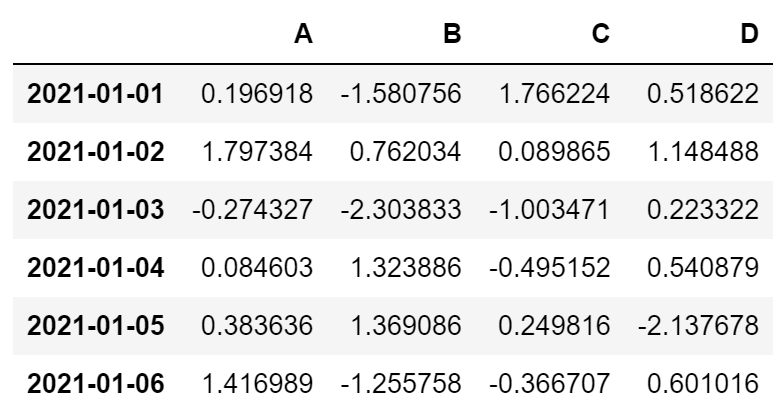
정보탐색
- df.head() : 첫 5행(default=5) 확인
- df.tail() : 마지막 5행 확인
- df.index : 인덱스 확인
- df.columns : column 확인
- df.values : value 확인
- df.info() : 데이터 프레임의 기본 정보 확인 (크기, 데이터 형태 등)
- df.describe() : 데이터 프레임의 기술통계 정보 확인
- df.sortvalues(by="기준컬럼", ascending=True(기본값오름차순), inplace=True)
- inplace=True : 원본데이터에 변경사항 적용
- 특정 컬럼(열)을 기준으로 데이터를 정렬
데이터 선택
# 한개 컬럼 선택
df['A']
# 이 선택 방법은 컬럼명이 문자열일 경우에만 불러올 수 있음( ex. 컬럼명: 3, '3' 둘다 오류남)
df.A
# 두개 이상 컬럼 선택
#df['A', 'B'] -> Error
df[['A', 'B']]- offset index
- [n:m] : n부터 m-1까지
- 인덱스나 컬럼의 이름으로 slice 하는 경우 끝을 포함
# 인덱스 0 ~ 2 행까지 출력
df[0:3]
# 1일부터 4일까지 모두 출력
df['20210101':'20210104']- loc : location
index 이름으로 특정 행, 열을 선택
## loc[행, 열]
# (:) 전체 행, (['A', 'B']) A, B 컬럼 출력
df.loc[:, ['A', 'B']]
# 1일부터 4일 행, (["A", "D"]) A, D 컬럼 출력
df.loc["20210102":"20210104", ["A", "D"]]
# 1일부터 4일 행, ("A":"D") A ~ D 컬럼 출력
df.loc["20210102":"20210104", "A":"D"]
# 2일 행, (["A", "B"]) A, B 컬럼 출력
df.loc["20210102", ["A","B"]]- df.iloc : intiger location
컴퓨터가 인식하는 인덱스 값으로 선택
# 행 인덱스가 3인 데이터('2021-01-04')의 모든값 출력(시리즈 형태로 반환)
df.iloc[3]
# df.iloc[행, 열]
df.iloc[3, 2]
# 인덱스 : 3~4행, 0~1 컬럼
df.iloc[3:5, 0:2]
# 인덱스 : 1,2,4 행, 0,2 컬럼
df.iloc[[1, 2, 4], [0, 2]]
# 전체행, 인덱스 : 1~2 컬럼
df.iloc[:, 1:3]조건에 맞는 dataframe 확인
- df[ condition ]

컬럼 추가
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 수정
df['E'] = ['one', 'one', 'two', 'three', 'four', 'six']
df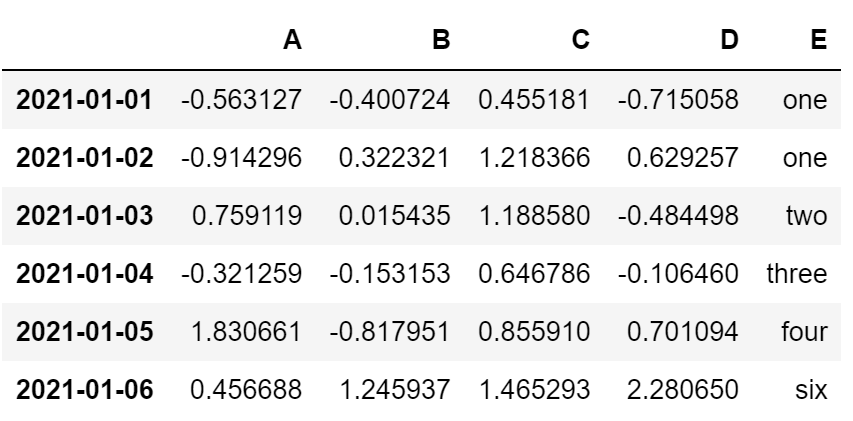
- df.isin()
특정 요소가 있는지 확인
# E 컬럼에 'two', 'six' 값이 있는지 확인
df['E'].isin(['two', 'six'])
# 출력
# 2021-01-01 False
# 2021-01-02 False
# 2021-01-03 True
# 2021-01-04 False
# 2021-01-05 False
# 2021-01-06 True
# Freq: D, Name: E, dtype: booldf[df['E'].isin(['two', 'six'])]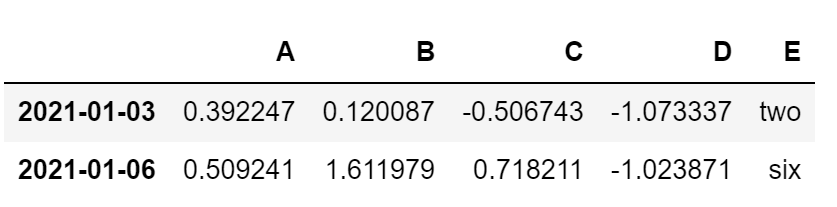
특정 컬럼 제거
- del
- drop
del df['E']
df# axis : 0은 행(default), 1은 열
df.drop(['D'], axis=1) # 열 삭제
df.drop(['20210104']) # 행 삭제apply()
- 함수 적용
df['A'].apply('sum') # 3.955685591404973
df['A'].apply("mean") # 0.6592809319008288
df['A'].apply("min"), df['A'].apply("max") # (-0.04249566107799036, 1.3038916847394042)df[['A', 'D']].apply("sum")
# 출력
# A 3.955686
# D -1.658560
# dtype: float64df['A'].apply(np.sum)
# 출력
# 2021-01-01 0.959249
# 2021-01-02 0.833553
# 2021-01-03 0.392247
# 2021-01-04 -0.042496
# 2021-01-05 1.303892
# 2021-01-06 0.509241
# Freq: D, Name: A, dtype: float64df.apply(np.sum)
# 출력
# A 1.247785
# B 0.211866
# C 5.830115
# D 2.304984
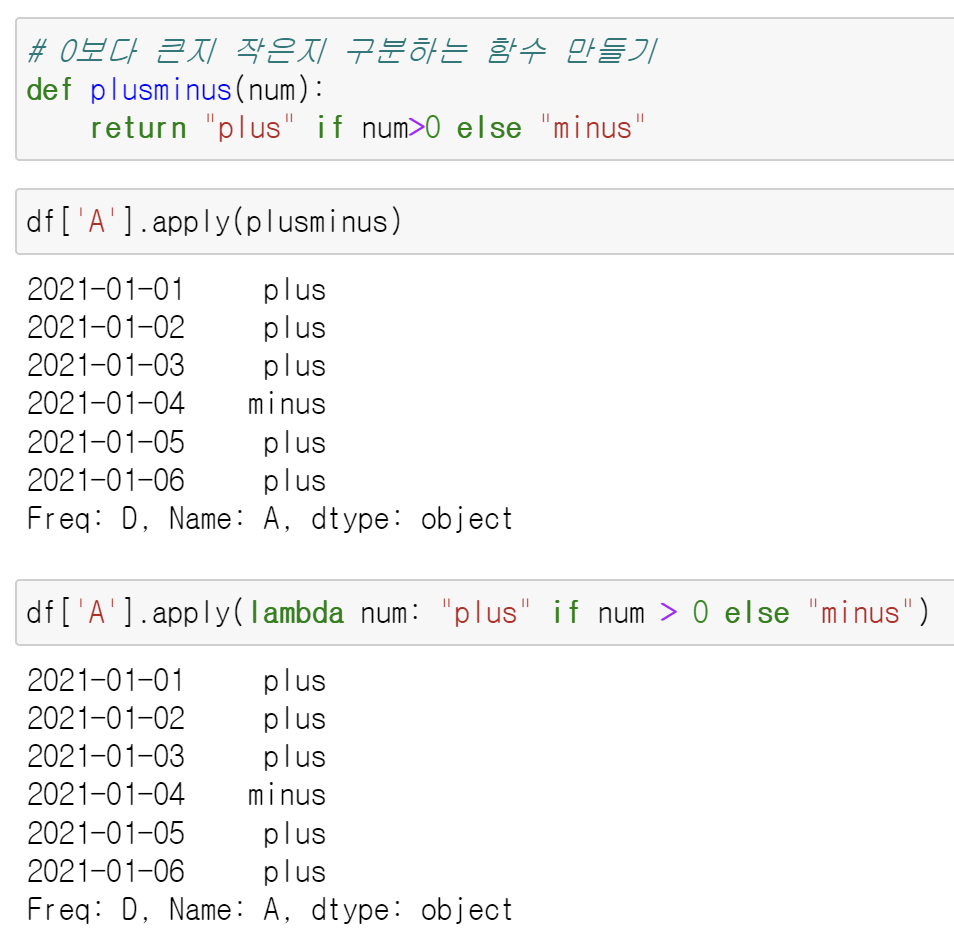
# dtype: float64- 0보다 큰지 작은지 구분하는 함수 생성하여 apply 적용
✔️ 서울시 CCTV 현황분석 1~2
→ 목표
- 서울시의 구 별 cctv 현황과 구 별 인구현황 데이터를 이용하여 전체적인 경향을 파악하고, 파악한 경향에서 벗어난 데이터를 분석해보기
- 데이터 출처
1) 서울시 구별 CCTV 현황 : http://data.seoul.go.kr/dataList/OA-2734/F/1/datasetView.do
2) 구별 인구 현황 : https://data.seoul.go.kr/dataList/419/S/2/datasetView.do
1. 데이터 읽기
csv 데이터 읽기
import pandas as pd
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv", encoding='utf-8')
# head() : 기본값 5
CCTV_Seoul.head()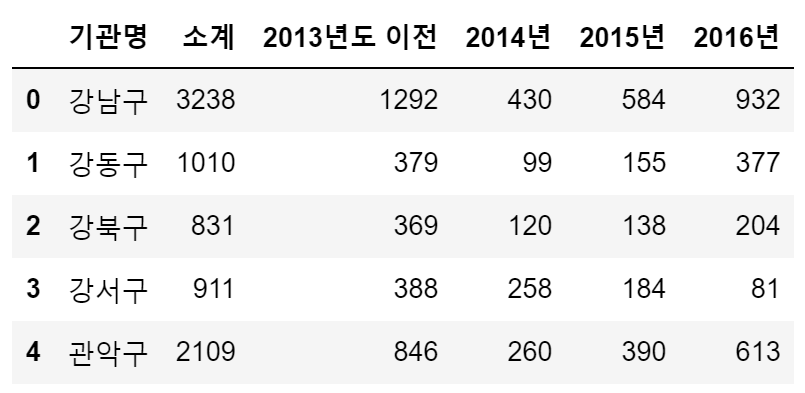
CCTV_Seoul.columns
# 출력
# Index(['기관명', '소계', '2013년도 이전', '2014년', '2015년', '2016년'], dtype='object')excel 데이터 읽기
# usecols와 같은 모든 옵션 설정은 pandas 공식문서 참조
# pandas.read_excel documentation 검색
# "https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html"
pop_Seoul = pd.read_excel(
"../data/01. Seoul_Population.xls", header = 2, usecols="B, D, G, J, N"
)
pop_Seoul.head()- header : 자료를 읽기 시작할 행(header) 지정
- usecols : 읽어올 엑셀의 컬럼 지정
컬럼명 변경
- CCTV_Seoul
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace=True)
# inplace=True : 원본 데이터에 자동으로 반영하는 옵션
CCTV_Seoul.head()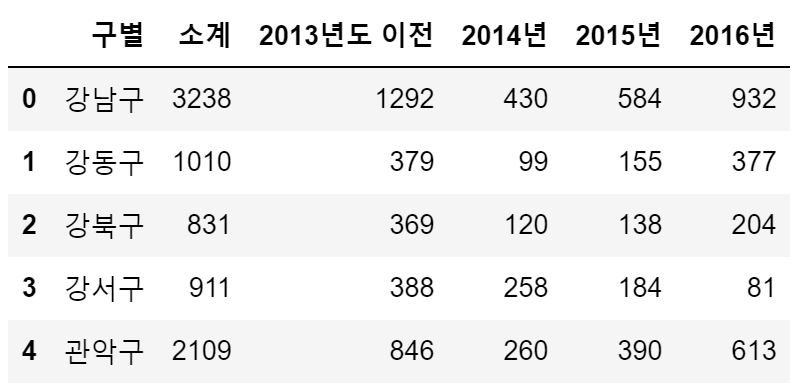
- pop_Seoul
pop_Seoul.rename(
columns={
pop_Seoul.columns[0]: "구별",
pop_Seoul.columns[1]: "인구수",
pop_Seoul.columns[2]: "한국인",
pop_Seoul.columns[3]: "외국인",
pop_Seoul.columns[4]: "고령자",
},
inplace=True
)
pop_Seoul.head()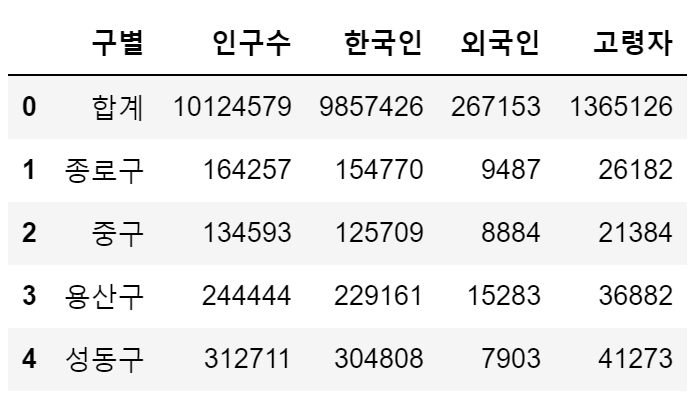
"이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다."
