✔️ 서울시 CCTV 현황분석 3~5
2. CCTV 데이터 훑어보기
CCTV_Seoul.head()
CCTV_Seoul.tail()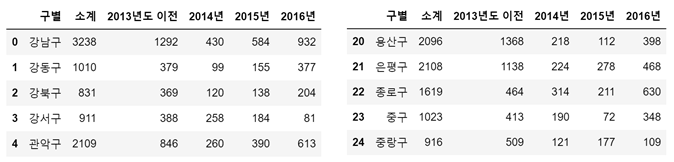
sort_values()
- 정렬 컬럼 설정 두가지 방법
1) by="컬럼명"
2) ["컬럼명"]
# 기존 컬럼이 없으면 추가, 있으면 수정
CCTV_Seoul["최근증가율"] = (
((CCTV_Seoul["2016년"]) + (CCTV_Seoul["2015년"]) + (CCTV_Seoul["2014년"])) / CCTV_Seoul["2013년도 이전"] * 100
)
CCTV_Seoul.sort_values(by="최근증가율", ascending=False).head()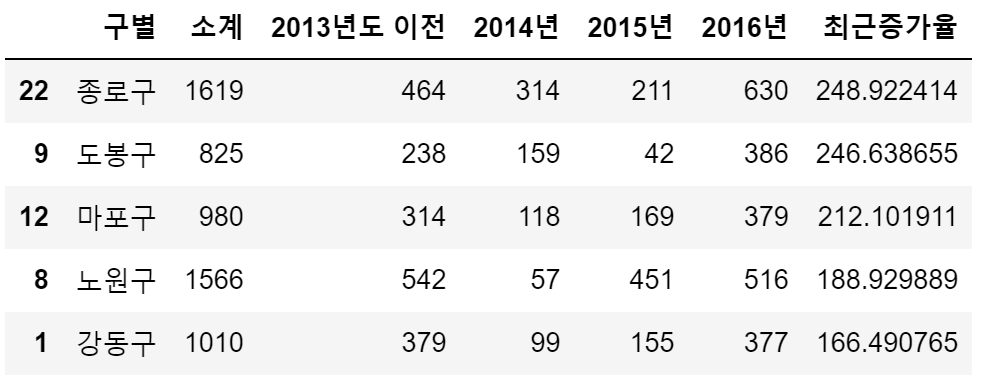
3. 인구현황 데이터 훑어보기
pop_Seoul.head()
pop_Seoul.head()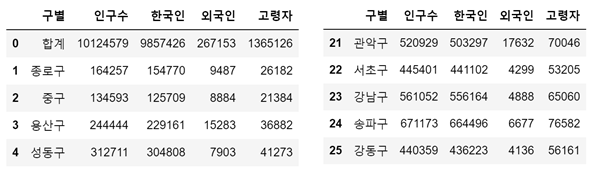
- 불필요한 합계 행(pop_Seoul[0]) 삭제
pop_Seoul.drop([0], axis=0, inplace=True)
#asix : 0은 행(가로) , 1은 열(세로)
pop_Seoul.head()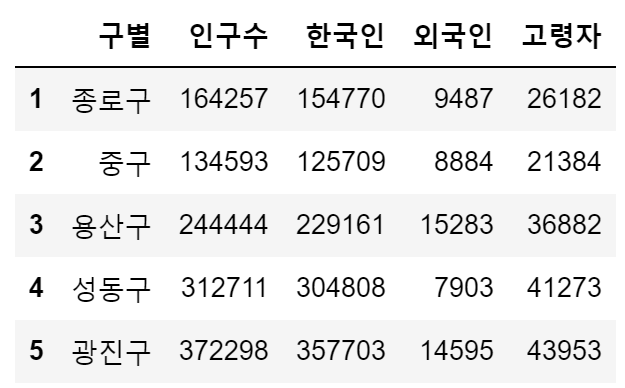
unique()
- 고유한 '구별' 데이터 확인
pop_Seoul['구별'].unique() # array(['종로구', '중구', '용산구', '성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구', '도봉구', '노원구', '은평구', '서대문구', '마포구', '양천구', '강서구', '구로구', '금천구', '영등포구', '동작구', '관악구', '서초구', '강남구', '송파구', '강동구'], dtype=object)
len(pop_Seoul['구별'].unique()) # 25- 외국인 비율, 고령자 비율 계산하고 컬럼 생성
pop_Seoul['외국인비율'] = pop_Seoul['외국인']/pop_Seoul['인구수']
pop_Seoul['고령자비율'] = pop_Seoul['고령자']/pop_Seoul['인구수']pop_Seoul.sort_values(["외국인비율"], ascending=False).head()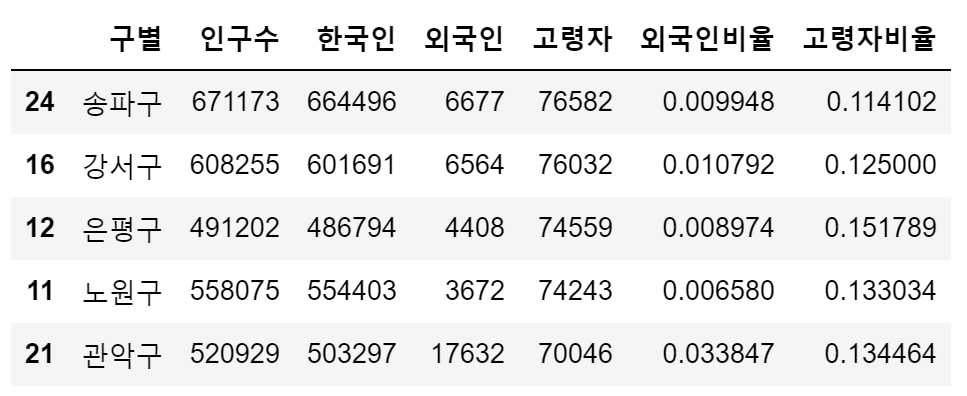
pop_Seoul.sort_values(by="고령자비율", ascending=False).head()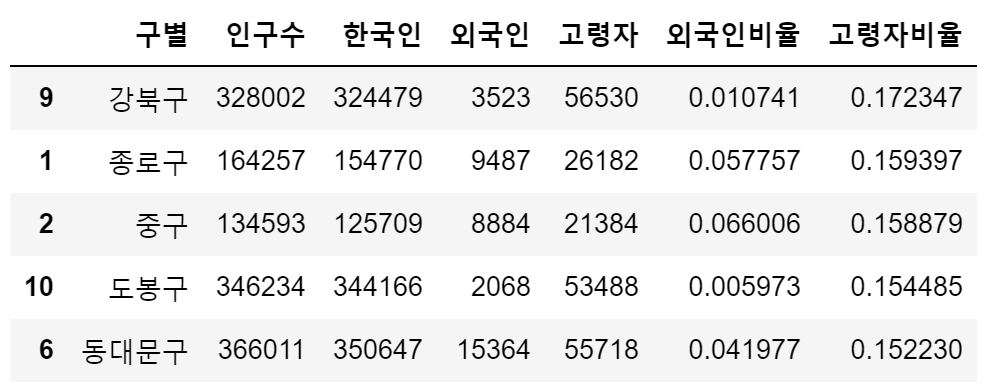
4. 두 데이터 합치기
- Pandas에서 데이터 프레임을 병합하는 방법
1. pod.concat()
2. pd.merge()
3. pd.join()
pd.merge()
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라고 함
- 기준이 되는 키값은 두 데이터 프레임에 모두 포함되어 있어야 함
예제
# 딕셔너리 안의 리스트 형태 (열값 기준으로 데이터 입력) left = pd.DataFrame({ 'Key': ['K0' ,'K4', 'K2', 'K3'], 'A' : ['A0', 'A1', 'A2', 'A3'], 'B' : ['B0', 'B1', 'B2', 'B3'] }) left# 리스트 안의 딕셔너리 형태 (행값 기준으로 데이터 입력) right = pd.DataFrame([ {'Key':'K0', 'C':'C0', 'D':'D0'}, {'Key':'K1', 'C':'C1', 'D':'D1'}, {'Key':'K2', 'C':'C2', 'D':'D2'}, {'Key':'K3', 'C':'C3', 'D':'D3'}, ]) right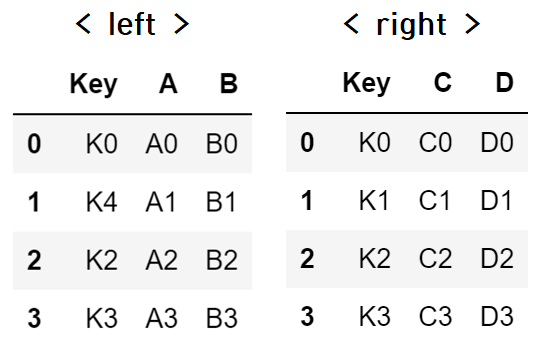
- pd.merge(left, right, how=" ", on=" ")
# how="inner" (default 값) -> 공통된 키값만 확인 pd.merge(left, right, on='Key')# how="left" -> 'left'의 모든 키값을 기준으로 확인 pd.merge(left, right, how="left", on='Key')# how="right" -> 'right'의 모든 키값을 기준으로 확인 pd.merge(left, right, how="right", on='Key')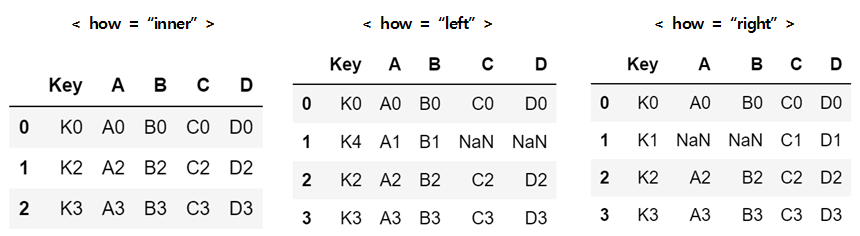
- CCTV_Seoul 데이터와 pop_Seoul 데이터 합친 후 'data_result' 데이터프레임 저장
data_result = pd.merge(CCTV_Seoul, pop_Seoul, on='구별')
data_result.head()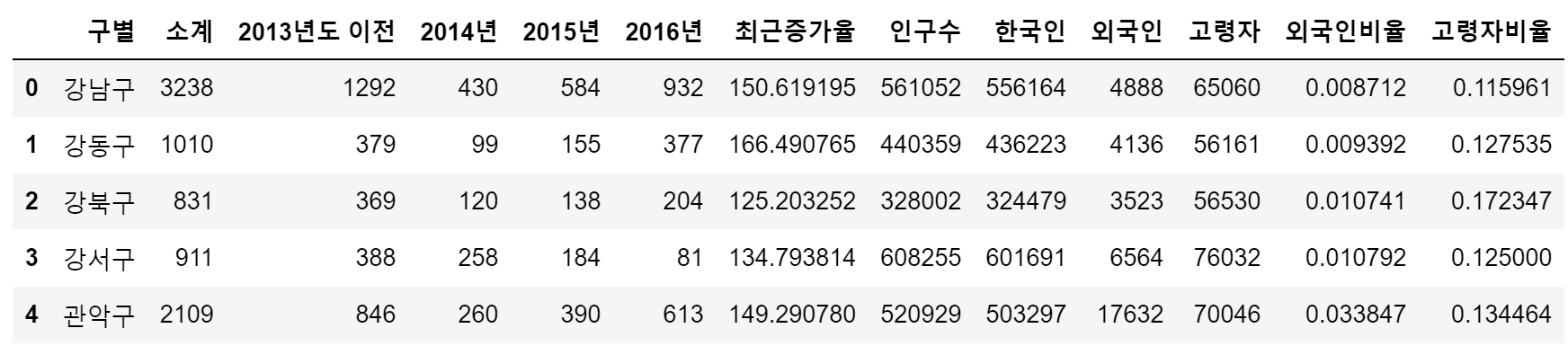
- 년도 별 컬럼('2013년도 이전', '2014년', '2015년', '2016년') 삭제
* 컬럼 삭제 방법- del
- drop()
del data_result['2013년도 이전']
data_result.drop(['2014년', '2015년', '2016년'], axis=1, inplace=True)
data_result.head()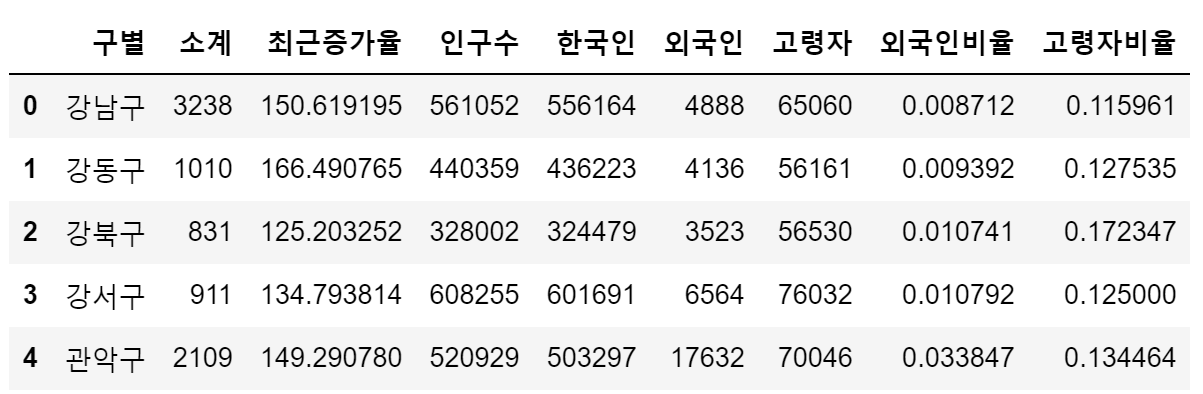
set_index()
- 인덱스 변경 및 설정
- 선택한 컬럼을 데이터 프레임의 인덱스로 지정
data_result.set_index("구별", inplace=True)
data_result.head()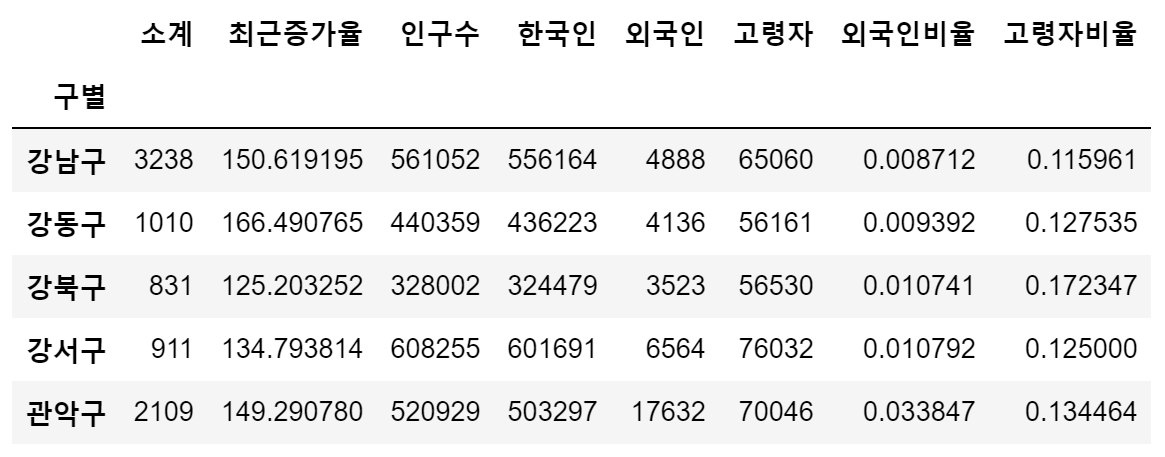
corr()
- 상관계수 / correlation의 약자
- 0 ~ 1(절댓값) 사이값 나타나고, 1에 가까울수록 높은 상관성
- -1~0 : 음의 상관관계 / 1~0 : 양의 상관관계
- 연산이 가능한 타입만 연산수행(int / float O, object 타입은 X)
- 예제 목표 : 상관계수가 0.2 이상인 데이터를 비교
# 컬럼을 기준으로 각 값 비교
data_result.corr()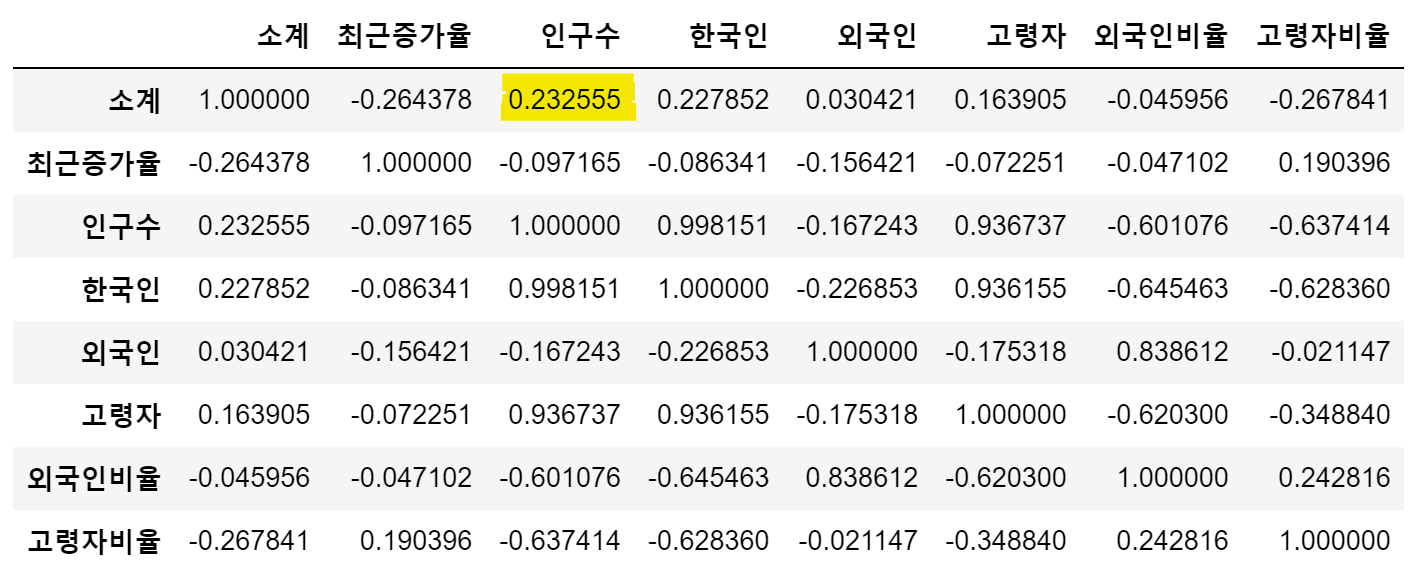 → CCTV수(소계)와 인구수의 상관관계는 0.232555로 낮은 양의 상관관계를 보임
→ CCTV수(소계)와 인구수의 상관관계는 0.232555로 낮은 양의 상관관계를 보임
- 인구수 별 CCTV 설치 비율 구하기
data_result['CCTV비율'] = data_result['소계']/data_result['인구수'] * 100
data_result.sort_values(['CCTV비율'], ascending=False).head()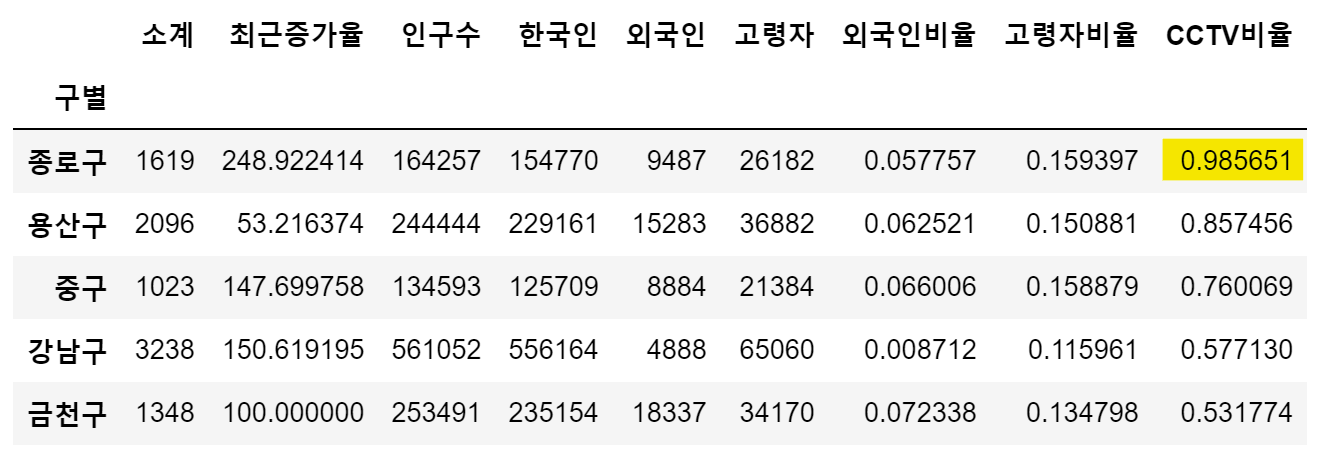 → 종로구가 제일 높은 인구수별 cctv 설치 비율을 보임
→ 종로구가 제일 높은 인구수별 cctv 설치 비율을 보임
5. 데이터 시각화
⭐ matplotlib 기초
- 그래프 기본 작성 형태
import matplotlib.pyplot as plt from matplotlib import rc rc('font', family='Malgun Gothic') # plt.rcParams['axes.unicode_minus'] = False get_ipython().run_line_magic('matplotlib', 'inline') # %matplotlib inline -> notebook을 실행한 브라우저에서 바로 그림을 볼 수 있게 해주는 것 plt.figure(figsize=(10, 6)) plt.plot(x, y) plt.show()
예제 1
- np.arange(a, b, s): a 부터 b 까지 s의 간격
- np.sin(value)
import numpy as np t = np.arange(0, 12, 0.01) y = np.sin(t) plt.figure(figsize=(10, 6)) plt.plot(t, np.sin(t)) plt.plot(t, np.cos(t))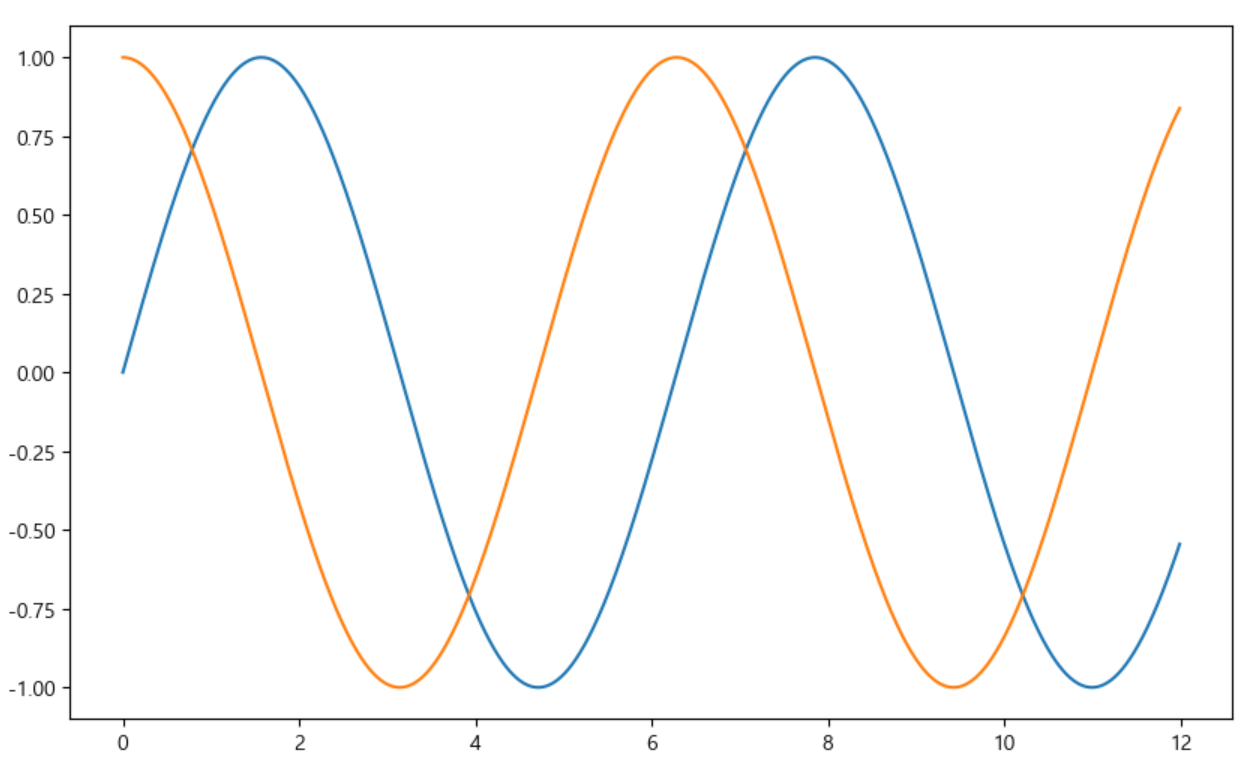
- 위 그래프에 옵션 추가
1) plt.grid() : 격자 무늬 추가
2) plt.title() : 그래프 제목 추가
3) plt.xlabel(), ylabel() : x축, y축 제목 추가
4) plt.legend() : 주황색 , 파란색 선 데이터 의미 구분
- legend() 범례 설정 2가지
- plt.plot(t, np.sin(t))
plt.plot(t, np.cos(t))
plt.legend(labels=['sin', 'cos'])- plt.plot(t, np.sin(t), lable='sin')
plt.plot(t, np.cos(t), lable='cos')
plot.legend()
def drawGraph(): plt.figure(figsize=(10, 6)) plt.plot(t, np.sin(t)) plt.plot(t, np.cos(t)) plt.grid(True) # 격자무늬 설정 plt.legend(labels=['sin', 'cos'], loc=2) # loc : 범례 위치 설정(2:'upper left') plt.title("Example of sinewave") # 그래프 제목 설정 plt.xlabel('time') # x축 제목 설정 plt.ylabel('Amplitude(진폭)') # y축 제목 설정 plt.show() drawGraph()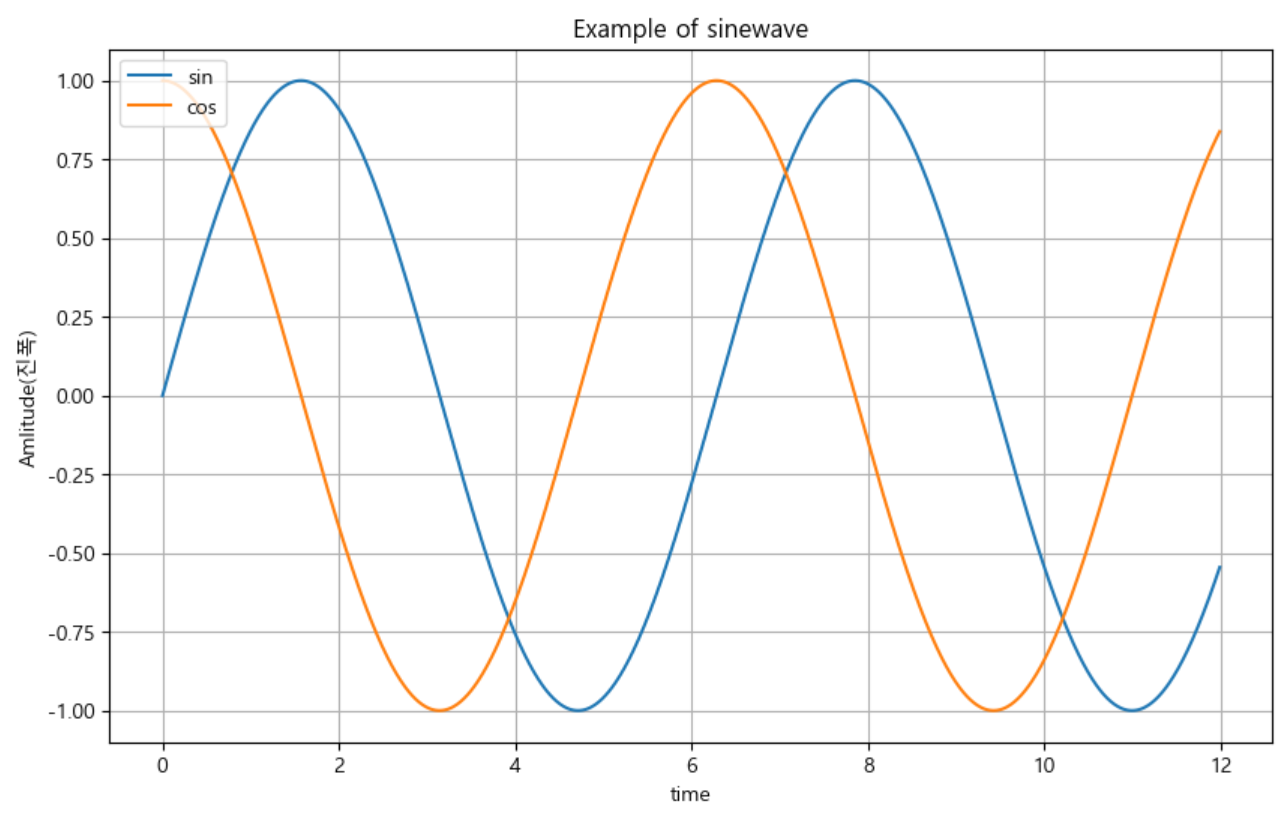
예제2 : 그래프 커스텀
t = np.arange(0, 5, 0.5) # array([0. , 0.5, 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5]) plt.figure(figsize=(10, 6)) plt.plot(t, t, 'r--') # 그래프 선 모양이 빨간색, 점선(red --) plt.plot(t, t**2, 'bs') # 그래프 점 모양이 파란색, 사각형(blue square) plt.plot(t, t**3, 'g>') # 그래프 점 모양이 초록색, 오른쪽 삼각형(green ▶) plt.show()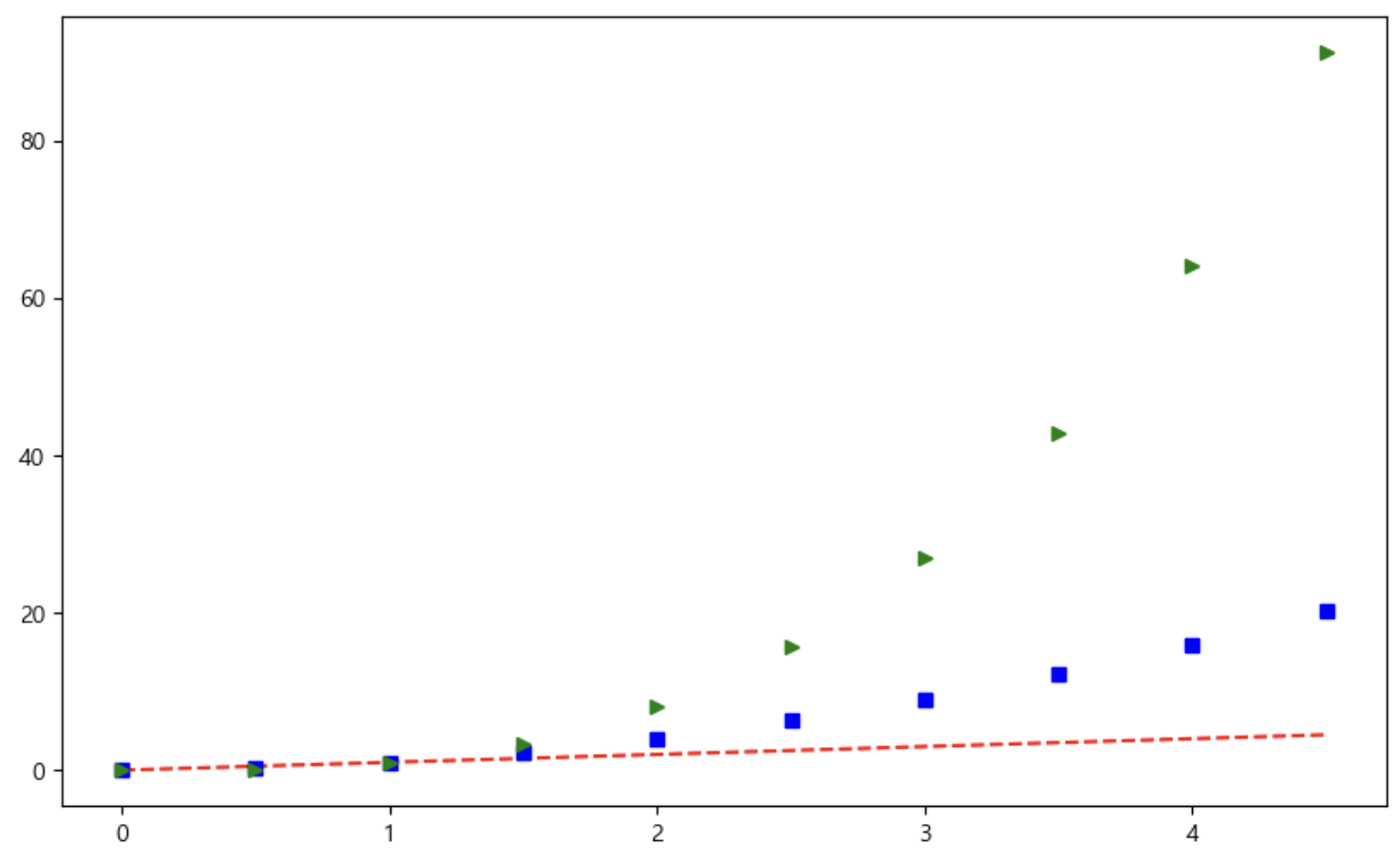
# t = [0, 1, 2, 3, 4, 5, 6] t = list(range(0, 7)) y = [1, 4, 5, 8, 9, 5, 3] def drawGraph(): plt.figure(figsize=(10, 6)) plt.plot( t, y, color="red", # plot은 선 그래프, 그래프 색상은 빨간색 linestyle='dashed', # 점선(dashed) : '--', 실선 : '-' marker='o', # marker 모양은 원(점) markerfacecolor='yellow', # 노란색으로 marker 채우기 markersize=15 ) plt.xlim([-0.5, 6.5]) # x축 범위 설정 plt.ylim([0.5, 9.5]) # y축 범위 설정 plt.show() drawGraph()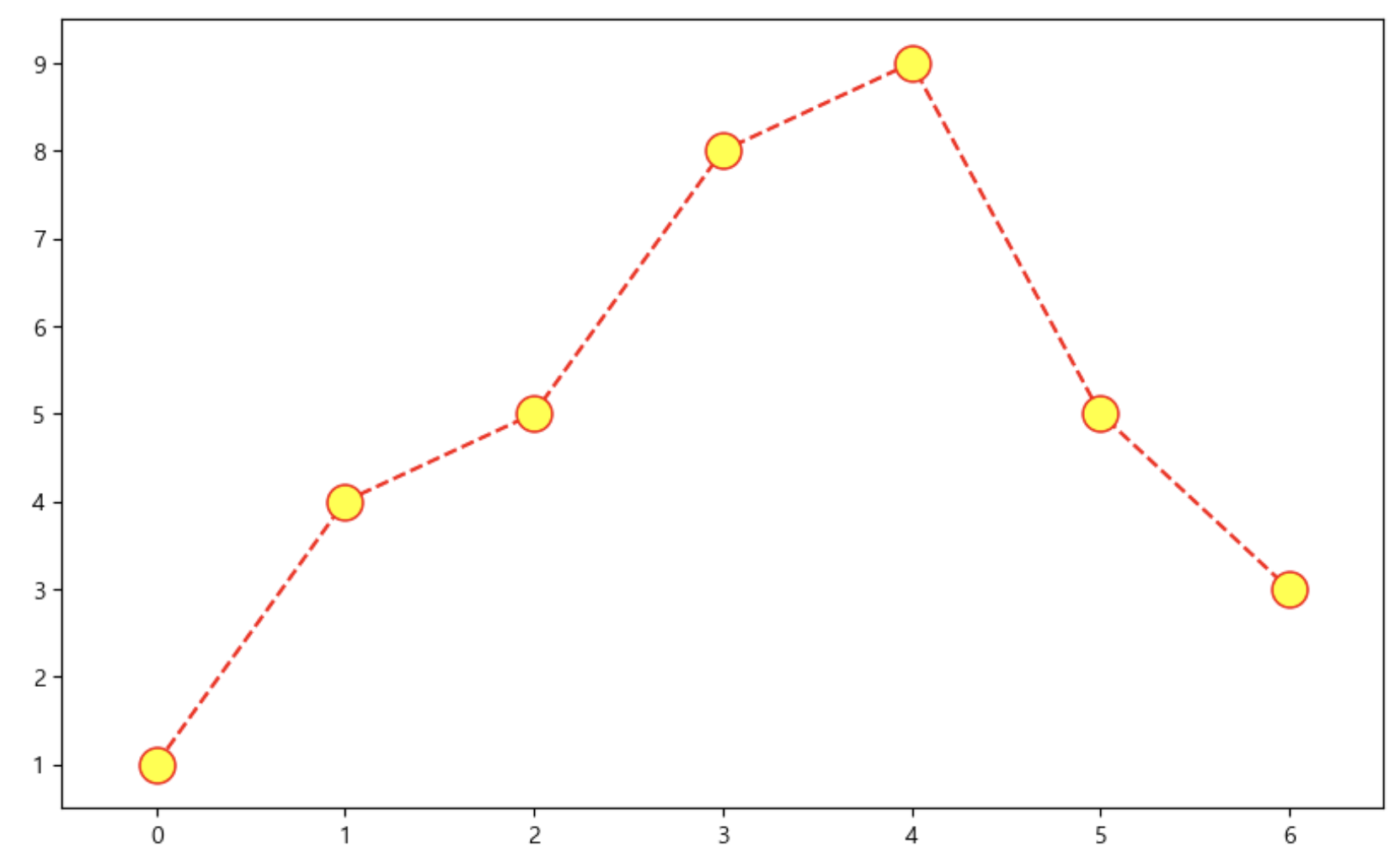
예제3 : scatter plot
t = np.array(range(0, 10)) y = np.array([9, 8, 7, 9, 8, 3, 2, 4, 3, 4]) def drawGraph(): plt.figure(figsize=(10, 6)) plt.scatter(t, y) plt.show() drawGraph()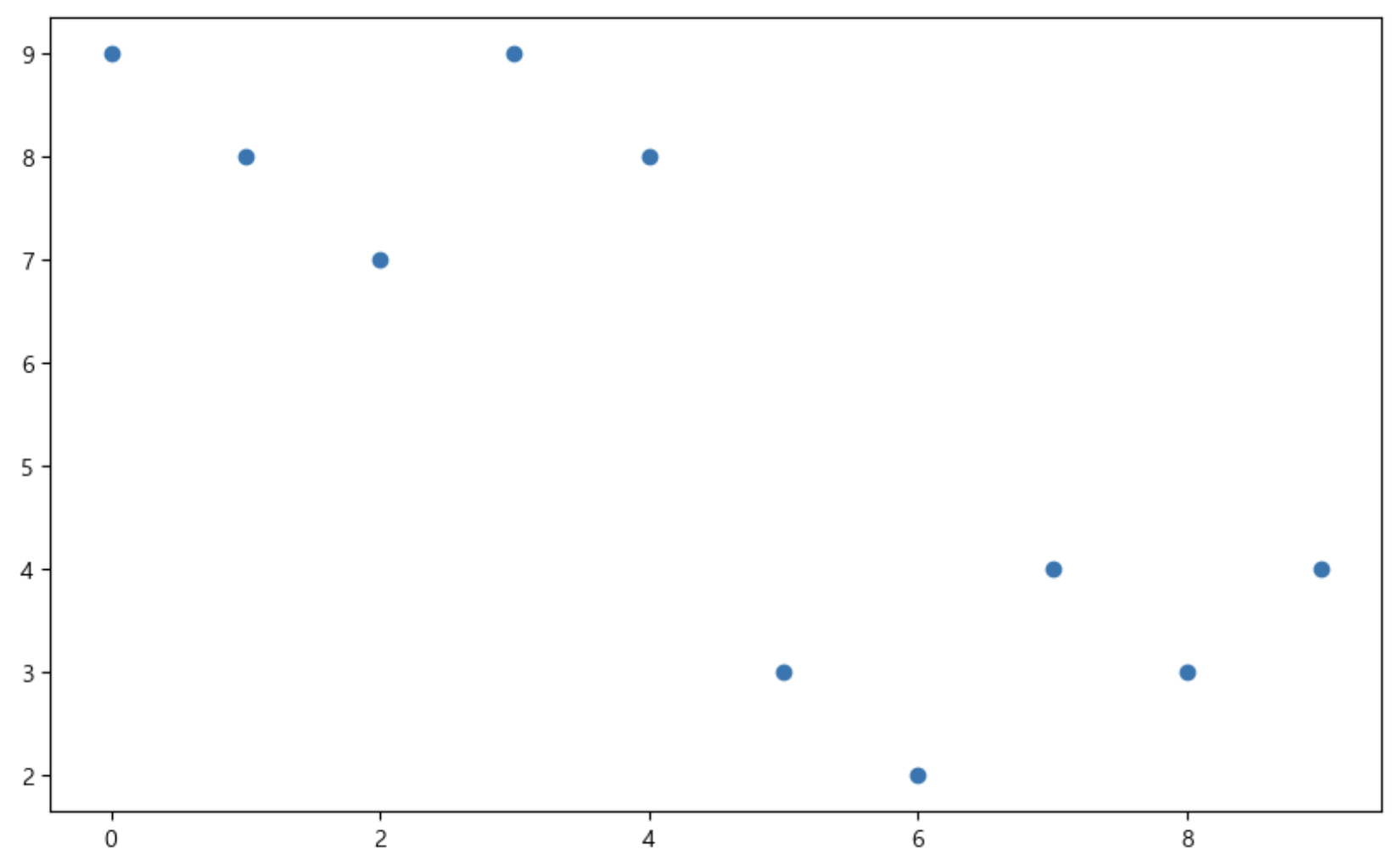
t = np.array(range(0, 10)) colormap = t def drawGraph(): plt.figure(figsize=(20, 6)) plt.scatter(t, y, s=50, c=colormap, marker='>') plt.colorbar() plt.show() drawGraph()
예제4 : pandas에서 plot 그리기
- matplotlib을 가져와서 사용
공식문서 참조(matplotlib-example-gallery에서 참고자료 확인하여 다양하게 적용)
링크 : https://matplotlib.org/stable/gallery/index.htmldata_result.head()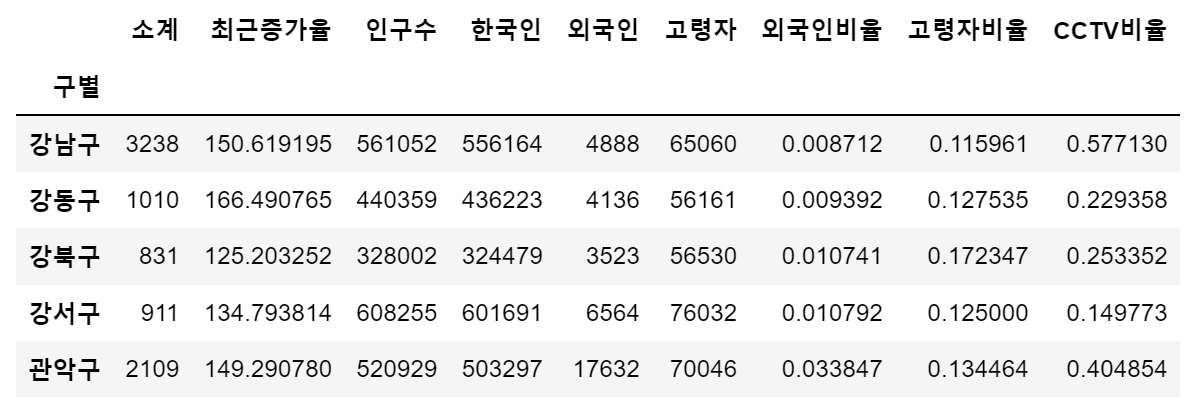
# 그래프 구현 마지막 쿼리에 ' ; ' 작성하면 <Axes: xlabel='구별'> 이런 문구 출력을 막을 수 있음 data_result['인구수'].plot(kind='bar', figsize=(10, 5)); # bar : 막대그래프(세로 기본)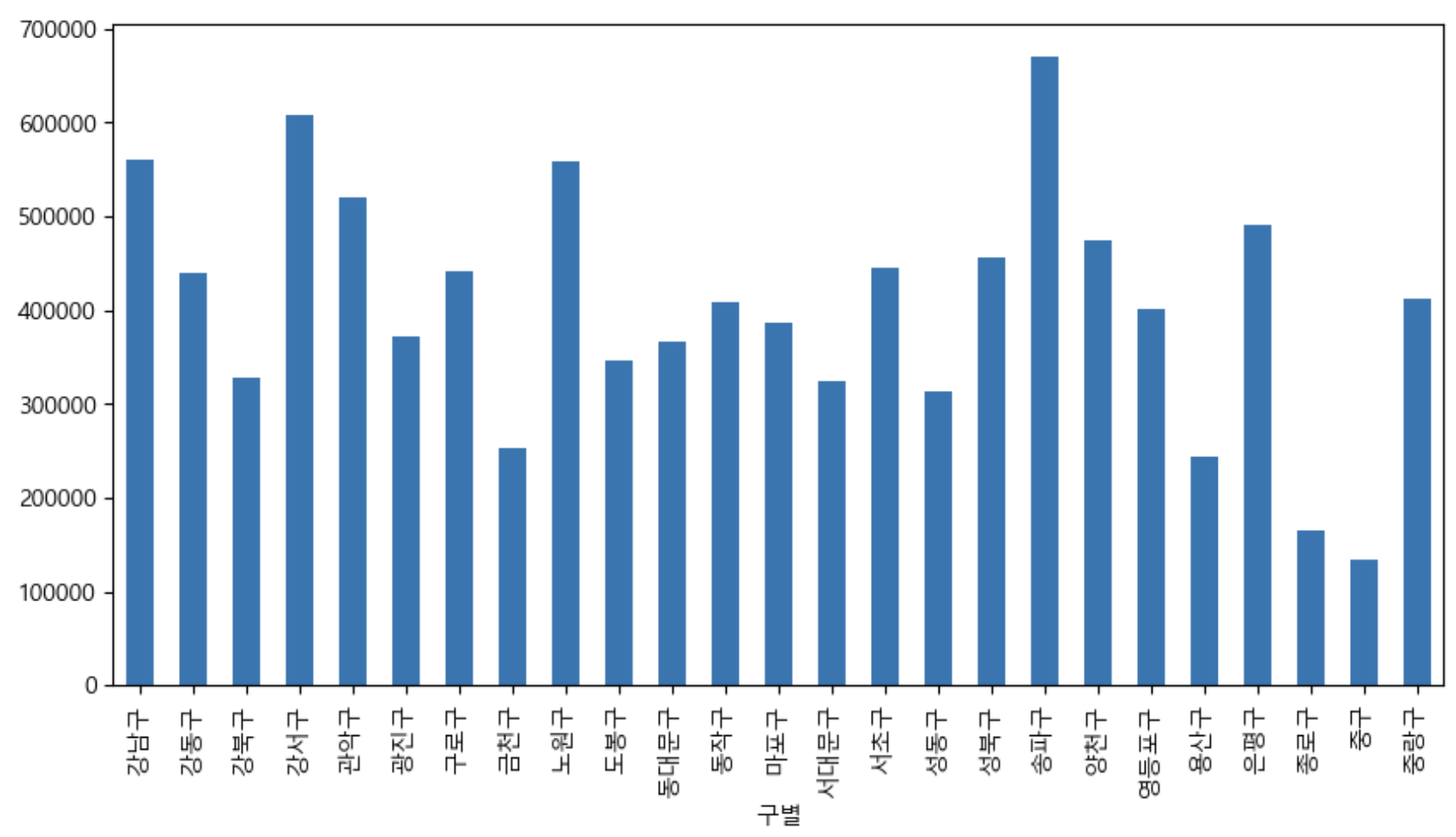
data_result['인구수'].plot(kind='barh', figsize=(10, 5)) # barh : 가로 막대그래프(horizontal)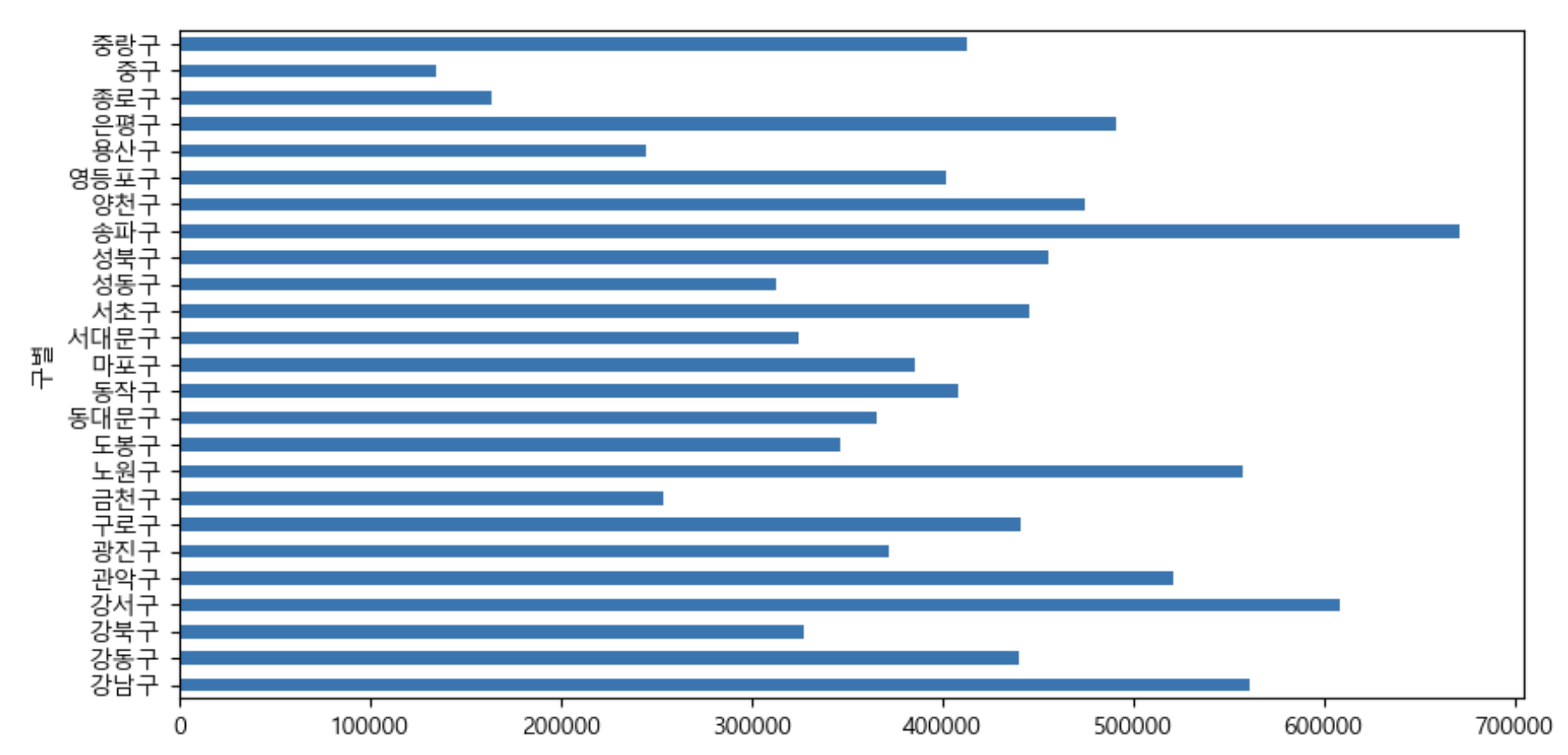
- CCTV 데이터와 인구별 데이터 시각화
- pandas.DataFrame.plot 공식문서 (옵션설정 시 참조하여 설정)
링크 : https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.plot.html
import matplotlib.pyplot as plt
# import matplotlib as mpl
from matplotlib import rc
plt.rcParams['axes.unicode_minus'] = False # 마이너스 부호로 인해 한글깨짐현상 방지
rc("font", family='Malgun Gothic')
%matplotlib inline
# 동일 : get_ipython().run_inline_magic("matplotlib", 'inline')
data_result.head()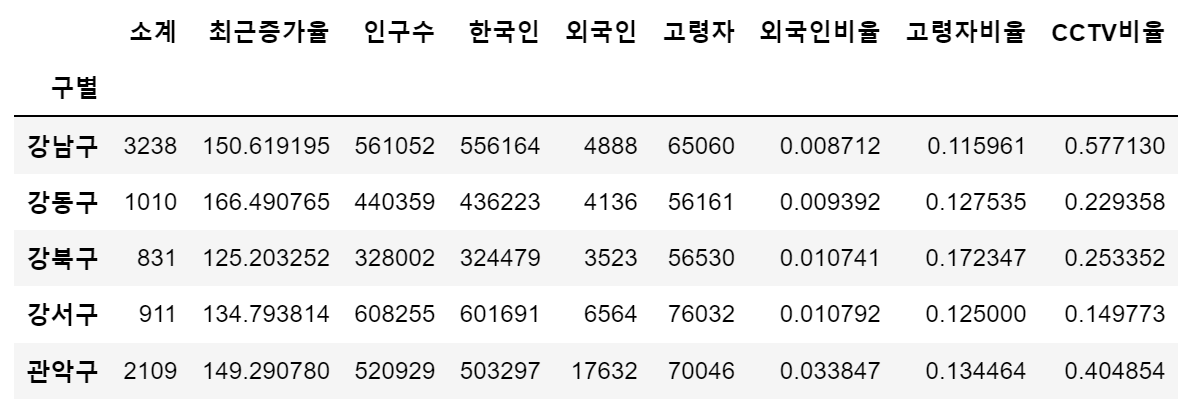
- 소계(CCTV) 컬럼 시각화
def drawGraph():
data_result['소계'].sort_values().plot(
kind='barh', grid=True, title='가장 CCTV가 많은 구(CCTV 개수)', figsize=(6, 6), );
drawGraph()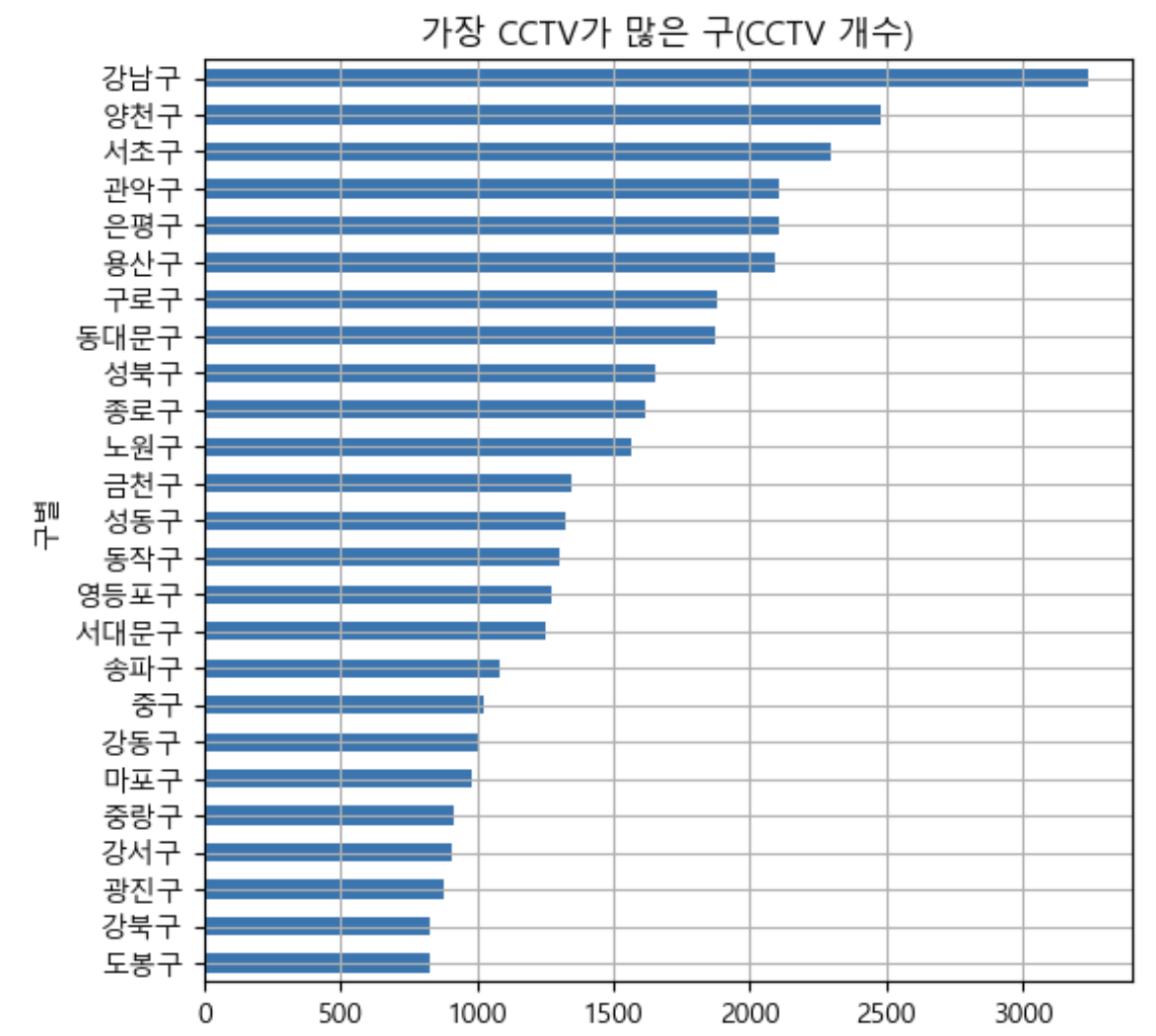
- CCTV 비율 시각화
def drawGraph():
data_result['CCTV비율'].sort_values().plot(
kind='barh', grid=True, title='가장 CCTV가 많은 구(CCTV비율)', figsize=(6, 6), );
drawGraph()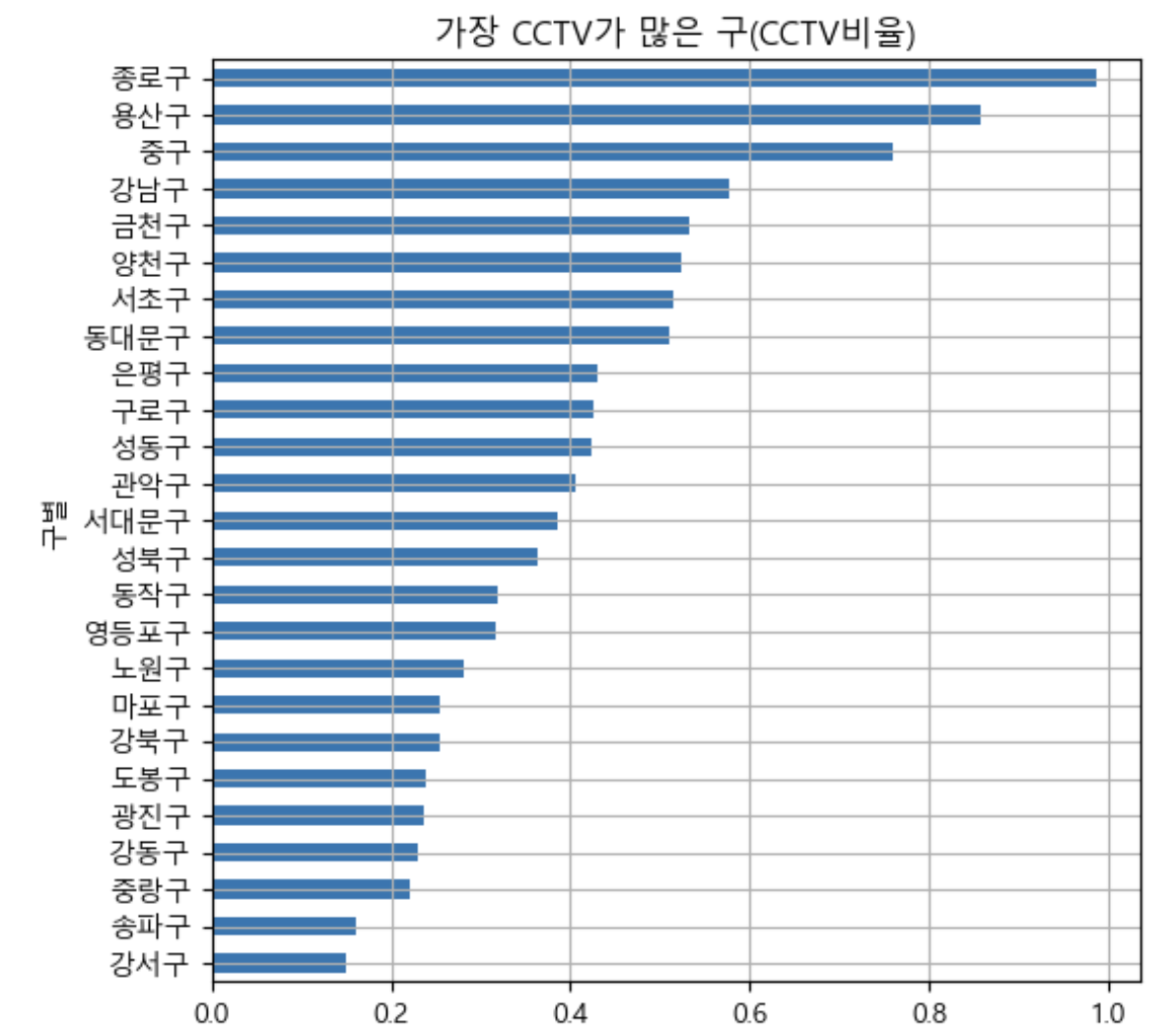
6. 데이터 경향 표시
- 인구수와 소계(CCTV) 컬럼으로 scatter plot 그리기
def drawGraph():
plt.figure(figsize=(10, 6))
plt.scatter(data_result['인구수'], data_result['소계'], s=30)
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.grid()
plt.show()
drawGraph()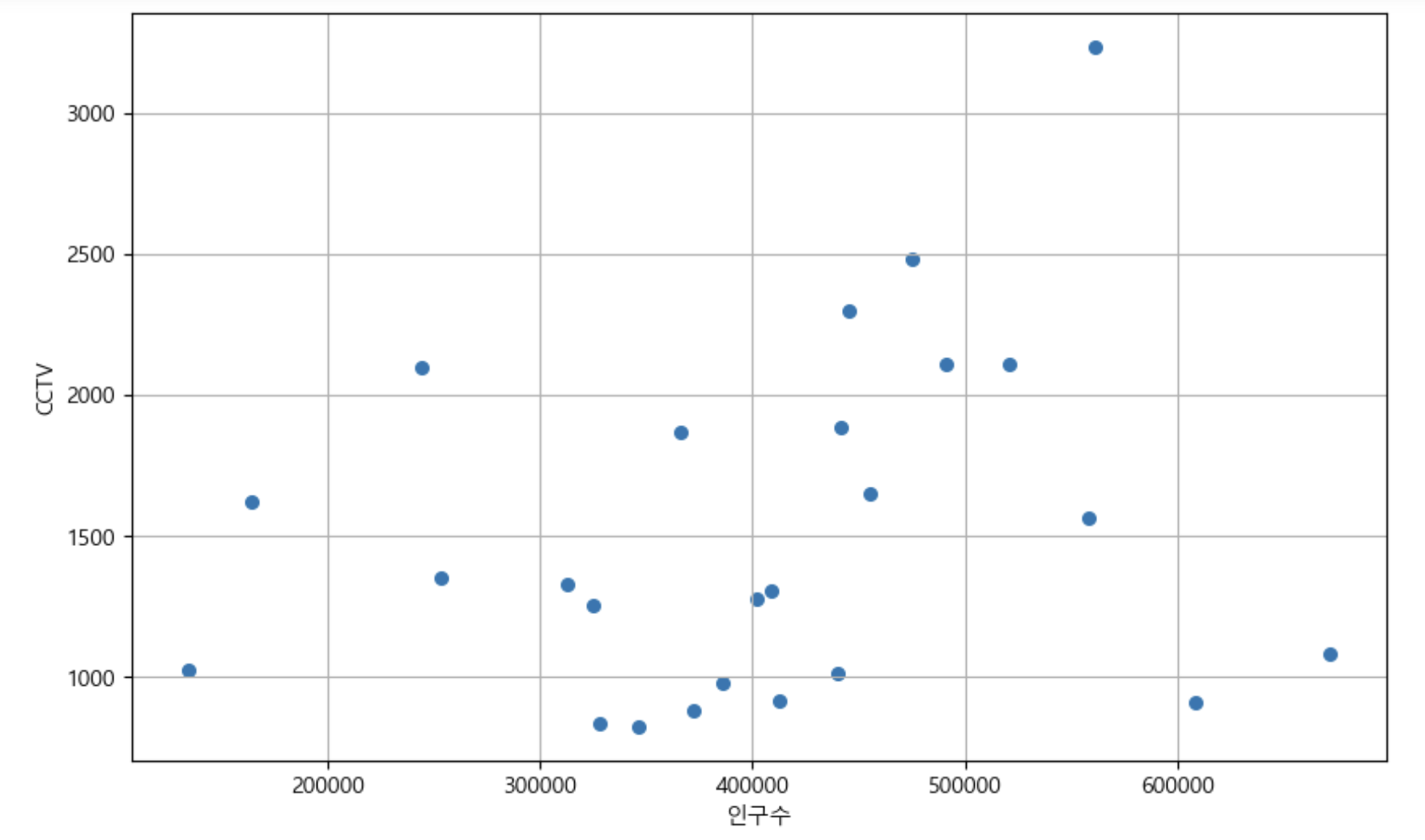
Numpy를 이용한 1차 직선 만들기 ⭐
- np.polyfit() : 직선을 구성하기 위한 계수를 계산
- np.poly1d() : polifit으로 찾은 계수로 파이썬에서 사용할 수 있는 함수를 만들어주는 기능
import numpy as np
# 계수 계산
fp1 = np.polyfit(data_result['인구수'], data_result['소계'], 1)
fp1 # array([1.11155868e-03, 1.06515745e+03])
# 함수 생성
f1 = np.poly1d(fp1)
f1 # poly1d([1.11155868e-03, 1.06515745e+03])
# 생성된 함수에 특정 값 입력하면 나오는 결과 확인
f1(400000) # 1509.7809252413338- 인구가 40만인 구에서 서울시의 전체 경향에 맞는 적당한 CCTV 수는? ⭐
- 경향선을 그리기 위한 x 데이터 생성
- np.linspace(a, b, n) : a부터 b까지 n개의 등간격 데이터 생성
fx = np.linspace(100000, 700000, 100) # 10만~70만 사이의 100개 데이터 생성
def drawGraph():
plt.figure(figsize=(10, 6))
plt.scatter(data_result['인구수'], data_result['소계'], s=30)
plt.plot(fx, f1(fx), ls='dashed', lw=3, color='g') # (ls:line style), (lw:line width)
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.grid()
plt.show()
drawGraph()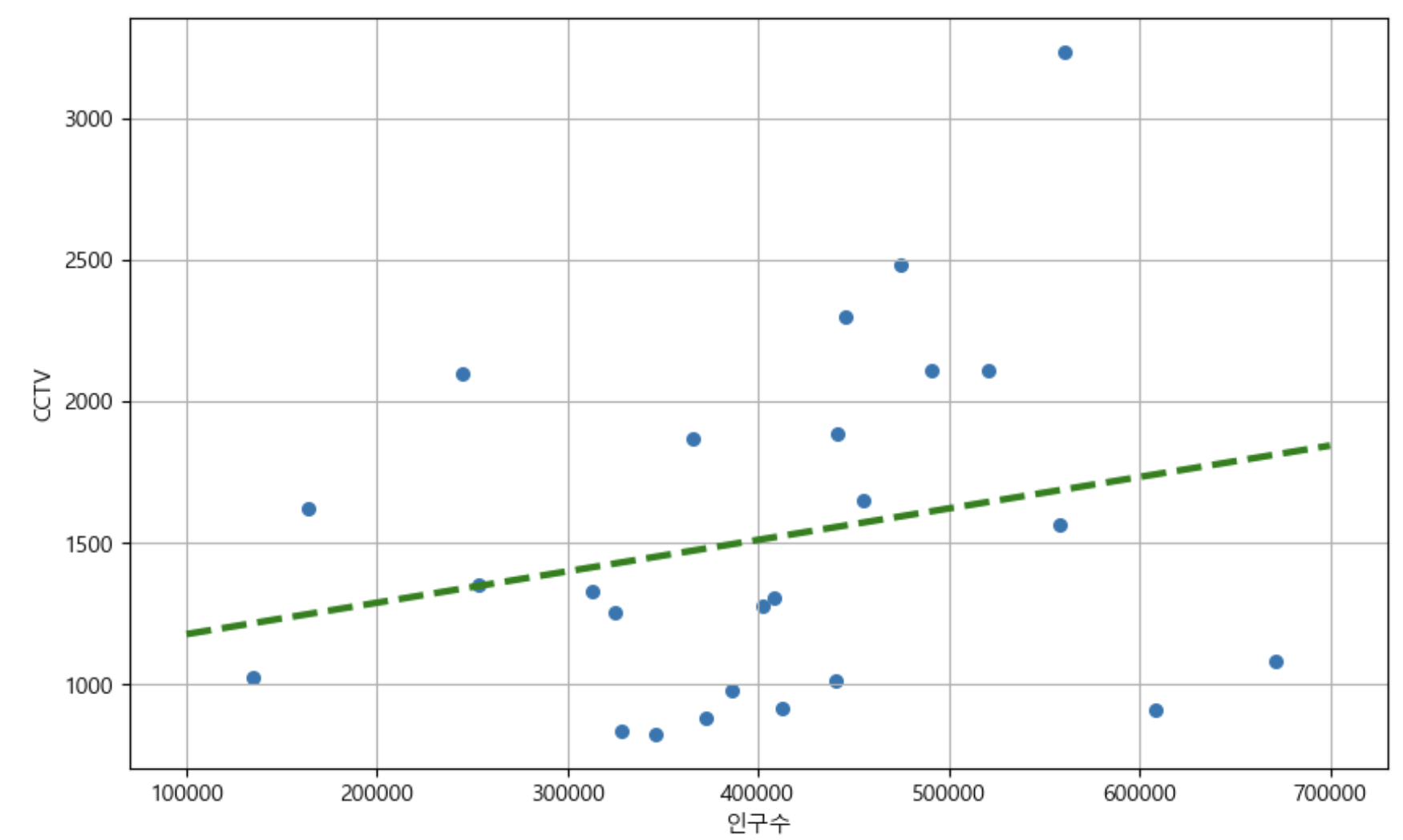
7. 강조하고 싶은 데이터 시각화 해보기
그래프 다듬기
- 경향과 오차 만들기
- 경향(trend)과의 오차 만들자
- 경향은 f1함수에 해당 인구를 입력
- f1(data_result['인구수'])
fp1 = np.polyfit(data_result['인구수'], data_result['소계'], 1)
f1 = np.poly1d(fp1)
# fx = np.linspace(10000, 70000, 100) → 오타 발견!!
fx = np.linspace(100000, 700000, 100)
data_result['오차'] = data_result['소계'] - f1(data_result['인구수'])
data_result.head(1)
- 경향과 비교해서 데이터의 오차가 너무 나는 데이터를 계산
df_sort_f = data_result.sort_values(['오차'], ascending=False) # 오차를 기준으로 전체 데이터 내림차순
df_sort_t = data_result.sort_values(['오차'], ascending=True)- 경향대비 CCTV를 많이 가진 구 비교
df_sort_f.head()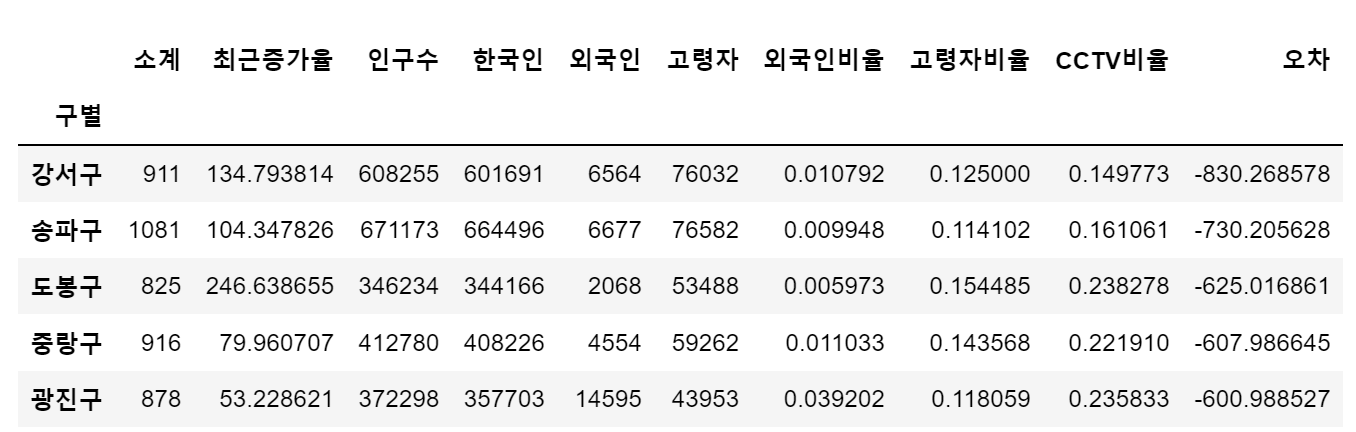
- 경향대비 CCTV를 적게 가진 구
df_sort_t.head()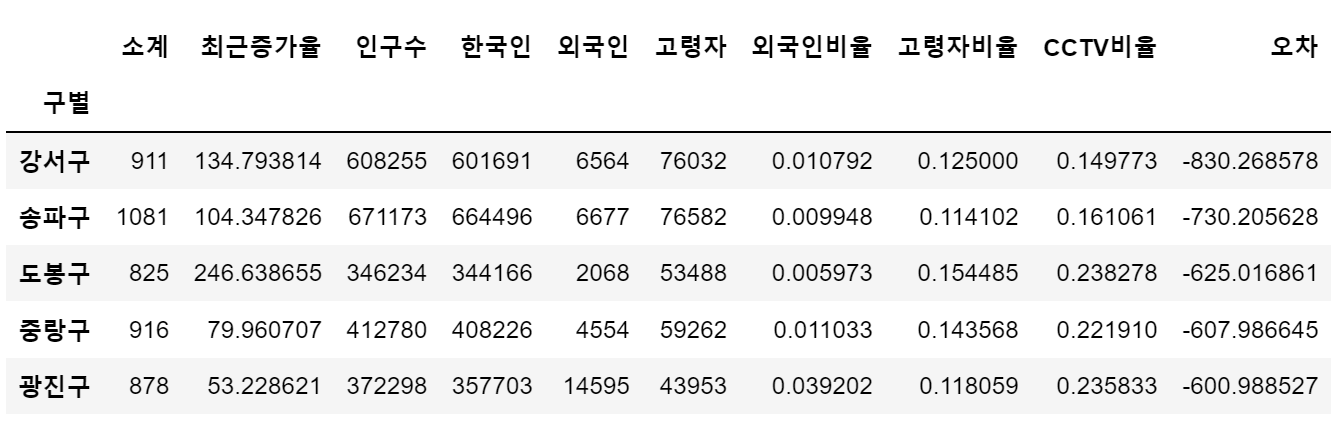
- 특정 x축 값, y축 값, index명 확인해보기
data_result['인구수'][0] # 561052
data_result['소계'][0] # 3238
data_result.index[0] # '강남구'- 최종 그래프 구하기
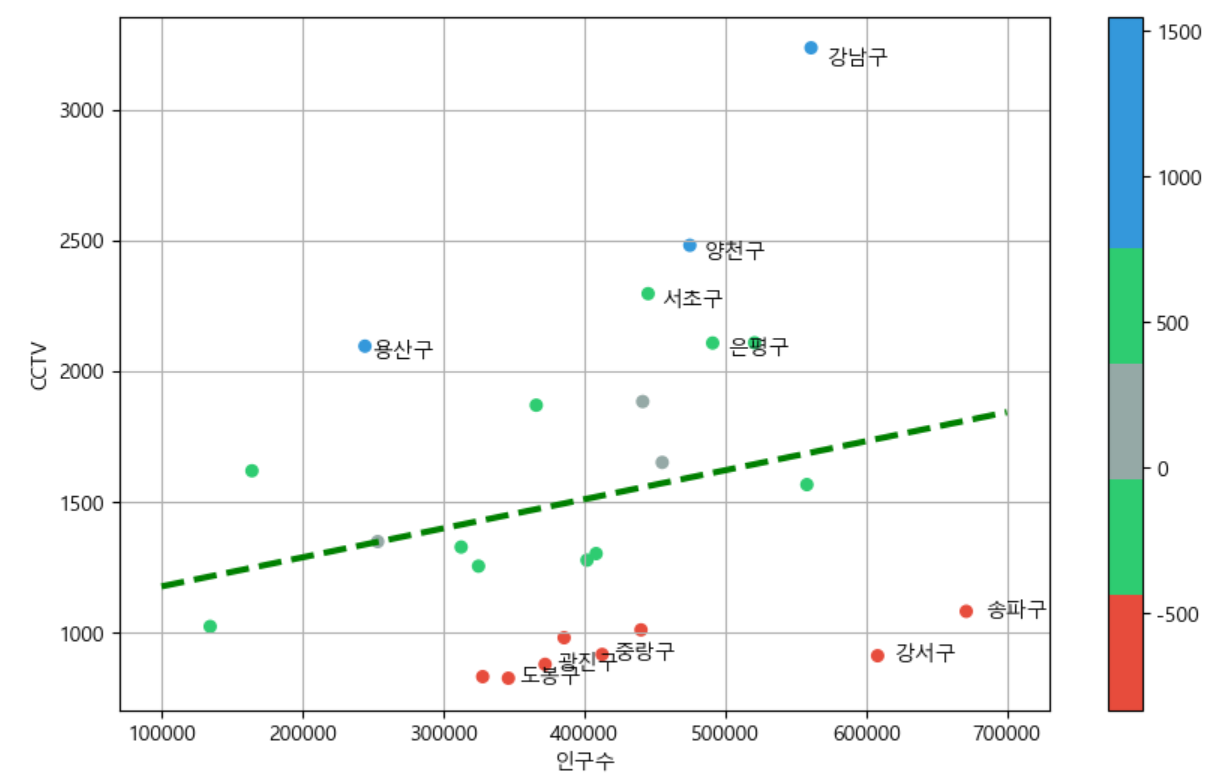
- 목표 : 서울시의 구 마다 인구수 별 CCTV 설치 현황 경향을 파악하고 경향에서 벗어난 구를 비교해하기 위해 시각화해보기
from matplotlib.colors import ListedColormap
# colormap을 사용자 정의( user define )로 셋팅
color_step = ['#e74c3c', '#2ecc71', '#95a9a6', '#2ecc71', '#3498db', '#3498db']
my_cmap = ListedColormap(color_step)def drawGraph():
plt.figure(figsize=(10, 6))
plt.plot(fx, f1(fx), ls='dashed', lw=3, color='g') # (ls:line style), (lw:line width)
# fx = np.linspace(10000, 70000, 100)
plt.scatter(data_result['인구수'], data_result['소계'], s=30, c=data_result['오차'], cmap=my_cmap)
# c: 어떤 기준으로 색깔 지정하는지 설정
# 경향에서 많이 벗어난 10개 구의 이름 출력
for n in range(5):
# 상위 5개
plt.text(
df_sort_f['인구수'][n] * 1.02, # x 좌표(* 1.02 -> 텍스트 위치를 마커에서 떨어뜨려 놓기 위함 )
df_sort_f['소계'][n] * 0.98, # y 좌표
df_sort_f.index[n], # title
fontsize=10,
)
# 하위 5개
plt.text(
df_sort_t['인구수'][n] * 1.02,
df_sort_t['소계'][n]*0.98,
df_sort_t.index[n],
fontsize=10,
)
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.colorbar()
plt.grid()
plt.show()
drawGraph()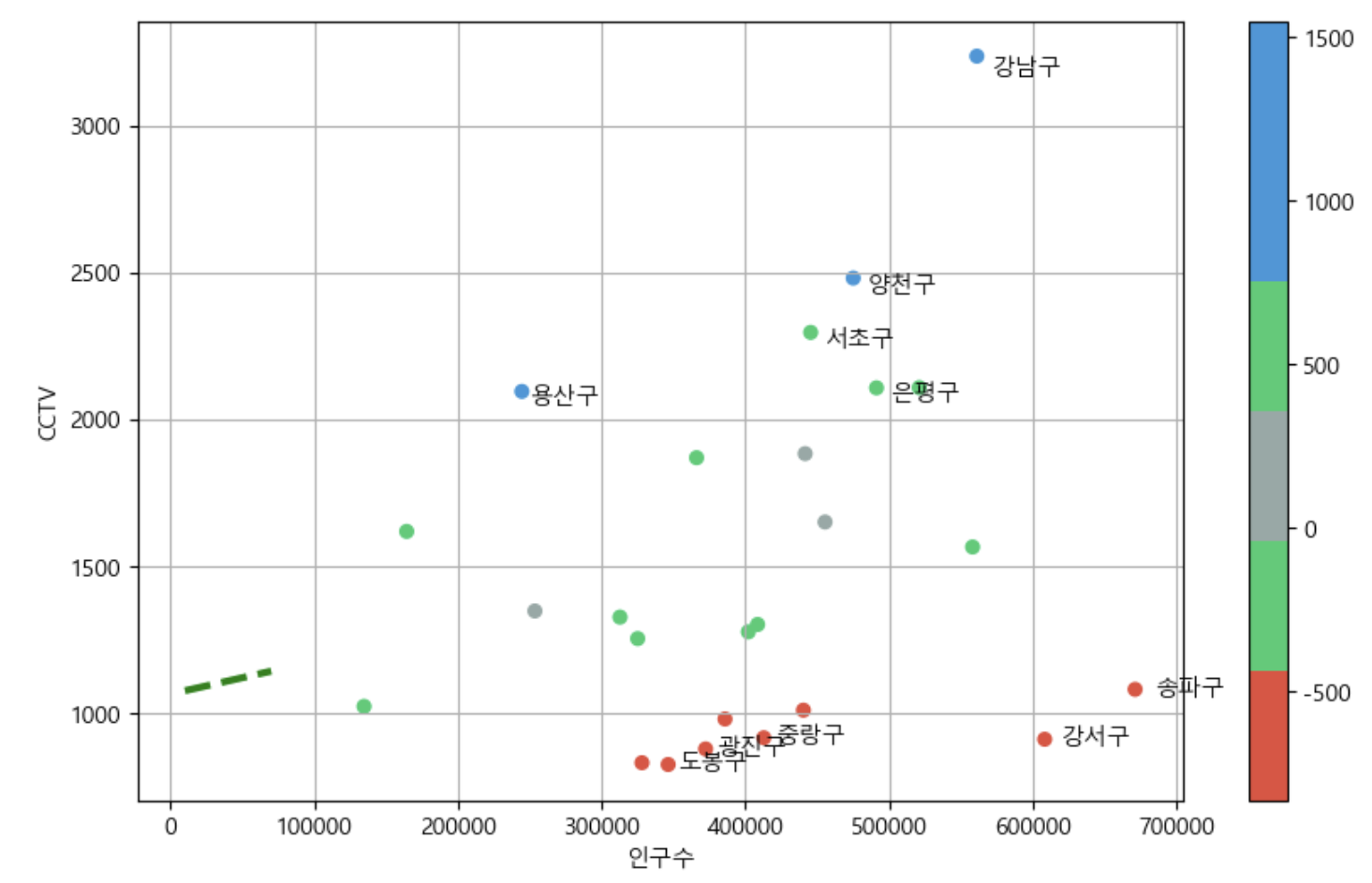
→ 서울시의 각 구 별 인구수 대비 CCTV 설치 현황보다 더 많이 설치된 구 : 강남구 ~ 은평구
→ 서울시의 각 구 별 인구수 대비 CCTV 설치 현황보다 더 적게 설치된 구 : 도봉구 ~ 송파구
❓ 경향선이 각 설치 현황 그래프와 동시에 출력되지 않는 현상이 나타났다. 어디서 잘못된 것인지 확인해 볼 필요가 있겠다.
+ 추가) ❗앞전에 경향선을 구하기 위한 fx 설정값에 100000부터 700000이 아닌 10000부터 70000으로 설정되어있어 그래프에 구하고자 하는 범위까지 나타나지 않았던 것이었다. 굉장히 간단한 문제였고 실제로 그래프에서도 잘 나타나는것을 볼 수 있다. 앞으로 문제가 생기면 초기화 값이 잘 적용되었는지부터 확인해 보자.
- 오차까지 구해진 데이터 프레임을 CCTV_result.csv 파일로 저장
data_result.to_csv('../data/01. CCTV_result.csv', sep=',', encoding='utf-8-sig')"이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다."
