Unified Detection
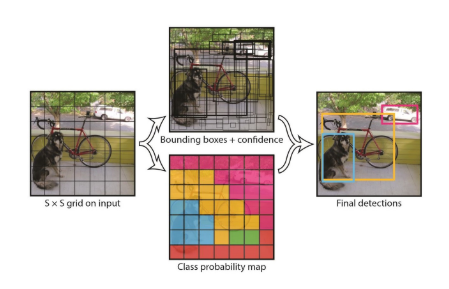
1. 이미지를 SXS Grid로 나눔.
2. 각 Grid cell은 B개의 Bounding Box와 각 Bounding Box에 대한 Confidence score를 가짐.
(만약 cell에 object가 존재하지 않으면 신뢰도 점수는 0)
3. 각 Grid cell은 C개의 conditional class probability를 갖음.
4. 각각의 Bounding Box는 x,y,w,h,confidence로 구성
(x,y): Bounding box의 중심점을 의미하며, grid cell의 범위에 대한 상대값이 입력.
(w,h): 전체 이미지의 width, height에 대한 상대값이 입력.
예1: 만약 x가 grid cell의 가장 왼쪽에 있다면 x=0, y가 grid cell의 중간에 있다면 y=0.5
예2: bbox의 width가 이미지 width의 절반이라면 w=0.5
Bounding Box - 테두리 상자
Confidence score - 신뢰도 점수
출처 및 참조 : https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088

안녕하세요. 데이터와 동고동락 중인 개발자 입니다.