개발 단계: db생성, db구성, 데이터 이행예전 서버 -> 새로운 서버 예전 버전 -> 새로운 버전
운영 단계: db운영(공간관리, 락관리, 악성 세션의 SQL튜닝, 오라클 문제들 해결), 데이터 이행운영 서버 -> 개발 서버 OTLP 서버 -> DW 서버
✅ data 이행 시 중요하게 다뤄야 할 점 2가지
✔️ data 의 정합성
✔️ data 이행 성능(속도)
✅ data 이행 성능을 높이기 위해서는 어떻게 해야 하는가 ? (중요)
1. table 구조 --> data 입력 --> 인덱스 생성(병렬처리) ⭐ 중요! ⭐
2. buffer 옵션을 사용한다. 데이터 행들을 가져오는데 사용되는 작업단위의 크기를 설정
✅ data 이행에 관련한 개념 및 툴 3가지
✔️ Direct load insert
✔️ SQL * Loader
✔️ export/import
✏️ Direct load insert
💡 Direct load insert 의 특징
1. DATA 를 HWM 위에입력한다.
2. append, parallel 힌트를 사용해서 입력
3. nologging 옵션을 사용할 수 있다. -> redo 가 생성되지 않는다. 속도는 빠르지만 복구가 되지 않는다.
✔️ 장점 : 속도가 빠르다.
✔️ 단점 : 낭비되는 저장공간이 생긴다. (즉, 저장공간이 더 많이 소요된다.) nologging 으로 insert 를 하면 복구가 안된다.
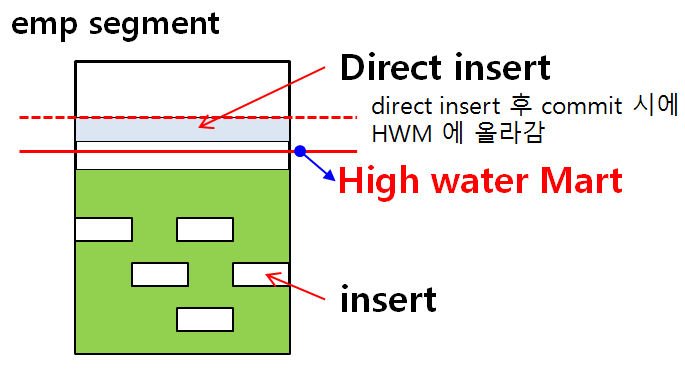
💡 Insert 할 때
insert into new_emp select * from emp@dblink명;✅ 위 경우 데이터가 아래에서 위로 차오른다. 그 때 마크가 하나 생기는데 이것이
High water mark이다. 마치 음료를 먹고 위에 있는 자국같은 것 ! 그래서 데이터를 지워도 하이워터마크는 내려오지 않는다. truncate로 지울 수 있고 delete나 다른것은 지울수가 없다.select ename, sal from emp where job='SLAESMAN';✅ 이 경우 job에 인덱스가 없어서 full table scan이 일어나는데, 이때 HWM까지 읽는다. HWM를 내려주는 작업을 디비 리워드 작업이라 한다.
⭐
정리: 테이블에 데이터를 입력하게 되면 데이터는 HWM아래에 입력이 됨. 그리고 해당 테이블을 풀테이블 스캔 하게 되면 HWM까지 스캔한다. HWM가 높다면 full table scan 할 때 시간이 많이 걸리기 때문에 성능이 떨어진다!
1. append 힌트 사용해서 Direct load insert하기
SCOTT> insert /*+ append */ into emp_new
select *
from emp;
SCOTT> commit;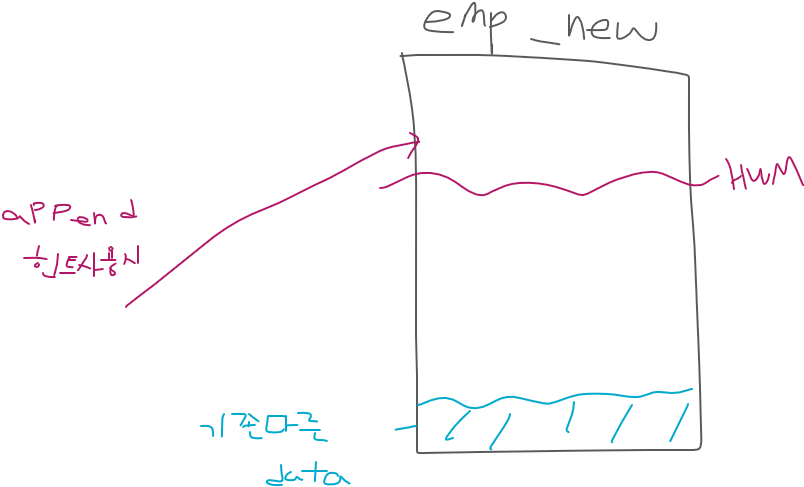
✅ HWM위에 입력하는것이 아래에 입력하는 것 보다 속도가 훨씬 빠릅니다! 이미지는 데이터가 예쁘게 있는 것 같지만 HWM 밑에는 구멍이 송송 뚤려있는 형태라서 구멍이 없는쪽을 찾아서 데이터를 넣기때문에 느리다.
❗ HWM위에 넣는것이 용량이 부족할 수는 있지만, 데이터 이행을 빠르게 하는것이 중요한 상황이라면 append를 사용하여 위에 넣는게 더 좋다.
2. parallel 힌트(병렬) 사용해서 Direct load insert하기
💡 좀 더 빠르게 데이터 이행을 하고자 하면, 병렬로 작업해야 합니다.
SCOTT> delete from emp_new;
SCOTT> insert /*+ parallel(emp_new, 4) */ into emp_new
select *
from emp;
-- 병렬도?!
/*+ parallel(emp_new, 4) */
↑ 병렬도 (cpu_count * 2만큼 줄 수 있다.)
SYS> show parameter cpu_count;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
cpu_count integer 2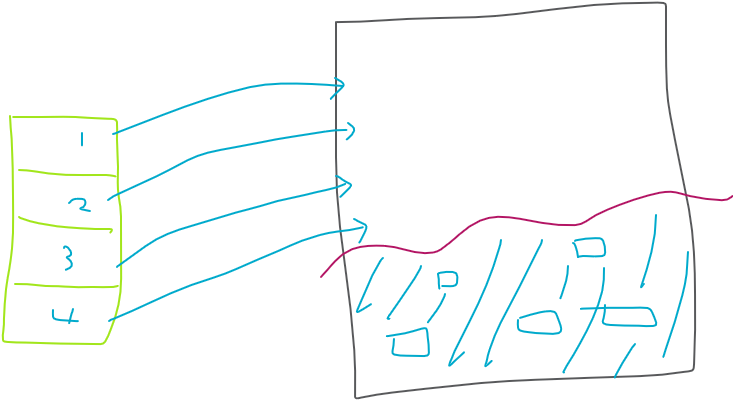
✅ parallel 힌트를 사용하면 4개의 프로세서가 나눠서 데이터를 이행한다. 원래는 1개가 했다. 더 빨라짐 !
✅ commit;을 해야 select가 되어야 하는게 맞는데 commit;을 하지 않았는데 select가 된다는 것은 HWM아래로 데이터가 들어갔다는 것입니다 -> 병렬처리 작업이 안되었다 !
❗ 병렬 쿼리 작업을 할 때는 병렬쿼리 작업이 가능하도록 활성화 작업을 해주어야 한다.
SCOTT @ orcl2 > alter session enable parallel dml; Session altered.
3. nologging 옵션을 이용해서 Direct load insert하기
💡 redo 가 생성되지 않는다. 속도는 빠르지만 복구가 되지 않는다.
SCOTT> delete from emp_new;
SCOTT> commit;
SCOTT> alter session enable parallel dml;
SCOTT> insert /*+ append */ into emp_new
nologging
select *
from emp;4. ⭐ Direct load insert 의 제약사항
- LOB 컬럼이 하나라도 있으면 수행이 안된다.
create table emp ( ename number(10), email clob); -- 이런거 있으면 안된다.
- IOT(index organized table) 는 지원하지 않는다.
- 분산 DB 환경에서는 지원하지 않는다.
✏️ SQL * Loader
💡 엑셀, csv, 텍스트 파일을 오라클 데이터 베이스의 테이블에 입력하는 툴 !
1. SQL * Loader 로 대용량 데이터 입력하기(text data)
✔️ 테이블 생성
✔️ 아래의 스크립트를 a.txt로 저장[orcl2:~]$ vi a.txt -- 아래 내용 넣고 저장 load data infile * into table depart_test fields terminated by ',' -- 데이터와 데이터는 콤마(,)로 구분하겠다. optionally enclosed by '"' -- 데이터 중에는 더블 쿼테이션 마크가 있을 수 있다. (did, dname, last_updated date 'yyyy-mm-dd') -- 컬럼명 begindata -- 여기까지는 데이터 넣기위한 문법 부분이고 아래는 데이터이다. 10,Electric,2000-01-05 11,Marketing,2000-07-05 12,transport,1999-03-02 13,manage,2001-03-05 10,Electric,2000-01-05 11,Marketing,2000-07-05 -- 테이블 만들 때 did는 숫자고 dname은 문자형태로 만들었다. 그렇지만 위에 '' 이런거 안했음. 그래도 잘 들어감! -- 날짜는 포맷을 지정해주자!✔️ 오라클의 데이터 이행 툴인 sqlloader를 이용해서 데이터 입력하기
$ sqlldr scott/tiger control=a.txt . . Commit point reached - logical record count 6✅
control=a.txt에 있는 컨트롤파일은 오라클의 컨트롤 파일이 아니고 sqlldr안의 컨트롤 파일이다.
✅ 데이터 파일은 텍스트 파일(데이터 들어있는파일), 콘트롤 파일은 데이터를 어떻게 넣겠다 라는 문법이 기록되어있다. (콤마로 구분, 옵션...등)
✅ 위는 컨트롤 파일안에 모든것을 다 넣고, 컨트롤 파일만 썼다.
❓ 그렇다면 데이터 파일과 컨트롤 파일을 서로 분리하고 데이터 이행을 하는 방법은?
1. 카페에서 sample.csv를 다운로드
2. sample 이라는 테이블을 scott유저에서 생성
3. 다운로드 받은 sample.csv를 리눅스에 /home/oracle밑에 올린다.
4. 데이터 입력 문법이 있는 아래의 컨트롤 파일을 생성한다.$ vi sample.txt options(skip=1) load data infile '/home/oracle/sample.csv' into table sample fields terminated by ',' optionally enclosed by '"' (line_no , time_inout, in_cnt, out_cnt )5. SQLloader를 이용해서 다음과 같이 데이터를 이행한다!
$ sqlldr scott/tiger control=sample.txt data=sample.csv . . Commit point reached - logical record count 20
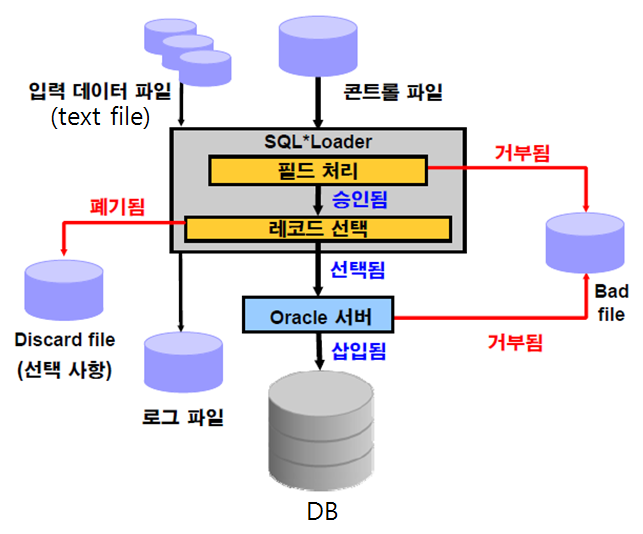
data file -> data가 있는 파일
controlfile -> SQL loader 문법이 들어있는 파일
bad file -> 문법에 어긋난 data가 들어간 파일
discard file -> 문법은 맞는데 테이블에 제약이 있어서 제약에 어긋나서 입력 안되는 data가 들어간 파일
log file -> SQL loader로 데이터를 이행한 이력정보SQL loader를 이용해서 데이터 입력시 성능을 높이는 방법
💡direct 옵션
- y : direct path load 방식으로 load 한다. (HWM 위에 입력)
- n : conventional load 방식으로 load 한다. (HWM 아래에 입력)
$ sqlldr scott/tiger control=sales100.txt data=sales.csv direct=y✏️ 데이터 이관 vs 데이터 이행
데이터 이관은 구서버에있는 데이터를 그대로(통채로) 신서버로 옮기는 것이고 데이터 이행은 구서버에 있는 데이터를 일부 변경하고, 컬럼을 삭제/추가 등 특별한 작업을 해서 옮긴다.
✏️ export / import
table 단위: 특정 테이블만 export / importuser 단위: scott과 같이 유저가 가지고 있는 모든 객체를 export / importtablespace 단위: tablespace의 데이터를 통채로 export / importdatabase 단위: database를 통채로 export / import
✅ feedback=10를 쓰면 export 과정이 보인다.
✅ 데이터의 정합성이 중요하므로 이행후에 두 데이터가 똑같이 맞는지 확인해보기! (db link 만들어서 minus를 통해 차이점을 구할 것!)
💡 참고) db link 생성
* 생성, 조회해보기
SCOTT @ orcl3> create database link orcl2_link
connect to scott
identified by tiger
using 'edydr1p0.us.oracle.com:1521/orcl2';
SCOTT @ orcl3> select * from dept@orcl2_link; * orcl3에서 orcl2 scott 유저의 테이블들의 이름, 건수를 확인
SCOTT @ orcl3> select table_name, num_rows
from user_tables@orcl2_link;1. table 단위 level export/import
순서
1. orcl2에서 scott계정의 emp 테이블을 export 하기
$ . oraenv orcl2 [orcl2:~]$ exp scott/tiger tables=emp file=emp.dmp2. orcl3에서 scott계정에 emp 테이블을 import 하기
$ . oraenv orcl3 [orcl3:~]$ imp scott/tiger tables=emp file=emp.dmp
2. user level로 export/import
1. orcl2의 scott이 가지고 있는 모든 테이블을 통채로 export 하기
$ . oraenv orcl2 $ exp scott/tiger owner=scott file=scott.dmp2.orcl2의 scott.dmp를 orcl3에 import 하기
[orcl3:~]$ imp system/oracle file=scott.dmp fromuser=scott touser=scott💡 데이터 정합성 검사 필수
🚨 user level로 이행할 때 주의사항
위 방법은 데이터가 작은 회사는 좋은방법이지만 KT나 텔레콤, 대기업 DB에서는 이렇게 작업하면 시간이 너무 오래걸리고 제일 중요한 것은 UNDO가 full나고 TEMP도 full이 납니다.
인덱스, 제약, 함수, 프로시저등을 나중에 생성하는 방법으로 수행하는것이 좋다!
* 효율적 이행
1. as - is DB 에서 테이블 생성 스크립트만 뽑아내서 to- be DB에 빌드한다.
2. 데이터 덤프를 뽑아내서 import 한다.
3. 인덱스 생성 스크립트를 뽑아내서 to - be DB에 병렬도를 지정해서 인덱스를 생성한다.
4. 제약 생성 스크립트를 뽑아내서 to - be DB에 제약을 생성
5. 시너님, 프로시저, 함수 생성 스크립트 뽑아내서 to - be DB에 생성
6. as - is와 to - be 간의 테이블 갯수와 데이터 건수, 인덱스 건수, 시너님, 프로시저, 함수의 갯수, 권한이 일치하는지 확인3. table space level export/import 할때
- orcl2, orcl3의 Character set이 서로 일치한지 확인후
- orcl2에서 tablespace를 하나 만든다.(이것을 통채로 넘길것임)
- 만든 tablespace 안에 table만들고 데이터를 넣는다.
- 이제 table이 들어있는 Tablespace를 넘겨줄건데 그전에 tablespace를 read only 상태로 바꾼다.(백업을 해도 된다는 의미이다.)
- 테이블스페이스를 tablespace 단위로 export 한다.
$ exp transport_tablespace=y tablespaces=tsysh file=ts.dmp
Username: sys as sysdba- 이제 2개의 파일이 필요하다.
1. ts.dmp 덤프 파일 -> 위에서 만든 덤프파일
2. tsysh.dbf 데이터 파일 -> 넘겨줄 ts의 데이터파일- 위 두개의 파일을 orcl3로 copy!
-- 1. tsysh.dbf는 /u01/app/oracle/oradata/orcl3/ 로 copy
$ cp /home/oracle/tsysh.dbf /u01/app/oracle/oradata/orcl3/tsysh.dbf
-- 2. ts.dmp는 /home/oracle 밑에 있으면 된다.- orcl3에서 임포트하기
$ imp transport_tablespace=y file=ts.dmp
datafiles='/u01/app/oracle/oradata/orcl3/tsysh.dbf';❗️주의사항!
✔️ Character set 서로 일치해야 한다.SYS @ orcl2 > col PROPERTY_NAME for a30 col PROPERTY_VALUE for a20 select PROPERTY_NAME , PROPERTY_VALUE from database_properties where PROPERTY_NAME like '%CHARA%';✔️ Read Only로 변경한 후에 바로 data file을 copy
SYS> alter tablespace tsysh read only;
4. database level로 export/import 할때
complete: database 전체를 exportincremental: database 전체를 export한 이후에 변경된 부분만 exportcumulative: 변경된 부분을 누적해서 export
complete incre incre incre incre cumulative
월 화 수 목 금 토
$ exp full=y file=complete01.dmp inctype=complete; 