복습
- 데이터 이행 3가지
Direct load insert
SQL * Loader
export/import1. table level 2. user level : orcl2 -----> oecl3 3. tablespace level 4. database level
tablespace level의 export/import
💡 테이블 스페이스를 통채로 다른 db에 이관하는 것 ! (이행과 이관 차이의 개념을 명확히 알고 있어야 한다.)
* si dba의 일:
orcl(예전 서버) --------------> orcl3(새로운 서버)
* sm dba의 일:
orcl2(운영) -----------------> orcl3(개발)tablespace level로 export/import 하는 방법 실습
orcl2 ----------------> orcl3
ts01 tablespace를 통채로 orcl3로 넘길 것이다.작업하기 전에 먼저 확인해야 하는 작업
✔️Character set서로 일치해야 한다.
✔️Read Only로 변경한 후에 바로 data file을 copy[orcl2:~]$ ps -ef | grep pmon oracle 5469 1 0 Oct09 ? 00:00:16 asm_pmon_+ASM oracle 8189 1 0 06:47 ? 00:00:02 ora_pmon_orcl3 oracle 19466 1 0 09:30 ? 00:00:00 ora_pmon_orcl21. orcl2 와 orcl3 에서 각각 character set 을 확인합니다.
$ . oraenv orcl2 SYS @ orcl2 > col PROPERTY_NAME for a30 col PROPERTY_VALUE for a20 select PROPERTY_NAME , PROPERTY_VALUE from database_properties where PROPERTY_NAME like '%CHARA%'; PROPERTY_NAME PROPERTY_VALUE ------------------------------ -------------------- NLS_NUMERIC_CHARACTERS ., NLS_CHARACTERSET KO16MSWIN949 NLS_NCHAR_CHARACTERSET AL16UTF16 SYS @ orcl3 > col PROPERTY_NAME for a30 col PROPERTY_VALUE for a20 select PROPERTY_NAME , PROPERTY_VALUE from database_properties where PROPERTY_NAME like '%CHARA%';SYS @ orcl3 > SYS @ orcl3 > 2 3 PROPERTY_NAME PROPERTY_VALUE ------------------------------ -------------------- NLS_NUMERIC_CHARACTERS ., NLS_CHARACTERSET KO16MSWIN949 NLS_NCHAR_CHARACTERSET AL16UTF162. 테이블 스페이스 생성 ( 테이블스페이스 명이 짝꿍과 중복되지 않도록 )
SYS> create tablespace tsysh datafile '/home/oracle/tsysh.dbf' size 5m;3. SCOTT 유저로 접속하여 1번에서 생성한 테이블스페이스에(tsysh) table 을 생성한다.
SCOTT> create table emp06 ( empno number(10), ename varchar2(20) ) tablespace tsysh;4. 아래의 작업을 3번 이상 반복한다.(data 입력)
SCOTT> insert into emp06 values(1111,'aaa'); SCOTT> commit; SCOTT> select count(*) from emp06; COUNT(*) ---------- 3
- SYS 유저에서 orcl3로 tsysh 테이블스페이스를 넘겨줄 준비를 한다.
-- ( tsysh 테이블 스페이스를 read only 로 변경한다. )SYS> alter tablespace tsysh read only;-- read only 로 변경했다는 것은, 백업을 해도 된다는 의미이다.
-- 따라서 read only 로 변경한 후 원본 datafile 을 복사한다.SYS> select t.name, d.enabled from v$tablespace t, v$datafile d where t.ts# = d.ts#; NAME ENABLED ------------------------------ ---------- SYSTEM READ WRITE SYSAUX READ WRITE UNDOTBS1 READ WRITE USERS READ WRITE EXAMPLE READ WRITE TSYSH READ ONLY6. tsyeom 테이블스페이스를 tablespace 단위로 export 한다.
$ exp transport_tablespace=y tablespaces=tsysh file=ts.dmp Username: sys as sysdba Password:oracle✔️ transport_tablespace 에 테이블스페이스명을 입력했을 때 오류가 발생하면 y 를 쓰도록 한다.
7. 2개의 파일을 준비해야 합니다.
- ts.dmp 덤프 파일
- tsysh.dbf 데이터 파일
8. 위 두개의 파일을 orcl3로 copy합니다.- tsysh.dbf는 /u01/app/oracle/oradata/orcl3/ 로 copy
$ cp /home/oracle/tsysh.dbf /u01/app/oracle/oradata/orcl3/tsysh.dbf
- ts.dmp는 /home/oracle 밑에 있으면 된다.
9. orcl3으로 이동
10. 아래의 임포트 명령어로 임포트 수행$ imp transport_tablespace=y file=ts.dmp datafiles='/u01/app/oracle/oradata/orcl3/tsysh.dbf';11. orcl3 sys유저로 접속해서 tsysh 테이블 스페이스가 잘 보이는지 확인
SYS> select t.name, d.enabled from v$tablespace t, v$datafile d where t.ts# = d.ts#; SYS> alter tablespace tsysh read write;
문제 orcl2에서 ts100 테이블 스페이스를 만들고 tablespace에 emp100테이블을 생성하고 데이터도 emp와 똑같이 맞추세요. 그리고 ts100 테이블 스페이스를 통채로 orcl3로 이관하기 !
1. 테이블 스페이스 생성, emp100테이블 생성
SYS> create tablespace ts100 datafile '/home/oracle/ts100.dbf' size 5m; SCOTT> create table emp100 tablespace ts100 as select * from emp where 1=2; -- 구조 만들기 SCOTT> insert into emp100 select * from emp; -- 데이터 넣기 SCOTT> commit;orcl2에서 export
SYS> alter tablespace ts100 read only; exp transport_tablespace=y tablespaces=ts100 file=ts100.dmp위 두개의 파일을 orcl3로 copy합니다.
$ cp /home/oracle/ts100.dbf /u01/app/oracle/oradata/orcl3/ts100.dbf10. 아래의 임포트 명령어로 임포트 수행
$ imp transport_tablespace=y file=ts100.dmp datafiles='/u01/app/oracle/oradata/orcl3/ts100.dbf';❓ @ ts하면 ts100 있는데 cp가 안됨
-> orcl2에서 export 하면 orcl3에 ts100이 생기는게 맞나요? cp 해야하는데 ts100이 orcl3에 있어서 orcl3에서 ts100을 지우니까 자꾸 에러가 남
database level로 export/import
- complete : database 전체를 export
- incremental : database 전체를 export한 이후에 변경된 부분만 export
- cumulative : 변경된 부분을 누적해서 export
complete incre incre incre incre cumulative
월 화 수 목 금 토
$ exp full=y file=complete01.dmp inctype=complete; export pump / import pump
💡 기존 export / import를 더 업그레이드 한것이 export pump / import pump
- export 로 받은 파일은?
dump 파일 - export pump 로 받은 파일은?
pump 파일
➡️ pump의 장점?
1. export / import 작업을 잠깐 중지시켰다가 재시작 시킬 수 있습니다.
2. 병렬로 작업할 수 있습니다. (가장 큰 장점)
3. export 하기 전에 작업에 필요한 디스크 공간을 미리 예측할 수 있다.
4. db link를 이용해서 바로 export한 pump 파일을 원격지에 생성할 수 있습니다.
5. 다양한 remaping이 가능하다.orcl2 ------------> orcl3 sales ------------> sales 테이블 example tablespace ts300 tablespace scott scott_dev emp -------------> emp
- orcl3에도 example tablespace 가 있어야 이쪽에 sales테이블을 import 할 수 있는데 pump는 그냥 ts300 tablespace에 remaping이 가능하다.
- 원래는 유저명이 같아야 import가 되는데, 유저명이 달라도 임포트가 가능하다.
- export 하면서 pump 파일을 압축을 바로 할 수 있습니다.
- 기본 export /import 방식에 비해서 속도가 20배 정도 더 빠릅니다. (중요)
pump 의 종류 4가지
- table level
- user level
- tablespace level
- database level
table level pump 실습
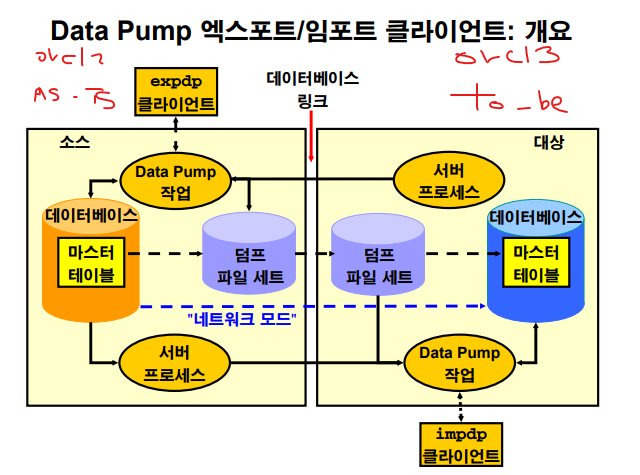
1. directory를 생성합니다.
#1. 디렉토리가 있는지 조회하기(orcl2) SYS> select * from dba_directories; DATA_PUMP_DIR /u01/app/oracle/admin/orcl2/dpdump/ -- 얘는 디폴트 디렉토리 #2. 디렉토리 하나 만들기 $ mkdir /home/oracle/pump_orcl2 orcl2 SYS> create directory datapump_dir as '/home/oracle/pump_orcl2';2. export pump/ impoir pump 를 수행할 유저에게 directory 를 엑세스할 권한을 부여합니다.
orcl2 SYS> grant read, write on directory datapump_dir to scott,sh,hr;3. table level로 export pump 합니다.
$ expdp sh/sh directory=datapump_dir tables=sales dumpfile=sales_pump.dmp [orcl2:~]$ cd pump_orcl2/ [orcl2:pump_orcl2]$ ls export.log sales_pump.dmp4. orcl3에 import를 합니다.
orcl2 --------------------------------> orcl3 /home/oracle/pump_orcl2 /home/oracle/pump_orcl3 #orcl3에서 /home/oracle/pump_orcl3 디렉토리를 생성하기 orcl3 > $ mkdir /home/oracle/pump_orcl3 #orcl3에서 orcl3_dir 디렉토리를 생성합니다. orcl3 SYS> create directory orcl3_dir as '/home/oracle/pump_orcl3'; orcl3 SYS> grant read, write on directory orcl3_dir to scott; orcl3 SYS> create tablespace ts1000 datafile '/home/oracle/ts1000.dbf' size 100m;5. /home/oracle/pump_orcl2 밑에 있는 sales_pump.dmp를 /home/oracle/pump_orcl3 밑으로 카피합니다.
$ cp /home/oracle/pump_orcl2/sales_pump.dmp /home/oracle/pump_orcl3/sales_pump.dmp6. 그리고 다음과 같이 orcl2의 sales 테이블을 orcl3으로 임포트 합니다.
orcl2 -----------------------------------> orcl3 /home/oracle/pump_orcl2 /home/oracle/pump_orcl3 디렉토리명: datapump_dir 디렉토리명: orcl3_dir 테이블: sales 테이블: sales 유저: sh 유저: scott ts: example ts: ts1000 $ .oraenv orcl3 $ impdp scott/tiger directory=orcl3_dir dumpfile=sales_pump.dmp remap_schema=sh:scott remap_tablespace=example:ts1000 SCOTT @ orcl3 > select count(*) from sales; COUNT(*) ---------- 918843✅orcl2에 있는 sh의 sales테이블을 export pump를 받았고, orcl3_dir에 가져다 놓았다.
점심시간 문제 다음과 같이 orcl2의 hr 계정의 employees 테이블을 orcl3의 scott 계정에 import pump 하기!
orcl2 -----------------------------------> orcl3
/home/oracle/pump_orcl2 /home/oracle/pump_orcl3
디렉토리명: datapump_dir 디렉토리명: orcl3_dir
테이블: employees 테이블: sales
유저: hr 유저: scott
ts: example ts: ts20001. table level로 export pump 합니다. (orcl2)
$ expdp hr/hr directory=datapump_dir tables=employees dumpfile=employees_pump.dmp [orcl2:~]$ cd pump_orcl2/ [orcl2:pump_orcl2]$ ls export.log sales_pump.dmp2. orcl3에서 ts2000만들기
orcl3 SYS> create tablespace ts2000 datafile '/home/oracle/ts2000.dbf' size 100m;3. orcl2에서 /home/oracle/pump_orcl2 밑에 있는 sales_pump.dmp를 /home/oracle/pump_orcl3 밑으로 카피합니다.
$ cp /home/oracle/pump_orcl2/employees_pump.dmp /home/oracle/pump_orcl3/employees_pump.dmp4. orcl3계정에서 import하기
$ impdp scott/tiger directory=orcl3_dir dumpfile=employees_pump.dmp remap_schema=hr:scott remap_tablespace=example:ts2000 SCOTT @ orcl3 > select count(*) from employees; COUNT(*) ---------- 107
remaping 옵션 (p.17-19)

- remap_tablespace
- remap_schema
- remap_datafile
- remap_table
- remap_data : 데이터 이행하면서 data를 변경할 수 있다.
user level 펌프 실습
orcl2 ----------------------> orcl3
scott의 모든 테이블 smith 유저 생성하고 임포트1. scott계정이 가지고있는 모든 테이블들을 전부 export data pump 합니다.
$ expdp scott/tiger directory=datapump_dir schemas=scott dumpfile=scott.dmp💡 병렬로 export pump 하기
$ expdp scott/tiger directory=datapump_dir schemas=scott dumpfile=scott2.dmp parallel=4 SYS @ orcl2 > show parameter cpu_count NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ cpu_count integer 2 -- 이거 *22. orcl2에서 생성한 scott.dmp파일을 orcl3에 임포트 하기 위해서 orcl3에 smith라는 유저 생성하기
SYS @ orcl3> create user smith identified by tiger; SYS @ orcl3> grant connect, resource to smith;3. /home/oracle/pump_orcl2 밑에 있는 scott.dmp를 home/oracle/pump_orcl3밑에 복사하기!
orcl2 -----------------------------------> orcl3 /home/oracle/pump_orcl2 /home/oracle/pump_orcl3 디렉토리명: datapump_dir 디렉토리명: orcl3_dir 유저: scott 유저: smith # 복사하기 $ cp /home/oracle/pump_orcl2/scott.dmp /home/oracle/pump_orcl3/scott.dmp4. orcl3에서 scott.dmp를 import pump합니다.
[orcl2:~]$ . oraenv ORACLE_SID = [orcl2] ? orcl3 [orcl3:~]$ impdp system/oracle directory=orcl3_dir dumpfile=scott.dmp remap_schema=scott:smith SMITH @ orcl3 > select table_name from user_tables; TABLE_NAME ------------------------------ SALES100 DEPT100 SAMPLE DEPART_TEST EMP_NEW SALGRADE BONUS EMP DEPT
문제 orcl2 sh의 계정의 모든 테이블들을 스키마 단위로 export pump를 받고 orcl3의 sh2 계정에 import pump를 하시오 !
orcl2 -----------------------------------> orcl3
/home/oracle/pump_orcl2 /home/oracle/pump_orcl3
디렉토리명: datapump_dir 디렉토리명: orcl3_dir
유저: scott 유저: smith1. sh계정이 가지고있는 모든 테이블들을 전부 export data pump 합니다.
$ expdp sh/sh directory=datapump_dir schemas=sh dumpfile=sh.dmp2. orcl2에서 생성한 sh.dmp파일을 orcl3에 임포트 하기 위해서 orcl3에 sh2라는 유저 생성하기
SYS @ orcl3> create user sh2 identified by sh2; SYS @ orcl3> grant connect, resource to sh2;3. /home/oracle/pump_orcl2 밑에 있는 scott.dmp를 home/oracle/pump_orcl3밑에 복사하기!
$ cp /home/oracle/pump_orcl2/sh.dmp /home/oracle/pump_orcl3/sh.dmp4. orcl3에서 sh.dmp를 import pump합니다.
[orcl3:~]$ impdp system/oracle directory=orcl3_dir dumpfile=sh.dmp remap_schema=sh:sh25. 병렬로 sh계정의 모든 테이블들을 전부 export하기
$. oraenv orcl2 $ expdp sh/sh directory=datapump_dir schemas=sh dumpfile=sh_%U.dmp parallel=4 [orcl2:pump_orcl2]$ ls employees_pump.dmp sales_pump.dmp scott2.dmp sh_01.dmp sh_03.dmp export.log scott.dmp sh.dmp sh_02.dmp💡 병렬로 작업할 때는 dumpfile명에 %U를 써주어야 합니다. %U를 쓰면 오라클이 알아서 dump 파일 명을 병렬도에 맞춰서 생성합니다.
- export pump/ import pump를 할 때 진행과정을 모니터링 할 수 있다.
■ export / import 하는 과정을 모니티링하는 스크립트 select owner_name, job_name, operation, state from dba_datapump_jobs; select opname, target_desc, sofar, totalwork, (sofar/totalwork * 100) per, username from v$session_longops where opname='SYS_EXPORT_SCHEMA_01';
totalwork: 총 수행해야할 용량( 단위 : MB)
sofar: 현재 수행한 용량 ( 단위 : MB)
target_desc: 작업의 종류
opname: job name 과 같다.
tablespace level로 export / import pump 하는 방법
✔️ orcl2에서 작업
1. ts2000 테이블 스페이스 생성
2. scott 유저로 접속해서 ts2000 테이블 스페이스에서 emp2000 테이블 생성
3. ts2000 테이블 스페이스를 read only로 변경하기
4. ts2000 테이블 스페이스를 export 하기
5. /u01/app/oracle/oradata/orcl2/ts2000.dbf 파일을 /u01/app/oracle/oradata/orcl3/ts2000.dbf에 copy하기
6. /home/oracle/pump_orcl2 밑에있는 ts2000.dmp를 /home/oracle/pump_orcl3 밑에 copy하기
✔️ orcl3에서 작업
7. orcl3에 ts2000.dmp 파일을 임폴터 데이터 펌프 합니다.
8. ts2000 테이블 스페이스를 read write합니다.
9. scott 계정에서 emp2000 테이블 조회가 되는지 확인
✔️ orcl2에서 작업
1. ts2000 테이블 스페이스 생성SYS > create tablespace ts2000 datafile '/u01/app/oracle/oradata/orcl2/ts2000.dbf' size 10m;
- scott 유저로 접속해서 ts2000 테이블 스페이스에서 emp2000 테이블 생성
SCOTT> create table emp2000 (empno number(10), ename varchar2(10), sal number(10) ) tablespace ts2000; SCOTT> insert into emp2000 select empno, ename, sal from emp; SCOTT> commit;
- ts2000 테이블 스페이스를 read only로 변경하기
SYS> alter tablespace ts2000 read only;
- ts2000 테이블 스페이스를 export 하기
$ expdp directory=datapump_dir dumpfile=ts2000.dmp transport_tablespace=y tablespaces=ts2000 . . Job "SYS"."SYS_EXPORT_TRANSPORTABLE_01" successfully completed at 15:06:52
- /u01/app/oracle/oradata/orcl2/ts2000.dbf 파일을 /u01/app/oracle/oradata/orcl3/ts2000.dbf에 copy하기
$ cp /u01/app/oracle/oradata/orcl2/ts2000.dbf /u01/app/oracle/oradata/orcl3/ts2000.dbf
- /home/oracle/pump_orcl2 밑에있는 ts2000.dmp를 /home/oracle/pump_orcl3 밑에 copy하기
$ cp /home/oracle/pump_orcl2/ts2000.dmp /home/oracle/pump_orcl3/ts2000.dmp✔️ orcl3에서 작업
7. orcl3에 ts2000.dmp 파일을 임폴터 데이터 펌프 합니다.$ impdp directory=orcl3_dir dumpfile=ts2000.dmp transport_datafiles='/u01/app/oracle/oradata/orcl3/ts2000.dbf'
- ts2000 테이블 스페이스를 read write합니다.
- scott 계정에서 emp2000 테이블 조회가 되는지 확인
문제 ts3000 테이블 스페이스를 orcl2에서 만들고 ts3000에 emp3000테이블을 생성한 후에 데이터를 좀 넣고나서 ts3000 테이블 스페이스를 orcl3로 이관하시오!
1. ts3000 테이블 스페이스 생성
create tablespace ts3000 datafile '/u01/app/oracle/oradata/orcl2/ts3000.dbf' size 10m;2. scott 유저로 접속해서 ts3000 테이블 스페이스에서 emp3000 테이블 생성
SCOTT> create table emp3000 (ename varchar2(10), sal number(10) ) tablespace ts3000; SCOTT> insert into emp3000 select ename, sal from emp; SCOTT> commit;3.ts3000 테이블 스페이스를 read only로 변경하기
SYS> alter tablespace ts3000 read only;4.ts3000 테이블 스페이스를 export 하기
$ expdp directory=datapump_dir dumpfile=ts3000.dmp transport_tablespace=y tablespaces=ts30005. /u01/app/oracle/oradata/orcl2/ts2000.dbf 파일을 /u01/app/oracle/oradata/orcl3/ts2000.dbf에 copy하기
$ cp /u01/app/oracle/oradata/orcl2/ts3000.dbf /u01/app/oracle/oradata/orcl3/ts3000.dbf6. /home/oracle/pump_orcl2 밑에있는 ts2000.dmp를 /home/oracle/pump_orcl3 밑에 copy하기
$ cp /home/oracle/pump_orcl2/ts3000.dmp /home/oracle/pump_orcl3/ts3000.dmp✔️ orcl3에서 작업
7. orcl3에 ts3000.dmp 파일을 임폴터 데이터 펌프 합니다.$ impdp directory=orcl3_dir dumpfile=ts3000.dmp transport_datafiles='/u01/app/oracle/oradata/orcl3/ts3000.dbf'
⭐ 보유기술
- 데이터 이행 3가지 방법
- direct load insert
- SQL loader
- export pump / import pump
- table level
- schema level
- tablespace level
- database level
database level로 export pump하기
$ expdp directory=datapump_dir full=y file=complete02.dmp 현업에서 export / import pump 수행하는 방법
🤔 가장 빠른 데이터 이행은?
1. 오라클 골든게이트(유료)
2. 테이블 스페이스 레벨의 export / import (transport tablespace)
✅ 위와 같이 이행할것이 아니라면 가장 많이 사용하는 export / import는 스키마(schema)레벨의 export / import 입니다.
❗ 잘 모른다면 그냥 스키마 단위로 export, import 합니다. 이렇게 하면 이행하는 과정에서 임포트 하는 db쪽에 temp와 undo tablespace가 full나면서 작업이 안됩니다.
이것을 해결하는 방법이 인덱스와 제약을 나중에 생성하는 방법이다.(아래참고)orcl2 ----------------> orcl3 hr hr3✔️ 0, 1번은 orcl2, 나머지는 orcl3에서 진행
0. hr 계정의 데이터를 스키마 단위로 export합니다.
1. hr의 테이블 생성스크립트를 뽑아냅니다. (contraint=n)
2. hr3에서 1번에서 생성한 스크립트를 돌립니다.
3. hr의 dump 파일을 hr3로 import 합니다.
4. hr3에서 인덱스를 생성합니다.
5. hr3에 제약을 생성합니다.
➡️ 그냥 export / import와 어떤 차이가 있냐면, 인덱스와 제약을 나중에 생성한다.
실습
✔️ 0번은 orcl2, 나머지는 orcl3에서 진행
0. hr 계정의 데이터를 스키마 단위로 export합니다.$ exp system/oracle file=hr.dmp owner=hr1. hr의 테이블 생성스크립트를 뽑아냅니다. (contraint=n)
SYS @ orcl3> create user hr3 identified by tiger; SYS @ orcl3> grant connect, resource to hr3; SYS @ orcl3> create user oe identified by oe; SYS @ orcl3> grant connect, resource to oe; $ imp system/oracle file=hr.dmp fromuser=hr touser=hr3 indexes=n constraints=n indexfile=hr_table.sql✅ 위 명령어는 진짜 임포트를 하는게 아니라 테이블 생성 스크립트를 만드는 것이다! indexes=n contraints=n 으로 했기때문에 index 생성 스크립트나, contraints 생성 스크립트를 생성하지 않고 테이블 생성 스크립트만 만드는 것이다.
:%s/REM //g
2. hr3에서 1번에서 생성한 스크립트를 돌립니다.
$ vi hr_table.sql -- 안에 내용 위처럼 편집 HR3 @ orcl3 > @/home/oracle/hr_table.sql HR3 @ orcl3 > select index_name from user_indexes; INDEX_NAME ------------------------------ COUNTRY_C_ID_PK --하나만 있다. no 했는데도 만들어진거보면 중요한 애 일듯! 이정도는 괜찮다.3. hr의 dump 파일을 hr3로 import 합니다.
$ imp system/oracle file=hr.dmp ignore=y indexes=n fromuser=hr touser=hr3 HR3 @ orcl3 > exec dbms_stats.gather_schema_stats('HR3'); HR3 @ orcl3 > select table_name from user_tables;⭐
ignore=y는 데이터를 임포트 할 때 기존에 테이블이 이미 존재하면 무시하고 data만 입력하겠다!라는 것이다. 테이블 없으면 임포트하고 있으면 데이터만 입력..
4. hr3에서 인덱스를 생성합니다. -> vi로 열면 주석처리(REM)되어있는건 아까 만든거라서 이번에는 안지워도 된다.NOLOGGING;뒤에 parallel 4 를 붙여줘야한다.:%s/NOLOGGING /NOLOGGING parallel 4 /g$ imp system/oracle file=hr.dmp indexes=y constraints=n fromuser=hr touser=hr3 indexfile=hr_index.sql $ vi hr_index.sql --편집 HR3 @ orcl3 > @/home/oracle/hr_index.sql HR3 @ orcl3 > select index_name from user_indexes; --orcl3(19개)5. hr3에 제약을 생성합니다.
select constraint_name from user_constraints; --orcl3(34개)6. 다시 인덱스의 병렬도를 4에서 1로 변경
HR3 @ orcl3 > select ' alter index ' || index_name || ' parallel 1; ' from user_indexes; 'ALTERINDEX'||INDEX_NAME||'PARALLEL1;' -------------------------------------------------------- alter index REG_ID_PK parallel 1; alter index LOC_ID_PK parallel 1; alter index LOC_CITY_IX parallel 1; alter index LOC_STATE_PROVINCE_IX parallel 1; alter index LOC_COUNTRY_IX parallel 1; alter index JHIST_EMP_ID_ST_DATE_PK parallel 1; alter index JHIST_JOB_IX parallel 1; alter index JHIST_EMPLOYEE_IX parallel 1; alter index JHIST_DEPARTMENT_IX parallel 1; alter index JOB_ID_PK parallel 1; alter index EMP_EMAIL_UK parallel 1; 'ALTERINDEX'||INDEX_NAME||'PARALLEL1;' -------------------------------------------------------- alter index EMP_EMP_ID_PK parallel 1; alter index EMP_DEPARTMENT_IX parallel 1; alter index EMP_JOB_IX parallel 1; alter index EMP_MANAGER_IX parallel 1; alter index EMP_NAME_IX parallel 1; alter index DEPT_ID_PK parallel 1; alter index DEPT_LOCATION_IX parallel 1; alter index COUNTRY_C_ID_PK parallel 1; 19 rows selected. SQL> select index_name, degree from user_indexes;⭐ orcl2, orcl3간의 3가지 데이터의 일치성을 확인해야 한다.
1. orcl2, orcl3간의 hr 계정의 테이블 갯수와 건수 확인 - 일치했다!HR @ orcl2 > select table_name from user_tables; TABLE_NAME ------------------------------ COUNTRIES JOB_HISTORY EMPLOYEES JOBS DEPARTMENTS LOCATIONS REGIONS 7 rows selected.
- orcl2, orcl3간의 hr 계정의 인덱스 갯수 확인 - 일치했다.
- orcl2, orcl3간의 hr 계정의 제약 갯수 확인 - 일치했다.
오늘의 마지막 문제 orcl2의 sh 계정의 모든 테이블과 인덱스, 제약을 orcl3 sh3 계정에 임포트 하는데 가장 효율적인 방법으로 작업하시오!
풀이
✔️ 0번은 orcl2, 나머지는 orcl3에서 진행
0. orcl2의 sh 계정의 데이터를 스키마 단위로 export합니다.$ exp system/oracle file=sh.dmp owner=sh1. hr의 테이블 생성스크립트를 뽑아냅니다. (contraint=n)
SYS @ orcl3> create user sh3 identified by sh3; SYS @ orcl3> grant connect, resource to sh3; $ imp system/oracle file=sh.dmp fromuser=sh touser=sh3 indexes=n constraints=n indexfile=sh_table.sql✅
vi sh_table.sql열어서:%s/REM //g진행 !,...000rows이런거다 삭제2. sh3에서 1번에서 생성한 스크립트를 돌립니다.
SH3 @ orcl3 > @/home/oracle/sh_table.sql SH3 @ orcl3 > select index_name from user_indexes; no rows selected3. sh의 dump 파일을 sh3로 import 합니다.
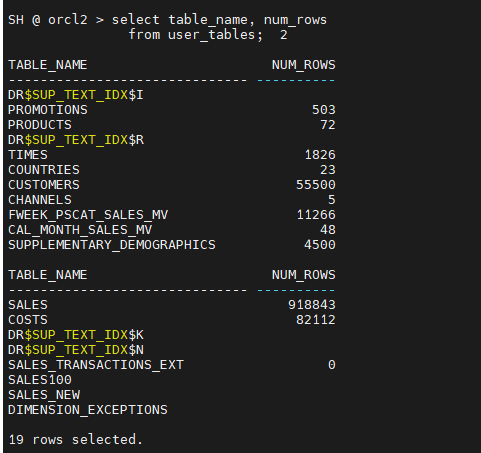
$ imp system/oracle file=sh.dmp ignore=y indexes=n fromuser=sh touser=sh3 SH3 @ orcl3 > exec dbms_stats.gather_schema_stats('SH3'); SH3 @ orcl3 > select table_name, num_rows from user_tables;⭐
ignore=y는 데이터를 임포트 할 때 기존에 테이블이 이미 존재하면 무시하고 data만 입력하겠다!라는 것이다. 테이블 없으면 임포트하고 있으면 데이터만 입력..4. sh3에서 인덱스를 생성합니다.
$ imp system/oracle file=sh.dmp indexes=y constraints=n fromuser=sh touser=sh3 indexfile=sh_index.sql SH3 @ orcl3 > @/home/oracle/sh_index.sql SH3 @ orcl3 > select index_name from user_indexes;5. sh3 제약 확인.
select constraint_name from user_constraints;6. 다시 인덱스의 병렬도를 4에서 1로 변경
SH3 @ orcl3 > select ' alter index ' || index_name || ' parallel 1; ' from user_indexes; 'ALTERINDEX'||INDEX_NAME||'PARALLEL1;' -------------------------------------------------------- alter index SUP_TEXT_IDX parallel 1; alter index TIMES_PK parallel 1; alter index SYS_IOT_TOP_75333 parallel 1; alter index SYS_IL0000075330C00002$$ parallel 1; alter index SYS_IOT_TOP_75328 parallel 1; alter index SYS_IL0000075325C00006$$ parallel 1; alter index DR$SUP_TEXT_IDX$X parallel 1; alter index SALES_PROD_BIX parallel 1; alter index SALES_CUST_BIX parallel 1; alter index SALES_TIME_BIX parallel 1; alter index SALES_CHANNEL_BIX parallel 1; 'ALTERINDEX'||INDEX_NAME||'PARALLEL1;' -------------------------------------------------------- alter index SALES_PROMO_BIX parallel 1; alter index PROMO_PK parallel 1; alter index PRODUCTS_PK parallel 1; alter index PRODUCTS_PROD_SUBCAT_IX parallel 1; alter index PRODUCTS_PROD_CAT_IX parallel 1; alter index PRODUCTS_PROD_STATUS_BIX parallel 1; alter index FW_PSC_S_MV_SUBCAT_BIX parallel 1; alter index FW_PSC_S_MV_CHAN_BIX parallel 1; alter index FW_PSC_S_MV_PROMO_BIX parallel 1; alter index FW_PSC_S_MV_WD_BIX parallel 1; alter index CUSTOMERS_PK parallel 1; 'ALTERINDEX'||INDEX_NAME||'PARALLEL1;' -------------------------------------------------------- alter index CUSTOMERS_GENDER_BIX parallel 1; alter index CUSTOMERS_MARITAL_BIX parallel 1; alter index CUSTOMERS_YOB_BIX parallel 1; alter index COUNTRIES_PK parallel 1; alter index COSTS_PROD_BIX parallel 1; alter index COSTS_TIME_BIX parallel 1; alter index CHANNELS_PK parallel 1;⭐ orcl2, orcl3간의 3가지 데이터의 일치성을 확인해야 한다.
- orcl2, orcl3간의 hr 계정의 테이블 갯수와 건수 확인
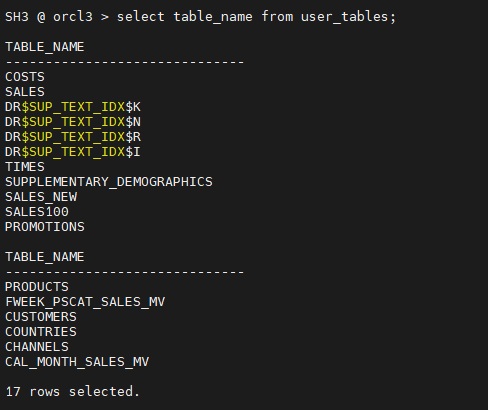
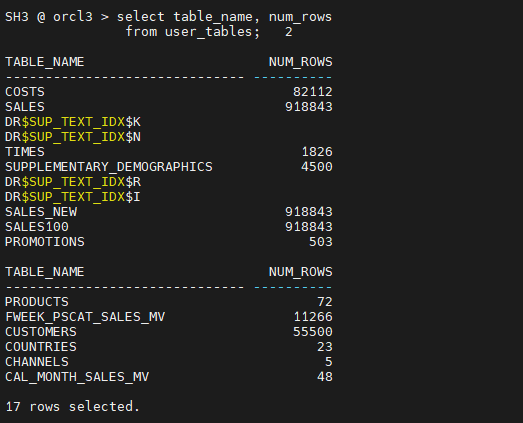
SH3 @ orcl3 > select table_name from user_tables; -- 17개 SH @ orcl2 > select table_name from user_tables; -- 19개
- orcl2, orcl3간의 hr 계정의 인덱스 갯수 확인
SH3 @ orcl3 > select index_name from user_indexes; 29 rows selected. SH @ orcl2 > select index_name from user_indexes; 29 rows selected.
- orcl2, orcl3간의 sh 계정의 제약 갯수 확인
SH3 @ orcl3 > select constraint_name from user_constraints; 154 rows selected. SH @ orcl2 > select constraint_name from user_constraints; 159 rows selected.
orcl3에 DIMENSION_EXCEPTIONS, SALES_TRANSACTIONS_EXT 가 없음select dbms_metadata.get_ddl('TABLE', table_name) || ';' from dba_tables where owner='SH'; select dbms_metadata.get_ddl('SALES_TRANSACTIONS_EXT', table_name) || ';' from dba_tables where owner='SH';아래 테이블 생성 스크립트를 SH3(orcl3)에서 진행
CREATE TABLE "SH3"."SALES_TRANSACTIONS_EXT" ( "PROD_ID" NUMBER, "CUST_ID" NUMBER, "TIME_ID" DATE, "CHANNEL_ID" NUMBER, "PROMO_ID" NUMBER, "QUANTITY_SOLD" NUMBER, "AMOUNT_SOLD" NUMBER(10,2), "UNIT_COST" NUMBER(10,2), "UNIT_PRICE" NUMBER(10,2) ) ORGANIZATION EXTERNAL ( TYPE ORACLE_LOADER DEFAULT DIRECTORY "ORCL3_DIR" ACCESS PARAMETERS ( RECORDS DELIMITED BY NEWLINE CHARACTERSET US7ASCII TERRITORY AMERICAN BADFILE log_file_dir:'ext_1v3.bad' LOGFILE log_file_dir:'ext_1v3.log' FIELDS TERMINATED BY "|" OPTIONALLY ENCLOSED BY '^' LDRTRIM ( PROD_ID , CUST_ID , TIME_ID DATE(10) "YYYY-MM-DD", CHANNEL_ID , PROMO_ID , QUANTITY_SOLD , AMOUNT_SOLD , UNIT_COST , UNIT_PRICE ) ) LOCATION ( 'sale1v3.dat' ) ) REJECT LIMIT 100 ; CREATE TABLE "SH3"."DIMENSION_EXCEPTIONS" ( "STATEMENT_ID" VARCHAR2(30), "OWNER" VARCHAR2(30) NOT NULL ENABLE, "TABLE_NAME" VARCHAR2(30) NOT NULL ENABLE, "DIMENSION_NAME" VARCHAR2(30) NOT NULL ENABLE, "RELATIONSHIP" VARCHAR2(11) NOT NULL ENABLE, "BAD_ROWID" ROWID NOT NULL ENABLE ) SEGMENT CREATION DEFERRED PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING TABLESPACE "USERS" ;