
✏️오늘의 TIL
- 인덱스가 생성되는 방식 2가지
- 인덱스의 구조를 위한 SQL튜닝 방법(ORDER BY절 대신 인덱스 이용)
- 유니크, 언유니크 인덱스
- 인덱스 생성
- 결합컬럼 인덱스
- 인덱스 생성 지침
- 인덱스 제거
- 동의어 (synonym)
- 데이터의 품질 높이기 1 (PRIMARY KEY)
[점심시간 문제]
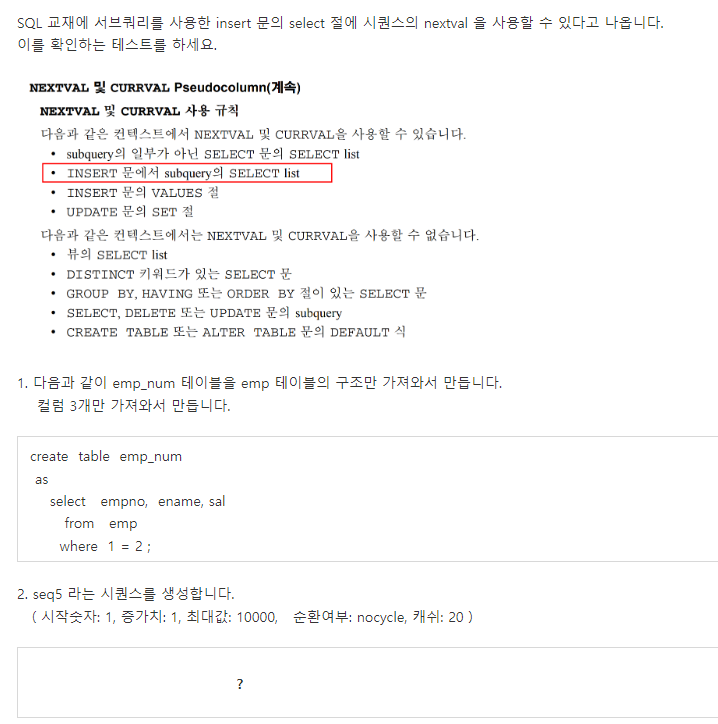

create sequence seq5
increment by 1
start with 1
0
j
nocycle
cache 20;
insert into emp_num
select seq5.nextval, ename, sal
from emp;
select * from emp_num;문제 581. c##scott 유저가 소유하고 있는 인덱스 리스트를 확인하시오
select *
from user_indexes;select index_name, table_name, uniqueness
from user_indexes
where index_name like 'EMP%';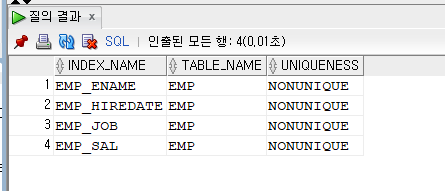
문제 582. 아래의 SQL을 튜닝하시오
튜닝 전
select ename, hiredate from emp where to_char(hiredate, 'RR/MM/DD') = '81/12/11;튜닝 후
select ename, hiredate from emp where hiredate = to_date('81/12/11', 'RR/MM/DD')✅ where 절에 인덱스 컬럼을 가공하면 인덱스를 사용할 수 없고, 풀테이블 스캔을 하게된다.
💡인덱스의 구조
1. 컬럼값 + rowid
2.
-> 오라클에서는 과도한 정렬작업을 수행하게 되면 성능이 느려집니다. 오라클이 정렬작업을 하려면 별도의 메모리에서 정렬작업을 수행합니다. 그 메모리 공간이 넉넉하지 않기때문에 과도한 정렬 작업이 들어오면 성능이 느려져서, 정렬 작업을 최소화할 수 있게 튜닝을 해야합니다.
이때, 이미 정렬이 되어있는 인덱스의 데이터를 이용합니다!
문제 583. 아래의 SQL울 튜닝하시오 (인덱스 구조를 이해하기 위한 문제)
튜닝 전
select ename, sal from emp order by sal asc;❗order by 절이 성능을 느리게 한다.
튜닝 후
select ename, sal from emp where sal >= 0;✅ 이미 인덱스는 데이터를 정렬해서 저장하고 있으므로, 인덱스에서 정렬된 데이터를 읽어오는게 더 성능이 좋습니다 !
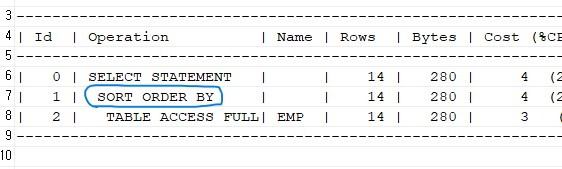
✍🏻 참고
1. 힌트 /*+ index_asc(테이블명 인덱스 이름) */ : 인덱스를 ascending하게 스캔
2. 힌트 /*+ index_desc(테이블명 인덱스 이름) */ : 인덱스를 descending하게 스캔
문제 584. 아래의 SQL을 튜닝
튜닝 전
select ename, job, sal from emp where job = 'SALESMAN' order by sal desc;튜닝 후
select /*+ index_desc(emp emp_sal) */ ename, job, sal from emp where sal > 0 and job = 'SALESMAN';
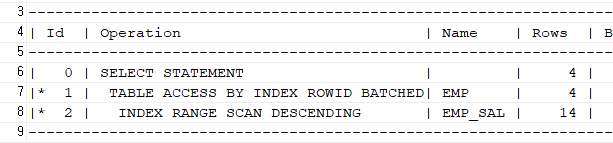
문제 585. 아래의 SQL을 튜닝
튜닝 전
select ename, hiredate from emp order by hiredate desc;튜닝 후
select /*+ index_desc(emp emp_hiredate) */ ename, hiredate from emp where hiredate < to_date('9999/99/99', 'RRRR/MM/DD');✅ 힌트를 썼다 하더라도, where절에 검색하는 키워드가 있어야한다. 힌트는 검색하는 방법을 알려주는 것 뿐 !
✍🏻 인덱스의 데이터를 스캔하기 위해 WHERE절에 해당 인덱스 컬럼이 있어야함. 아래는 인덱스의 데이터를 읽어오기 위한 조건들 !
1. 문자 > ' '
2. 숫자 >= 0
3. 날짜 < to_date('9999/99/99', 'RRRR/MM/DD');
인덱스의 구조를 위한 SQL튜닝 방법
✔️ WHERE절의 좌변을 가공하지 않기
✔️ ORDER BY절 대신에 인덱스 이용하기
인덱스가 생성되는 방식 2가지
- 수동으로
create index emp_deptno
on emp(deptno)- 자동으로 : primary제약이나 unique제약을 걸면, 제약은(contraint) 데이터의 품질을 높이기 위해 반드시 필요한 db 기능이다. primary key 제약을 생성한 컬럼은, 중복된 데이터와 null값이 입력되지 않는다.
✔️ emp테이블에 empno 에 primary key 제약을 생성합니다.
alter table emp
add constraint emp_empno_pk primary key(empno); // primary key 제약 생성
insert into emp(empno, ename, sal)
values(null, 'jane', 4000); // null값 넣어보기
insert into emp(empno, ename, sal)
values(7788, 'jack', 5000); // 중복된 데이터 넣어보기

✔️ emp테이블과 관련해서 생성된 인덱스를 확인해보기
select index_name, uniqueness
from user_indexes
where table_name = 'EMP';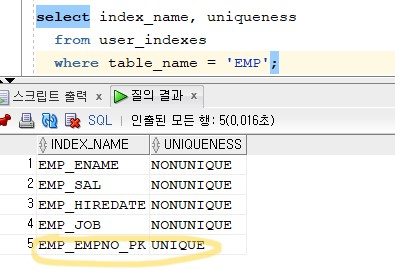
✅ 프라이머리 제약을 걸면, 유니크 인덱스가 자동으로 생성이된다.
EMP_EMPNO_PK UNIQUE <- 중복된 data가 없어야 걸리는 제약, 중복된 data가 없어야 생성되는 인덱스 !
✔️ 우리반 테이블의 ename에 unique제약을 거시오!
alter table emp17
add constraint emp17_ename_un unique(ename);✅ 우리반 학생들 이름중 중복된 data가 없어서 생성이 잘 되지만, 앞으로도 같은 이름의 학생이 없을때만 사용하면 된다.
✔️ 우리반 테이블에 ename에 인덱스가 있는지 확인하기
select index_name, uniqueness
from user_indexes
where table_name = 'EMP17';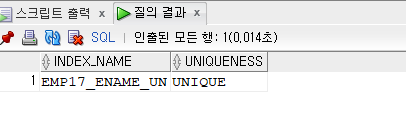
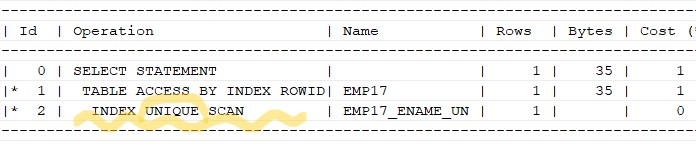
문제 586. 우리반 테이블에서 이름이 김동휘 학생의 이름과 나이, 주소를 출력하고 그 쿼리문의 실행계획을 확인하세요
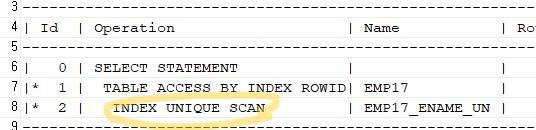
explain plan for select ename, age, address from emp17 where ename ='김동휘'; select * from table(dbms_xplan.display);✅ 유니크 인덱스는 이름의 중복된 데이터가 없음이 확실히 보장된 인덱스라서 김동휘 하나의 인덱스 행만 검색하고 바로 테이블 엑세스를 하러 가고 끝납니다. 그러나 non unique 인덱스이면 그 다음행인 김정명 행을 엑세스 합니다.
그래서 옵티마이져가 아래와 같은 SQL이 있고 2개의 인덱스가 있으면 유니크 인덱스를 더 선호합니다.
select ename, age, address from emp17 where age = 33 and ename = '김동휘' ↑ ↑ create index emp17_age alter table emp17 on emp17(age); add constraint emp17_un unique(ename); (nonunique) (unique)
문제 587. 내 자리 옵티마이져가 똑똑한 옵티마이져인지 확인해보기
create index emp17_age
on emp17(age)explain plan for select ename, age, address from emp17 where age = 33 and ename = '김동휘'; select * from table(dbms_xplan.display);
유니크 인덱스를 탔다 !
만약 emp17이 자주 바뀌는 테이블이라면 옵티마이저에게 최신정보를 자주 알려주어야 한다.
그렇지 않으면 옛날정보로 계속 할수가 있음
✅ 옵티마이저는 더 좋은 인덱스를 엑세스 하는데, 만약 덜 좋은 인덱스를 엑세스했다면 dba가 힌트를 줘서 튜닝해주면 된다.
문제 588. 아래의 SQL의 실행계획이 emp17_age인덱스를 엑세스 하도록 힌트를 주고 실행계획 확인 (nonunique를 타도록)
select ename, age, address
from emp17
where age = 33 and ename = '김동휘';select /*+ index(emp17 emp17_age) */ ename, age, address from emp17 where age = 33 and ename = '김동휘';여러개의 인덱스중에 특정 인덱스를 사용하게 하고 싶을 때 아래의 인덱스 힌트를 이용합니다.
/*+index(테이블명 인덱스이름)*/
✨ 정리
- 풀테이블스캔은 조건이 있어도 모든 데이터를 다 검색해서 조건을 찾는다.
- 위는 성능이 좋지않아서, 인덱스를 만들면 성능이 더 좋아진다.
- 인덱스중에서도 2개가 있다.
unique,nonunique nonunique- 특정값을 찾아도 그밑에 row하나를 더 검색한 후 멈춘다.
create index emp17_age
on emp17(age); 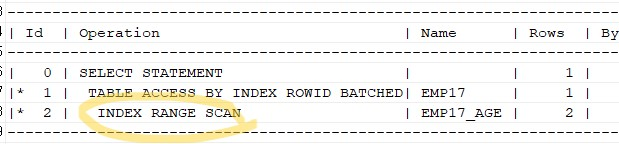
unique- 특정값을 찾으면 검색 멈춘다.
1. alter table emp17
add constraint emp17_un unique(ename);
or
2. create unique index emp17_age
on emp17(age); 유니크 인덱스는 두가지 방법으로 만들 수 있는데, 1번처럼 primary key를 생성하는 sql을 작성하면, 중복값과 null값 모두 못넣고 + nonunique 인덱스까지 생성이 된다.
인덱스 생성
✔️ 데이터 값이 유니크한지 유니크하지 않은지에 따라 2가지 !?
1. unique indexprimary key 제약 또는 unique제약을 걸었을 때 // 자동 or create unique index emp17_age on emp17(age); // 수동
2. nonunique indexcreate index emp17_age on emp17(age); // 수동
✔️ 인덱스를 구성하려는 컬럼의 갯수에 따라
1. 단일 컬럼 인덱스 : 인덱스를 구성하는 컬럼의 갯수가 1개
create index emp_sal
on emp(sal) // sal이라는 컬럼 하나2. 결합 컬럼 인덱스 : 인덱스를 구성하는 컬럼의 갯수가 2개 이상!
create index emp_job_sal
on emp(job,sal) // 컬럼이 job, sal로 두개!아래 만들어놓은 스크립트 실행하면 emp 테이블 drop되고 emp테이블과 연관된 인덱스들도 모두 drop된다.
@init_emp.sql
아무고토 안나옴!
결합컬럼 인덱스
예제. 아래의 결합 컬럼 인덱스를 생성하고 이 결합 컬럼 인덱스의 구조를 확인하기
create index emp_job_sal
on emp(job,sal);예제. 위 결합컬럼 인덱스의 구조를 확인하기
인덱스 구조는 1. 컬럼값 + rowid / 2. 컬럼값이 ascending하게 정렬되어있음
select job, sal, rowid
from emp
where job > ' ';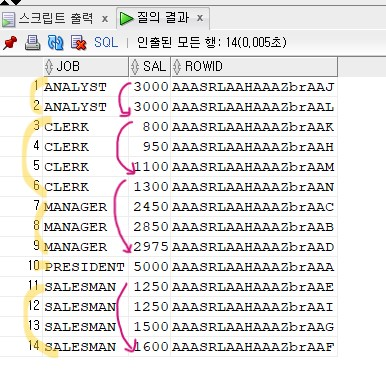
✅ job 별로 sal이 정렬되어 나오고있다.
결합컬럼 인덱스를 사용하는 이유
먼저, 문제를 풀기위해 위에 만들었던 인덱스를 드롭하고 초기화합니다.
drop index emp_job_sal;
@init_emp.sql;문제 589. emp테이블의 job 컬럼에 인덱스를 생성하기
create index emp_job on emp(job);
문제 590. 직업이 CLERK인 사원들의 직업, 월급 출력하는 쿼리문의 실행계획 확인하기
explain plan for select job, sal from emp where job = 'CLERK'; select * from table(dbms_xplan.display);
job은 인덱스를 사용해서 찾았는데 sal을 찾으려면 인덱스가 없으니까 table access를 해야한다. (밑줄친 작업이 있는 이유!) -> 이러한 것을 해결하기 위해 결합컬럼 인덱스를 사용한다.
✅ 위의 SQL의 실행계획은 JOB 에 대한 DATA 는 emp_job 에 있지만 select 절에서 요구하는 sal 에 대한 data 는 emp_job 에 없으므로 emp 테이블을 엑세스 하러 가야 하는 실행계획이 나왔다. 만약 인덱스에 sal 까지도 다 구성했으면 테이블 엑세스하러 갈 필요가 없었을 것
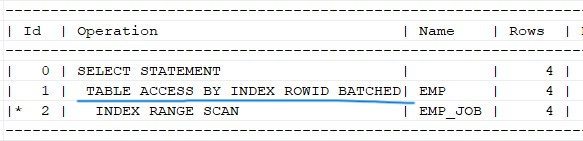
문제 591. emp 테이블에 job 과 sal 에 다음과 같이 결합 컬럼 인덱스를 생성하시오 !
create index emp_job_sal on emp(job, sal);
문제 592. 아래의 SQL의 실행계획을 다시 확인하시오 !
explain plan for select job, sal from emp where job = 'CLERK'; select * from table(dbms_xplan.display);emp_job_sal 결합 컬럼 인덱스에서 job 과 sal 에 대한 data를 다 얻어냈기 때문에 emp 테이블을 엑세스 하지 않는 실행계획이 나왔다.
select empno, ename, sal, job, deptno
from emp
where empno = 7788;
create index emp_idx7
on emp(empno, ename, sal, job, deptno); 문제 593. emp 테이블과 관련된 인덱스를 조회하시오 !
✅ sqldeveloper 에서 emp, index눌러서 보고 여러개 뜨면 결합인덱스!

문제 594. 아래의 SQL 튜닝하기
튜닝 전
slect ename, job, sal from emp where job = 'CLERK' order by sal desc;튜닝 후
select /*+ index_desc(emp emp_job_sal) */ ename, job, sal from emp where job = 'CLERK' and sal > 0; // 여기서 이거 안줘도 된다.지금 emp_job_sal 인덱스는 직업, 월급을 묶어서 만든거임 ! 그래서 where절에 sal > 0;을 안줘도 된다.
select /*+ index_desc(emp emp_job_sal) */ ename, job, sal from emp where job = 'CLERK' ;✅ 힌트도 줬고 , 검색조건도 잘 주어서
sal > 0;안해도 된다.
문제 595. deptno, sal을 결합한 결합컬럼 인덱스로 생성하기 (emp_deptno_sal)
create index emp_deptno_sal on emp(deptno,sal);
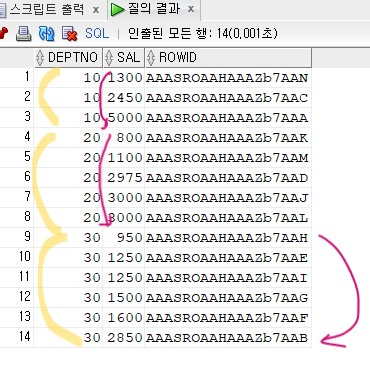
문제 596. emp_deptno_sal index의 구조를 확인하기
select deptno, sal, rowid from emp where deptno >= 0;
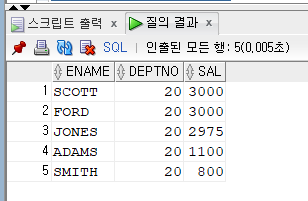
문제 597. 아래의 SQL 튜닝하기 (order by절 사용하지 않기)
select ename, deptno, sal
from emp
where deptno = 20
order by sal desc;튜닝 후
select /*+ index_desc(emp emp_deptno_sal) */ename, deptno, sal from emp where deptno = 20;
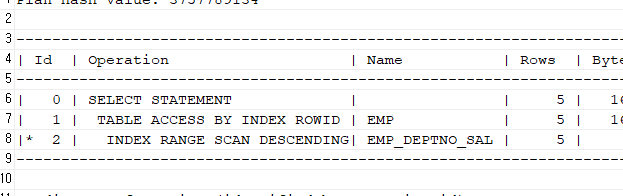
💡확인해보면 !select /*+ index_desc(emp emp_deptno_sal) */ename, deptno, sal from emp where deptno = 20 order by sal desc; select * from table(dbms_xplan.display);
- 위처럼 order by절을 실수로 썼다 하더라도 실행계획보면 order by절이 아예 실행이 안되는 것을 볼 수 있다.
인덱스 생성 지침
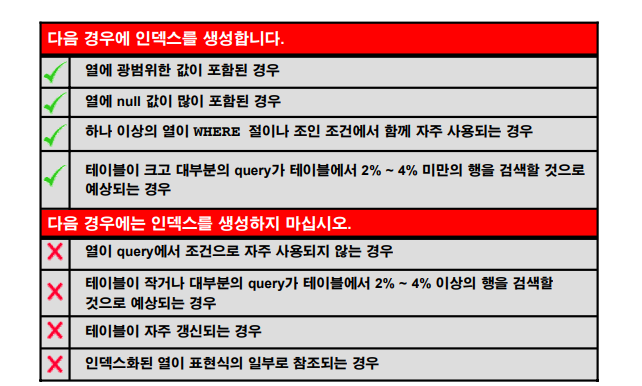
위 교재 조금 말이 애매해서 다시 정리하자면
⭕ 아래와 같은 경우 인덱스를 생성하세요
1. 테이블의 크기가 클 때
emp테이블 처럼 작은 테이블은 인덱스가 필요없다. 인덱스 없이도 검색속도가 빠름!
2. null값이 많은 컬럼에 인덱스를 걸면 좋다
인덱스 구성시 null값은 구성되지 않는다. 책에 빈페이지는 목차에 구성되지 않는다.
ex) 책을 보는데 목차가 없으면 안그래도 찾기 힘든것들을 빈페이지도 다 봐야한다. 근데 빈페이지는 목차를 만들어놓지 않으면 아예 거기는 찾아보지도 않고 원하는 정보를 찾을 수 있으니 null값이 많은 컬럼에 인덱스를 걸면 좋다.
3. where절에 자주 검색되는 컬럼에 인덱스를 걸어줘야 한다
select empno, ename, sal
from emp
where ename = 'SCOTT';
select empno, ename, sal
from emp
where ename = 'ALLEN'; ex) 이렇게 위처럼 ename을 자주 where절에 넣는데 인덱스를 뜬금없이 empno로 만들었다? -> 쓸데없는 인덱스를 만든 것!
4. 검색하려는 데이터의 행이 전체 테이블의 2-4% 미만인 컬럼에 인덱스를 건다
검색해야하는 목차가 거의 50%면 풀스캔하는거랑 다를바 없으니까..
❌ 다음의 경우 인덱스를 생성하지 마세요
1. where절에 자주 검색되지 않는 컬럼
2. 테이블이 작거나 검색하는 행이 테이블 전체의 2-4% 이상의 컬럼
3. 자주 갱신되는 컬럼 ⭐
ex) 테이블의 데이터를 변경하면 인덱스도 같이 변경해줘야 한다. 책의 내용을 변경하면 목차도 다시 변경하는데 책은 그냥 변경하면 간단하지만 목차는 ㄱ,ㄴ,ㄷ 순서이기 때문에 변경할 때 시간이 많이 걸린다. 인덱스가 있는 테이블에 insert , update를 하면 insert , update속도가 느려진다.
4. 인덱스화된 열이 컬럼에 표현식으로 사용되는 경우
= 가공되었을 때 → 가공되면 full table scan이 되니까 그냥 안하는게 낫다!
select ename, sal
from emp
where sal * 12 = 36000; // 표현식으로 사용되었다. 문제 598. (인덱스 생성하면 안되는 이유중 3번 관련한 실험문제) 인덱스가 생성되어있는 테이블과 생성되어있지 않은 테이블에 대량의 데이터를 insert 할 때 속도를 확인해보기
✔️ 다음 2개의 테이블을 생성해봅니다.
1. create table sales_no_index
as
select * from sales
where 1 = 2;
2. create table sales_with_index
as
select * from sales
where 1 = 2;✔️ 위 2개의 테이블 중에 sales_with_index 테이블에만 인덱스 생성합시다.
create index sales_index_1
on sales_with_index(amount_sold, promo_id);✔️ 아래와 같이 대량의 data를 2개 테이블에 각각 입력하고 속도를 비교해봅시다.
set timing on
insert into sales_no_index
select * from sales; 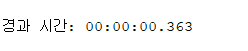
set timing on
insert into sales_with_index
select * from sales;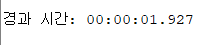
✅ index가 있는쪽의 테이블에서 insert 할때의 속도가 더 느리다 !!
(인덱스 있는 테이블의 DMA가 느림)
인덱스 제거
문법
drop index 인덱스명
문제 599. emp table에 관련된 인덱스가 무엇인지 조회하기
select index_name from user_indexes where table_name = 'EMP';
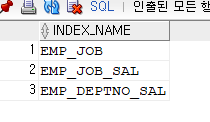
문제 600. emp 테이블과 관련된 모든 인덱스 삭제
drop index emp_job; drop index emp_job_sal; drop index emp_deptno_sal;✅ emp테이블 삭제하면 emp 테이블과 관련된 인덱스들도 모두 삭제된다 !
동의어

💡동의어란, 특정 개게에 대한 다른 이름이다!
ex) c##scott(dba)이라는 유저가 있는데 , 우리가 이 유저에서 emp, dept...를 만든다.
이 작업은 DBA가 하는것(현재 이 글에서 테이블을 만든 사람은 c##scott)
c##scott은 drop권한이 있다. 이 계정을 개발자들에게 주면 안된다.
c##smith (개발자) 들을 emp, dept 테이블에 대해 select, update, insert권한을 갖지만 delete나 drop권한을 주면 안된다 !
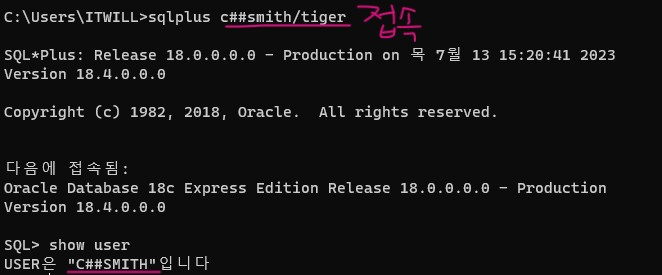
문제 601. c##scott유저에서 c##smith유저를 만들고, 접속할 수 있는 권한을 부여하고 c##smith 유저로 접속
create user c##smith // create user + 유저명 identified by tiger; // user 만들때 identified + password grant connect to c##smith; grant select on emp to c##smith;
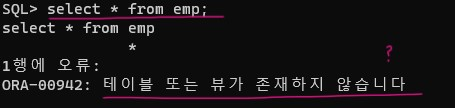
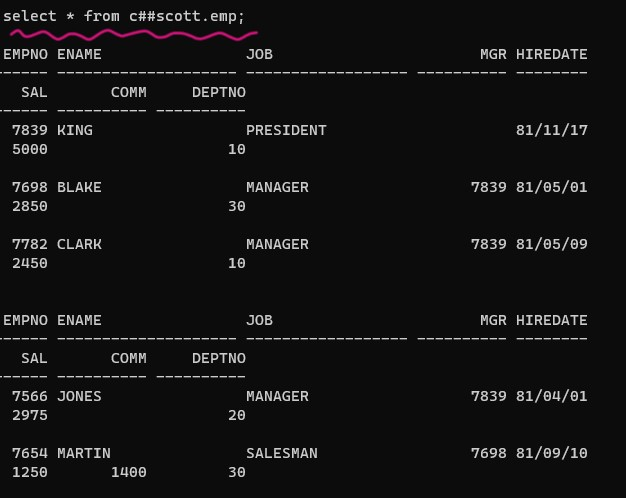
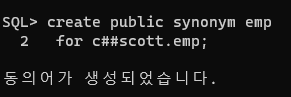
✅ 개발 dba가 emp 테이블을 생성했으면, 위와같이 synonym도 생성한다. synonym을 만들어야 c##scott 유저가 emp 테이블을 select 할 때 테이블명 앞에 c##scott을 접두어로 안붙여도 되기 때문 !!
문제 602. c##smith 유저가 다음과 같이 dept테이블과 salgrade테이블을 조회할 수 있게 하기
grant select on dept to c##smith; grant select on salgrade to c##smith;create public synonym salgrade for c##scott.salgrade create public synonym dept for c##scott.dept
문제 603. synonym을 생성하는데, employees를 e로 생성하기
create synonym e for employees;✅ c##scott만 사용할 시너님이면 public을 안써도 된다!
💡 개발 dba로 일할 때 synonym 생성 팁 !
hr 계정이 가지고 있는 모든 테이블들을 c##smith 유저가 select할 수 있게 하시오 !
-> 근데... 테이블이 300 개면 grant로 권한주고 시너님만들고... 이거 노동해야한ㄷㅏ...!!
그러면 어떻게 할까!?
예제1. hr 계정이 소유하고 있는 테이블 리스트를 확인하기
select table_name
from dba_tables
where owner = 'HR';
예제2. hr 계정의 7개의 테이블을 select할 수 있는 권한을 c##smith에게 부여하는 스크립트를 생성하기
select 'grant select on hr. '|| table_name ||' to c##smith; '
from dba_tables
where owner = 'HR';
예제3. 이번에는 public synonym을 생성하시오
select 'create public synonym '||table_name|| ' for hr.'|| table_name||';'
from dba_tables
where owner = 'HR';문제 604. employees 시너님을 삭제하시오 !
drop synonym e;
답은 2. False
데이터의 품질 높이기 1 (PRIMARY KEY)
제약(contraint) 은, 테이블에 data의 품질을 높이기 위해서 제한거는 기능!
ex) 데이터가 함부로 엉뚱한 데이터로 입력되지 않게하고, null값이나 중복된 data를 허용하지 못하게 막는 기능
✍🏻 제약의 종류 5가지
1.primary key: 중복된 data와 null을 허용하지 못하게 막는 제약
2.unique: 중복된 data를 허용하지 못하게 막는 제약
3.not null: null값을 허용하지 못하게 막는 제약
4.check: 지정된 data만 입력되고, 수정될 수 있도록 막는 제약
5.foreign key: 자식키에 해당하는 컬럼에 거는 제약
오늘의 마지막 문제를 풀기위한 환경을 만들기
1. 프롬프트창 열고 emp table 초기화 하기.
@init_emp.sql문제 605. 사원 테이블의 월급에 인덱스를 걸고 아래의 SQL의 MAX 함수를 사용하지 말고 결과를 출력하시오
(order by분만 아니라 max, min은 정렬작업이 내부적으로 발생하므로 max를 쓰지 말고 인덱스를 활용하게 해야한다.)
create index emp_sal on emp(sal);튜닝 전
select max(sal) from emp튜닝 후
select /*+ index_desc(emp emp_sal) */ sal from emp where sal >= 0 and rownum = 1;
문제 606. (마지막 문제)아래의 SQL을 튜닝하기!
튜닝 전 -
버퍼의 갯수 3개select /*+ gather_plan_statistics */ ename, sal from emp where sal = (select max(sal) from emp); SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));튜닝 후 -
버퍼의 갯수 2개select /*+ gather_plan_statistics index_desc(emp emp_sal) */ ename, sal from emp where sal >= 0 and rownum = 1; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
