
✏️ 오늘의 TIL
- Group by 절을 포함하는 복합뷰는 insert 와 delete 가 안된다.
- View 생성할 때 쓰는 구문 옵션
- view 제거
- 절대로 중복되지 않는 번호 만들기 (SEQUENCE)
- NEXTVAL 및 CURRVAL
- 데이터 검색 속도를 높이기(INDEX)
- SQL 튜닝방법 첫번째 (WHERE절 좌변 가공X)
[7월 12일 점심시간 문제]
부서번호, 부서번호별 평균월급을 출력하는 view를 생성하세요.
view 이름은 dept_avg 로 생성하세요.
create or replace view dept_avg
as
select deptno, round(avg(sal)) as 평균월급
from emp
group by deptno;
select * from dept_avg;✅ 뷰 만드는 문법 다음 select 절에 그룹함수를 쓸 때는 컬럼별칭을 함께 써줘야한다!!
복습(VIEW)
view 를 사용하는 이유?
- 보안상의 이유 (민감한 데이터를 노출하지 않기위해)
- 복잡한 쿼리문을 단순하게 쿼리하기 위해서
view 의 옵션 2가지
- with read only : DML 작업이 아예 안되게 막는 옵션
- with check option : 특정 조건의 행에 데이터를 갱신하지 못하게 막는 옵션
※ view 는 데이터를 저장하지 않고 그냥 테이블을 바라보는 쿼리문이다.
근데 view 에서 바꾸면 기본 테이블에서도 바뀐다.
SQLD 기출 문제
문제. (단답형) 다른 테이블에서 파생된 테이블로, 물리적 데이터가 저장되는 것이 아닌 논리적으로 존재하는것을 무엇이라고 하는가?
답. view
(근데 테이블은 아님!!)

풀어보기!
🟥 참고사항
✔️ group 함수와 group by 절을 써서 만든 복합뷰는 아예 DML이 안된다.
✔️ 조인을 해서 만든 view 는 1쪽 테이블 (더 적은 테이블) 은 수정이 안되는데,
M쪽 테이블 (더 많은 테이블:emp) 은 수정이 된다.
대신 dept 테이블 deptno 에 primary key 제약이 걸려있어서 중복된 부서번호가 없다는 것이 보장이 되어야 수정이 가능하다. (SQLP 객관식, 성능고도화책) ★★★★★
(나중에 다시 복습해보기)
문제 552.
직업, 직업별 토탈월급을 출력하는 view 를 생성하시오 (이름 : job_sumsal)create or replace view job_sumsal as select job, sum(sal) as sumsal from emp group by job;
view 의 insert
문제 553. 위의 뷰 job_sumsal 에 아래의 데이터를 입력하시오
job : enginner sumsal : 5600insert into job_sumsal(job, sumsal) values('engineer',5600);오류
insert into job_sumsal select job, sum(sal) from emp group by job;또 오류
SQL 오류: ORA-01733: 가상 열은 사용할 수 없습니다
즉, inserting one or more rows using a view whose defining query contains a GROUP BY clause will cause an error 는 맞는말이다.▽
OCP 시험문제 에서 보기 E 내용임!

문제 554. job_sumsal 뷰의 데이터에서 job 이 SALESMAN 인 데이터를 지우시오
delete from job_sumsal where job='SALESMAN';SQL 오류: ORA-01732: 뷰에 대한 데이터 조작이 부적합합니다
보기 F도 정답임~
✔️ Group by 절을 포함하는 복합뷰는 insert 와 delete 가 안된다!!
그렇다면 단순뷰는?
문제 555. 아래의 단순뷰를 생성하시오 -> 테이블의 갯수가 한개인..!
create or replace view emp98 as select * from emp where job !='ANALYST';
문제 556. emp98 뷰에 이름이 KING 인 사원을 지우시오 (복합뷰는 안지워졌었음)
delete from emp98 where ename = 'KING';☆ 단순뷰에서는 지워진다! 실제 EMP 테이블에서도 지워졌다.
✔️ 뷰의 데이터를 지우면 실제 뷰 관련 테이블의 데이터를 지우는 것이다!! 잊지말깅
문제 557. emp98 뷰에 아래의 데이터를 입력하시오
사원번호 : 3845 사원이름 : JANE 월급 : 4000 부서번호 : 20insert into emp98 (empno, ename, sal, deptno) values (3845, 'JANE', 4000, 20 );데이터가 생겼다 (insert 성공)
✔️ 뷰에 데이터를 입력하면 뷰와 관련된 테이블에 데이터가 입력된다!! (지우는거, 입력하는거 마찬가지)
✔️ 테이블에 대해서 select, update, delete 에 권한을 주었으면
테이블에 관련된 view 에 대해서는 select, update, delete 권한을 따로 주지 않아도 가능하다.
c##scott c##king
emp테이블
grant select on emp to c##king; -> update emp98
grant update on emp to c##king; set sal=0
grant delete on emp to c##king; where ename=ALLEN';
(EMP 테이블에 대한 권한부여) (EMP98 뷰 도 업데이트 가능)
문제 558. 아래의 보기가 맞는지 틀린지 테스트 하시오
B. Tables in the defining query of a view must always exist in order to create the view (뷰를 만들기위해서는 테이블이 항상 존재해야한다)create view dept_view2 as select * from dept900;ORA-00942: 테이블 또는 뷰가 존재하지 않습니다
-> create force view dept_view2 as select * from dept900;force 옵션 사용하면 테이블이 없어도 view 를 생성할 수 있다. (밑에 옵션 설명 참고)
디폴트는 noforce 임!
View 생성할 때 쓰는 구문 옵션 (오라클 정교재)
: CREATE VIEW 문에 subquery를 포함하여 뷰를 생성할 수 있습니다.
구문 설명:
★ OR REPLACE 뷰가 이미 있는 경우 다시 생성합니다.
★ FORCE 기본 테이블의 존재 여부에 관계없이 뷰를 생성합니다. (위에 문제 증명에 사용된 것)
★ NOFORCE 기본 테이블이 있는 경우에만 뷰를 생성합니다 (기본값 디폴트)
-> force, noforce : 매번 사용하는것은 아님!! 그냥 알고만 있으면 됨.
view 뷰의 이름입니다.
alias 뷰의 query에서 선택한 표현식의 이름을 지정합니다(alias의 수와 뷰에서 선택한 표현식의 수가 일치해야 함).
subquery 완전한 SELECT 문입니다 (SELECT list에서 열의 alias 사용 가능).
WITH CHECK OPTION 뷰에서 액세스할 수 있는 행만 삽입하거나 갱신할 수 있도록 지정합니다.
constraint CHECK OPTION 제약 조건에 할당되는 이름입니다.
WITH READ ONLY 현재 뷰에서 DML 작업을 수행하지 못하도록 합니다.
view 제거
✔️ 뷰는 데이터베이스의 기본 테이블을 기반으로 하기 때문에 뷰를 제거해도 관련된 테이블이 삭제되는 것은 아니다.
✔️ 문법: drop view emp98; -> emp 테이블 그대로 있음
✔️ 그러나 이 뷰를 가지고 만든 procedure 는 무효화 된다.
✔️ 생성자나 DROP ANY VIEW 권한을 가진 유저만 뷰를 제거할 수 있습니다.
문제 559.
내가 가지고 있는 db의 권한이 무엇인지 확인하시오select * from session_privs;100개 이상 권한을 가지고 있다. DBA 권한을 받았기 때문에 이렇게 많은것
문제 560.
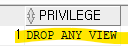
session_privs 에서 DROP_ANY_VIEW 가 있는지 확인하시오select * from session_privs where privilege ='DROP ANY VIEW';
있다! 그래서 뷰를 드롭 할 수 있다!
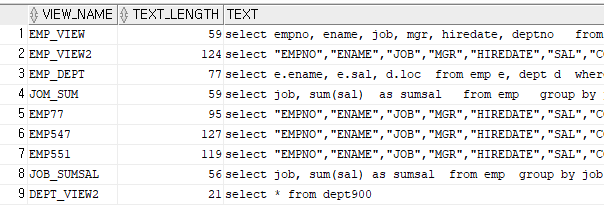
문제 561. 내가 생성한 VIEW 가 뭐가 있는지 확인하시오
select * from user_views;그동안 만들었던 view확인 가능
TEXT 부분이 view 만들때 만든 쿼리문임
문제 562.
가지고있는 view 중에 job_sumsal 뷰를 삭제하시오drop view job_sumsal; (drop view view이름)
VIEW 끝~
책이랑 목차 다르게 인덱스 전에 시퀀스 먼저 하신다구 함
절대로 중복되지 않는 번호 만들기 (SEQUENCE)
: 일련 번호 생성기 (순서대로 번호를 생성하는 DB object)
ex) 쿠팡의 주문 테이블이 있다면 주문번호는 순서대로 부여된다.
은행의 번호표 기계.. 기계가 없이 사람이 일일히 번호를 적어서 나눠준다면 오차가 발생할 것이다.
이런것들이 db에서도 마찬가지다.
✔️ sequence 를 사용하지않고 하드코딩하여 사용하면 실수가 발생할 수 있다.
하지만 오라클의 시퀀스를 생성하면 번호가 순서대로 잘 생성이 된다!
🟥 SEQUENCE
• 고유 번호를 자동으로 생성할 수 있습니다.
• 공유할 수 있는 객체입니다.
• Primary key 값을 생성하는 데 사용할 수 있습니다.
• 응용 프로그램 코드를 대체합니다. (밑의 예시 참고)
• 시퀀스 값이 메모리에서 캐시된 경우 액세스 속도가 향상됩니다.
시퀀스의 응용 프로그램 코드 대체
insert into 주문테이블 (주문번호, 주문상품, 배송지)
values (시퀀스이름.nextval, '노트북' , '서울시');-> 이상적인 시퀀스 활용 insert 문
select max(주문번호) +1 into :v_order -> :v_order 는 변수(빈 컵 상태)
from 주문테이블
insert into 주문테이블 (주문번호, 주문상품, 배송지)
values (:v_order, '노트북' , '서울시'); -> 개선해야 할 개발환경의 insert 문 (요런게 위에 말한 응용프로그램코드)
대용량이 되면 위의 select 문이 느려진다.
max(주문번호) +1 로 번호를 생성하지말고 시퀀스를 사용해서 번호를 생성하길 권장한다.
CREATE SEQUENCE 문: 구문

🟥 구문 설명:
sequence 시퀀스 생성기의 이름입니다.
INCREMENT BY n 시퀀스 번호 사이의 간격을 지정하며, 여기서 n은 정수입 니다(이 절을 생략하면 시퀀스는 1씩 증가함)
START WITH n 생성할 첫번째 시퀀스 번호를 지정합니다(이 절을 생략하면 시퀀스는 1부터 시작함).
MAXVALUE n 시퀀스가 생성할 수 있는 최대값을 지정합니다.
NOMAXVALUE 오름차순 시퀀스의 경우 최대값 10^27을, 내림차순 시퀀스의 경우 –1을 지정합니다(기본 옵션).
MINVALUE n 최소 시퀀스 값을 지정합니다.
NOMINVALUE 오름차순 시퀀스의 경우 최소값 1을, 내림차순 시퀀스의 경우 –(10^26)을 지정합니다(기본 옵션)
CYCLE | NOCYCLE 최대값이나 최소값에 도달한 후에 시퀀스를 계속 생성할지 여부를 지정합니다(NOCYCLE이 기본 옵션임).
CACHE n | NOCACHE Oracle 서버가 메모리에 미리 할당하고 저장하는 값의 개수를 지정합니다(Oracle 서버는 기본적으로 20개의 값을 캐시함).
예제.
1. 시퀀스 생성하기create sequence seq1 increment by 1 -> 증가치 start with 1 -> 시작숫자 maxvalue 100 -> 최대값 nocycle -> 순환여부 cache 20; -> 미리 메모리에 올려놓을 번호의 갯수 (성능을 위해)
주문 테이블을 생선합니다.
create table cuppang_order ( order_num numver(10), order_name varchar2(20), address varchar2(30) );cuppang_order 테이블에 데이터를 입력합니다.
insert into cuppang_order values ( seq1.nextval, '노트북', '서울시 송파구' ); insert into cuppang_order values ( seq1.nextval, '무선 마우스', '서울시 강남구' ); select * from cuppang_order;100번 넘게 입력하면,
오류가 발생한다!
이 오류가 나기전에 DBA 는 지금 현재 몇번까지 번호가 생성되었는지 확인을 하고,
maxvalue 에 도달할 것 같으면, maxvalue 값을 늘려주어야한다. (DBA 역할)

NEXTVAL 및 CURRVAL Pseudocolumn
문제 563.
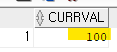
현재 seq1 의 현재 시퀀스 값을 확인하시오select seq1.currval from dual;
100번까지 찬 것을 확인 할 수 있다.
문데 564.
seq1 의 설정값이 어떻게 되어 있는지 확인 하시오select * from user_sequences;
max_value 가 100이라는 것을 확인할 수 있다.

문제 565.
seq1 의 maxvalue 값을 200으로 늘리시오alter sequence seq1 maxvalue 200;
200으로 늘어났다!

✔️ dba가 관리해야 하는 일 중에서 시퀀스 maxvalue 값에 도달해서 에러나지 않게끔해야하는 일을 꼭 챙겨야한다.
문제 566. seq2 시퀀스를 생성하는데, 시작값은 1로하고 최대값은 100000, cycle로 하고 cache는 20으로 주어 시퀀스를 생성하시오
create sequence seq2 increment by 1 start with 1 maxvalue 100000 cycle cache 20;잘 만들어졌는지 확인하기!
select * from user_sequences;

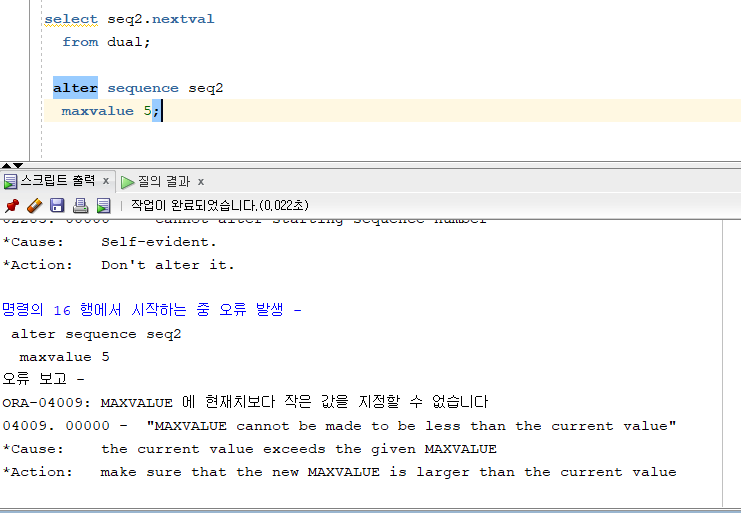
문제 567. 문제 seq2 시퀀스의 시작값을 1이 아닌 5로 변경하시오!
alter sequence seq2 start with 5;
✔️ 시퀀스의 시작값은 수정할 수 없다 !! 나머지는 모두 가능
*무슨말?

문제 568. seq1 시퀀스 drop하기
drop sequence seq1✔️ 시퀀스fmf drop했어도 이미 생성한 번호들은 그대로 잘 테이블에 입력되어 있다.
💡 시퀀스 관련해서 dba가 반드시 알아야할 tip !
-> 시퀀스 파라미터 중에 cache 파라미터를 사용할 때 주의할 사항
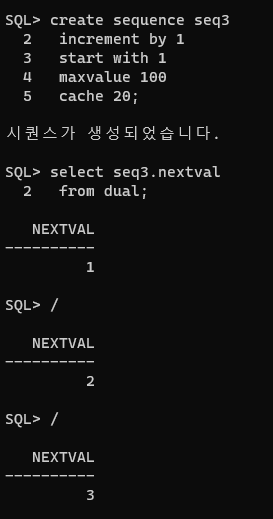
create sequence seq3
increment by 1
start with 1
maxvalue 100
cache 20;seq3 는 은행 번호표 기계라고 생각해보자. cache는 미리 번호표를 뽑아놓은 상태. 그걸 사람들이 몰렸을 때 바로바로 가져갈 수 있는 것! 메모리가 넉넉해야 cache줄 수 있다.
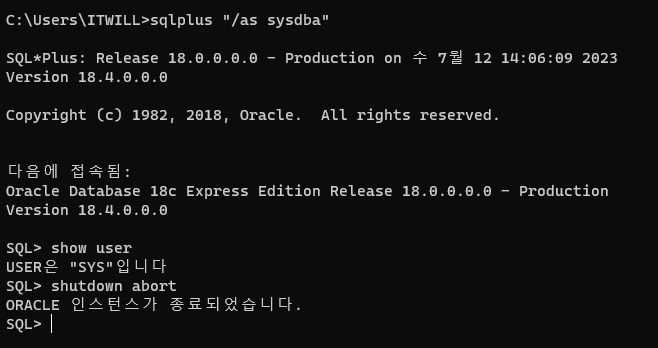
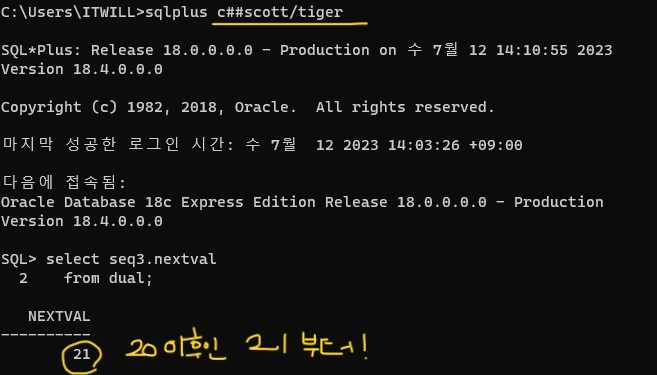
❗시퀀스 번호를 1번, 2번 생성한 후에 db가 비정상 종료 되었다가 다시 startup이 되면 시퀀스 번호를 3번이 아니라 21번이 된다!!! (아래 실험 참고)
왜냐하면, 메모리에 올렸던 번호들이 다 사라져버렸기 때문. 그래서 번호의 순서가 순차적으로 시퀀스를 통해 테이블에 입력되어야 한다면 이부분을 신경써야 한다. 이럴경우 시퀀스를 삭제하고 다시 시작숫자 맞춰서 생성해야한다. nocache로 생성하면 이런 위험은 없지만, 성능을 위해 nocache로 만들지 말자

문제 569. 시퀀스 ocp시험문제 환경 셋팅
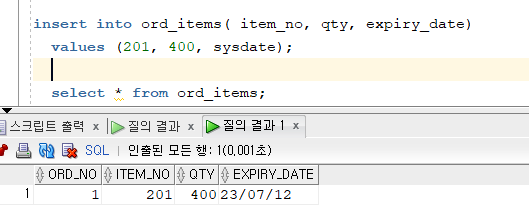
CREATE SEQUENCE ord_seq INCREMENT BY 1 // 증가치 START WITH 1 // 시작 숫자 MAXVALUE 100000 // 최대값 CYCLE // 순환한다. (1번부터 10만번까지 나온 후, 다시 1부터 나온다.) CACHE 5000; // 최대 10만개중 오라클 메모리(인스턴스)에 1번부터 5000까지 올려놓겠다. 5000까지 다 쓰면 5001부터 5000개까지 다시 뽑아놓는다. CREATE TABLE ord_items ( ord_no NUMBER(4) DEFAULT ord_seq.NEXTVAL NOT NULL, // ord_no에 널값넣으면 시퀀스값으로 들어가게 하겠다 item_no NUMBER(3), qty NUMBER(3), expiry_date DATE, CONSTRAINT it_pk PRIMARY KEY (ord_no, item_no));
ord_no NUMBER(4) DEFAULT ord_seq.NEXTVAL NOT NULL부분 확인해보기!insert into ord_items( item_no, qty, expiry_date) values (201, 400, sysdate);
- 위는 암시적 null을 넣은 것.
❗ primary key 제약이 걸려있으면 null 값을 입력할 수 없다. 그런데 위처럼 암시적으로 null을 입력하면, default값이 입력된다. 디폴트로DEFAULT ord_seq.NEXTVAL NOT NULL이 시퀀스를 지정했기때문에 시퀀스값이 입력된다!!- 싸이클 쓸 때
minvalue값을 신경써야한다. 기본값은 1이긴한데, 만약minvalue가 -100 이면 맥스값에 도달했을때 다시 1로 시작하는게 아니라 -100으로 시작한다. -100, -99, -98.....
❗ 시퀀스 생성시 cycle 옵션을 줬으면maxvlaue값까지 다 출력된 다음 다시 시작하는 숫자가startwith값이 아니라,minvalue값 부터 시작한다.
그래서, cycle을 썼으면 START WITH, MINVALUE의 값을 동일하게 맞춰줘야 한다.
문제 570.
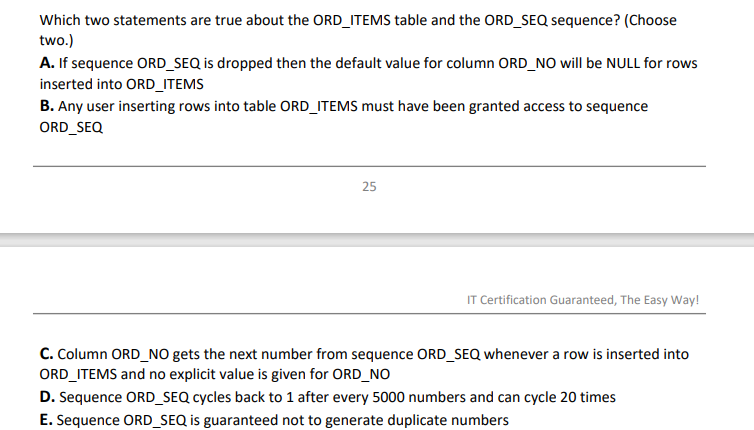
A: 시퀀스 지워도 널로 안바뀐다.
B: 맞다
C: 암시적으로 넣었을때는 시퀀스 값이 들어가니까 정답
D: 5000은 메모리에 미리 뽑은거고 MAXVALUE가 10만이니까 1부터 시작하려면 10만까지 돌아야한다.
E: 시퀀스가 중복되지 않는 번호가 발생할거라고 보장할 것이다. ? -> cycle로 만들었으니, 1번부터 10만까지 나오면 다시 1로 생성된다!! 중복된다.
nocycle로 만들어야 절대 중복되지 않는다.
데이터 검색 속도를 높이기(INDEX)
인덱스란? 쿼리문의 검색속도를 높이는 db object !
✔️ 풀스캔을 하지 않고 약간목차 찾아서 가는 느낌
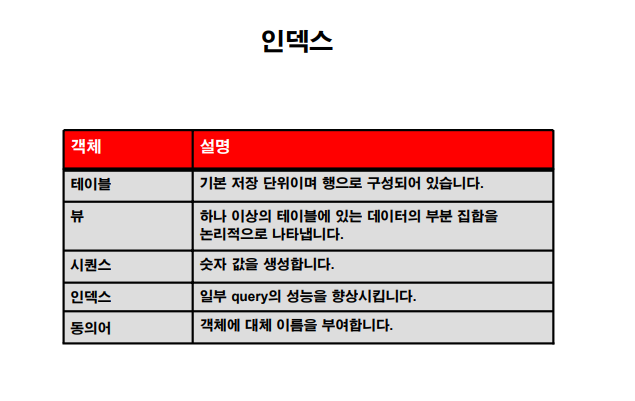
🟥 인덱스
• 스키마 객체입니다.
• Oracle 서버에서 포인터를 사용하여 행 검색 속도를 높이는데 사용할 수 있습니다.
• 신속한 경로 액세스 방식을 사용하여 데이터를 빠르게 찾아 디스크 I/O(입/출력)를 줄일 수 있습니다.
• 인덱스의 대상인 테이블에 독립적입니다.
• Oracle 서버에서 자동으로 사용되고 유지 관리됩니다. (챕터의 제목 바꾸면 목차에서도 그 챕터의 제목을 수정해야하는데 오라클은 자동으로 해준다!)
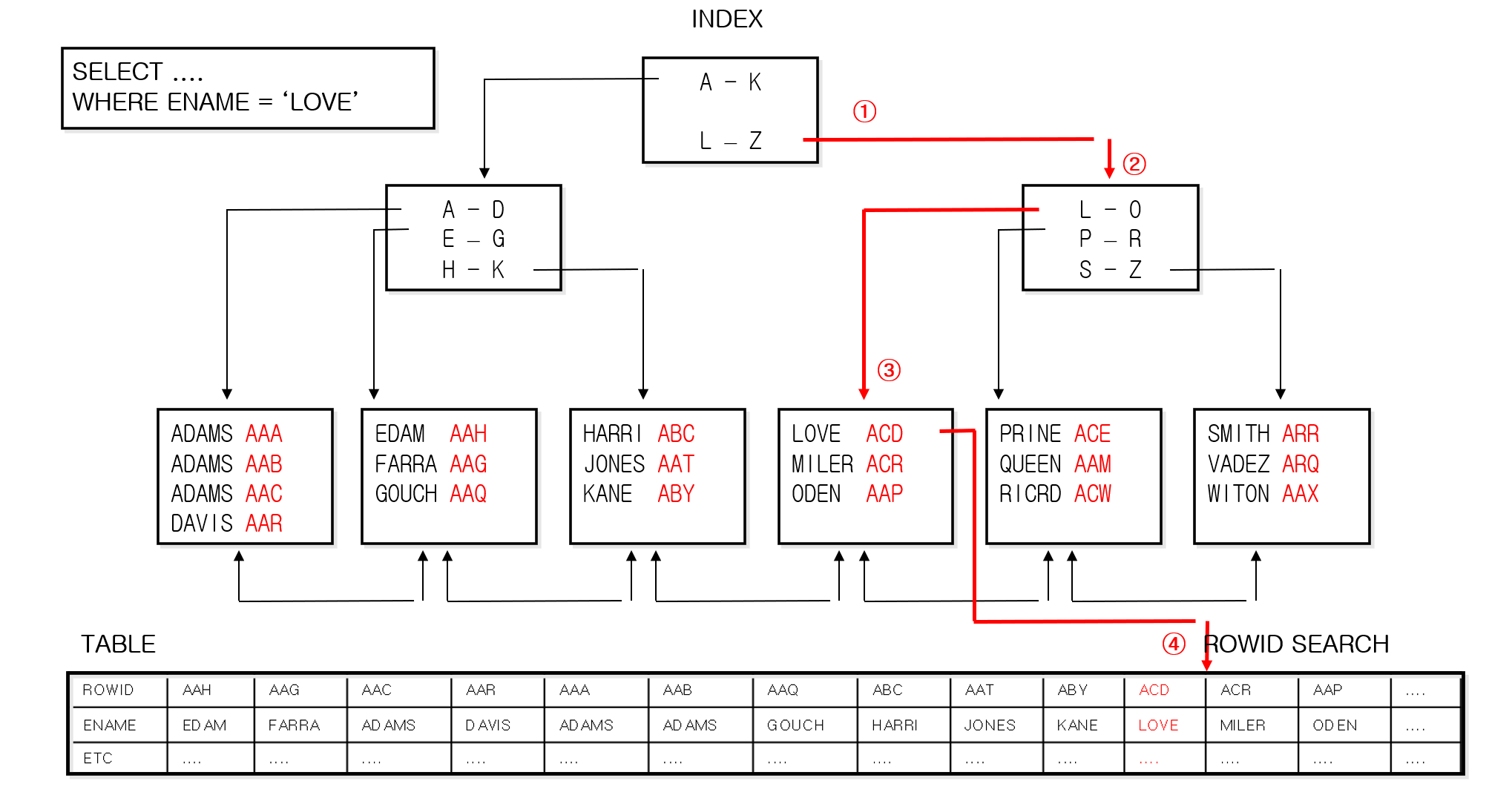
<인덱스 구조>
✔️ 빨간 글씨는row_id라고 하는데 이것은 목차의 페이지번호와 같다.
✔️ 인덱스의 구조 :컬럼값 + rowid (행의 주소)이고,컬럼값이 acending하게 정렬되어있다.
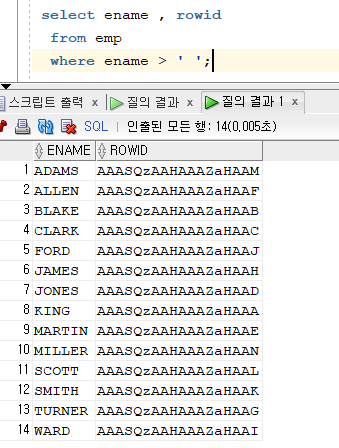
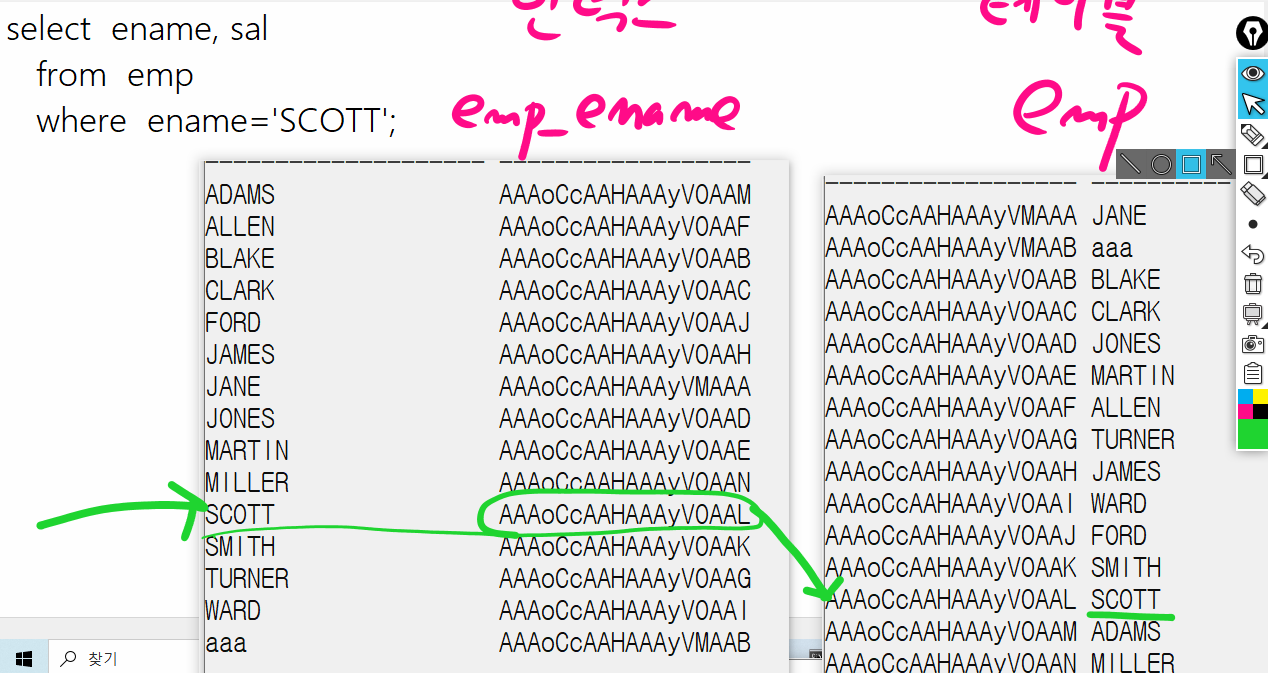
✔️ 인덱스 문법 (이름에 인덱스 만들기)create index emp_ename on emp(ename);✔️ ename의 인덱스만 보는 쿼리문
select ename , rowid from emp where ename > ' ';
- order by절을 쓰지 않았지만 이름이 A-Z순서로 정렬되어 출력된다!!!
✔️ 위 SQL결과가 테이블에서 읽어온 데이터가 아니라, EMP_ENAME이라는 인덱스에서 읽어온 데이터임을 확인해보자explain plan for select ename , rowid from emp where ename > ' '; select * from table(dbms_xplan.display);

문제 570. emp 테이블의 sal에 인덱스를 생성하는데 인덱스 이름은 emp_sal!
create index emp_sal on emp(sal);
문제 571. emp_sal 인덱스의 구조를 확인하세요
select sal , rowid from emp
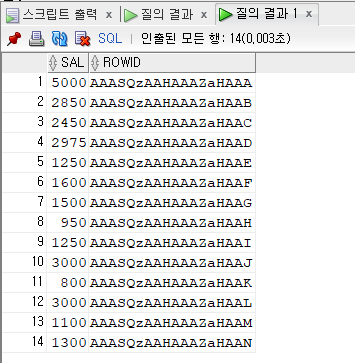
위처럼만 쓰면 table에서 가져온거다. 정렬이상함!! where 절을 꼭 써주기!!
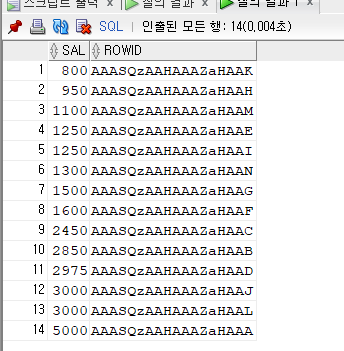
select sal , rowid from emp where sal >= 0;
- 오름차순으로 잘 나오는것을 확인할 수 있다.
문제 572. emp테이블에 hiredate에 인덱스 생성하세요
create index emp_hiredate on emp(hiredate); select hiredate , rowid from emp where hiredate < to_date('9999/12/31' , 'RRRR-MM-DD');✔️
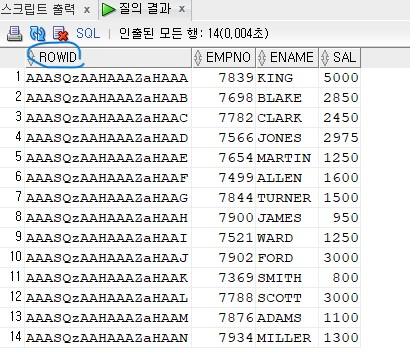
rowid는 로우의 주소인데 인덱스에도 있고 테이블에도 있다.select rowid, empno, ename, sal from emp;
문제 574. 이름이 SCOTT인 사원의 이름, 월급을 출력
select ename, sal from emp where ename = 'SCOTT';아까 우리가 ename에 인덱스를 생성해놓았어서 찾는방법이 하나가 더 추가되었다!
(SCOTT data찾는방법 총 두개!)
1.full table scan: SCOTT data를 찾기 위해서 테이블을 처음부터 끝까지 모두 스캔
2.index range scan: SCOTT data를 찾기 위해서 목차(index)를 통해 테이블을 엑세스
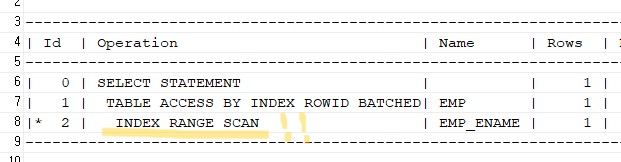
문제 575. 여러분들의 옵티마이저는 아래의 SQL을 실행할 때 full table scan을 했는지 index range scan을 했는지 실행계획 확인해보기
explain plan for select ename, sal from emp where ename = 'SCOTT'; select * from table(dbms_xplan.display);
✅ index range scan을 해서 'SCOTT'을 찾았다.
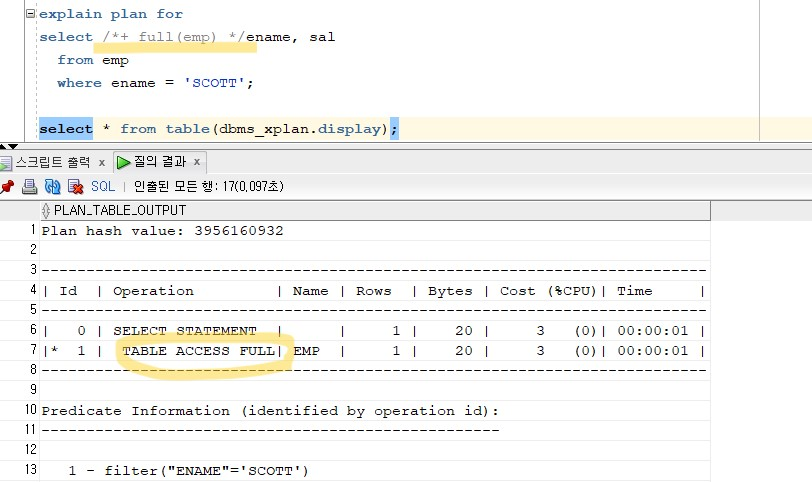
문제 576. 아래의 SQL의 실행계획이 full table scan이 되게 하시오!
explain plan for select /*+ full(emp) */ename, sal from emp where ename = 'SCOTT'; select * from table(dbms_xplan.display);
/*+ full(emp) */는 힌트라고 하는데, 옵티마이저를 제어하고 싶을 때 많이 사용한다.
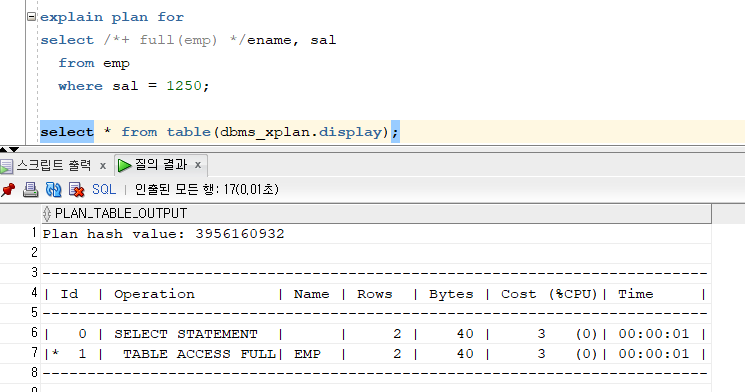
문제 577. 월급이 1250인 사원의 이름, 월급을 출력하는 쿼리문을 작성하는데 full table scan이 되게 하시오!
select /*+ full(emp) */ename, sal from emp where sal = 1250;
문제 578. 위 SQL이 emp_sal 인덱스를 통해서 테이블을 엑세스 할 수 있도록 힌트 주기
select /*+ index(emp emp_sal) */ ename, sal from emp where sal = 1250;
/*+ index(테이블명 인덱스이름) */
✅ 만약 인덱스가 있는데도 불구하고 fullscan을 한다면, 이렇게 힌트를 줘서 실행시키기!
그렇지만 합리적인 힌트를 주어야한다. 만약 인덱스 없는데 인덱스 쓰라고 하면 안됨
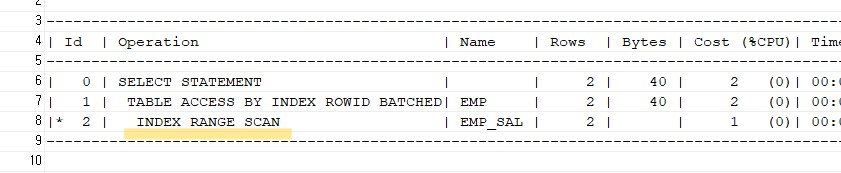
SQL 튜닝방법 첫번째
1. WHERE절에 좌변을 가공하지 말기!
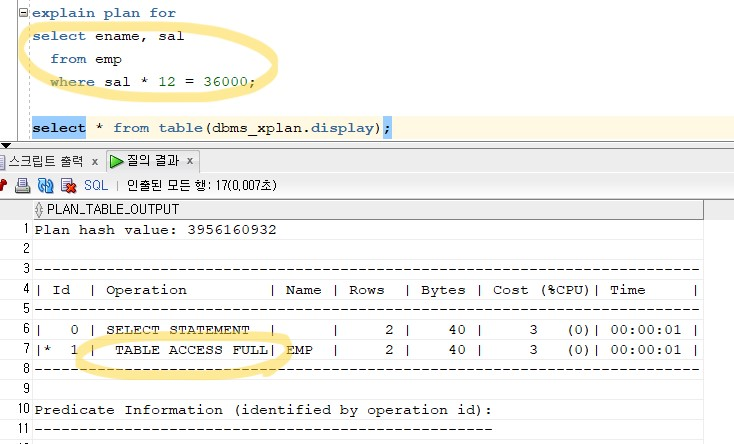
튜닝 전select ename, sal from emp where sal * 12 = 36000;
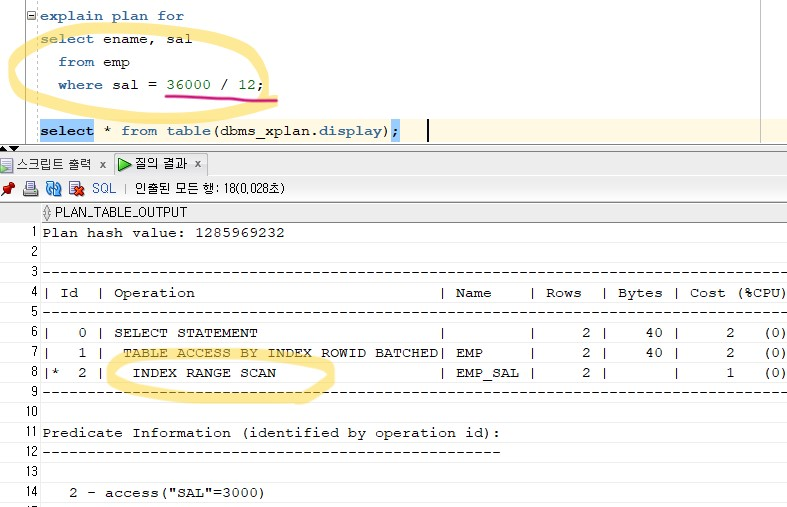
튜닝 후-> 좌변에 * 12를 우변 /12 로 넘김select ename, sal from emp where sal = 36000 / 12;
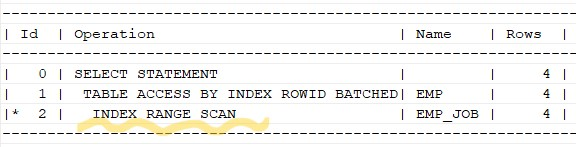
문제 579. 사원 테이블에 job에 인덱스 생성 (인덱스 이름은 emp_job)
create index emp_job on emp(job);
문제 580. 아래의 SQL을 튜닝하세요!
튜닝 전select ename, sal, job from emp where substr(job, 1, 5) = 'SALES';
튜닝 후select ename, sal, job from emp where job like 'SALES%';
💡참고 !
지금 데이터 포맷이 RR/DD/MM로 나오는데 이게 RRRR/DD/MM으로 출력되게 하고싶다면 아래처럼! (현재 세션에서만 변경된다)
alter session set nls_date_format='RRRR/MM/DD';