
복습
- rac 소개
- rac 관리
- rac 튜닝
- instance recovery 튜닝
- interconnect traffic 튜닝
- 글로벌 경합에 대한 튜닝
gc buffer busy
- cache fusion 메커니즘 6가지
- rac 환경에서 대기 이벤트
- gc buffer busy
- SQ enqueue
- HW enqueue
- RAC 성능 튜닝 tip !
✏️ 4. rac 성능 튜닝 tip !
(p 6-21)
(특별히 rac 환경에서 성능을 위해 고려할사항 ? )
- SQL 튜닝이 가장 중요하다
- buffer cache 의 크기를 늘린다.
- 높은 레벨의 락 사용을 줄인다.
ex) lock table emp in exclusive mode;
- 자동 세그먼트 저장관리 기법을 사용한다. (HW enqueue 가 줄어든다.)
➡️ 이미 디폴트이다. 오라클이 자동을 관리한다는 것은, pct free 같은 블럭 관련 파라미터들의 설정값을 오라클이 알아서 하겠다!
- 파티션 테이블을 생성한다. (파티션 와이즈 조인을 하기 때문에 인스턴스간의 통신을 줄일수 있다. 파티션끼리 조인하는것!)
- 불필요한 구문해석(parsing) 을 줄인다.
리터럴 SQL -> Bind variable 로 변경해서 PL/SQL 프로그래밍 하기 ➡️ 강사님께서 가장 많이 장애 보고를 했던 레포팅 내용 : 이 db에는 과도한 리터럴 SQL로 인해 하드 파싱이 많이 유발되어 성능이 느려지니 리터럴 SQL을 바인드 변수로 변경하기 ! ex) select empno, ename, sal from emp where empno=7788; ↓ select empno, ename, sal from emp where empno = :p_empno using i;
- 사용하지 않는 인덱스를 정리한다.
개발할 때 개발자들이 dba에게 인덱스 생성 요청을 많이한다. dba가 잘 선별해서 필요한 인덱스를 생성해야 한다. 인덱스가 테이블에 많이 걸리게 되면 단점이 테이블 insert 할 때 속도가 느려진다! 많이 선별 했는데도 불구하고 사용하지 않은 인덱스들이 있다.
- 적절한 인터커넥트를 구성한다.
ex) 인터커넥트를 infiniband로 구성
- 시퀀스의 cache 사이즈를 늘린다.
ex) SQ enqueue를 감소시키기 위해
- oltp 환경에서는 긴시간의 full table scan 을 감소한다.
✔️ 6. 불필요한 parsing을 줄이는 실습
6번 실습 cursor_sharing이 exact이 아니라 force면 어떤 현상이 벌어지는지 테스트
- cursor_sharing 값 확인
SQL> show parameter cursor_sharing NAME_COL_PLUS_SHOW_PARAM TYPE VALUE_COL_PLUS_SHOW_PARAM ------------------------ ---- ------------------------- cursor_sharing string FORCE
- 아래의 SQL을 스캇 유저에서 실행하고 메모리에 올라간 쿼리문 확인하기
ALTER system FLUSH shared_pool; select empno, ename, sal from emp where empno=7566; select sql_text from v$sql where sql_text like 'select empno%'; SQL_TEXT -------------------------------------------------------------------------------- select empno, ename, sal from emp where empno=:"SYS_B_0"➡️ 오라클이 알아서 7788인 리터럴 값을 바인드 변수로 변경했다.
empno=:"SYS_B_0"
다음에 SQL문장은 똑같은데 리터럴 값이 다른 문장이 들어오면 파싱 과정을 생략하고 이 SQL을 그대로 사용한다!
문제 다시 cursor_sharing을 exact으로 변경하기(이게 default값이다!)
-- 변경하기!
alter system set cursor_sharing=exact scope=both sid ='*';
-- 1, 2번 노드에서 수행
shutdown immediate
startup
-- 다시 잘 바뀌었나 확인
SYS @ racdb1 > show parameter cursor_sharing
NAME_COL_PLUS_SHOW_PARAM TYPE VALUE_COL_PLUS_SHOW_PARAM
------------------------ ---- -------------------------
cursor_sharing string EXACT문제 아래 2개의 SQL이 서로 공유가 되는지 확인하기
select empno, ename, sal
from emp
where empno=7788;
select empno, ename, sal
from emp
where empno=7902;
select sql_text
from v$sql
where sql_text like 'select empno%';
SQL_TEXT
--------------------------------------------------------------------------------
select empno, ename, sal from emp where empno=7788
select empno, ename, sal from emp where empno=7902➡️ 아까 force였을때는 하나만 나왔는데 이번에는 숫자값이 달라서 다른 SQL로 판단이 되었다. 즉 공유가 되지 않음! 이 현상을 하드파싱 이라고 한다. (같은 SQL을 공유풀에서 찾아서 파싱을 생략하는 것은 소프트 파싱임)
DECLARE
TYPE rc IS REF cursor; #테이블 형태의 데이터를 저장할 수 있는 변수 타입을 rc라는 이름으로 변수타입 생성
l_rc rc; #테이블 형태의 데이터를 저장할 수 있는 변수 생성
l_dummy all_objects.object_name%TYPE;
l_start NUMBER DEFAULT dbms_utility.get_time; #숫자로 만드는데 1/100초로 현재 시간을 리턴 하는 변수 생성
BEGIN
FOR i IN 1 .. 10000 #10000번을 돌리는데
loop
OPEN l_rc FOR #테이블형태의 데이터를 저장할 수 있는 변수
'select object_name from all_objects where object_id = ' || i;
fetch l_rc INTO l_dummy; #l_dummy에 데이터 넣을것이다. 얘를 출력하는건 아님
close l_rc;
END loop;
dbms_output.put_line ( round( (dbms_utility.get_time - l_start)/100, 2) || 'seconds'); # 루프문 돌리는데 걸린 시간
END;
/
💡바인드 변수 사용했을때
DECLARE TYPE rc IS REF cursor; l_rc rc; l_dummy all_objects.object_name%TYPE; l_start NUMBER DEFAULT dbms_utility.get_time; BEGIN FOR i IN 1 .. 10000 loop OPEN l_rc FOR 'select object_name from all_objects where object_id = :x' USING i; fetch l_rc INTO l_dummy; close l_rc; END loop; dbms_output.put_line ( round ( (dbms_utility.get_time - l_start) / 100, 2) || 'seconds..'); END; /
✔️ 7번. 사용하지 않는 인덱스 정리 실습
실습
- scott 유저로 접속해서 demo 돌리기
SCOTT> @demo.sql
- 사원테이블 월급에 인덱스 생성하기
create index emp_sal on emp(sal);
- 인덱스를 모니터링 한다.
alter index emp_sal monitoring usage; select index_name, used from v$object_usage; INDEX_NAME USE ------------------------------ --- EMP_SAL NO
- 사원 테이블의 월급을 조회해서 emp_sal 인덱스를 사용하기
select /*+ index(emp emp_sal) */ ename, sal from emp where sal = 3000;
- emp_sal인덱스를 사용했는지 확인하기
select index_name, used from v$object_usage; INDEX_NAME USE ------------------------------ --- EMP_SAL YES➡️ 만약 확인해서
NO이면 인덱스 지워주면 된다.
6. emp_sal 인덱스 모니터링을 해제하기select index_name, monitoring from v$object_usage; INDEX_NAME MON ------------------------------ --- EMP_SAL YES alter index emp_sal nomonitoring usage; select index_name, monitoring from v$object_usage; INDEX_NAME MON ------------------------------ --- EMP_SAL NO
문제 emp 테이블의 job에 인덱스를 걸고 모니터링을 거시오 그리고 job에 걸린 인덱스를 사용해보기!
- job에 인덱스 생성
create index emp_job on emp(job);
- 모니터링 걸기
alter index emp_job monitoring usage; select index_name, used from v$object_usage; INDEX_NAME USE ------------------------------ --- EMP_SAL YES EMP_JOB NO
- emp_job 인덱스를 사용하기
select /*+ index(emp emp_job) */ ename, job from emp where job = 'ANALYST'; -- 사용했는지 확인 select index_name, used from v$object_usage; INDEX_NAME USE ------------------------------ --- EMP_SAL YES EMP_JOB YES
- 모니터링 해제
select index_name, monitoring from v$object_usage; INDEX_NAME MON ------------------------------ --- EMP_SAL NO EMP_JOB YES alter index emp_job nomonitoring usage;
RAC 목차
- 소개
- 관리
- 튜닝
- 고가용성(서비스)
📖 7장. 고가용성(서비스)
- RAC의 장점
- 고가용성
- 확장성
- RAC의 단점
: 인터커넥트 부하로 인해 성능이 떨어지는 단점➡️ 단점을 극복하기 위해 오라클에서 권고하는 방법
각 노드마다 업무 성향을 다르게 나눈다. 만약 주문관련 업무가 노드 2에서도 이루어지면 주문 관련 업무 데이터가 2번에도, 3번에도 모두 있을것이다. 이것은 인터커넥트 부하가 생길 수 있다.❓ 근데 어느 노드에 붙을지 랜덤인데 어떻게 ?
: 이것을 오라클에서 제공한다.서비스를 이용하면 어느 노드로 접속하게 할지 결정할 수 있다.
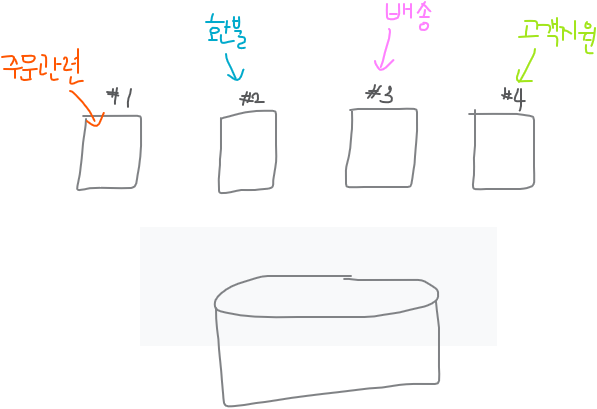
✏️ 서비스란 무엇인가?
💡 같은 작업을 하는 세션들의 모임 !
✔️ 서비스를 만들고 시작하기
실습
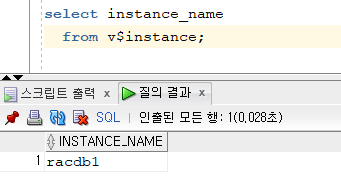
1. 현재 db에 있는 서비스가 무엇인지 확인
show parameter service_name NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ service_names string racdb2. 1번 노드에 order(주문팀) 서비스를 생성합니다.
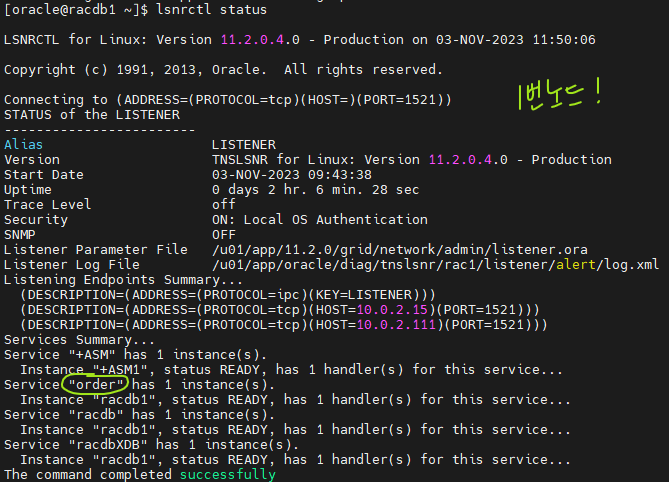
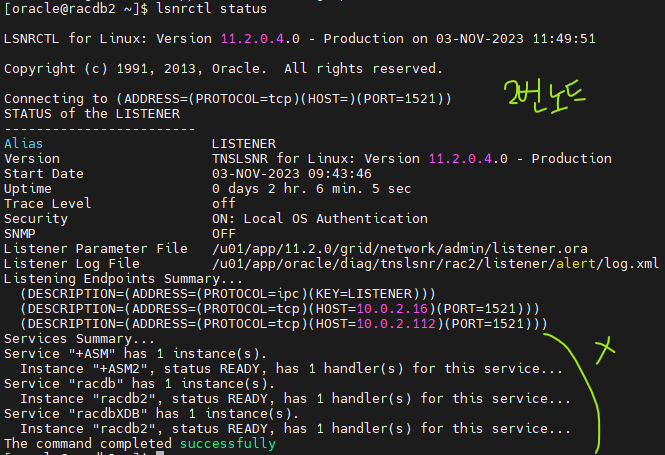
SQL> select name from v$database; 최초로 서비스를 띄울 인스턴스 ↑ $ srvctl add service -d racdb -s order -r racdb1 -a racdb2 ↑ ↑ ↑ db 이름 서비스이름 failover 시킬 백업 인스턴스3. 주문(order)서비스를 시작 시킵니다.
$ srvctl start service -d racdb -s order $ srvctl status service -d racdb -s order
4. 각 인스턴스에서 실행해보기-- 1번 인스턴스 SYS @ racdb1 > show parameter service_name NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ service_names string order -- 2번 인스턴스 NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ service_names string racdb5. 리스너의 상태를 확인해서 order 서비스가 떠있는지 확인
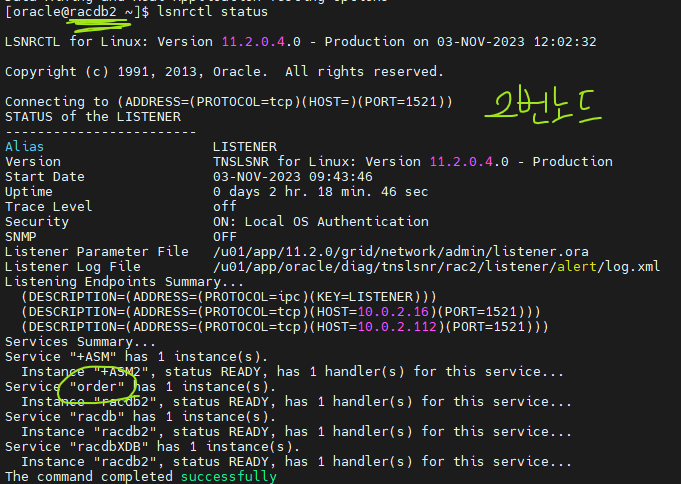
$ lsnrctl status
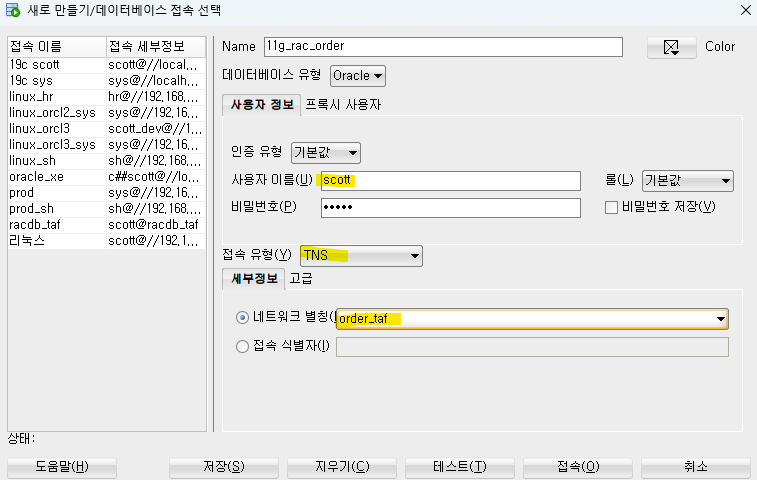
➡️ 2번 노드에서는order가 보이지 않고 1번에서만 보인다 !6. sqldeveloper를 이용해서 order 서비스, scott으로 접속하기
C:\app\ITWILL\product\18.0.0\dbhomeXE\network\admin 로 이동해서tnsnames.ora를 연다. 내용 추가해주기 !!
⬇️ sqldeveloper 에서
7. 1번 노드를 shutdown abort 하면 서비스가 2번으로 넘어가는지 확인SYS @ racdb1 > shutdown abort
-- 2번노드에서 수행 SYS @ racdb2 > show parameter service_name; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ service_names string order



문제 쿠팡 rac 노드 2번에 배송업무 (transfer) 서비스를 띄우시오!
- transfer 서비스 생성
$ srvctl add service -d racdb -s transfer -r racdb2 -a racdb1
- 주문(order)서비스를 시작 시킵니다.
$ srvctl start service -d racdb -s transfer $ srvctl status service -d racdb -s transfer transfer 서비스가 racdb2 인스턴스에서 실행 중임
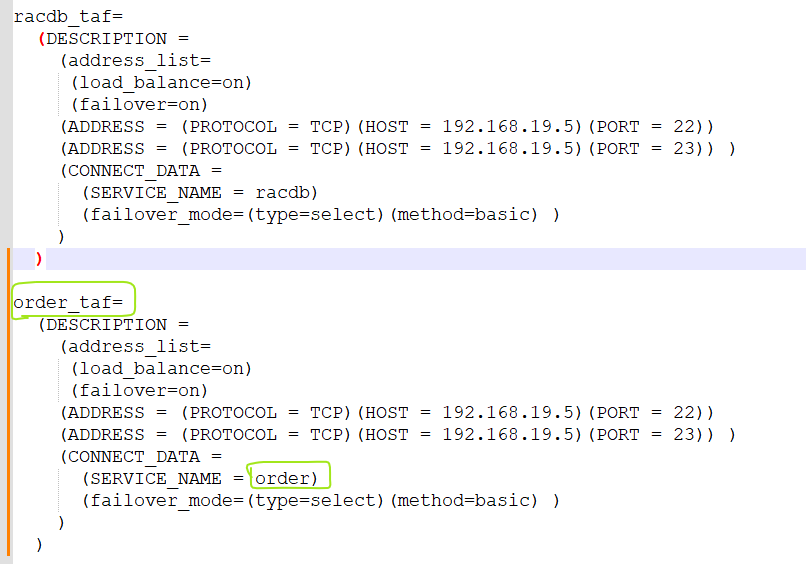
문제 sqldeveloper로 scott 유저로 transfer 서비스에 접속하기
transfer_taf=
(DESCRIPTION =
(address_list=
(load_balance=on)
(failover=on)
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.19.5)(PORT = 22))
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.19.5)(PORT = 23)) )
(CONNECT_DATA =
(SERVICE_NAME = transfer)
(failover_mode=(type=select)(method=basic) )
)
) 
✔️ 서비스를 다시 원래 노드로 relocate 시키기
- 2번으로 failover된 서비스를 1번 노드로 relocate시키기
relocate할 인스턴스 이름 ↑ $ srvctl relocate service -d racdb -s order -i racdb2 -t racdb1 ↑ 서비스가 현재 떠있는 인스턴스$ srvctl status service -d racdb -s transfer

문제 2번에 transfer 서비스를 1번 노드로 relocate하기
$ srvctl relocate service -d racdb -s transfer -i racdb2 -t racdb1
$ srvctl status service -d racdb -s transfer
transfer 서비스가 racdb1 인스턴스에서 실행 중임
✔️ 서비스를 중지시키고 삭제하는 방법
$ srvctl stop service -d racdb -s order -- 중지시키고
$ srvctl remove service -d racdb -s order -- 삭제하기
$ srvctl status service -d racdb -s order
PRCR-1001 : ora.racdb.order.svc 리소스가 존재하지 않습니다.문제 transfer 서비스를 중지시키고 삭제하기!
$ srvctl stop service -d racdb -s transfer -- 중지시키고 $ srvctl remove service -d racdb -s transfer -- 삭제하기 $ srvctl status service -d racdb -s transfer PRCR-1001 : ora.racdb.transfer.svc 리소스가 존재하지 않습니다.
⭐ 서비스를 만들고 관리하는 이유는, 노드별로 각각 업무를 분산시켜서 인터커넥트 부하를 방지하기 위해서 이다!
⭐ 서비스를 생성하고 관리하는 방법 3가지
- srvctl 명령어
- enterprise manager
- dbms_service.modify_service 패키지
✔️ 서비스 친화도란?
💡 해당 서비스에 대해 보다 더 빠른 응답속도를 보이는 노드는 해당 서비스에 대해 서비스 친화도가 높다.
❓ 서비스가 떠있는 인스턴스가 shutdown abort 되었을 때 해당 서비스가 다른 가용 노드로 넘어가게 되는데 만약 아래와 같이 노드가 여러개면 어느 노드로 넘어갈까 ?
$ srvctl add service -d racdb -s order -i racdb -a racdb2,racdb3racdb2,racdb3 여기는 공간 없도록 !
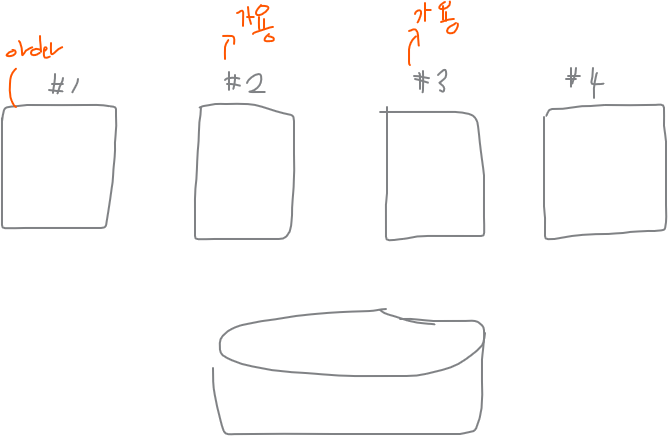
➡️ 1번에 shutdown abort가 일어났다. 그러면 1번 노드에 있던 scott은 어디로 넘어갈까??
: 가용노드인 2번과 3번 중에서 서비스 친화도가 높은 노드로 failover한다. 랜덤이 아님!!
✏️ 서비스로 관리되는 오라클의 관리 요소들
- 스케줄러 : 특정 시간에 특정 프로그램이 실행되게 하는 오라클 패키지
< 사용 예시 >
1번 노드에서 scott 유저가 밤11시에 배치 프로그램 스케줄을 돌리고 있다.
2,3번 노드가 가용서버라는 가정하에 갑자기 1번 인스턴스가 죽었다. (비정상종료)
95%정도 진행되었는데 5% 남기고 프로그램이 종료되었다면
가용서버중 서비스 친화도가 높은 노드로 넘어가서 나머지 5%를 그쪽 노드에서
마무리 지어준다 ! - 리소스 매니저 : 특정 세션이 오라클의 자원을 무한히 사용하지 못하도록 제한을 거는 기능. 특정 서비스가 오라클의 자원을 무한히 사용하지 못하도록 리소스 매니저로 제한을 걸어줄 수 있다. (p.7-20)
세션(session) -> 딱 한개의 접속유저
서비스(service) -> 여러 다수 유저들
* 서비스를 이용하지 않고 그냥 리소스 매니저만 이용한다면
자원에 대한 제한을 유저 단위만 할 수 있다.
예) scott으로 접속한 사람들은 모두 리소스 사용에 대한 제한을 받게한다.
* 서비스를 이용한 리소스 매니저 기능을 이용하면 다음과 같이
서비스 별로 리소스에 대한 제한을 줄 수 있다.
40% 40% 20%
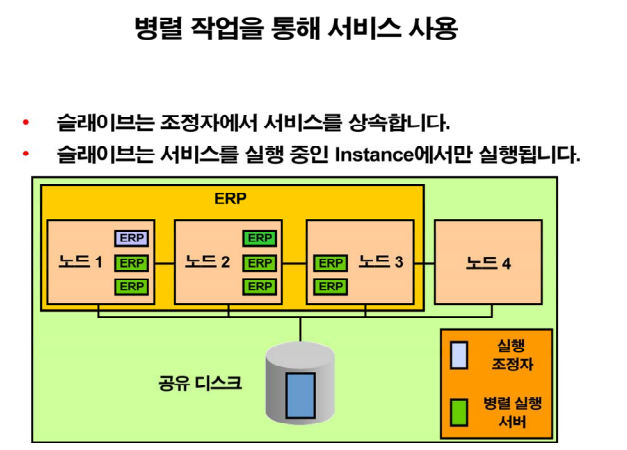
주문 배송 고객지원✏️ 서비스를 이용했을 때의 병렬 처리 방법
(p. 7-27)
select /*+ parallel(a) */ count(*)
from dba_objects a, dba_objects b;➡️ 서비스를 여러 노드에 띄울 수 있고, 사용자들은 노드1, 노드2, 노드3 중 랜덤으로 접속이 된다. 이것은 병렬작업할때 좋다. 여러노드의 cpu, 메모리를 쓰면 작업이 빠르다. 한쪽에서만 병렬 처리를 하려면 느리다!
$ srvctl add service -d racbd -s erp -i racdb1,racdb2,racdb3 -a racdb4racdb1,racdb2,racdb3 에 erp 서비스를 띄우겠다 !
➡️ 그림에 보라색은 코디네이터 , 초록색은 프로세서들(슬레이브)
select /*+ parallel(a) */ count(*) from dba_objects a, dba_objects b;✅ 4개의 노드가 있는 RAC 환경에서 위 병렬 쿼리를 수행하면 ERP 서비스가 떠있는 3개의 노드에 병렬 프로세서들이 작업을 수행한다. 그렇게되면
3개의 장비의 cpu, memory를 다 사용할 수 있으니, 싱글 노드일 때 보다 더 좋은 성능을 보일 수 있다.
🚨 그러나 인터커넥트 부하가 심한 시간에 위 작업이 수행된다면, 오히려 한개의 노드에서 병렬쿼리를 수행했을 때 보다 더 느릴 것이다.💡 이것을 해결하는 RAC 파라미터가 있다!
instance_groupsparallel_instance_group
파라미터 실습 !
실습1.
- instance_groups 라는 파라미터를 다음과 같이 설정(1번노드에 대한)
# 1번 노드 # 2번 노드 instance_groups=seoul,busan instance_groups=seoul alter system set instance_groups=seoul,busan scope=spfile sid='racdb1';
- db 내렸다 올리기
- instance_groups 라는 파라미터를 다음과 같이 설정(2번 노드에 대한)
alter system set instance_groups=seoul scope=spfile sid='racdb2';
- db 내렸다 올리기
➡️ 에러 아님.

실습2. 병렬 프로세서가 1번 노드에서만 수행되도록 하기
-- 이렇게 하면 부산이 1번에 있으니 1번에만 뜬다.
alter session set parallel_instance_group=busan;
select /*+ parallel(a) */ count(*)
from dba_objects a, dba_objects b;
-- 확인하기
col program for a20
select inst_id, process, program
from gv$session
where program like'%(P0%';
INST_ID PROCESS PROGRAM
---------- ------------------------ --------------------
1 12441 oracle@rac1 (P000)
1 12443 oracle@rac1 (P001) 안되었음 no row selected
실습3 양쪽 인스턴스에 모두 병렬 프로세서가 뜨게 하기
-- 이렇게 서울로만 지정하고 병렬 쿼리를 날리면 1,2번 노드 양쪽에 모두 뜬다.
alter session set parallel_instance_group=seoul;
select /*+ parallel(a) */ count(*)
from dba_objects a, dba_objects b;문제 다시 instance_groups 파라미터를 null로 초기화하기
alter system reset instance_groups scope=spfile sid='racdb1';
alter system reset instance_groups scope=spfile sid='racdb2';
startup force✏️ 서비스 단위로 user trace를 생성하는 방법
- SQL trace란?
: SQL 튜닝할 때 보다 더 많은 성능 정보를 얻기 위해 필요한 기능.
SQL <- 개발자, 운영자들이 튜닝할 SQL을 메일로 보내준다.
그렇지만
SQL 튜너가 직접 악성 SQL을 찾아서 튜닝을 하는 경우도 있다.
➡️ 주문 내역 집계 배치 프로그램(pl/sql)이 느리니까 튜닝좀 해주세요!주문내역 집계 배치 프로그램 안에는 수십개의 SQL들이 있다. 만약 20개의 SQL들이 있었다고 하면 이 SQL들 중에서 가장 느린 SQL이 무엇인지 TOP10을 보여달라고 오라클에게 요청할 수 있다.
💡 이것을 알아내는게 바로 SQL trace이다!!
✔️ SQL trace 생성법
: scott에서 하기
alter session set SQL_TRACE=true;
alter session set events '10046 trace name context forever,level 12';
-- 나중에 trace 파일 찾기 쉬우라고 설정하는 것이라 필수는 아니다!
alter session set tracefile_identifier=mytrace;
-- 악성 SQL을 여러개 돌렸다고 가정
select ename, sal, job
from emp
where deptno = 20;
select ename, sal, job
from emp
where ename = 'ALLEN';
.
.
.
alter session set SQL_TRACE=false;
-- 끄기
alter session set events '10046 trace name context off';
-- 위 SQL에 대한 튜닝 정보가 있는 trace file 위치
show parameter user_dump_dest
NAME TYPE VALUE
------------------------------------ ----------- -------------------- ----------
user_dump_dest string /u01/app/oracle/diag /rdbms/rac
db/racdb1/trace
$ cd /u01/app/oracle/diag/rdbms/racdb/racdb1/trace
$ ls -rlt
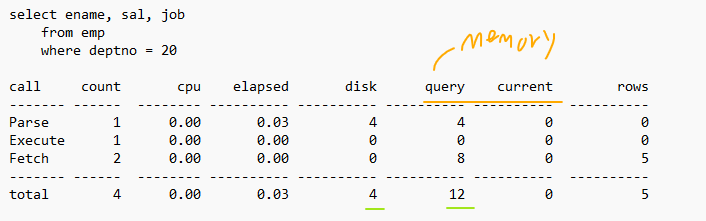
✔️ trace 파일을 분석합니다.
[oracle@racdb1 trace]$ tkprof scott/tiger sys=no trace=racdb1_ora_9067_MYTRACE.trc output=1103_report01.txt [oracle@racdb1 trace]$ cp 1103_report01.txt /home/oracle/1103_report01.txt➡️ 훨씬 보기 좋은 형태로 SQL들을 분석해준다!
➡️ SQL의 SQL trace 정보(위 이미지)와 실행계획과 관련된 대기 이벤트를 보여준다.
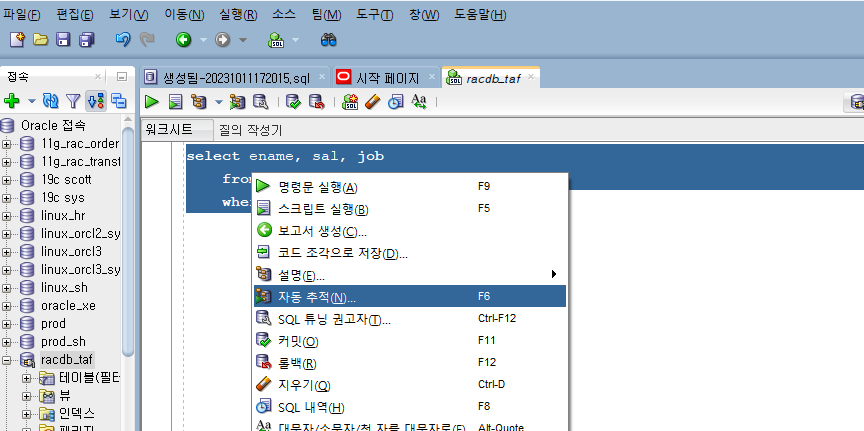
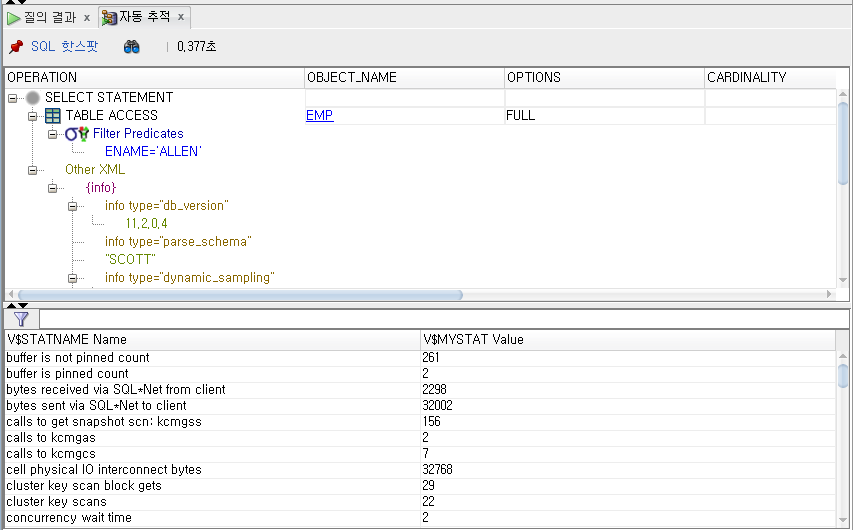
💡 sqldeveloper에서 trace 파일 보기
위처럼 보이지는 않는다.
➡️ 토드(tead), orange와 같은 툴을 이용하면 위의 정보를 쉽게 툴에서 볼 수 있다. 이러한 SQL trace를 지금 우리는 세션 레벨로 생성했는데, 서비스를 이용하면 서비스 레벨로 SQL trace를 생성할 수 있다.
💡 서비스 레벨로 trace를 생성하는 방법
exec dbms_monitor.serv_mod_act_trace_enable('order');➡️ order서비스를 이용하는 모든 세션들을 다 trace 걸겠다.
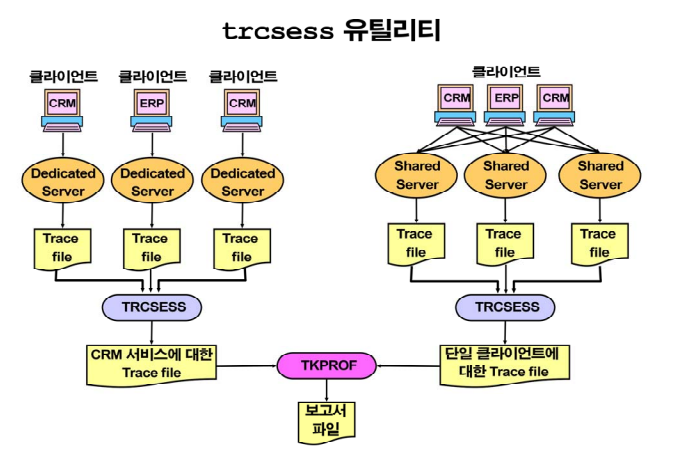
trafile 이 세션별로 생성되므로 여러 trace file들이 생성된다.
여러개의 trace file들이 생성되므로 그 여러개의 trace file을 오라클이 알아서 찾아서 하나의 파일로 만들어줘야 하는데 그 툴이 바로 trcsess이다.
서비스 단위로 SQL trace를 생성하는 순서
- order 서비스 sql trace 활성화 시킨다.
SQL> exec dbms_monitor.serv_mod_act_trace_enable('order');
- 이제 order서비스를 이용하는 모든 유저들의 SQL정보가 전부 trace file에 기록이 된다.
- order 서비스 sql trace를 비활성 시킨다.
SQL> exec dbms_monitor.serv_mod_act_trace_disable('order');
- user_demp_dest 파라미터에 지정된 위치로 가서 아래의 명령어로 order 서비스에 관한 trace file들을 하나로 합친다.
$ trcsess output=order.trc service=order
- trace 파일을 분석하기
$ tkprof scott/tiger sys=no trace=order.trc output=1103_report02.txt
✏️ 서비스의 기타 기능
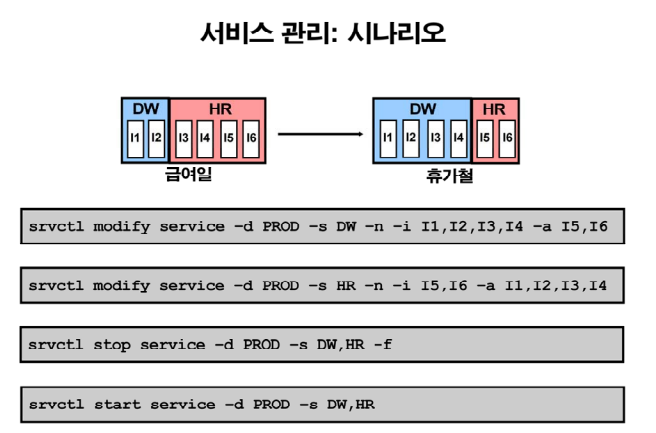
💡 급여일에는 데이터 분석하는 노드를 줄이고 휴가철에는 늘린다. HR은 사원관리. 위는 휴가철 변경할 때 하는 명령어
문제 그럼 다시 휴가철 -> 급여일로 될 수 있도록 rac 서비스 노드들을 구성하시오!
srvctl modify service -d PROD -s DW -n -i I1, I2 -a I3, I4, I5, I6
srvctl modify service -d PROD -s HR -n -i I1, I2, I3, I4 -a I5, I6
srvctl stop service -d PROD -s DW,HR -f
srvctl start service -d PROD -s DW,HR 