
📖 8장. RAC 환경에서의 고가용성
- 클라이언트 로드 밸런싱
- 서버측 로드 밸런싱
- 클라이언트 CTF (connect time failover)
- TAF (transparent Application Failover)
- FAN (Fast Application Notification)
✏️ 1. 클라이언트 로드 밸런싱
✅ RAC 환경에서 제공하는 로드 밸런싱 (load balancing) 방법 2가지
1. 클라이언트 로드 밸런싱
tnsnames.ora 파일 안에 load_balance=on 이라는 파라미터가 있어서 어느 노드로 접속할지가 완전히 랜덤으로 결정되게끔 하는 로드 밸런싱! sqldeveloper scott 유저로 접속을 할 때 racdb_taf tns 별칭을 써서 접속 할 때 완전 랜덤으로 1번 노드, 2번 노드로 접속할 수 있는것은 load_balance=on 때문이다!⭐ TIP !
racdb_taf tns 별칭으로 접속을 시도하는데, 자꾸 접속이 안된다고 해결 요청이 들어온다면!
1) 아래 내용을 서버에 tnsnames.ora에 넣고 서버에서 직접 racdb_taf를 이용해 접속을 해본다.
➡️서버 접속 방법 ( 아래 처럼 접속 후에 vi로 tnsnames.ora를 열고 넣는다.)
➡️ 별칭으로 접속해보기[oracle@racdb1 ~]$ cd $ORACLE_HOME/network/admin [oracle@racdb1 admin]$ ls samples shrept.lst tnsnames.ora [oracle@racdb1 admin]$ vi tnsnames.ora
2) sqlplus scott/tiger@racdb_taf 로 접속이 안된다면, tnsping은 수행되는지 확인!$ tnsping racdb_taf
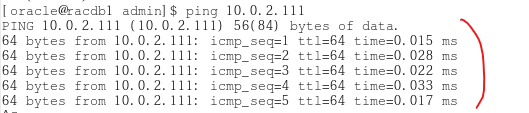
$ ping 10.0.2.111
❓ 위와 같이 나오면 정상인데 만약 ping이 안나가고 에러가 나면 서버실에 가서 network 랜선이 빠져있는지 확인해보아야 한다.


✏️ 2. 서버 로드 밸런싱
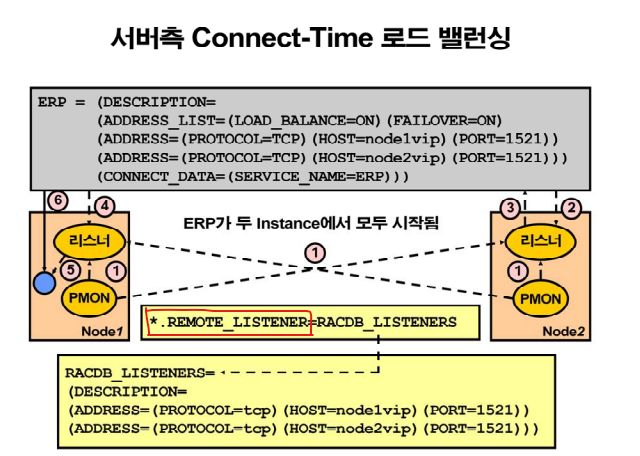
💡 서버의 부하에 따라 노드를 분산하는 기능! 내 노드가 바쁘면 다른 노드에 세션을 할당하는 기능이다.
✅ 서버 로드 밸런싱 기능을 이용하기 위해 셋팅해야할 2가지 사항
1. remote_listener를 셋팅한다.
2. 리스너의 서비스 등록 방법을 동적 서비스 등록 방법으로 설정한다.
✔️ 리스너에게 서비스를 등록해주는 방법 2가지1) 동적 서비스 등록 (권장) (11g pmon -> listener, 12c 이후는 LPEG -> listener) 2) 정적 서비스 등록 (listener.ora 파일 안에 서비스 이름을 직접 기술)
예를 들어 1번 노드가 바쁘고 2번 노드가 한가하다면 2번으로 접속해야 하는데, 새롭게 접속하는 세션들은 클라이언트 노드 발란스는 랜덤이라 눈치없이 1번 노드로 넣어준다. 서버측 로드 밸런스가 2번 쪽으로 유도하기 때문에 서버측과 클라이언트 측이 서로 소통 해야 한다. 자기의 노드가 바쁜지 안바쁜지는 PMON이 상대측 노드의 리스너에게 알려준다. PMON이 자기 리스너와 상대편 리스너에게 지금 노드의 상태정보를 알려준다. 이것을REMOTE_LISTENER을 설정해주어야 하고,동적 서비스 등록방법을 설정해주어야 한다.
실습 1번 노드와 2번 노드에서 각각 REMOTE_LISTENER 파라미터가 셋팅되어 있는지 확인하기
SYS @ racdb1 > show parameter REMOTE_LISTENER;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
remote_listener string rac-scan:1521
SYS @ racdb2 > show parameter REMOTE_LISTENER;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
remote_listener string rac-scan:1521
$ cat /etc/hosts
### SCAN
10.0.2.120 rac-scan -- 10.0.2.120 의 별칭이다! rac-scan 는 스캔리스너의 ip주소 리스너들을 총괄하는 리스너이다.(1521은 포트번호)
✅ 리스너.ora 찾기
[grid@+ASM1 ~]$ cd $GRID_HOME/network/admin
[grid@+ASM1 admin]$ ls
endpoints_listener.ora listener.ora.bak.rac1 samples sqlnet.ora
listener.ora listener2310222AM0424.bak shrept.lst
-- vi listener.ora 열면 scan listener로 운영되고 있다는 것을 알 수 있다.
LISTENER=(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=IPC)(KEY=LISTENER)))) # line added by Agent
LISTENER_SCAN1=(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=IPC)(KEY=LISTENER_SCAN1)))) # line added by Agent
ENABLE_GLOBAL_DYNAMIC_ENDPOINT_LISTENER_SCAN1=ON # line added by Agent
ENABLE_GLOBAL_DYNAMIC_ENDPOINT_LISTENER=ON # line added by Agent✔️ 서버 로드밸런싱 테스트
✍🏻 로드밸런싱 테스트
1. 아래 2개 서비스를 시작시킨다. (oracle user에서)
: 서버쪽 로드밸런스 안하는 서비스, 하는서비스 만들고 시작시키기!$ srvctl add service -d racdb -s SNOLBA -r racdb1,racdb2 $ srvctl add service -d racdb -s SLBA -r racdb1,racdb2 $ srvctl start service -d racdb -s SNOLBA $ srvctl start service -d racdb -s SLBA $ srvctl status service -d racdb -s SNOLBA SNOLBA 서비스가 racdb1,racdb2 인스턴스에서 실행 중임 $ srvctl status service -d racdb -s SLBA SLBA 서비스가 racdb1,racdb2 인스턴스에서 실행 중임2. 아래의 SQL 을 수행하여 서비스 속성을 변경합니다. (sys 유저에서)
exec DBMS_SERVICE.MODIFY_SERVICE ( - 'SNOLBA', - goal => DBMS_SERVICE.GOAL_NONE, - clb_goal => DBMS_SERVICE.CLB_GOAL_LONG); exec DBMS_SERVICE.MODIFY_SERVICE ( - 'SLBA', - goal => DBMS_SERVICE.GOAL_SERVICE_TIME, - clb_goal => DBMS_SERVICE.CLB_GOAL_SHORT);:
SNOLBA는 서버 로드발란스 안하는걸로, LONG 으로
:SLBA는 로드발란스를 하는 것으로, SHORT 으로 modify 한다.
💡 goal 옵션1) goal => DBMS_SERVICE.GOAL_NONE : 로드 밸런싱 안하겠다. 2) goal => DBMS_SERVICE.GOAL_SERVICE_TIME : 로드 밸런싱 하겠다.💡 clb_goal 옵션
1) clb_goal => DBMS_SERVICE.CLB_GOAL_LONG) : 세션의 갯수로 로드 밸런싱 하겠다. (1번 50개, 2번 50개 균등하게. 서버 로드밸런싱 안하겠다!) 2) clb_goal => DBMS_SERVICE.CLB_GOAL_SHORT) : 서비스 친화도로 로드 밸런싱 하겠다! ★ 1번 노드가 부하가 있는데도 불구하고 무조건 균등하게 세션을 2개의 노드에 각각 분할해 준다면, 1번 노드에 접속한 세션들은 성능 저하를 경험하게 될 것이다! 1번 노드가 바쁘면 2번 노드로 접속할 수 있게 해주어야 한다!!3. 위의 두개의 서비스로 접속할 수 있는 tns 정보가 1번 노드의 tnsnames.ora 에 있는지 확인
$ cd $ORACLE_HOME/network/admin $ vi tnsnames.ora SNOLBA = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = rac1-vip)(PORT = 1521)) (ADDRESS = (PROTOCOL = TCP)(HOST = rac2-vip)(PORT = 1521)) (LOAD_BALANCE = yes) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = SNOLBA) ) ) SLBA = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = rac1-vip)(PORT = 1521)) (ADDRESS = (PROTOCOL = TCP)(HOST = rac2-vip)(PORT = 1521)) (LOAD_BALANCE = yes) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = SLBA) ) )4. 두 서비스의 tns alias 가 설정되어져 있다.(접속 테스트)
$ sqlplus scott/tiger@slba -- 랜덤으로 붙고있다 ! $ sqlplus scott/tiger@snolba
✍🏻 지금 부터는 서버쪽 로드 밸런스
1. 아래 파일들을 1번 노드에 올렸다.(모바텀 이용)
4. sys 유저에서 아래의 유저를 생성하고 권한 부여 (이미 있으므로 이 단계는 생략해도 됨)SYS> create user JFV identified by jfv; SYS> grant connect, resource, dba to JFV; SYS> connect jfv/jfv SYS> create table fan(c number);5. 별도의 터미널 창을 열고 아래의 SQL 이 반복되게 쉘 스크립트 작성 (JFV의 세션의 갯수 확인) 쉘 스크립트 이름은
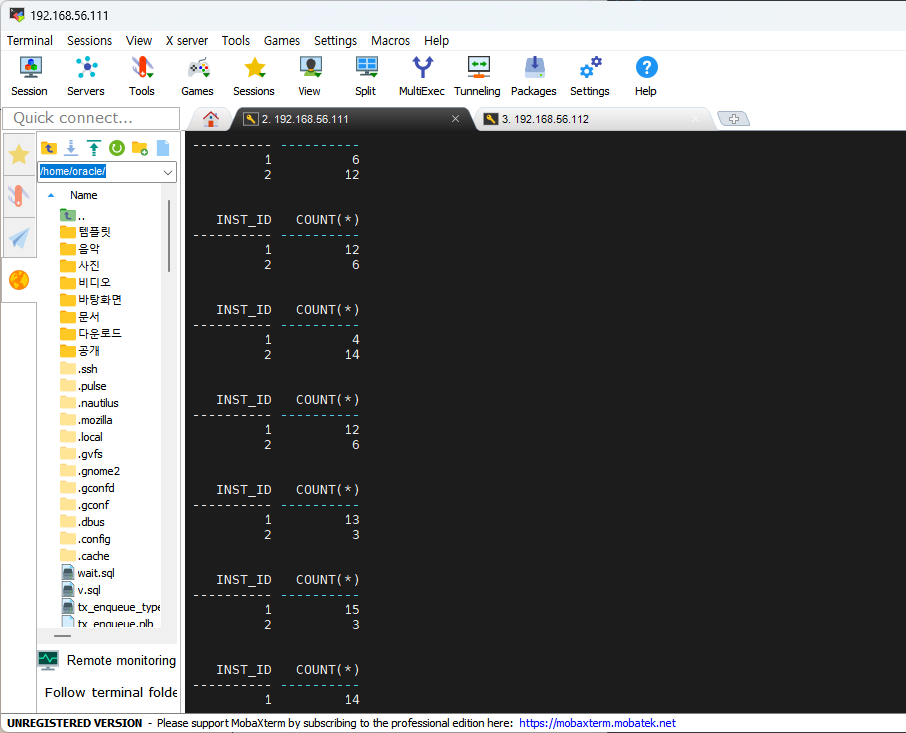
c.sh로 했음select inst_id, count(*) from gv$session where username='JFV' group by inst_id order by inst_id;#!/bin/bash while true do sqlplus -s / as sysdba <<EOF select inst_id, count(*) from gv\$session where username='JFV' group by inst_id order by inst_id; EOF sleep 2; done
6. 부하를 주는 스크립트를 1번 노드에만 2개를 띄운다.$ cd $ chmod 777 primes $ ./primes
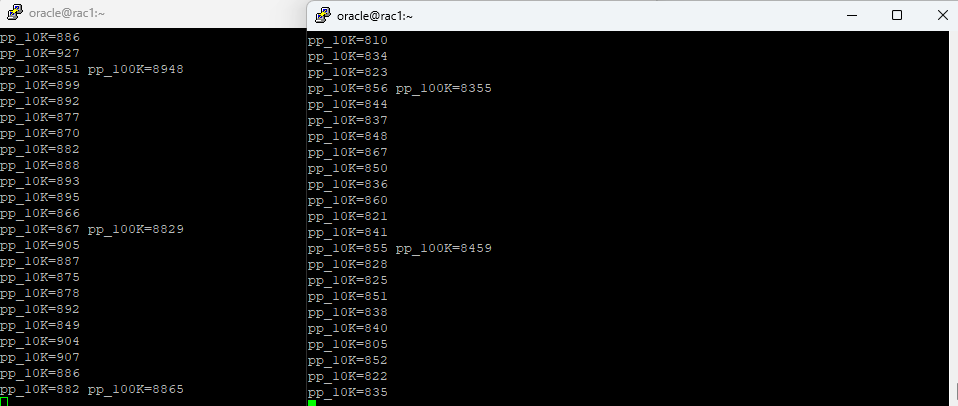
7. 별도의 푸티창을 열고 oracle 유저로 접속, jfv 유저로 계속 1번과 2번 노드에 접속하는 스크립트를 수행한다.$ chmod 777 fan.sh $ chmod 777 startfanload.sh $ ./startfanload.sh SNOLBA -- 로드밸런싱 안했을 때 테스트
➡️ 1번 노드가 busy 한데 세션이 계속 1번 쪽으로 붙는 것을 확인할 수 있다.
9. 스크립트를 중지시킨다.chmod 777 stopfanload.sh ./stopfanload.shCtrl+C 를 누르고 재빠르게 ./stopfanload.sh 수행
10. 로드밸런싱이 수행되는 스크립트 수행$ ./startfanload.sh SLBA -- 로드밸런싱 했을때 테스트
밸런싱이 되는 모습을 확인할 수 있다.
안정적으로 밸런싱이 되는 모습을 확인하기 위해서는 많은 시간을 기다려야 한다.
➡️ 로드 밸런싱을 하는 서비스 SLBA를 이용해서
✏️ 3. 클라이언트 CTF(connect time failover)
💡 tnsnames.ora 파일안에 failover=on이라는 파라미터가 있어서, 최초에 접속할 때 두개의 노드중에 하나가 죽어있다면 처음부터 살아있는 노드로 접속하게 하는 기능
그럼 만약 failover=on이 없다면 어떻게 접속되는가?
: 클라이언트 로드 밸런싱으로 1번 또는 2번으로 랜덤하게 접속되는데, 만약 죽어있는 노드로 접속하게 되면 ORA-3113 에러를 보게 됩니다.
1) vip를 사용 안했을 때 -> 죽어있는 노드로 접속할 때 10분 대기하고 나서 ORA-3113 에러를 본다.
2) vip를 사용 -> 죽어있는 노드로 접속할 때 바로 ORA-3113 에러가 난다.
or
1) vip를 사용 안했을 때 -> 이미 접속이 되어져 있는 상태인데 내가 접속한 노드가
죽은 상태에서 SQL을 실행한 경우 10분 대기 하고 ORA-3113 에러를 본다.
2) vip를 사용 -> 이미 접속이 되어져 있는 상태인데 내가 접속한 노드가 죽은 상태에서 SQL을
실행하면 바로 ORA-3113 에러가 난다.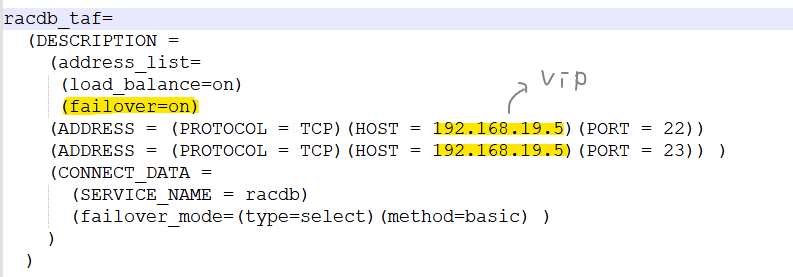
실습1. ctf 기능이 잘 구현되는지 확인
- 1번 노드를 shutdown abort 시키기
SYS @ racdb1 > shutdown abort ORACLE instance shut down.
- sqldeveloper 로 racdb_taf tns 별칭을 이용하여 scott user로 접속되는지 확인
: 무조건 살아있는 노드로 접속하게끔 하는것이 CTF
✏️ 4. TAF (transparent Application Failover)
💡 투명한 응용프로그램들(instance, vip, listener..)의 failover
투명하다는 것은 내가 접속한 노드가 shutdown abort 되었는지도 모르는 상태에서 그냥 자연스럽게 살아있는 노드로 접속되는 것을 말한다.
-- taf 파라미터 (tnsnames.ora 안에 있음)
(failover_mode=(type=select)(method=basic) ) ➡️ 다시 정리: taf란 ! 내가 접속한 노드가 죽었을 때 자동으로 살아있는 노드로 재접속 되는 기능
✅ taf 파라미터 중
type 파라미터의 종류3가지
1.none: TAF 기능을 쓰지 않겠다!
session: 큰 빅데이터를 select 하는 도중에 내가 접속한 노드가 shutdown abort 되면 select의 fetch가 실패하면서 그냥 끝난다. (짧게 짧게 끝나는 SQL이 많은 OLTP 환경에서 유용)3.
select: 큰 빅데이터를 select 하는 도중에 내가 접속한 노드가 shutdown abort 되면 select의 fetch를 살아있는 노드로 접속해서 계속 이어서 fetch를 해주게 한다. (대량의 레코드를 한번데 select 하는 배치 프로그램 환경에서 효율적)
❓ TAF 파라미터 중에서 method 파라미터 값의 종류는 무엇?
1.basic: failover가 필요로 할 때 살아있는 노드의 인스턴스에 서버 프로세서를 할당하는 방식
2.preconnect: failover가 필요하지 않을 때도 미리 failover에 대비해서 다른 인스턴스에 서버 프로세서를 가동 시켜 failover시 발생하는 오버 헤드를 미리 줄이는 방식
➡️basic: 1번 노드가 shutdown 된다면 그제서야 2번 노드의 서버프로세스를 하나 깨운다.
➡️preconnect: 미리 번 노드의 서버프로세스를 깨워놓는다. 장애가 났을 때 빨리 넘어갈 수 있다. 단점은 자원이 많이 든다!
실습 TAF 기능이 잘 구현되는지 확인
: 내가 접속한 노드가 죽었을 때 자동으로 살아있는 노드 에게 접속되게 하는 기능
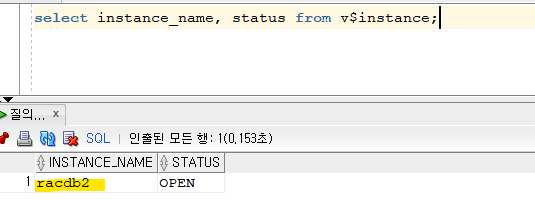
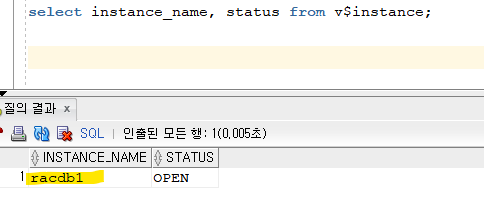
- sqldeveloper로 scott유저로 접속 한 후, 몇번 노드로 접속했는지 확인 --
racdb2번 노드로 접속!!- 접속한 노드를 puyyt에서 shutdown abort 하기
SYS @ racdb2 > shutdown abort ORACLE instance shut down.
- 투명하게 다른 살아있는 노드로 넘어갔는지 확인하기
문제 taf 파라미터중, method의 preconnect를 테스트 하시오
transfer2_taf=
(DESCRIPTION =
(address_list=
(load_balance=on)
(failover=on)
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.19.5)(PORT = 22))
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.19.5)(PORT = 23)) )
(CONNECT_DATA =
(SERVICE_NAME = transfer)
(failover_mode=(type=select)(method=preconnect) )
)
) - shutdown abort
✅ 유저가 많으면 확실히 preconnect, basic이 차이가 난다.✏️ 5. FAN (Fast Application Notification)
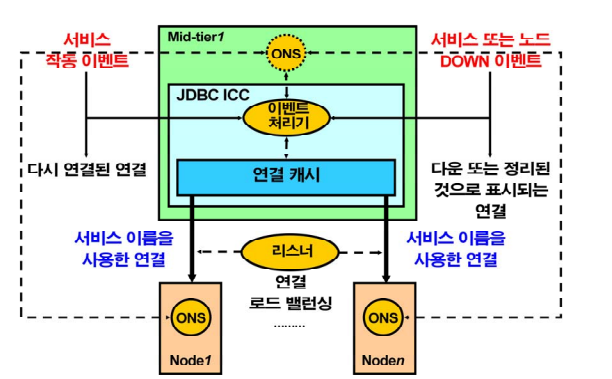
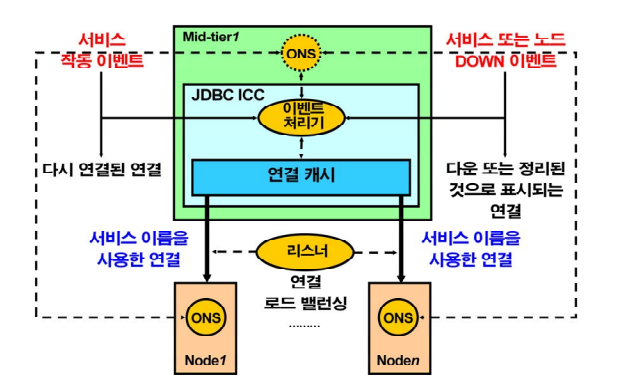
💡장애 (인스턴스 shutdown abort)가 발생했다는 메세지와 로드 밸런싱 정보를 응용 프로그램에게 빨리 알려주는 기능.
✅
ONS(oracle notification service) 가 관련 데몬 프로세서 인데,
1. 장애가 발생했다는 정보
2. 로드 밸런싱 정보
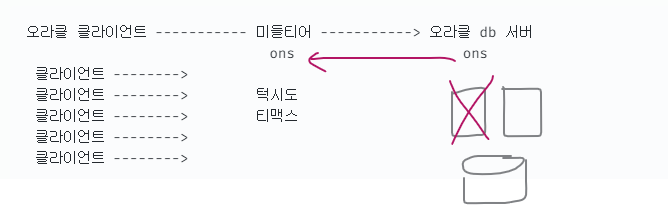
➡️ 오라클 db 서버가 맛집이라면 미들티어는 줄세우는 기능!
➡️ RAC1이 죽었다면 ons가 미들티어쪽 ons 한테 RAC1 죽었다고 알려준다. 그래서 빠르게 RAC2로 접속할 수 있는 것!
➡️ 오라클 제품 중에 oracle client 제품이 있는데 이 제품을 미들티어 서버에 설치를 해야 ons 데몬을 띄울 수 있다.
❓ FAN 기능을 구현하려면 어떻게 해야하는가 ?

✔️ oltp 서비스를 만들고 시작시키기!
$ srvctl add service -d racdb -s oltp7 -r racdb1,racdb2 $ srvcl start service -d racdb -s oltp7✔️ sys 유져에서 oltp7 서비스를 modify 합니다.
exec dbms_service.modify_service ( - service_name =>'oltp7', - aq_ha_notifications => true, - failover_method => dbms_service.failover_method_basic, - failover_type => dbms_service.failover_type_session, - failover_retries => 180, failover_delay => 5, - clb_goal => dbms_service.clb_goal_long );✔️ 아래의 내용을 tnsnames.ora에 넣는다.
oltp7= (DESCRIPTION = (address_list= (load_balance=on) (failover=on) (ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.19.5)(PORT = 22)) (ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.19.5)(PORT = 23)) ) (CONNECT_DATA = (SERVICE_NAME = oltp7) ( server = dedicated ) # (failover_mode=(type=select)(method=basic) ) ) )
aq_ha_notifications => true,이것을 꼭 써야한다. 그래야 빠르게 장애가 난 것을 알릴 수 있음.
원래 taf 안쓰면 자동으로 상대편 노드로 넘어가지 않는데, FAN기능을 썼기때문에 넘어간다.
✔️ sqldeveloper 에서 oltp7로 접속한 후에 내가 접속한 노드를 다운 시키고 잘 넘어가는지 확인해보기select instance_name from v$instance; $ ps -ef | grep ons
📖 9장. 클러스터 관리
💡 RAC 설치할 때 제일 처음에 grid를 설치하는데 grid를 설치하게 되면 클러스터와 ASM이 같이 설치됩니다.
: 우리 19c rac 설치할 때 ASM에 설치가 된다. 그런데 현업에서는 RAW DEVICE로 쓴다. 잘 안깨져서!
⭐ TIP : 오라클 RAC 설치하면 처음에는 무조건 ASM에 구성이 되지만 나중에 다시 RAW DEVICE로 변경해줍니다. 또는 DBCA로 DB 생성 안하고 처음부터 create database로 생성해서 raw device로 구성합니다.
GRID 설치시 voting disk와 ocr file 구성하는 부분이 있는데 이 2개가 ASM에 만들어집니다. 그래서 전부 raw device로 구성하고 싶어서 설치 후에 voting disk와 ocr file을 ASM에서 raw device로 뺍니다!
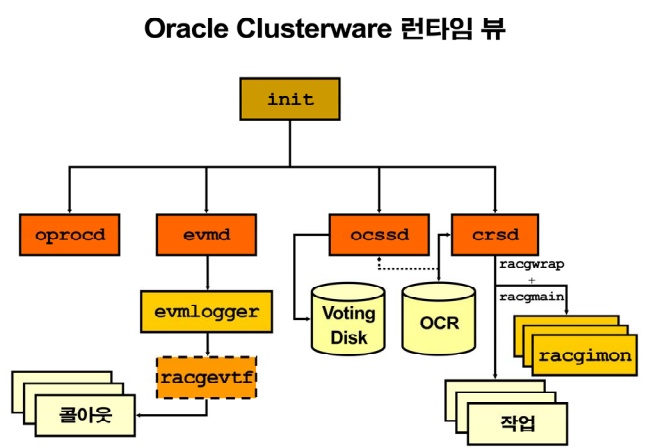
❓ 오라클 클러스터 소프트웨어가 하는 정확한 역할?
1. 응용 프로그램들을 실시간 모니터링 하고 있다가 응용 프로그램들이 비정상적으로 죽으면 다시 살려내는 기능
2. 만약 못살려내면 다른 노드에 failover 시킵니다.
❓ 클러스터 데몬 프로세서들의 역할
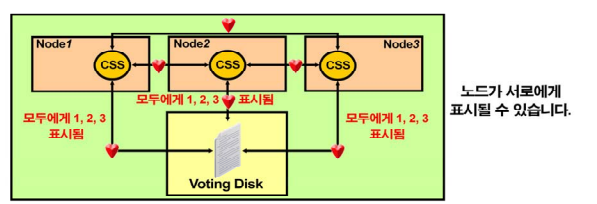
1. css (cluster syncronyation service)
: heartbeat 메커니즘을 이용해서 클러스터 노드를 모니터링 하여 노드간의 공유 자원의 정합성이 깨지는 현상을 방지 하기 위한 모듈!
➡️ css 데몬이 상대편 노드로 계속 심장박동 신호를 보내서 내가 살아있음을 알린다!voting disk에 심장 박동 주기를 어떻게 할지에 대한 정보가 들어있다.[oracle@racdb1 ~]$ ps -ef | grep ocssd grid 3611 1 0 15:22 ? 00:00:06 /u01/app/11.2.0/grid/bin/ocssd.bin oracle 5287 5244 0 15:53 pts/0 00:00:00 grep ocssd
2. crs (cluster ready service)
: 고가용성을 보장하기 위한 모듈
관련 데몬 -crsd<- 고가용성을 보장하기 위한 액션을 수행하는 데몬이다!ex) 1번 노드에 ora.rac1.vip가 떠있는데 1번 노드를 다운 시키면, 이 ora.rac1.vip를 번 노드로 failover 시켜주는 데몬이 crsd입니다.✅ crsd가 사용하는 ocr 파일 안에는(위 사진 참고) rac응용 프로그램에 대한 클러스터 정보가 들어있다!
실습.
1. vip가 1번 노드와 2번 노드에 각각 떠있는지 확인하기$ crs_stat -t ora.rac1.vip ora....t1.type ONLINE ONLINE rac1 ora.rac2.vip ora....t1.type ONLINE ONLINE rac22. 1번 노드를 root 유저에서 reboot 하기!
3. 2번 노드에 아래와 같이 뜨는지 확인$ crs_stat -t ora.rac1.vip ora....t1.type ONLINE ONLINE rac2 ora.rac2.vip ora....t1.type ONLINE ONLINE rac2
4. 2번 노드에서 crs_stop -all 하고 crs_start -all 하기!
3. evm(event manager service)
: 특정 이벤트가 발생했을 때 특정 action을 수행하는 모듈
관련 데몬 -evmd(특정 이벤트가 발생했을 때 특정 action 스크립트를 시작시키는 데몬)💡 클러스터 서비스의 가장 핵심 데몬 3개가 정상인지 확인하는 명령어
: 아래처럼 4개가 다 온라인으로 떠야 정상이다. 1,2번노드에서 각각 수행하면 됨$ crsctl check crs CRS-4638: Oracle High Availability Services is online -- ocssd CRS-4537: Cluster Ready Services is online -- ocrsd CRS-4529: Cluster Synchronization Services is online -- ocssd CRS-4533: Event Manager is online -- evmd

✔️ 명령어들 !
✍🏻 모든 노드를 전부 내렸다가 올리는 명령어
$ crs_stop -all
$ crs_start -all✍🏻 특정 노드만 내렸다가 올리는 명령어
crsctl stop crs
crsctl start crs✍🏻 서버를 reboot 하면 자동으로 클러스터가 올라오는데, 자동으로 클러스터를 못올라오게 하는 명령어
$ crsctl disable crs✔️ voting disk의 역할 및 관리 방법
💡 voting disk란 split brain 현상을 방지 하기 위한 정보가 들어있는 파일
(심장 박동 주기 : misscount, disktimeout)
misscount: 노드간의 심장박동 전달 주기 (30초)disktimeout: 노드와 voting disk 간의 심장박동 전달주기(200초)
실습 voting disk의 위치를 확인하기
[oracle@racdb1 ~]$ crsctl query css votedisk
## STATE File Universal Id File Name Disk group
-- ----- ----------------- --------- ---------
1. ONLINE 86594153f6c64f9bbf209cea79882487 (ORCL:CRS01) [CRS]
2. ONLINE 68ddc20602934f22bfb8441f869fbf00 (ORCL:CRS02) [CRS]
3. ONLINE 8e496277e2b54f8dbf8036df0242090b (ORCL:CRS03) [CRS]
Located 3 voting disk(s).➡️ voting disk는 최소 3개중 2개가 정상이고 1개만 손상되어도 운영이 가능하다. 심지어 3개중에 2개가 손상이고 1개만 정상이어도 운영이 가능함 !
오라클 11gR2 부터 voting disk는 자동 백업이 되어진다. 자동 백업이 되어지는 위치는 다음과 같다.
[oracle@racdb1 ~]$ ocrconfig -showbackup
rac1 2023/11/06 14:10:51 /u01/app/11.2.0/grid/cdata/rac/backup00.ocr
rac2 2023/11/01 16:39:52 /u01/app/11.2.0/grid/cdata/rac/backup01.ocr
rac2 2023/11/01 11:25:45 /u01/app/11.2.0/grid/cdata/rac/backup02.ocr
rac1 2023/11/06 14:10:51 /u01/app/11.2.0/grid/cdata/rac/day.ocr
rac1 2023/10/27 13:51:10 /u01/app/11.2.0/grid/cdata/rac/week.ocr💡 orc 파일과 voting disk의 백업 주기는?
1. 4시간에 한번씩 백업
2. 매일밤 12시에 백업
3. 매주 주말에 백업
오늘의 마지막 문제 오늘 배운 ctf, taf, fan 중에서 ctf를 테스트 하기!
아래의 tnsnames.ora의 내용중 ctf 기능을 지우고 1번 노드를 다운시키고 2번 노드만 가용중인 상태에서 오라클에 scott 유저 접속하면 랜덤으로 1번 노드에 붙을 때 ORA-3113 에러가 나는지 확인하기
racdb3_taf=
(DESCRIPTION =
(address_list=
(load_balance=on)
# (failover=on)
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.19.5)(PORT = 22))
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.19.5)(PORT = 23)) )
(CONNECT_DATA =
(SERVICE_NAME = racdb)
(failover_mode=(type=select)(method=basic) )
)
)