
5장. RAC 환경에서 백업과 복구 하는 방법
✏️ 1. rman으로 database full backup 하기
1. 아카이브 모드인지 확인
SYS @ racdb1 > archive log list Database log mode Archive Mode Automatic archival Enabled Archive destination USE_DB_RECOVERY_FILE_DEST Oldest online log sequence 172 Next log sequence to archive 173 Current log sequence 1732. 알맨 백업본이 저장될 위치인 fast recovery area 영역의 크기 확인
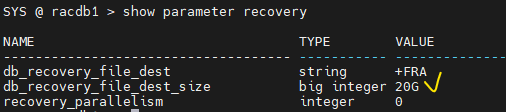
SYS @ racdb1 > show parameter recovery NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ db_recovery_file_dest string +FRA db_recovery_file_dest_size big integer 10G -- 10기가!!! recovery_parallelism integer 03.
db_recovery_file_dest_size를 20G로 늘리기SYS @ racdb1 > alter system set db_recovery_file_dest_size=20G scope=both sid='*';
4. rman으로 접속해서 full backup 하기!$ rman target / nocatalog RMAN> configure controlfile autobackup on; RMAN> backup database;➡️ 아카이브 모드라서 핫백업이 가능하다.
✏️ 2. RAC 환경에서 data file이 깨졌을 때 복구 방법
🚨 RAC 환경에서 복구할 때 주의 사항!!
- 반드시 하나의 인스턴스만 올리고 복구를 해야한다. 복구 하는 노드 외에 다른 노드의 인스턴스는 전부 shutdown 되어 있어야 함!!
- RAC 환경에서는 복구 어드바이져 기능을 못쓴다.
( list failure, advise failure, repail failure)
실습
- ts01 테이블 스페이스는 사이즈 10m로 생성
SYS> create tablespace ts01 datafile '+data' size 10m;
- ts01 테이블 스페이스에 emp 테이블과 같은 emp200 테이블을 생성합니다. (scott)
SCOTT> create table emp200 tablespace ts01 as select * from emp;
- RMAN으로 ts01 테이블 스페이스를 백업합니다.
[oracle@racdb1 ~]$ rman target / nocatalog RMAN> backup tablespace ts01;
- 양쪽 인스턴스를 모두 shutdown abort로 내립니다. (ASM이라서)
SYS @ racdb1 > shutdown abort SYS @ racdb2 > shutdown abort
- asmcmd로 가서 ts01 테이블 스페이스의 datafile을 손상 시킵니다. (grid 유저에서)
$ su - grid $ asmcmd ASMCMD> pwd +data/RACDB/datafile ASMCMD> rm TS01.268.1152273891
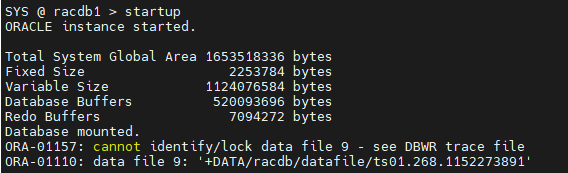
- 1번 인스턴스만 startup 합니다. (에러날것임)
- RMAN으로 접속해서 손상된 파일을 복원합니다.
RMAN> restore datafile 9;
- RMAN으로 접속해서 손상된 파일을 복구합니다.
RMAN> recover datafile 9; RMAN> alter database open;
- 다른 인스턴스를 startup 합니다.
✏️ 3. RAC 환경에서 아카이브 로그 파일 구성
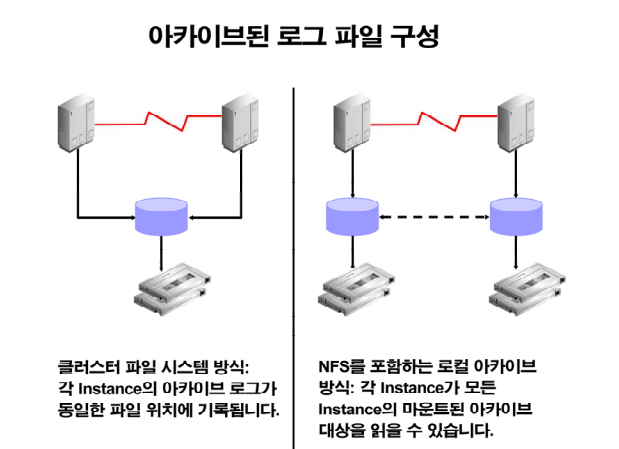
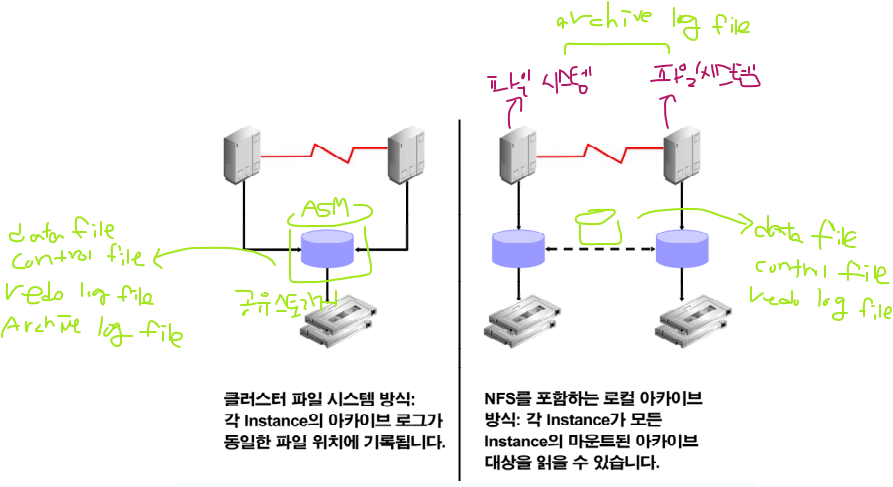
➡️ 왼쪽은 ASM, 클러스터 파일 시스템, 오른쪽은 raw device
SYS @ racdb1 > select name from v$archived_log;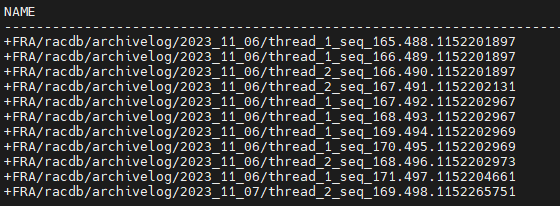
만약 ASM을 공유 스토리지로 사용하고 있다면 아카이브 로그 파일은 ASM 쪽에 생성됩니다.
오라클이 알아서 아카이브 로그 파일의 이름을 생성하고 있습니다. 그러다 보니 아카이브 로그 파일을 raw device에 생성을 할 수 없다!
왜냐하면 raw device는 이미 씨디처럼 이름이 정해져있다.
/raw/raw1/raw11
/raw/raw1/raw12
.
.
.
💡 datafile, controlfile, redo log file 등은 raw device로 구성할 수 있으나, 아카이브 로그 파일은 raw device로 구성을 할 수 없다. 이름 지정을 못하기 때문
- datafile 예시!! -
datafile system tablespace '/raw/raw1/raw11' size 100m
system01.dbf
➡️ 공유 스토리지가 raw device면 공유 스토리지에는 datafile, controlfile, redo logfile을 둘 수 있으나, 아카이브 로그 파일은 각 노드의 파일 시스템에 생성된다!
➡️raw device 환경에서 복구 작업을 할때는 아카이브 로그 파일을 복구를 진행하는 노드로 다 복사해주어야 한다.
➡️ 또는 network file system 을 구성하면 복구 하는 노드에서 다른 노드의 아카이브 로그 파일을 읽을 수 있다!
문제 ts02 tablespace, ts03 tablespace, ts04 tablespace를 각각 10m로 만들고 rman으로 백업하기
1. tablespace 생성
SYS> create tablespace ts02 datafile '+data' size 10m; SYS> create tablespace ts03 datafile '+data' size 10m; SYS> create tablespace ts04 datafile '+data' size 10m;2. rman 백업
[oracle@racdb1 ~]$ rman target / nocatalog RMAN> report need backup; RMAN retention policy will be applied to the command RMAN retention policy is set to redundancy 1 Report of files with less than 1 redundant backups File #bkps Name ---- ----- ----------------------------------------------------- 9 0 +DATA/racdb/datafile/ts02.271.1152281319 10 0 +DATA/racdb/datafile/ts03.272.1152281319 11 0 +DATA/racdb/datafile/ts04.273.1152281319 RMAN> backup tablespace ts02; RMAN> backup tablespace ts03; RMAN> backup tablespace ts04;
문제 양쪽 인스턴스를 모두 shutdown abort 하고 asmcmd로 들어가서 ts02, ts03, ts04 테이블 스페이스와 관련된 datafile들을 모두 삭제하기
$ su - grid
$ asmcmd
ASMCMD> pwd
+data/RACDB/datafile
ASMCMD> rm TS02.272.1152281237
ASMCMD> rm TS03.273.1152281245
ASMCMD> rm TS04.274.1152281253문제 복구하기
한쪽 인스턴스를 startup 한다. (에러날 것)
RMAN으로 들어가서 복원
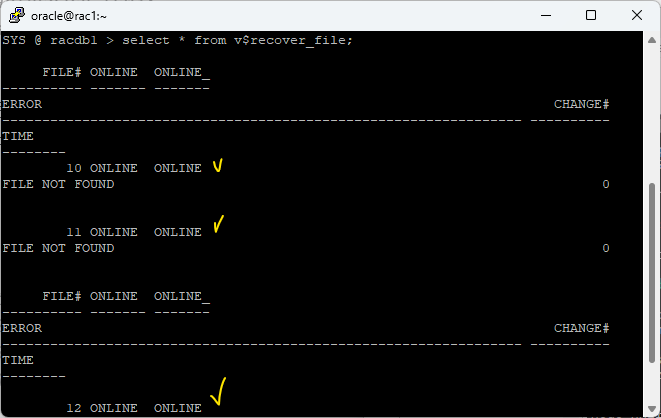
select * from v$recover_file;혹은 얼럿로그 파일 확인RMAN> list failure; -- 안된다 select * from v$recover_file; RMAN> restore datafile 10; RMAN> restore datafile 11; RMAN> restore datafile 12;
- RMAN으로 들어가서 복구 후 디비 올리고, 다른 노드도 디비 올리기
RMAN> recover datafile 10,11,12; RMAN> alter database open;

✏️ 4. RAC 환경에서 불완전 복구
💡 완전 복구를 할 수 있으면 완전 복구를 시도해야 한다. 그런데 완전 복구를 할 수 없는 상황에서만 불완전 복구를 하면 된다. (물어보고 진행해야함)
- 완전복구 : 장애가 발생하기 전 마지막으로 commit한 그 시점으로 복구
- 불완전 복구 : 데이터베이스를 장애가 발생하기 전 과거 특정 시점으로 복구
: 월 화 수 있을 때 만약 화요일 오후 4시에 디비가 깨졌다고 가정하자! 화요일 오후 3시 정도로 불완전 복구를 해주세요! 혹은 오후 12시 정도로 복구해주세요. 나머지 한시간 정도의 DML 작업은 수동으로 작업.
✔️ 둘 다 과거로 db를 되돌리는 복구
1. time base : 과거의 특정 시간으로 복구
2. cancle base : 과거의 특정 시간으로 복구 하는것인데, 주로 current redo log file이 손상 되었거나 redo log file 전체가(디스크가) 모두 손상되었을 때!
문제 rman으로 fullbackup 진행하기
RMAN> backup database;✔️ 1. rac 환경에서 time base 불완전 복구
- 현업에서 빈번하게 일어나는 복구 작업 순위
- block이 손상 되었을 때 복구
- time base 불완전 복구
- controlfile 손상시 복구
실습 time base 불완전 복구
💡 불완전 복구 전에 중요한 작업을 해야한다. /home/oracle/.bash_profile 을 vi 로 열어서 아래의 내용을 맨아래에 추가해야 합니다.
NLS_LANG=american_america.we8iso8859p15
NLS_DATE_FORMAT='RRRR/MM/DD:HH24:MI:SS'
export NLS_LANG
export NLS_DATE_FORMAT
저장하고 나와서
$ source .bash_profile1. 현재 시간을 확인합니다.
: 날짜만 나오면 복구할 수 없다..bashprofile안에SYS @ racdb1 > select sysdate from dual; SYSDATE ------------------- 2023/11/07:14:51:562. 로그 스위치를 2번정도 일으키기 (실습을 위해 작업이 일어나고 있다는 것을 알리기 위해)
SYS @ racdb1 > alter system switch logfile;3. scott user를 drop하기
SYS @ racdb1 > drop user scott cascade;4. 양쪽 인스턴스를 모두 shutdown immediate로 내립니다.
SYS @ racdb1 > shutdown immediate SYS @ racdb2 > shutdown immediate5. 한쪽 인스턴스만 mount로 올리기
SYS @ racdb1 > startup mount6. RMAN으로 접속해서 timebase 불완전 복구를 시도 (1번노드)
RMAN> run { set until time='2023/11/07:14:51:56'; restore database; recover database; alter database open resetlogs; }7. scott으로 접속이 잘 되는지 확인
8. 불완전 복구를 했으니 풀백업 진행RMAN> backup database; RMAN> report obsolete; -- 불필요한 백업 파일들이 보인다. RMAN> delete obsolete; -- 불필요한 파일들을 지운다. SYS @ racdb2 > startup -- 2번 노드 올리기!
✔️ 2. rac 환경에서 cancle base 불완전 복구
1. 로그 스위치를 두번, 체크포인트 한번 일으키기
SYS @ racdb1 > alter system switch logfile; SYS @ racdb1 > alter system checkpoint;2. current redo log 그룹이 무엇인지 확인
SYS @ racdb1 > select group#, sequence#, status, thread# from v$log; GROUP# SEQUENCE# STATUS THREAD# ---------- ---------- ---------------- ---------- 1 3 CURRENT 1 2 2 INACTIVE 1 3 1 INACTIVE 2 4 2 CURRENT 2💡
thread#번호는 어느 인스턴스의 리두 로그 그룹인지를 나타내기 위한 숫자 !
🚨 지금 쓰레드당 2개씩 있는데, 이 상황에서 약간 불안해서 각 쓰레드당 그룹을 하나씩 추가하여 3개로 만들어놓고 진행!!3. 리두 로그 그룹 5번을 1번 인스턴스 용으로 생성하기
SYS @ racdb1 > alter database add logfile thread 1 group 5 ;4. 리두 로그 그룹 6번을 2번 인스턴스 용으로 생성하기
SYS @ racdb1 > alter database add logfile thread 2 group 6 ;5. 로그 스위치 1번, 체크 포인트 1번을 각각의 노드에서 수행
6. 리두 로그 그룹의 상태를 확인SYS @ racdb1 > select group#, sequence#, status, thread# from v$log; GROUP# SEQUENCE# STATUS THREAD# ---------- ---------- ---------------- ---------- 1 3 CURRENT 1 2 2 INACTIVE 1 3 1 INACTIVE 2 4 2 CURRENT 2 5 0 UNUSED 1 6 0 UNUSED 27. 다시 풀백업을 수행 (RMAN) 안해도 괜찮지만 혹시나..!
8. 다시 로그 스위치 1번, 체크 포인트 1번을 각각의 노드에서 일으킨다.
9. (혹시 모르니 수행) 현재 controlfile을 생성하는 스크립트 생성하기SYS> alter database backup controlfile to trace as '/home/oracle/create_control.sql';10. 리두 로그 그룹의 상태 확인
SYS @ racdb1 > select group#, sequence#, status, thread# from v$log; 2 GROUP# SEQUENCE# STATUS THREAD# ---------- ---------- ---------------- ---------- 1 3 INACTIVE 1 2 5 CURRENT 1 -- 1번 노드의 리두로그 그룹은 2번 3 4 INACTIVE 2 4 5 CURRENT 2 5 4 INACTIVE 1 6 3 INACTIVE 211. CURRENT 리두 로그 그룹의 멤버가 무엇인지 확인
SYS> select group#, member from v$logfile; -- 2개가 있다 ! 2 +DATA/racdb/onlinelog/group_2.262.1152284419 2 +FRA/racdb/onlinelog/group_2.258.115228442112. 양쪽 인스턴스를 모두 shutdown immediate로 내린다.
13. asmcmd로 접속해서 current 리두 로그 그룹의 멤버를 모두 삭제
$ su - grid $ asmcmd -- database 쪽 ASMCMD> pwd +data/RACDB/onlinelog ASMCMD> rm group_2.262.1152284419 -- fra쪽 ASMCMD> pwd +fra/RACDB/onlinelog ASMCMD> ls ASMCMD> rm group_2.258.115228442114. 1번 인스턴스를 startup
SYS @ racdb1 > startup ORACLE instance started. Total System Global Area 1653518336 bytes Fixed Size 2253784 bytes Variable Size 1124076584 bytes Database Buffers 520093696 bytes Redo Buffers 7094272 bytes Database mounted. ORA-00313: open failed for members of log group 2 of thread 1 ORA-00312: online log 2 thread 1: '+FRA/racdb/onlinelog/group_2.258.1152284421' ORA-17503: ksfdopn:2 Failed to open file +FRA/racdb/onlinelog/group_2.258.1152284421 ORA-15012: ASM file '+FRA/racdb/onlinelog/group_2.258.1152284421' does not exist ORA-00312: online log 2 thread 1: '+DATA/racdb/onlinelog/group_2.262.1152284419' ORA-17503: ksfdopn:2 Failed to open file +DATA/racdb/onlinelog/group_2.262.1152284419 ORA-15012: ASM file '+DATA/racdb/onlinelog/group_2.262.1152284419' does not exist15. RMAN으로 접속해서 불완전복구한 이력 정보와 현재 incarnation 번호를 확인
: incarnation (reset되어 새롭게 태어난 db..! redo log file이 초기화 된 것)RMAN> list incarnation; List of Database Incarnations DB Key Inc Key DB Name DB ID STATUS Reset SCN Reset Time ------- ------- -------- ---------------- --- ---------- ---------- 1 1 RACDB 1148479398 PARENT 925702 2023/10/22:04:03:53 -- RAC 처음 이미지의 원본 2 2 RACDB 1148479398 CURRENT 22270205 2023/11/07:15:00:16 -- 타임베이스 불완전 복구 한 이후의 디비 -- 현재 상태가 마지막꺼 ! Inc Key 잘 기억하기. 2번 !16. RMAN에서 incarnation 번호 2번으로 다음과 같이 database를 reset합니다.
RMAN> reset database to incarnation 2;
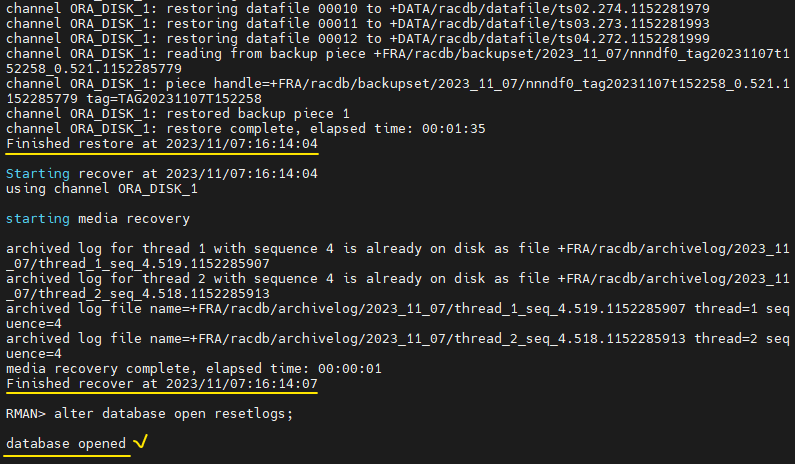
-- reset 하기 전에 다른 푸티창 열어서 현재 상태를 확인했는데 아까는 그룹2번이 CURRENT 였는데, -- 지금은 INACTIVE 이다. 이럴경우 그냥 불완전 복구 안하고 그룹 drop 하고 오픈하면 된다. SYS @ racdb1 > select group#, sequence#, status, thread# from v$log; GROUP# SEQUENCE# STATUS THREAD# ---------- ---------- ---------------- ---------- 5 4 INACTIVE 1 2 5 INACTIVE 1 1 3 INACTIVE 1 4 5 CURRENT 2 6 3 INACTIVE 2 3 4 INACTIVE 2 -- 근데 다시 보니 바뀐게 아니라 CURRENT가 없어진거라 불완전 복구 진행 RMAN> run { set until sequence 5 thread 1; restore database; recover database; } RMAN> alter database open resetlogs;
17. 다른 인스턴스(2번) startup
18. fullbackup 수행
🚨 RMAN을 빠져나갔다가 다시 들어와서 해야함!! reset 된 새로운 db로 해야하기 때문임!!!
RMAN> backup database; Starting Control File and SPFILE Autobackup at 2023/11/07:16:21:09 piece handle=+FRA/racdb/autobackup/2023_11_07/s_1152289269.506.1152289271 comment=NONE Finished Control File and SPFILE Autobackup at 2023/11/07:16:21:12❓ 혹시 백업이 실패했다면 report obsolete, delete obsolete ! 그래도 실패한다면 delete backup

✏️ 5. RAC 환경에서 controlfile 복구하기
오늘의 마지막 문제
- DB ID(데이터베이스 번호)를 조회합니다. (rman 백업 복원시 필요)
SYS @ racdb1 > select dbid from v$database; DBID ---------- 1148479398
- RMAN으로 controlfile을 백업하기 (혹시 실패할까봐)
RMAN> configure controlfile autobackup on; RMAN> backup datafile 1; Starting Control File and SPFILE Autobackup at 2023/11/07:16:32:38 piece handle=+FRA/racdb/autobackup/2023_11_07/s_1152289958.509.1152289961 comment=NONE Finished Control File and SPFILE Autobackup at 2023/11/07:16:32:41
- controlfile을 생성하는 스크립트를 생성하기 (혹시 실패할까봐)
SYS> alter database backup controlfile to trace as '/home/oracle/create_control2.sql';
- controlfile의 위치를 확인
SYS> select * from v$controlfile; +DATA/racdb/controlfile/current.260.1150862631 +FRA/racdb/controlfile/current.256.1150862631
- 양쪽 인스턴스를 모두 shutdown immediate 하기
- asmcmd에서 controlfile을 전부 삭제
[oracle@racdb1 ~]$ su - grid 암호: [grid@+ASM1 ~]$ asmcmd ASMCMD> pwd +data/RACDB/CONTROLFILE ASMCMD> rm Current.260.1150862631 ASMCMD> pwd +fra/RACDB/CONTROLFILE ASMCMD> rm Current.256.1150862631
- 한쪽 인스턴스만 startup 하기
SYS @ racdb1 > startup ORA-00205: error in identifying control file, check alert log for more info
- RMAN으로 접속해서 DB ID를 설정하기 (⭐ RAC 환경에서 다른 점)
RMAN> set dbid=1148479398; executing command: SET DBID
- autobackup 받은 알맨 백업본을 복원하기
RMAN> restore controlfile from autobackup;
- alter database mount 하기
RMAN> alter database mount;
- RMAN에서 recover database로 db를 복구하기
RMAN> recover database;
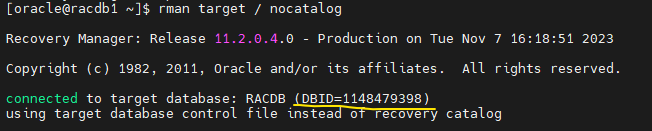
- alter database open resetlogs;
RMAN> alter database open resetlogs;
12. 다른 인스턴스(2번)을 올린다.
13. 다시 fullbackup을 수행!RMAN> backup database;
⭐ 내일 RAC 수업 후에 workshop2 이미지로 SQL 튜닝 수업 할거임! 필요하면 11gWS2.ova 이거 공유폴더에서 가져가기
✏️ 6. RAC 환경에서 parameter file 복구
실습
- db id를 조회
SYS> select dbid from v$database;
- parameter file을 백업합니다
RMAN> configure controlfile autobackup on; RMAN> backup datafile 2; -- 아까 dbid 조회 안했어서 알맨 로그인할때 뜨는 것 확인함 connected to target database: RACDB (DBID=1148479398)➡️
configure controlfile autobackup on;수행 후 아무런 파일이나 백업을 받으면, 파라미터 파일이 자동으로 컨트롤 파일과 함께 백업이 되어진다.
2. parameter file을 삭제합니다SYS> show parameter spfile; -- 위치확인 NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ spfile string +DATA/racdb/spfileracdb.ora [oracle@racdb1 ~]$ su - grid [grid@+ASM1 ~]$ asmcmd ASMCMD> cd +DATA/racdb/ ASMCMD> rm spfileracdb.ora -- spfile 지우기3. 양쪽 인스턴스를 내립니다. (shutdown immediate)
4. 한쪽 인스턴스만 startup 합니다.SYS @ racdb1 > startup ORA-01078: failure in processing system parameters ORA-01565: error in identifying file '+DATA/racdb/spfileracdb.ora' ORA-17503: ksfdopn:2 Failed to open file +DATA/racdb/spfileracdb.ora ORA-15056: additional error message ORA-17503: ksfdopn:2 Failed to open file +DATA/racdb/spfileracdb.ora ORA-15173: entry 'spfileracdb.ora' does not exist in directory 'racdb' ORA-06512: at line 45. rman에서 파라미터 파일을 복원합니다.
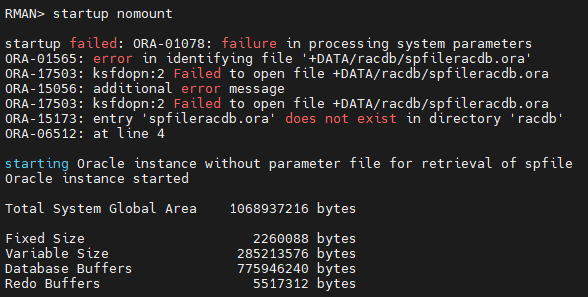
RMAN> startup nomount -- 파라미터 파일이 없지만 알맨이 가상으로 올린다.
RMAN> set dbid=1148479398 RMAN> restore spfile from autobackup; channel ORA_DISK_1: no AUTOBACKUP in 7 days found RMAN-00571: =========================================================== RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS =============== RMAN-00571: =========================================================== RMAN-03002: failure of restore command at 11/08/2023 10:02:07 RMAN-06172: no AUTOBACKUP found or specified handle is not a valid copy or piece -- 위에서 백업받은적이 없다고 나와서 그리드로 가서 위치를 찾으러 간다. su - grid ASMCMD> pwd +fra/racdb/autobackup/2023_11_08 ASMCMD> ls s_1152352136.496.1152352139 -- autobackup 본이 있는 위치를 직접 지정해준다. RMAN> restore spfile from '+fra/racdb/autobackup/2023_11_08/s_1152352136.496.1152352139';
6. 각각의 노드를 startup 시킵니다.-- startup 되어서 dbid 확인했다. SYS @ racdb1 > select dbid from v$database; DBID ---------- 1148479398
🚨 RAC 환경에서의 db 복구시 주의 사항 2가지
- 모든 인스턴스를 내리고 하나의 인스턴스만 올리고 복구해야한다.
- 아카이브 로그파일이 공유 폴더에 없다면 복구하는 노드의 파일 시스템에 모든아카이브 로그 파일이 엑세스가 되어야 한다.
