
📖 1장. 오라클 데이터 베이스 구조와 탐색
✍🏻 정리
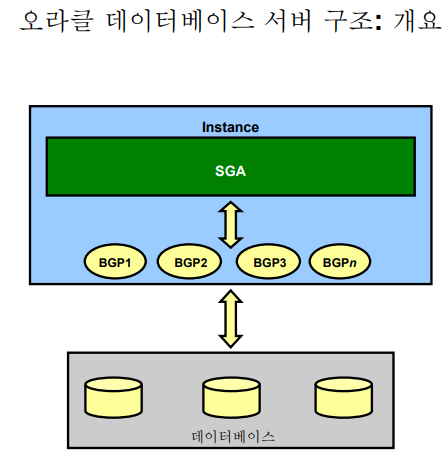
💡 오라클 아키텍쳐 구조는 데이터 베이스와 인스턴스로 구성되어있는데, 인스턴스는 SGA와 백그라운드 프로세서들로 구성되어있다.
💡 인스턴스(instance,즉시)는 데이터베이스에서 액세스한 데이터를 저장하고 있는 오라클 메모리인데 오라클을 사용하는 사용자들이 데이터를 빠르게 엑세스 할 수 있도록 데이터를 저장하는 메모리영역이다.
💡 SGA는 system global area의 약자로 SQL과 DB에서 읽은 데이터를 저장하는 메모리 이다.
💡 백그라운드 프로세서들의 역할은 무엇이냐면 SGA와 DB간의 데이터 교류를 하는 역할을 한다. SGA의 내용을 데이터베이스에 반영하도록 작동하는 프로세서.
💡 백그라운드 프로세서들 중 대표적인게 뭐가 있냐면 DBWR, LGWR, CKPT, SMON, PMON 등이 있다.
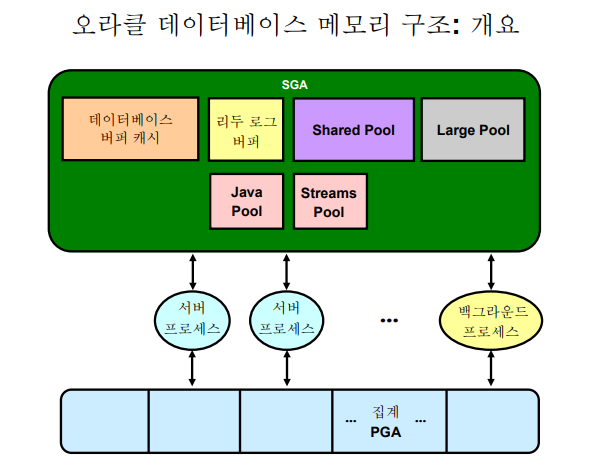
💡 오라클 메모리 구조는 SGA, PGA 두가지로 나뉜다.
💡 SGA는 shared global area로 여러 프로세서들이 공유해서 사용하는 메모리 영역
💡 PGA는 private global area 특정 프로세서가 정렬과 같은 작업을 위해 개별적으로 사용하는 메모리 영역
💡 데이터 베이스 버퍼 캐시에 있는 더티 버퍼를 data file로 내려쓰는 백그라운드 프로세스는 DBWR 임
💡 리두 로그 버퍼는 DML문이나 DDL문처럼 데이터베이스에서 수행한 변경 사항에 대한 데이터를 기록하는 메모리 영역! (redo!다시하다. 다시 작업하다 log이력)
💡 Shared Pool 영역은 SQL과 PL/SQL을 파싱한 결과물이 저장되고 공유되는 영역!
: 파싱한 결과물 ➡️ 라이브러리 캐시에 올라간다.
(1. SQL, PL/SQL 코드 | 2. SQL, PL/SQL Parse tree (SQL->기계어) | 3. 실행계획)
💡 Large Pool은 병렬 쿼리문을 수행했을 때 병렬 작업을 위한 오라클 메모리 영역이다. RMAN으로 백업과 복구를 할 때 사용되는 메모리영역이다! 또shared server 구조에서 사용되는 메모리 영역
💡 PGA 메모리 영역은 서버 프로세서가 개별적으로 사용하는 메모리 영역이다. 이 영역에서 데이터 정렬작업을 수행하고 HASH JOIN을 할 때 사용하는 메모리 영역1. parsing : SQL을 기계어로 변환하고 실행계획을 생성하는 단계 2. execute : 실행계획대로 SQL을 실행해서 datafile과 buffer cache에서 결과 데이터를 찾음 만약 찾는 데이터가 버퍼 캐시에 있으면 바로 fetch, 없다면 datafile에서 읽어서 buffer cache에 복사본 올리고 fetch! 3. fetch : server process -> user process 에게 결과데이터 전달 1) select max(sal) from emp; -- 결과가 하나이다. 패치 한번 이루어짐 2) select * from sh.sales; -- 결과가 여러가지다. 패치가 여러번 일어난다.⭐💡 update 문 처리과정
1. parsing 2. execute
✏️ 데이터 베이스 Instance에 연결
- 그냥 접속하는 문법
$ sqlplus scott/tiger@192.168.56.1:1521/xe- 리스너를 통해 접속하는 방법 (load ballancing, ctf, taf를 이용하면서 접속하는 문법)
$ sqlplus scott/tiger@rac_taf 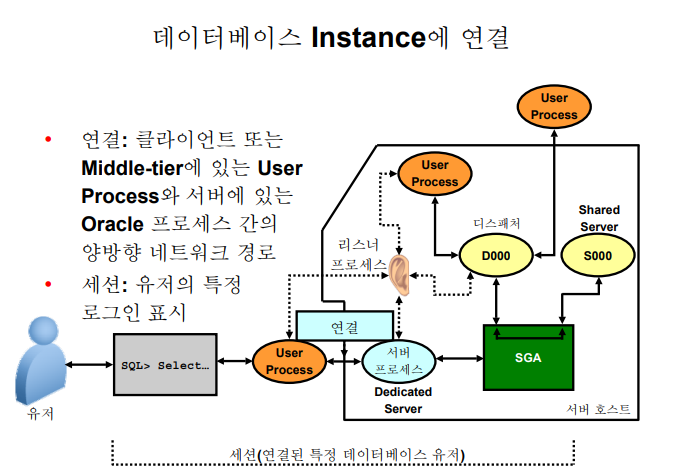
💡 오라클에서 유저프로세스가 서버 프로세서를 할당 받는 방식 2가지
1. dedicated server process : 유저 프로세서 하나당 서버 프로세서 하나
2. shared server process : 유저 프로세서가 수행한 SQL을 여러 공유 서버 프로세서들 중에 한가한 서버 프로세서가 수행해준다.
: 대체적으로 dedicated server process 지만 쿠팡이나 이런곳은 유저 프로세서가 굉장히 많으므로 shared server process로 한다.
실습1. 지금 현재 오라클 데이터 베이스에 떠있는 서버 프로세서들이 어떤게 있는지 확인하기
-- 백그라운드 프로세서만 보기
select * from v$process where background=1;
-- 백그라운드 프로세서가 아닌 프로세서들을 보려면
select * from v$process where background is null;
💡 내가 접속한 sqldeveloper에 해당하는 서버 프로세서를 알고 싶다면 spid를 조회해보자.
select s.sid, s.serial#, p.spid
from v$session s, v$process p
where
s.sid = (select sid from v$mystat where rownum = 1)
and s.paddr = p.addr
144 868308
select * from v$process where spid=8308;
-- 위에서 확인한 spid를 가지고 리눅스에서 프로세서를 확인합니다.
oracle 8308 1 0 09:48 ? 00:00:01 oracleorcl2 (LOCAL=NO)
oracle 8935 8148 0 10:22 pts/1 00:00:00 grep 8308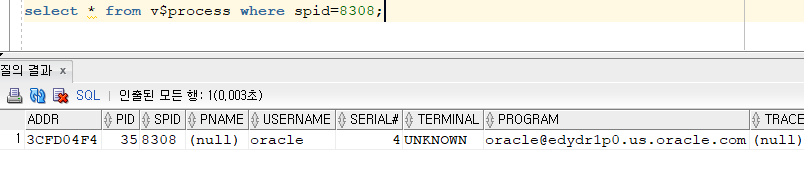
➡️ 악성 SQL을 돌리는 유저를 kill 시킬때 유용
✏️ 데이터베이스 버퍼 캐시
💡 데이터 파일에서 읽은 데이터 블럭의 복사본을 보관하는 곳
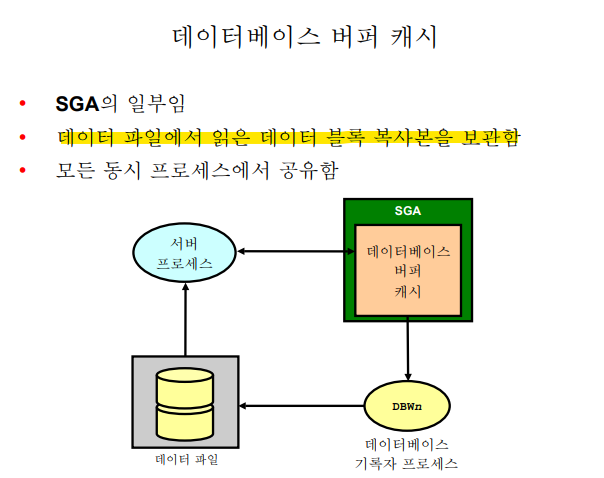
실습1. DBWR 백그라운드 프로세서의 SPID를 알아내보기
select *
from v$process
where program like '%DBW%';
-- 5411
[orcl2:~]$ ps -ef | grep 5411
oracle 5411 1 0 08:52 ? 00:00:00 ora_dbw0_orcl2
oracle 9484 8148 0 10:58 pts/1 00:00:00 grep 5411 ✏️ 리두 로그 버퍼
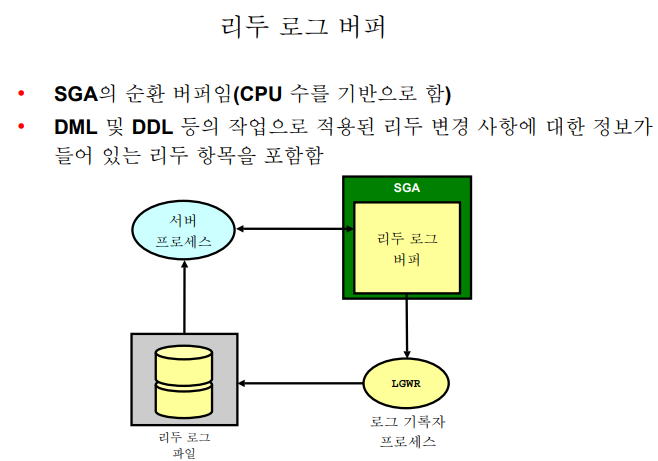
➡️ 서버프로세스가 리두로그 버퍼에 쓰고 LGWR가 리두로그 파일로 내려쓴다.
실습1. 리두 로그 버퍼의 크기를 확인하기
SYS @ orcl2 > show parameter log_buffer NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ log_buffer integer 5758976 SYS @ orcl2 > select 5758976/1024/1024 from dual; 5758976/1024/1024 ----------------- 5.4921875 -- 5기가
✏️ Shared Pool
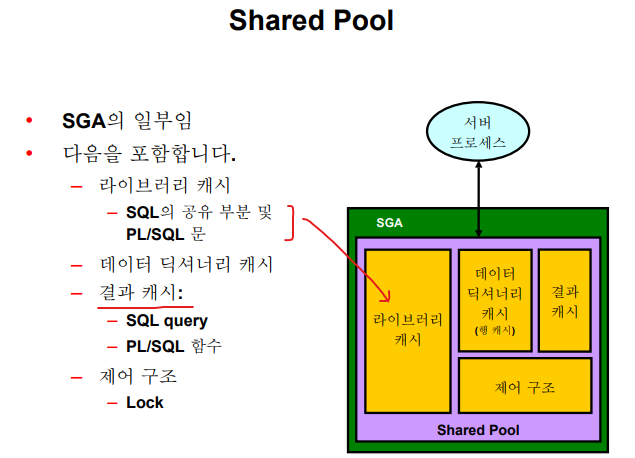
결과 캐시는 특정 SQL의 결과를 빠르게 보기 위해 결과캐시에 올려놓으면 두번째부터 빠른 속도로 볼 수 있다. SQL 튜닝에서 중요한 부분
💡 Shared Pool 영역은 SQL과 PL/SQL을 파싱한 결과물이 저장되고 공유되는 영역!
✔️ 라이브러리 캐시 영역에서 공유되는 것들 (파싱한 결과물)
1. SQL, PL/SQL 코드
2. SQL, PL/SQL Parse tree (SQL->기계어)
3. 실행계획✔️ 데이터 딕셔너리 캐시에 공유되는 것들
select ename, sal from emp where ename='SCOTT';➡️ 이 SQL을 실행할 때 emp 테이블이 과연 db에 있는 테이블인지 먼저 데이터 딕셔너리를 오라클이 아래처럼 조회해본다. 그리고 emp 테이블이 db에 존재한다 라는 정보를 데이터 딕셔너리 캐시에 캐쉬시키고 다음에 재활용한다. (데이터 딕셔너리 캐시의 역할)
select table_name, owner from dba_tables where table_name='EMP';✔️ result cache 결과 캐쉬란 ⭐
: 일반적으로는 한번 수행한 sql은 오라클 메모리의 라이브러리 캐쉬에 올라가는데, 그 결과 데이터는 라이브러리 캐쉬에 안올라간다. SQL만 올리고 결과는 올리지 않는다는 말!SCOTT> select /*+ result_cache */ ename, sal from emp where ename='SCOTT';➡️ 힌트를 사용하면 결과가 result cache로 들어간다. 그러면 다음에 또 같은것을 조회했을 때 빠르게 나온다. 자주보고 중요한 데이터는 result cache에 올려놓고 다음에 빠르게 액세스 할 수 있게 한다.
➡️ 힌트를 쓰지 않으면 (일반적으로는) 데이터 값을 찾으러 버퍼캐쉬로 간다.
✏️ DML문 처리 과정
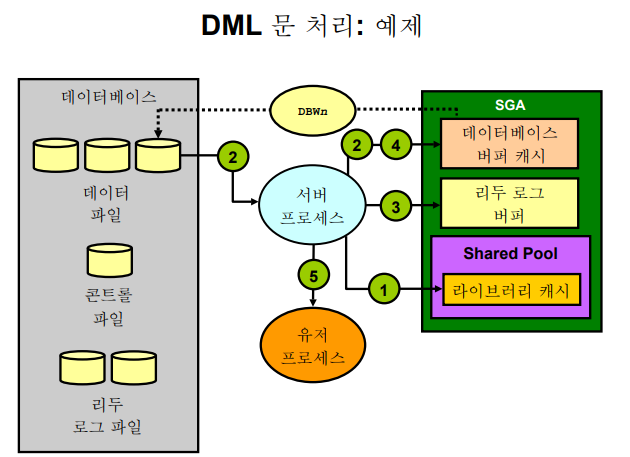
💡 select 문 처리과정
1. parsing : SQL을 기계어로 변환하고 실행계획을 생성하는 단계
2. execute : 실행계획대로 SQL을 실행해서 datafile과 buffer cache에서 결과 데이터를 찾음
만약 찾는 데이터가 버퍼 캐시에 있으면 바로 fetch, 없다면 datafile에서 읽어서 buffer cache에 복사본
올리고 fetch!
3. fetch : server process -> user process 에게 결과데이터 전달
1) select max(sal) from emp; -- 결과가 하나이다. 패치 한번 이루어짐
2) select * from sh.sales; -- 결과가 여러가지다. 패치가 여러번 일어난다. 💡 update 문 처리과정
update emp set sal = 0 where ename = 'ALLEN';1. parsing
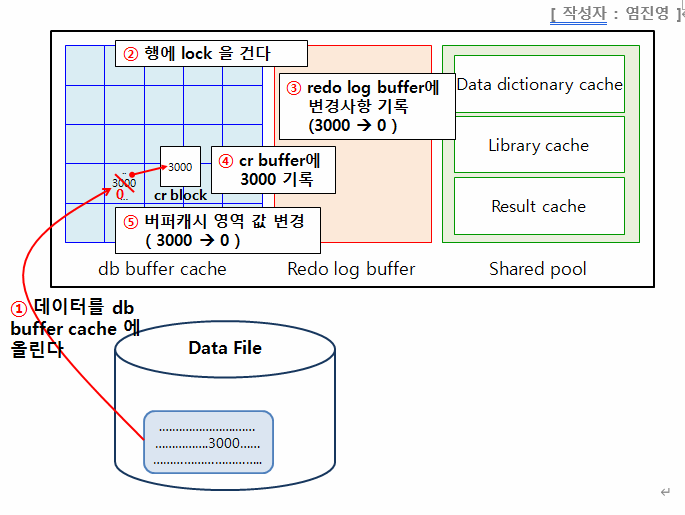
그림1.: shared pool에 똑같은 update 문장이 있는지 찾아본다. 만약 똑같은 update문이 있다면 parsing 과정을 생략한다. 만약 없다면 공유풀에 빈 공간을 확보(latch잡기) 하고 parsing을 수행한다. 그리고 결과물을 공유풀에 올린다.
❗ 파싱된 결과물 중에 실행 계획이 있다.2. execute
그림2.: 만약 update 하려는 데이터가 데이터베이스 버퍼 캐쉬에 있으면 바로 update를 수행하고, 없다면 datafile에서 읽어서 buffer cache에 올린다.
update하려는 행을 잠군다.(lock)
그림3.: update를 수행하기 전에 수정전 데이터를 undo buffer(cr buffer)에 기록한다. 리두로그 버퍼에는 update를 하겠다는 update문을 기록한다.
그림4.: 수정전 데이터 -> 수정 후 데이터로 변경한다.
그림5.: 서버 프로세서가 유저 프로세서에게 update가 잘 되었다고 알려준다.
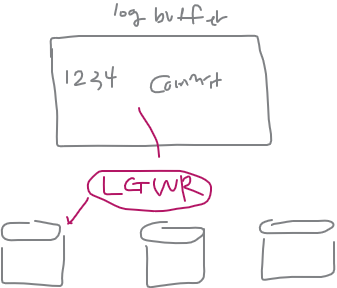
💡 commit의 처리과정
그림1.사용자가 commit을 하면 서버 프로세서가 scn 번호와 함께 commit 레코드를 리두 로그 버퍼에 기록한다.ex) 2605191 commit;
그림2.리두로그 버퍼에 기록된 리두 엔트리(entry)를 redo log file에 내려씁니다.
그림3.commit 잘 했다고 알려줍니다.
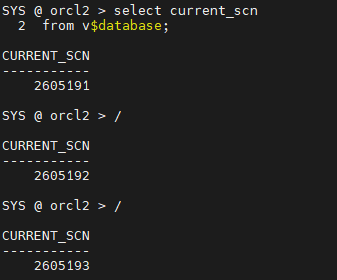
❓ scn번호? : system change number 의 약자. db올라온 이후로 중복 되는 것 없다.
✏️ Large Pool
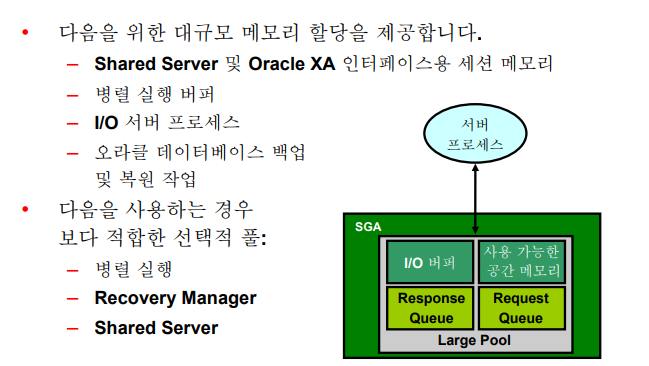
💡 shared server에서는 PGA 영역의 많은 부분이 Large Pool안으로 들어온다.
: 식당이라고 생각하면 된다. 서버프로세서 들이 서로 공유해야 하기 때문에 개별메모리 영역에 있으면 안된다. 그래서 shared server 일때는 라지풀을 크게 잡아주어야 한다.
실습1. 현재 large pool의 사이즈가 어떻게 되는지 확인하기
: 병렬 쿼리문을 조금 더 빠르게 수행되게 할 수 있는 방법은 없나요? -> large pool을 늘리고 병렬도를 넉넉히 주세요!
select /*+ parallel(e,4) */ ename, sal
from emp e;-- 조회해보기
PROMPT *** CURRENT parameter settings ***
col name format a12
col VALUE format a8
SHOW parameter sga_
PROMPT
PROMPT *** SGA Dynamic Component SIZE Information***
col component format a22
col current_size format a15
col min_size format a15
-- 이것만 sqldeveloper에서 돌림
SELECT component,current_size/1048576||'M' current_size,
min_size/1048576||'M' min_size
FROM v$sga_dynamic_components
WHERE component IN ('shared pool','large pool',
'java pool','DEFAULT buffer cache');
col name format a20
col VALUE format a20
PROMPT *** CURRENT parameter settings IN V$PARAMETER ***
SELECT name, VALUE, isdefault
FROM v$parameter
WHERE name IN ('shared_pool_size','large_pool_size',
'java_pool_size', 'db_cache_size'); 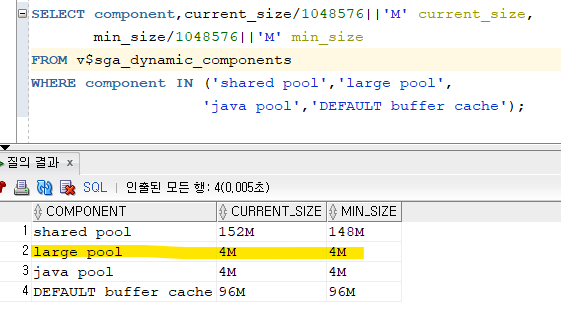
➡️ 4m로 셋팅되어져 있지만 자동으로 관리되고 있다.
문제 30m로 large pool size 늘리기
SYS @ orcl2 > select name, issys_modifiable from v$parameter where name like '%&name%' ; Enter value for name: large old 3: where name like '%&name%' new 3: where name like '%large%' NAME -------------------------------------------------------------------------------- ISSYS_MOD --------- large_pool_size IMMEDIATE SYS> alter system set large_pool_size=30m scope=both ;
❓ 30m가 아니라 32m로 늘어난 이유는, 청크(chunk) 단위 배수로 늘어나기 때문에!

✏️ Java Pool과 Streams Pool
1. Java Pool
OUI (oracle user interface)를 이용해서 오라클 설치를 했었는데 그때 OUI가 자바로 만든 인터페이스라서 OUI를 실행하면 자바풀이 사용이 됩니다. JAVA 코드를 오라클에서 실행하려면 역시 자바풀 메모리가 확보되어야 한다. 긴 자바 코드가 compile이 안된다고 연락이 온다면 java pool을 늘려주면 된다.

실습1. java pool 영역의 크기를 확인
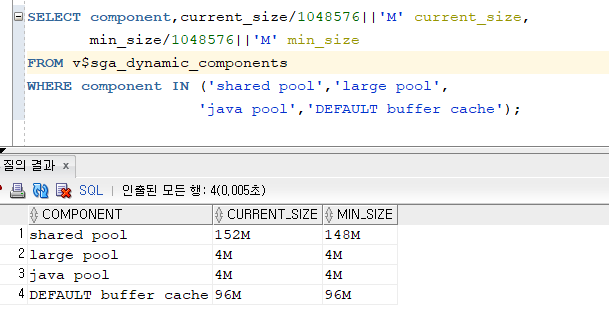
NAME ISSYS_MOD
------------------------------ ---------
java_pool_size IMMEDIATE
java_soft_sessionspace_limit FALSE
java_max_sessionspace_size FALSE
java_jit_enabled IMMEDIATE
SYS> alter system set java_pool_size=10m scope=both;
✔️ 오라클에서 수행해야할 자바 코드
set echo on
DECLARE
i NUMBER;
v_sql VARCHAR2(200);
BEGIN
FOR i IN 1..200 LOOP
-- Build up a dynamic statement to create a uniquely named java stored proc.
-- The "chr(10)" is there to put a CR/LF in the source code.
v_sql := 'create or replace and compile' || chr(10) ||
'java source named "SmallJavaProc' || i || '"' || chr(10) ||
'as' || chr(10) ||
'import java.lang.*;' || chr(10) ||
'public class Util' || i || ' extends Object' || chr(10) ||
'{ int v1=1;int v2=2;int v3=3;int v4=4;int v5=5;int v6=6;int v7=7; }';
EXECUTE IMMEDIATE v_sql;
END LOOP;
END;
/2. streams pool
데이터 동기화 할때 사용되는 메모리 영역
✏️ PGA 메모리 영역

실습1. PGA 영역이 자동으로 관리되는지 확인하기
SYS @ orcl2 > show parameter pga NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ pga_aggregate_target big integer 354M💡 354m 크기 안에서 오라클 서버 프로세서들이 필요한 만큼 자신의 pga 영역을 사용한다. 254m를 혼자 다 쓸 수 있는건 아니고 할당량이 정해져있다 !!!
유저 프로세서 --------------------------------------> 서버 프로세서 유저 프로세서 --------------------------------------> 서버 프로세서 유저 프로세서 --------------------------------------> 서버 프로세서 유저 프로세서 --------------------------------------> 서버 프로세서 유저 프로세서 --------------------------------------> 서버 프로세서 유저 프로세서 --------------------------------------> 서버 프로세서➡️ 354m룰 6개의 유저프로세스 프로세스 하나동 10m 쓴다고 가정하기! 조금 바쁘면 2번째 프로세서한테 조금 더 줄수 있다.
실습 pga_aggregate_target이라는 파라미터에 의해 pga영역이 자동으로 관리되고 정렬 작업이 필요한 프로세서들에 대해 메모리 관리가 자동화 되었다. 그런데 나는 dba라 오늘밤에 아주 큰 정렬 작업을 해야하는데, 빠르게 끝내고싶다
SYS> show pamaeter workarea_size_policy;
-- 내 세션에서는 수동관리하게따
SYS> alter session set workarea_size_policy = manual;
SYS> alter session set sort_area_size=1000000000; -- 정렬해주는애
SYS> alter session set hash_area_size=100000000;
create index emp_sal
on emp(sal)
parallel 4;
SYS> alter session set workarea_size_policy = auto;
alter index emp_sal parallel 1;✏️ 백그라운드 프로세서의 role
💡 DBWR 는 데이터 베이스 버퍼 캐쉬의 더티(수정된) 버퍼를 데이터 파일에 내려쓰는 프로세서
💡 LGWR 는 리두 로그 버퍼의 내용을 리두 로그 파일에 내려쓰는 프로세서
💡 CKPT 프로세서의 역할은 체크 포인트 이벤트(ckpt->lgwr->dbwr)를 일으키고 checkpoint 정보를 데이터 파일 헤더와 컨트롤파일에 내려쓰는 프로세서 입니다.
❓ 체크 포인트 : 메모리에 있는 내용들을 주기적으로 데이터에 내려쓴다.
💡 PMON 은 유저 프로세서가 비정상적으로 종료 되었을 때 (ex: sqldeveloper가 갑자기 꺼져버렸을 때) recovery를 수행하는 프로세서! 걸려있던 lock도 풀어준다.
# ex) update 후에 commit 하지 않고 비정상적으로 종료되었다면 recovery, lock도 풀어줌
update emp
set sal=0
where ename='SCOTT';💡 MMON 은 오라클 SGA의 메모리 사이즈 관리를 자동으로 조정한다.
✏️ 자동 공유 메모리 관리
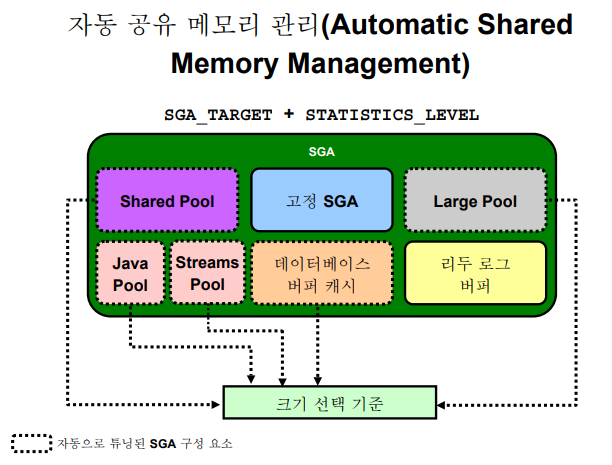
➡️ 그림에 점선으로 나온 메모리 영역의 사이즈가 자동으로 늘었다 줄었다 자동 조정 되는 메모리 영역이다. 실선으로 나온 메모리 영역은 사이즈가 고정되어있고 자동 조정 되지 않는 메모리이다.
💡 자동 공유 메모리 영역을 쓰려면 sga_target 과 statistics_level을 설정해줘야한다.
실습1. statistics_level 파라미터가 어떻게 설정되어있는지 확인
SYS @ orcl2 > show parameter statistics_level;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
statistics_level string TYPICAL➡️ 자동 공유 메모리 영역관리가 되려면 statistics_level을 typical 혹은 all로 설정해야한다.
실습2. sga_target, memory_target이 어떻게 설정되어있는지 확인
SYS @ orcl2 > show parameter sga_target
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
sga_target big integer 0
SYS @ orcl2 > show parameter memory_target;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
memory_target big integer 464M
SYS @ orcl2 > show parameter pga_aggregate_target;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
pga_aggregate_target big integer 0➡️ memory_target = sga_target(SGA) + pga_aggregate_target(PGA)
메모리 타겟 하나만 설정해놓으면 SGA, PGA 영역의 사이즈가 서로 자동으로 조정된다. 낮에는 PGA보다 SGA를 크게 잡고 쓰고있고, 밤에는 SGA보다 PGA를 크게 잡고 쓴다.
MMON, MMAN..?
❓ 오라클 처음 설치했을 때 설정해야 한다.
문제 memory_target parameter를 1500m로 설정하고 sga_target, pga_aggregate_target은 0으로 셋팅하기 !
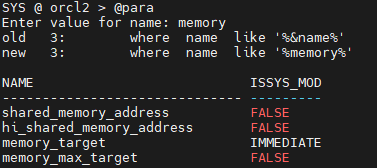
SYS @ orcl2 > alter system set memory_target=1500m scope=both;
alter system set memory_target=1500m scope=both
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid
ORA-00837: Specified value of MEMORY_TARGET greater than MEMORY_MAX_TARGET
-- MEMORY_MAX_TARGET 먼저 바꾸라고 해서 바꿨다.
SYS @ orcl2 > alter system set memory_max_target=1500m scope=spfile; ORACLE instance shut down.
SYS @ orcl2 > startup
ORA-00845: MEMORY_TARGET not supported on this system
-------------------------------------------------------------
# 에러 해결 후
SYS @ orcl2 > alter system set memory_target=1500m scope=both;
SYS @ orcl2 > show parameter memory
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
hi_shared_memory_address integer 0
memory_max_target big integer 1504M
memory_target big integer 1504M
shared_memory_address integer 0
-- pfile로 open 시키기
startup pfile=$ORACLE_HOME/dbs/initorcl2.oraORA-00845: MEMORY_TARGET not supported on this system 해결방법
- tmpfs 현재 용량확인(현재 사용가능 718M)
[orcl2:~]$ df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/VolGroup00-LogVol00 190G 81G 100G 45% / /dev/sda1 99M 18M 76M 20% /boot tmpfs 1.8G 718M 1.1G 41% /dev/shm /dev/hdc 52M 52M 0 100% /media/VBox_GAs_7.0.10_
- 현재 메모리 타겟 확인
$ cd $ORACLE_HOME/dbs vi initorcl2.ora *.memory_target=485832192 -- 485832192를 MB로 환산하면 463MB(485832192를/1024/1024)
- umount 해주고 다시 startup 해주었더니 되었음!
참고한 블로그
✏️ (중요) 논리적 및 물리적 데이터베이스 구조
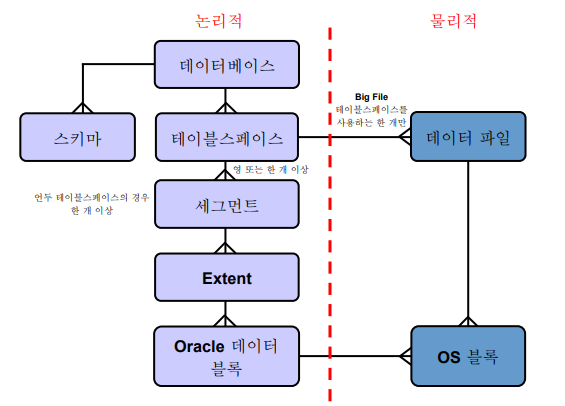
✏️ SYSTEM 및 SYSAUX 테이블스페이스

➡️ system tablespace에는 데이터 딕셔너리 테이블이 들어있고, sysaux tablespace는 EM 정보가 들어있다.
📖 2장. SQL 튜닝
✏️ 1. 비효율적인 SQL 성능 원인

- 오래되거나 누락된 옵티마이저 통계
select ename, sal from emp where sal=1200;➡️ 서버 프로세서가 위의 SQL을 파싱하고 실행계획을 생성하기 위해 emp 테이블에 대한 정보를 확인하는데 emp 테이블에 대한 정보가 옵티마이저 통계정보이다.
select table_name, last_analyzed from user_tables where table_name='EMP'; TABLE_NAME LAST_ANALYZED ------------------------------ ------------------- EMP #비어있다!(누락)emp테이블에 대한 정보가 있어야 옵티마이저가 좋은 실행계획을 낼 수 있는데
LAST_ANALYZED가 비어있으면 통계정보가 없다는 것. 좋은 실행계획을 낼 수 없다!!
