✏️ SQL 튜닝 툴 소개
(p.2-10)

1. ADDM: 오라클 인스턴스의 성능 정보를 수집하고 분석하여 성능 문제 해결방법을 알려주는 성능패키지
2. SQL Tuning Advisor: 성능상에 문제가 있는 SQL에 대한 새로운 실행계획과 적절한 인덱스 생성 스크립트를 알려주는 튜닝 패키지! (유료)예) SQL 프로파일, 인덱스 생성 스크립트, 통계 정보 수집을 권고
3. SQL Tunong Set(SQL Tuning Advisor에서 사용)
4. SQL Accescc Advisor: SQL Tuning Advisor가 튜닝해야할 딱 하나의 SQL만 바라보고 튜닝한다면SQL Accescc Advisor는 db전반적으로 큰 문제가 발생하지 않도록 하면서 성능 개선을 하게 하는 튜닝 패키지이다. 전반적으로 성능상의 문제를 보다 보니 인덱스 생성보다는 Materialize view나 파티션 테이블 생성으로 권고를 한다.새로운 인덱스를 생성하면 인덱스를 생성한 그 SQL은 빨라질 수 있으나 기존의 SQL이 느려질 수 있다. 개발 단계 말고 운영단계에서는 인덱스 생성을 최대한 신중하게 해야함
5. SQL Performance Analyzer: SQL 튜닝 어드바이저와 SQL 액세스 어드바이저는 딱 1개의 SQL만의 성능을 높이는 튜닝방법을 알려준다. 그렇지만SQL Performance Analyzer는 모든 SQL을 다 보고 모든 SQL을 위한 가장 좋은 튜닝 방법을 제시한다.예) DB 업그레이드, DB 패치, 전체 sql을 위한 새로운 인덱스 생성
6. SQL Monitoring: 오라클 데이터베이스에 실시간으로 발생하는 모든 SQL을 모니터링한다. 매일 밤 12시에 하루동안 발생했던 SQL중에서 악성 SQL top10을 정리한다.
SQL 튜닝 어드바이저를 auto 튜닝으로 사용하게 되면 자동으로 악성 SQL top10을 튜닝하고 자동으로 SQL 프로파일을 적용한다. 많은 회사들은 밤 12시에 오라클이 자동으로 SQL 튜닝을 하고 프로파일을 적용하는 기능을 끄고 있다. ( 자율주행 자동차와 같다. 아직 사람이 튜닝하는것이 더 좋음)
7. SQL Plan Management: 밤 10시에 자동으로 SQL 튜닝을 하고 튜닝 후 plan이 튜닝 전 plan 보다 더 좋다면 자동으로 새로운 플랜을 적용하는 기능이다.
실습 매일 밤 10시에 자동으로 오라클에서 일어나는 기능 3가지
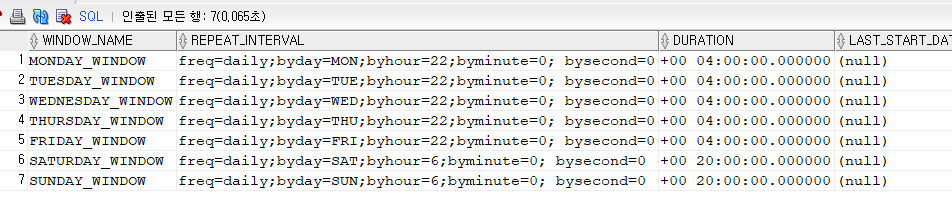
문제1. db 에 있는 테이블에 대해서 매일 밤 10시에 자동으로 통계정보를 수집하는지 확인하시오 !
select w.window_name, w.repeat_interval, w.duration , cast(w.last_start_date as timestamp with local time zone) last_start_date , cast(w.next_start_date as timestamp with local time zone) next_start_date from dba_scheduler_wingroup_members m , dba_scheduler_windows w where m.window_group_name = 'MAINTENANCE_WINDOW_GROUP' and w.window_name = m.window_name; MONDAY_WINDOW freq=daily;byday=MON;byhour=22;byminute=0; bysecond=0 TUESDAY_WINDOW freq=daily;byday=TUE;byhour=22;byminute=0; bysecond=0 WEDNESDAY_WINDOW freq=daily;byday=WED;byhour=22;byminute=0; bysecond=0 THURSDAY_WINDOW freq=daily;byday=THU;byhour=22;byminute=0; bysecond=0 FRIDAY_WINDOW freq=daily;byday=FRI;byhour=22;byminute=0; bysecond=0 SATURDAY_WINDOW freq=daily;byday=SAT;byhour=6;byminute=0; bysecond=0 SUNDAY_WINDOW freq=daily;byday=SUN;byhour=6;byminute=0; bysecond=0
문제2. 매일밤 10시와 주말에 통계정보 수집외에 또 어떤 작업이 수행되고 있는가 ?
select * from dba_scheduler_wingroup_members where window_group_name='MAINTENANCE_WINDOW_GROUP';
select window_name, repeat_interval, duration from dba_scheduler_windows where window_name in ('WEEKNIGHT_WINDOW','WEEKEND_WINDOW');
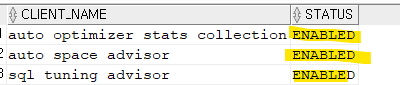
select client_name, status from dba_autotask_client; auto optimizer stats collection ENABLED -- 매일밤 10시에 통계정보 수집 자동 auto space advisor ENABLED -- 디스크 공간 조각 모음 기능 자동 sql tuning advisor ENABLED -- 매일밤 10시 악성 SQL 튜닝 자동
➡️ 거의 꺼져있을 것이다. 켜져있다면 모르는 것 일거나.. 용감하신 분..! 혹은 굉장히 능력있으신분. 큰회사일것. 오라클에서는 켜라고 하지만 문제가 생겼거나 문제가 생길까봐 꺼놓은 것이다.


문제3. 위의 기능중 통계정보 수집기능을 끄시오 ~
begin
dbms_auto_task_admin.disable(
client_name =>'sql tuning advisor',
operation => null,
window_name => null );
end;
/
문제4. 나머지 자동 통계정보 수집과 auto space advisor 기능도 끄기
begin dbms_auto_task_admin.disable( client_name =>'auto optimizer stats collection', operation => null, window_name => null ); end; / begin dbms_auto_task_admin.disable( client_name =>'auto space advisor', operation => null, window_name => null ); end; /
✏️ SQL 튜닝 작업

✔️ (느린 sql)
cpu 사용량이 높고, i/o가 많은 SQL을 찾아내서 어느 테이블인지 알고있기 = 어떤업무가 느린지 알 수 있다.
✔️통계 정보 수집을 자동으로 할지 수동으로 할지 dba가 결정해야한다.* 통계정보 수집 대상 4가지 1. 테이블 통계 정보 2. 인덱스 통계 정보 3. 컬럼 통계 정보 4. 시스템 통계 정보✔️ 회사마다
상황이 모두 다르므로 시스템 통계정보를 수집해야 한다.어느회사는 CPU 64개를 쓰고, 다른 회사는 CPU를 4개만 쓰는 회사도 있다. resource가 넉넉하면 넉넉한 환경에 맞춰 실행계획이 만들어져야 하고 부족하면 부족한 환경에 맞춰 알뜰하게 실행되게 실행계획이 만들어 져야 한다. 그래서 시스템 통계정보를 수집해주어야 한다.✔️ DBA는 선택되지 않는 인덱스를
제거해서 DML속도를 높이고, where절에서 자주 나타나는 컬럼에인덱스를 걸어서 검색 속도를 높여야한다. (인덱스 모니터링 하기)✔️ 좋은 실행계획은 변경되지 않고
계속 유지되게끔 관리해야한다. 옵티마이저가 더 좋은 실행계획이 있으면 그 실행계획으로 기존 sql을 실행해버리는데, 더성능이 느리다면 원래의 실행계획으로 원복시켜야 한다.stored outlone, SQL plan baseline을 이용하면 좋은 실행계획을 유지 관리 할 수 있다.✔️ DBA는 기존 인덱스보다 더 좋은 인덱스가 있을지 항상 연구해야한다.
예) 쿠팡으로 예를 들면 기존 기능을 더 좋게 하려고 계속 추가 개발을 한다. 추가 개발을 하면 새로운 SQL이 만들어진다!
실습1. 통계 정보 수집 4가지 실습
💡 통계정보 수집방법 총정리
✅ 통계정보의 종류 4가지
- 테이블 통계정보
- 인덱스 통계정보
- 컬럼 통계정보
- 시스템 통계정보
1. 테이블 통계정보 수집방법
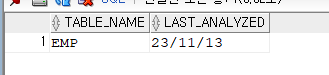
SQL> exec dbms_stats.gather_table_stats('SCOTT','EMP'); SQL> select table_name, last_analyzed from user_tables where table_name='EMP';
2. 인덱스 통계정보 수집방법SQL> create index demp_sal on emp(sal); -- 인덱스 만듬. 원래있긴했음!!! SQL> exec dbms_stats.gather_index_stats('SCOTT','EMP_SAL'); SQL> desc user_indexes; SQL> select index_name, num_rows, last_analyzed from user_indexes where index_name='EMP_SAL';
➡️ 테이블이든 인덱스든 계속해서 데이터가 변경되므로 변경된 사항에 대한 정보를 오라클에게 통계정보 수집으로 계속 알려주어야 한다.3. 컬럼의 통계정보 수집방법(P396)
-- 컬럼명 SQL> analyze table emp compute statistics for columns ename ;➡️ 테이블 통계 수집 하면 되지 왜 굳이 컬럼 통계 정보 수집이 필요한가??
: 컬럼중에 유독 변경이 많은 컬럼이 있다. 예를들어 emp 테이블에서 다른 컬럼은 변경되는 내용이 전혀 없는데sal만 자꾸 변경이 된다!! 그렇다면 테이블 전체의 통계정보를 수집하기 보다는 특정 컬럼만 통계정보 수집을 해주는 것이 바람직하다. 테이블이 크면 통계정보를 수집할 때 시간이 많이 걸리기 때문!!4. 시스템 통계정보 수집
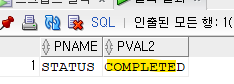
-- 시스템 통계 정보 수집 BEGIN DBMS_STATS.gather_system_stats('START'); END; / -- 시스템 통계 정보 중간 수집 (실제로는 시작과 종료 사이의 작업 수행 후) BEGIN DBMS_STATS.gather_system_stats('INTERVAL'); END; / -- 시스템 통계 정보 종료 BEGIN DBMS_STATS.gather_system_stats('STOP'); END; / -- 시스템 통계정보수집이 잘 되었는지 확인하기 select PNAME, PVAL2 from SYS.AUX_STATS$ where pname ='STATUS';
(아래는 성능 고도화 책 내용이다. 지금 안함!)
p400 ~ 401
4-1. 스키마(유져) 단위로 수집SQL> exec dbms_stats.gather_schema_stats('SCOTT');➡️ SCOTT 이 가지고 있는 모든 테이블에 대해서 통계정보를 수집
4-2. 데이터베이스의 모든 테이블에 대해서 통계정보 수집SQL> exec dbms_stats.gather_database_stats;➡️ 수행 시간도 오래걸리고 cpu 사용도 많이 사용되어서 정말 한가할 때 한번씩 해야함

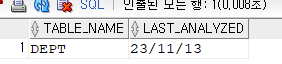
문제1. dept 테이블에 대해 테이블 통계정보 수집
SQL> exec dbms_stats.gather_table_stats('SCOTT','DEPT'); SQL> select table_name, last_analyzed from user_tables where table_name='DEPT';
문제2. emp 테이블에 sal에 대해 컬럼 통계 정보를 수집
SQL> analyze table emp compute statistics for columns sal ;
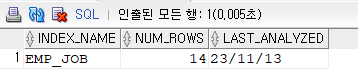
문제3. emp 테이블에 job에 인덱스를 걸고 통계정보 수집
SQL> create index emp_job on emp(job); -- 인덱스 만듬. 원래있긴했음!!! SQL> exec dbms_stats.gather_index_stats('SCOTT','EMP_JOB'); SQL> select index_name, num_rows, last_analyzed from user_indexes where index_name='EMP_JOB';
✏️ CPU및 대기 시간 튜닝 차원
💡 응답시간 = CPU시간 + 대기시간
맛집에 갔다!?
CPU시간 : 음식을 먹는 시간 (서비스 시간) -> 30분 : SQL 튜닝으로 해결
대기시간 : 줄 선 시간 -> 1시간 : 대기 이벤트를 보고 튜닝
응답시간은 총 1시간 30분이다!!➡️ 응답시간이 느리다면 두가지를 고려해서 왜 느린지 파악해야한다. (cpu시간, 대기시간)
⭐ 대기 이벤트를 보고 튜닝 하는 예 !
buffer busy wait -----------> pct free를 늘려서 해결
SQ enqueue -----------> cache size를 늘려서 해결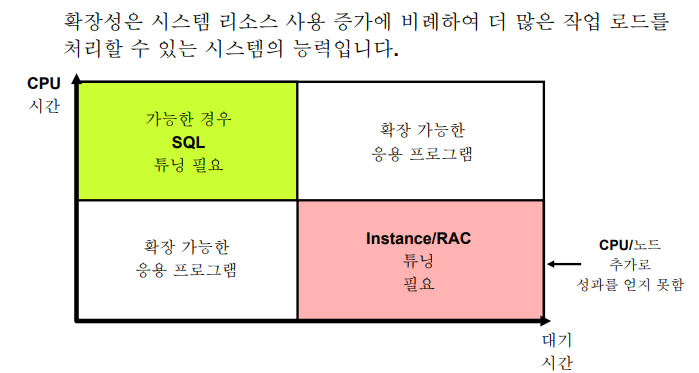
❓ 특정 SQL이 CPU 시간이 느린건지 대기 시간이 느린건지 어떻게 알 수 있을까?
: SQL trace를 보면 알 수 있다.
✍🏻 아래 확인
☞ 문제의 SQL 을 수행한 프로그램 정보및 DB 유져정보
DB SCHEMA : HIRA_LINK
OS USER : BWJF01
SYSTEM ID: ORA8
MACHINE : bonbu01
PROGRAM : @bonbu01 (TNS V1-V3)
☞ 튜닝전 SQL 과 TRACE 정보
SELECT "RECV_NO" ,
"RECV_YYYY" ,
"BRCH_CD" ,
"RECV_DATA_TYPE" ,
"YKIHO" ,
"DMD_TYPE_CD" ,
"PAY_SYS_TYPE" ,
"RECV_DT" ,
"EDPS_RECV_CLOS_YN" ,
"DIAG_YYYYMM" ,
"TOT_DMD_CNT" ,
"RETN_TYPE"
FROM "TBJFC02" "TBJFC02"
WHERE TO_NUMBER( "RECV_DT" ) >=20060724
AND TO_NUMBER( "RECV_DT" ) <=20060805
AND "RECV_DATA_TYPE" ='1'
AND ( "DMD_TYPE_CD" ='2'
OR "DMD_TYPE_CD" ='3' )
AND "PAY_SYS_TYPE" ='A'
AND "RETN_TYPE" IS NULL
AND "EDPS_RECV_CLOS_YN" ='Y'
AND SUBSTR( "YKIHO" , 3 , 1 ) <>'9';
⭐ elapsed은 응답시간, cpu가 cpu시간!!
응답시간이 47초이고 cpu시간이 19초이다. 대기시간은 (47 - 19) 28초 이다!!
call count cpu elapsed disk query current rows mis Wait Ela
------- ------ -------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.01 0 0 0 0 0 0.00
Exec 1 0.00 0.00 0 0 0 0 0 0.00
Fetch 356 19.00 47.64 70958 75211 63 8884 0 46.52
------- ------ -------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
Total 358 19.00 47.65 70958 75211 63 8884 0 46.52
⭐ 대기 이벤트 정보!!!! Count가 제일 큰 것 보기! -> db file scattered read이다. 여기서 대기시간 발생
이것을 줄이면 응답시간이 줄어들것이다.
Event waited on Count Zero Ela Elapse AVG(Ela) MAX(Ela) Blocks
---------------------------------------- -------- -------- ---------- ---------- ---------- --------
db file sequential read 501 450 0.57 0.00 0.05 501
SQL*Net message to client 357 0 0.00 0.00 0.00 0
SQL*Net message from client 357 0 11.55 0.03 0.22 0
db file scattered read 9847 6937 33.82 0.00 0.09 70457
file open 9 0 0.00 0.00 0.00 0
SQL*Net more data to client 227 0 0.14 0.00 0.01 0
latch free 26 0 0.52 0.02 0.02 0
Rows Row Source Operation
---------- ---------------------------------------------------
8884 TABLE ACCESS FULL TBJFC02
☞ 튜닝후 SQL 과 TRACE 정보
SELECT "RECV_NO" ,
"RECV_YYYY" ,
"BRCH_CD" ,
"RECV_DATA_TYPE" ,
"YKIHO" ,
"DMD_TYPE_CD" ,
"PAY_SYS_TYPE" ,
"RECV_DT" ,
"EDPS_RECV_CLOS_YN" ,
"DIAG_YYYYMM" ,
"TOT_DMD_CNT" ,
"RETN_TYPE"
FROM "TBJFC02" "TBJFC02"
WHERE "RECV_DT" >= '20060724'
AND "RECV_DT" <= '20060805'
AND "RECV_DATA_TYPE" ='1'
AND ( "DMD_TYPE_CD" ='2'
OR "DMD_TYPE_CD" ='3' )
AND "PAY_SYS_TYPE" ='A'
AND "RETN_TYPE" IS NULL
AND "EDPS_RECV_CLOS_YN" ='Y'
AND SUBSTR( "YKIHO" , 3 , 1 ) <>'9';
call count cpu elapsed disk query current rows mis Wait Ela
------- ------ -------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.04 0 9 0 0 1 0.00
Exec 1 0.00 0.00 0 0 0 0 0 0.00
Fetch 356 0.75 1.08 12 4841 0 8884 0 11.72
------- ------ -------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
Total 358 0.76 1.12 12 4850 0 8884 1 11.72
Event waited on Count Zero Ela Elapse AVG(Ela) MAX(Ela) Blocks
---------------------------------------- -------- -------- ---------- ---------- ---------- --------
db file sequential read 12 9 0.04 0.00 0.02 12
global cache cr request 36 0 0.11 0.00 0.01 0
SQL*Net message to client 357 0 0.01 0.00 0.01 0
SQL*Net message from client 357 0 11.53 0.03 0.38 0
file open 3 0 0.00 0.00 0.00 0
SQL*Net more data to client 234 0 0.09 0.00 0.01 0
latch free 2 0 0.04 0.02 0.02 0
Rows Row Source Operation
---------- ---------------------------------------------------
8884 TABLE ACCESS BY INDEX ROWID TBJFC02
10716 INDEX RANGE SCAN ➡️ db file sequential read는 full table scan을 하느랴 느리다는 것이다. full table scan을 줄어들게 하면 시간이 줄 것이다. where절 가공되있어서 가공했는데 밑에 보면 응답시간이 1초, cpu시간이 0.7초, 대기시간이 0.3초(1초 - 0.7초)로 줄어들었다.
점심시간 문제 아래의 SQL trace를 보고 응답시간과 CPU시간, 대기시간을 계산하기!
✍🏻 인덱스 스킵 스캔 튜닝 사례
call count cpu elapsed disk query current rows mis Wait Ela
------- ------ -------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.03 0.03 0 0 0 0 1 0.00
Exec 1 0.00 0.00 0 0 0 0 0 0.00
Fetch 1 4.17 16.46 35791 35830 0 1 0 13.96
------- ------ -------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
Total 3 4.20 16.49 35791 35830 0 1 1 13.96➡️ elapsed 응답시간은 16초, cpu시간은 4초! 대기시간은 16 - 4초 니까 14초가 걸렸다.
Event waited on Count Zero Ela Elapse AVG(Ela) MAX(Ela) Blocks
---------------------------------------- -------- -------- ---------- ---------- ---------- --------
db file sequential read 6 0 0.01 0.00 0.01 6
global cache cr request 4488 0 6.45 0.00 0.19 0
SQL*Net message to client 2 0 0.00 0.00 0.00 0
SQL*Net message from client 2 0 0.01 0.01 0.01 0
db file scattered read 2247 0 7.49 0.00 0.09 35785
latch free 14 0 0.00 0.00 0.00 0➡️ 대기 이벤트 정보를 보니 global cache cr request의 count수가 가장 높다. 얘때문에 대기시간 발생!
✏️ 응용 프로그램 설계, 구현 및 구성을 통한 확장성

- 데이터 베이스 모델링을 잘못하게 되면, 악성SQL을 작성할 수 밖에 없는 상황이 된다.
- 특정 업무가 특정 시간에 몰릴 때 update문의 lock이 발생할 수 있기 때문에 특정 업무에 대한 시간을 분배해야한다.
- 특정 시간에 여러 세션들이 동시에 접속을 하게되면 접속이 느려지므로, 접속 분배가 요구되어진다.
✏️ 고객 시스템의 일반적인 실수
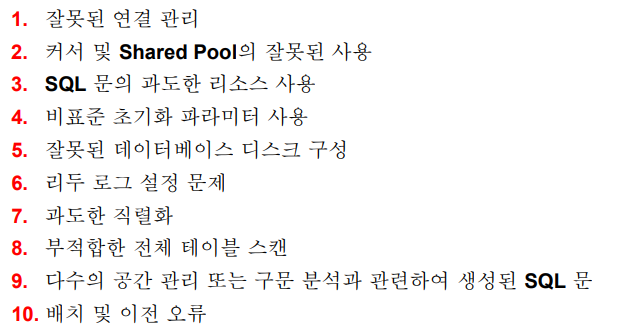
1. 커서 및 shared pool의 잘못된 사용 (sql이 공유될 수 없게 작성된것임)
* 해결방법 SQL이 공유될 수 있도록 ex) 리터럴 SQL -> 바인드 변수로 변경! (cursor_shariung 파라미터를 force로)2. SQL문의 과도한 리소스 사용
* 해결방법 SQL 튜닝, SQL 튜닝 어드바이저 사용3. 비표준화 초기화 파라미터 사용 (파라미터값을 잘못 설정한 것)
* 해결방법 옵티마이저에 관련한 초기화 파라미터는 오라클 기본 셋팅값으로 설정하는것이 바람직함4. 리두로그 파일 설정 문제 (리두로그 그룹을 적게 설정한것)
* 해결방법 리두 로그 그룹의 갯수를 늘림 : 로그 스위치가 일어나면 체크포인트가 발생하는데 체크포인트가 수행되고 있는 동안에는 리두로그 그룹의 상태가 ACTIVE이다. ACTIVE는 아직 DBWR에 의하여 datafile에 반영되지 않은것. 내려써지고 있는 중이다! INACTIVE가 덮어쓸 수 있는 상태인데 리두로그 그룹이 적어서 아직 ACTIVE상태라면 락이 걸린 것 처럼 멈춰버린다. 이럴 때 로그 그룹의 갯수를 늘려준다. 너무 앞으로 빨리 돌아오지 않도록 늘려주는 작업임!
5. undo tablespace의 크기를 너무 작게 두면 waiting 발생* 해결방법 undo tablespace의 사이즈를 늘리고 undo_management를 auto로 둔다.6. 오래 걸리는 full table scan
* 해결방법 인덱스 생성을 해서 해결7. 많은 양의 recursive SQL
❓recursive SQL은 SYS가 수행한 SQL이다.--ex) SCOTT이 수행한 SQL select empno, ename from emp here ename='SCOTT'; --ex) SYS가 수행한 SQL (EMP테이블이 DB에 있는지 확인) select table_name from user_tavles where table_name='EMP';* 해결방법 PL/SQL을 사용하거나 sql을 사용한다면 sql이 공유될 수 있도록 바인드 변수를 사용해서 작성하면 해결이 된다! 공유가 된다는 것은 SYS가 수행한 SQL의 정보를 데이터 딕셔너리 캐시에 캐시시킨다. 그래서 한번 공유가 되면 다시한번 recursive SQL을 사용하지 않아도 된다. PL/SQL은 프로시저로 실행하면 exec로 실행만 한다. 이렇게 되면 프로시저 코드가 공유되면서 계속 재사용이 된다. 그래서 오라클은 pl/sql사용을 권장함.8. 데이터 이행을 할 때 인덱스를 누락하는 경우가 사용자 실수로 발생
기존 데이터베이스 서버 ------------> 새로운 데이터 베이스 서버 emp emp emp_sal 누락➡️ 인덱스가 누락되면 성능이 떨어지므로 누락되지 않도록 신경을 써야한다.
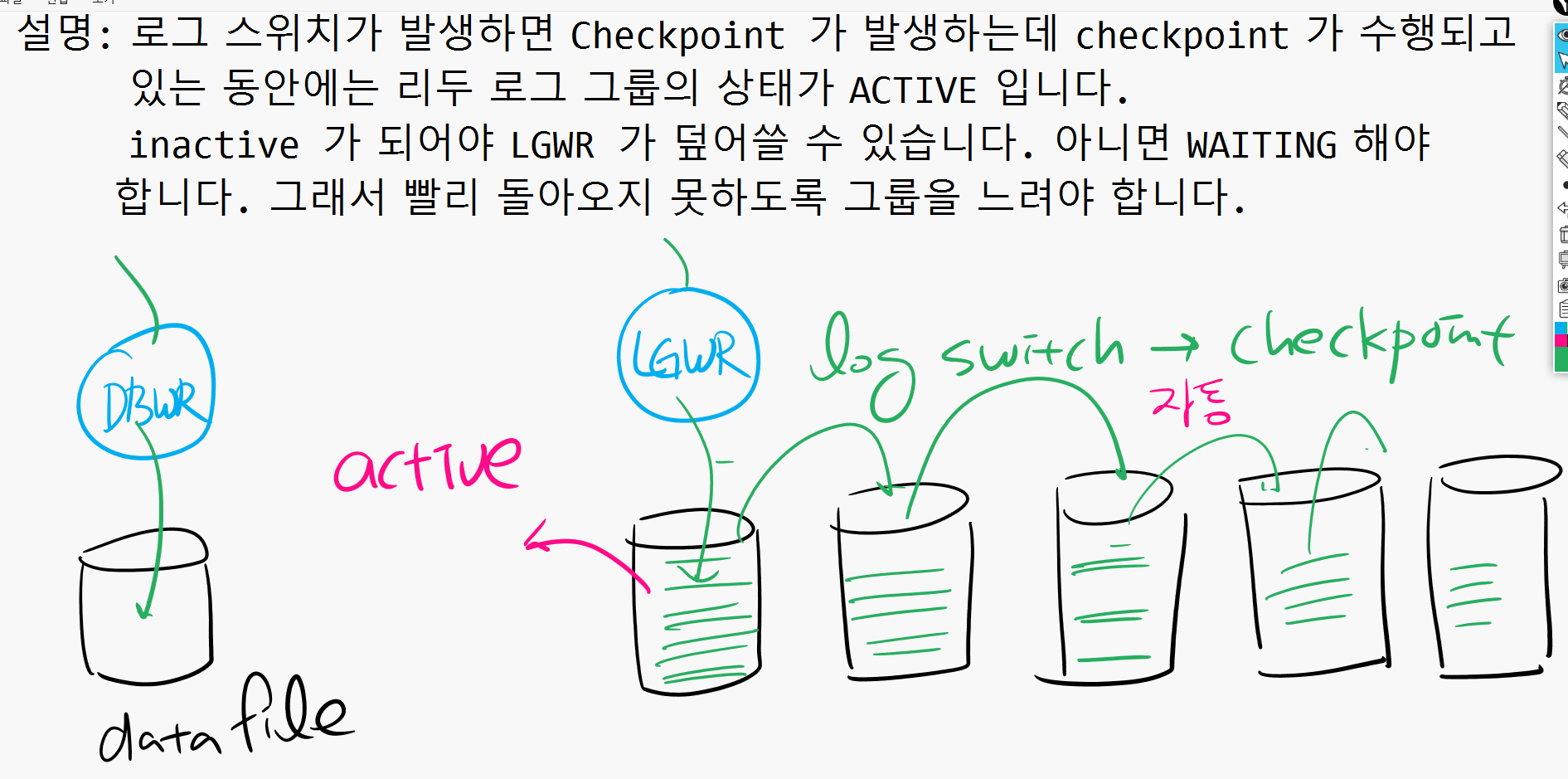
실습1. 지금 현재 리두 로그 그룹이 몇개가 있는지 확인하고 그룹을 6개로 늘리기
PROD > select group#, status
from v$log;
GROUP# STATUS
---------- ----------------
1 CURRENT
2 INACTIVE
3 INACTIVE
4 INACTIVE
5 INACTIVE
PROD > select group#, member
from v$logfile;
PROD > select group#, bytes/1024/1024
from v$log; -- 사이즈 100m 나옴
alter database add logfile group 6
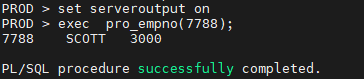
'/u01/app/oracle/oradata/orcl3/redo06.log' size 100m;실습2. 아래의 SQL의 결과를 출력하는 프로시저를 생성하기
select empno, ename, sal
from emp
where empno=7788;
exec pro_empno (7788);답!
create or replace procedure pro_empno (p_empno emp.empno%type) is v_emp emp%rowtype; begin select * into v_emp from emp where empno = p_empno; dbms_output.put_line(v_emp.empno || chr(9) || v_emp.ename || chr(9) || v_emp.sal) ; end; /
실습3. 아래의 SQL의 실행계획이 index scan이 될 수 있도록 인덱스를 생성하고 실행계획을 확인하기 (부적합한 full table scan) 아래 sql은 mgr이 인덱스 없어서 풀스캔 할 것이다.
explain plan for
select empno, ename, sal, mgr
from emp
where mgr=7566;
select * from table(dbms_xplan.display); 
create index emp_mgr on emp(mgr); explain plan for select empno, ename, sal, mgr from emp where mgr=7566; select * from table(dbms_xplan.display);
실습4. undo tablepsace의 크기를 확인하고 기존 사이즈의 2배로 늘리기 너무 작으면 dml 속도가 느려진다 .
-- 얘는 사용한거보는 쿼리 select * from ((select t.tablespace_name, ((t.total_size - f.free_size) / t.total_size) * 100 usedspace from (select tablespace_name, sum(bytes)/1024/1024 total_size from dba_data_files group by tablespace_name) t, (select tablespace_name, sum(bytes)/1024/1024 free_size from dba_free_space group by tablespace_name) f where t.tablespace_name = f.tablespace_name(+))); UNDOTBS 6.85369318
-- 얘가 답 select tablespace_name, sum(bytes) /1024/1024 from dba_data_files group by tablespace_name; TABLESPACE_NAME SUM(BYTES)/1024/1024 ------------------------------ -------------------- SYSAUX 78.25 TS9000 10 UNDOTBS 176 SYSTEM 274.375 select tablespace_name, file_name from dba_data_files; UNDOTBS /u01/app/oracle/oradata/PROD/disk4/undotbs01.dbf -- resize해도 되고 다른거 추가해도 된다. alter tablespace UNDOTBS add datafile '/u01/app/oracle/oradata/PROD/disk4/undotbs02.dbf' size 200m;
✏️ 능동적 튜닝 방법론

- 데이터 모델링만 잘해도 많은 SQL 튜닝을 필요없게 한다.
- 좋은 인덱스 하나가 많은 SQL 튜닝을 필요없게 한다.
- 뷰를 사용해서 SQL 튜닝을 할 수 있어야 한다.
- SQL을 처음 작성할 때 부터 튜닝된 SQL로 작성해야한다.
- SQL이 shared pool에서 공유될 수 있게 작성해야한다.
실습
1. 뷰를 다음과 같이 생성한다.
create view emp_deptno as select deptno, round(avg(sal)) avgsal from emp group by deptno;2. 만든 뷰 확인 (부서번호와 부서번호의 평균 월급이 출력되는 뷰이다.)
select * from emp_deptno;
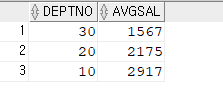
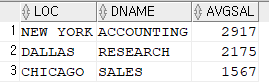
3. dept와 emp_deptno 뷰를 서로 조인해서 부서위치, 부서명, 부서번호별 평균 월급을 출력하기 (이게 튜닝 후!!)
select d.loc, d.dname, v.avgsal from dept d, emp_deptno v where d.deptno = v.deptno;
4. 위 결과를 view, in line view를 이용하지 말고 출력해보기 (이게 튜닝전임)select loc, dname, (select round(avg(sal)) from emp e where deptno = d.deptno) avgsal from dept d;➡️ dept 데이터가 많으면 악성 SQL이 된다. 엄청 느려짐!
5. 이름, 월급, 부서번호, 부서번호별 평균 월급을 출력하는데, 자기의 월급이 자기가 속한 부서번호의 평균 월급보다 더 큰 사원들만 출력하기
-- inline view로 (from절 서브쿼리) select e.ename, e.sal, e.deptno, avgsal from emp e, (select deptno, avg(sal) as avgsal from emp group by deptno ) v where e.deptno = v.deptno and e.sal > v.avgsal;➡️ 인라인뷰 안에서 group by를 먼저 수행하고 조인을 하면 조인되는 데이터의 양이 작아져서 좋은 성능으로 빠르게 결과가 출력될 수 있다.
✏️ 응용 프로그램 설계 단순화

✏️ 데이터 모델링

✏️ 효율적인 테이블 설계
- 테이블이 너무 커서 조인하는 SQL의 성능이 너무 느리면 그냥 조인하지 않게 테이블을 통합하기
ex) emp테이블과 dept테이블을 자주 조인하는 sql이 많은데 너무 느리다면 emp 테이블에 loc와 dname을 추가하기
- 테이블에 제약을 잘 걸면 데이터의 품질이 좋아져서 sql 또한 심플해진다.
- Materialized view를 사용해서 수행시간이 긴 SQL의 데이터를 저장해서 빠르게 검색해라!
(실습)- 파티션 테이블을 이용해서 검색 성능을 높여라
✔️ Materialized view 실습
💡실체화 뷰 쿼리로 재작성 (p 540)
실체화된 뷰 ( Materialized View )
실체의 반대 ? 가상 일반 뷰는 쿼리만 저장하고 있을뿐이지 자체적으로 data 를 가지고 있지는 않다. 그런데 Mview 는 data 를 저장하고 있다. 그래서 Mivew 의 장점이 뭐냐면 ? DW (Data Warehouse) 환경에서 대량의 data 를 미리 집계해두거나 미리 조인을 해두고 임시공간에 저장해두고 그 저장된 data 를 엑세스 하도록 옵티마이져가 자동으로 쿼리를 rewrite 하는 장점이있다.문제1. 아래와 같이 mview 를 만들고 아래의 2개의 SQL의 buffer 의 갯수를 비교하시오
-- materialized view만들기 문법 -- 만약 as 밑에 쿼리가 40분 걸려서 3건 나온다고 쳐보자. materialized view로 만들면 다음에 더 빠르게 -- 조회가 될 것이다. create materialized view dept_sal_sum enable query rewrite as select d.deptno, sum(e.sal) from emp e, dept d where e.deptno = d.deptno group by d.deptno ; select * from dept_sal_sum; DEPTNO SUM(E.SAL) -------- ---------- 30 9400 20 10875 10 8750 -- 실행계획 보기 SQL> set autot on SQL> select * from dept_sal_sum; ------------------------------------------------------ | Id | Operation | Name | Rows | ------------------------------------------------------ | 0 | SELECT STATEMENT | | 3 | | 1 | MAT_VIEW ACCESS FULL| DEPT_SAL_SUM | 3 | ------------------------------------------------------ drop view dept_sal_sum2; create view dept_sal_sum2 as select d.dname, sum(e.sal) sumsal from emp e, dept d where e.deptno = d.deptno group by d.dname; SQL> select * from dept_sal_sum2; ----------------------------------------------- | Id | Operation | Name | Rows | By ----------------------------------------------- | 0 | SELECT STATEMENT | | 4 | | 1 | HASH GROUP BY | | 4 | |* 2 | HASH JOIN | | 14 | | 3 | TABLE ACCESS FULL| DEPT | 4 | | 4 | TABLE ACCESS FULL| EMP | 14 | -----------------------------------------------
➡️ materialized view와는 다르게 일반 view는 emp, dept 테이블을 조인하고있다.
문제2. 아래의 SQL 의 실행계획을 보시오 !select d.deptno, sum(e.sal) from emp e, dept d where e.deptno = d.deptno group by d.deptno ; ------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 3 | 78 | 2 (0 )| 00:00:01 | | 1 | MAT_VIEW REWRITE ACCESS FULL| DEPT_SAL_SUM | 3 | 78 | 2 (0 )| 00:00:01 | -------------------------------------------------------------------------------➡️ 원래 위 쿼리는 조인을 해야하는데 조인되지 않았다. MVIEW의 Query rewrite 기능으로 emp, dept를 조인하지 않고 MVIEW에서 읽어왔다.
- Mview 와 관련된 힌트 ?
Rewrite~> mview 에서 data 를 가져와라no_Rewrite~> Mview 에서 가져오지 말고 테이블에서 가져와라문제3. 아래 2개 SQL 의 버퍼의 갯수를 비교하시오 ~
select /*+ no_rewrite */ d.deptno, sum(e.sal) from emp e, dept d where e.deptno = d.deptno group by d.deptno ; -- 이건 조인하고 select /*+ rewrite */ d.deptno, sum(e.sal) from emp e, dept d where e.deptno = d.deptno group by d.deptno ; -- 이건 MVIEW에서 데이터를 가져왔다. 더 빠르게 가져올 수 있음.➡️ MVIEW는 data warehouse쪽 환경에서 사용하기에 적합한 db오브젝트이다. (DW환경의 데이터들은 잘 변하지 않으므로!)
- with 절은 반복되는 무거운 SQL 의 결과를 TEMP 에 저장해놓고
빠르게 그 결과값을 엑세스 하기 위해서 사용하는 SQLSELECT e.ename AS employee_name, dc1.dept_count AS emp_dept_count, m.ename AS manager_name, dc2.dept_count AS mgr_dept_count FROM emp e, (SELECT deptno, COUNT(*) AS dept_count FROM emp GROUP BY deptno) dc1, emp m, (SELECT deptno, COUNT(*) AS dept_count FROM emp GROUP BY deptno) dc2 WHERE e.deptno = dc1.deptno AND e.mgr = m.empno AND m.deptno = dc2.deptno;
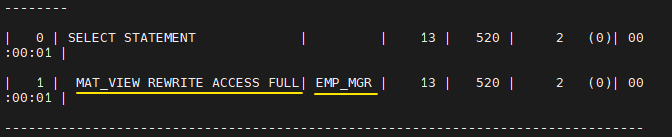
오늘의 마지막 문제 다음의 SQL을 MVIEW로 만들어서 쿼리 리라이트 기능을 사용할 수 있게 하기
SELECT e.ename AS employee_name,
dc1.dept_count AS emp_dept_count,
m.ename AS manager_name,
dc2.dept_count AS mgr_dept_count
FROM emp e,
(SELECT deptno, COUNT(*) AS dept_count
FROM emp GROUP BY deptno) dc1,
emp m,
(SELECT deptno, COUNT(*) AS dept_count
FROM emp GROUP BY deptno) dc2
WHERE e.deptno = dc1.deptno
AND e.mgr = m.empno
AND m.deptno = dc2.deptno;create materialized view emp_mgr enable query rewrite as SELECT e.ename AS employee_name, dc1.dept_count AS emp_dept_count, m.ename AS manager_name, dc2.dept_count AS mgr_dept_count FROM emp e, (SELECT deptno, COUNT(*) AS dept_count FROM emp GROUP BY deptno) dc1, emp m, (SELECT deptno, COUNT(*) AS dept_count FROM emp GROUP BY deptno) dc2 WHERE e.deptno = dc1.deptno AND e.mgr = m.empno AND m.deptno = dc2.deptno;