
📖 4장, SQL 튜닝 케이스
- 인덱스 엑세스 방법
- 조인 튜닝 방법
✏️ 데이터 엑세스 경로
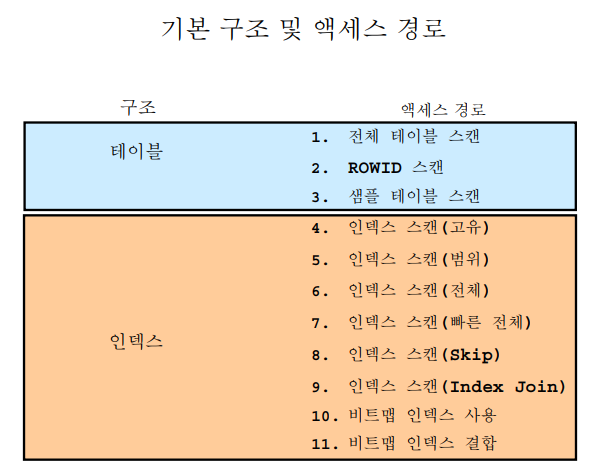
1. table access 방법
* 전체 테이블 스캔 : /*+ full(테이블명) */ * rowid에 의한 스캔 : /*+ rowid */ * sample 스캔 (따로 힌트는 없다.)2. index access 방법
* index range scan : /*+ index(테이블명 인덱스명) */ * index unique scan : /*+ index(테이블명 인덱스명) */ * index full scan : /*+ index_fs(테이블명 인덱스명) */ * index fast full scan : /*+ index_ffs(테이블명 인덱스명) */ * index skip scan : /*+ index_ss(테이블명 인덱스명) */ * index merge scan : /*+ and_equal(테이블 인덱스명1 인덱스명2) */ * index bitmap merge scan : /*+ index_combine(테이블명) */ * index join : /*+ index_join(테이블명 인덱스명1 인덱스명2) */ `
✔️ full table scan

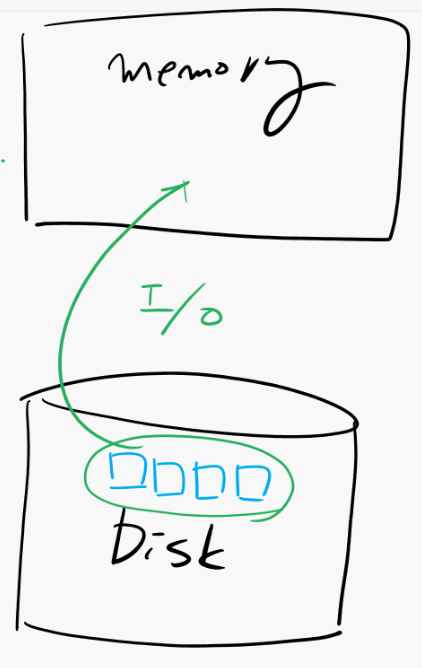
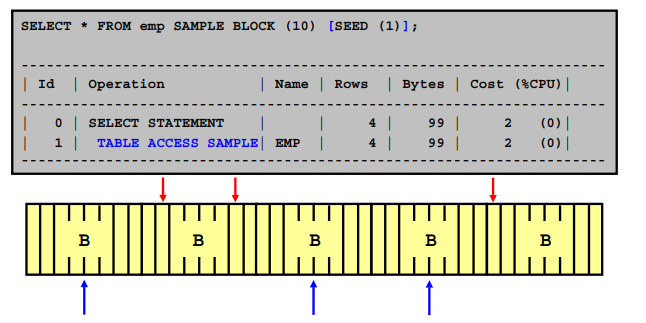
select * from emp;➡️ emp 16개! DB_FILE_MULTIBLOCK_READ_COUNT = 4이 그림에서 숫자 4는 4개를 동시에 퍼올리겠다라는 것인데 그럼 4번 (4 X 4) 수행! 적게 수행할수록 좋은것임!!
full table scan이란 HWM아래의 블럭들 전체를 스캔하는 스캔 방법이다. HWM 아래의 블럭들을 스캔할 때 DB_FILE_MULTIBLOCK_READ_COUNT의 갯수만큼 디스크에서 메모리로 한번의 I/O로 올려들이면서 스캔하는 방법이다.
➡️ full table scan을 할 수 밖에 없는 경우!
1. 인덱스 생성시
2. 테이블 통계 정보 수집할 때
3. 테이블을 다른 테이블 스페이스로 move할 때
4. where절이 없거나 index가 없는 컬럼의 데이터를 검색할 때
💡 full table scan을 할 수 밖에 없다면 full table scan을 빠르게 수행하면 되니ㅡㄴ데,
빠르게 수행할 수 있는 방법은?
alter session set DB_FILE_MULTIBLOCK_READ_COUNT=128; select * from emp; -- 현재 설정되어있는 값 확인 PROD > show parameter DB_FILE_MULTIBLOCK_READ_COUNT NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ db_file_multiblock_read_count integer 118➡️ 한번의 i/o로 128개의 블럭을 읽어들인다!
실습
- scott 유저에서 sh 계정의 sales 테이블을 가져다가 sales100테이블을 생성하기
create table sales100 as select * from sh.sales; insert into sales100 select * from sales100;
DB_FILE_MULTIBLOCK_READ_COUNT를 4개로 하고 인덱스 생성시간을 확인하기set timing on alter session set DB_FILE_MULTIBLOCK_READ_COUNT=4; -- index생성은 풀테이블 스캔을 한다. create index sales100_indx on sales100(amount_sold,prod_id); -- 5초가 나왔다.
DB_FILE_MULTIBLOCK_READ_COUNT를 256으로 하고 인덱스 생성시간 확인drop index sales100_indx; alter session set DB_FILE_MULTIBLOCK_READ_COUNT=256; create index sales100_indx on sales100(amount_sold,prod_id); -- 1초가 나왔다.➡️ 3배 정도 속도가 빨라졌다! alter session 명령어는 이 세션이 끝나면 모두 원복되는 것이다. 그리고 시스템 전체에 영향을 주지 않고 내 세션에서만 영향을 주는 명령어이다.
문제1. 통계정보 수집 시에도 full table scan을 한다고 했으니, 아래의 테이블의 통계정보를 수집할 때 DB_FILE_MULTIBLOCK_READ_COUNT가 4일때와 256일때 속도 차이가 얼마나 나는지 확인하기
1. DB_FILE_MULTIBLOCK_READ_COUNT가 4일 때!
set timing on
alter session set DB_FILE_MULTIBLOCK_READ_COUNT=4;
exec dbms_stats.gather_table_stats('SCOTT', 'SALES100');
Elapsed: 00:00:12.022. DB_FILE_MULTIBLOCK_READ_COUNT가 256일 때!
alter session set DB_FILE_MULTIBLOCK_READ_COUNT=256;
exec dbms_stats.gather_table_stats('SCOTT', 'SALES100');
Elapsed: 00:00:00.93✔️ 일부로 full table scane을 유도하는 경우
- 병렬 쿼리문을 수행할 때
select /*+ full(emp) parallel(emp) */ ename, sal, job
from emp
where job='SALESMAN';
↑ 인덱스 컬럼이라고 가정!➡️ 병렬 쿼리문을 수행할 때 인덱스를 통해 데이터를 엑세스 해서 병렬쿼리문이 수행되면 오히려 검색 성능이 떨어집니다. 그래서 다음과 같이 full 이라는 힌트를 써야한다.
대용량 데이터를 검색하는 DW(data warehouse)의 쿼리문들은 위와 같이 full 힌트와 parallel힌트를 같이 사용해서 데이터를 빠르게 검색하는 쿼리문이 많습니다. /*+ full(emp) parallel(emp) */
⭐ 병렬 쿼리문은 인덱스를 타면 느리다 !!
문제2. 아래의 SQL을 튜닝하기 !!
-- 튜닝전
select /*+ parallel(emp) */ empno, ename, sal
from emp
where deptno = 20;➡️ 실행계획이 인덱스 range scan으로 출력되었다고 생각하고 튜닝해보기
-- 튜닝후 select /*+ full(emp) parallel(emp) */ empno, ename, sal from emp where deptno = 20;
✔️ rowid에 의한 스캔 : /*+ rowid */
💡 옵티마이져가 선택하는 엑세스 경로 우선순위 15가지 순위
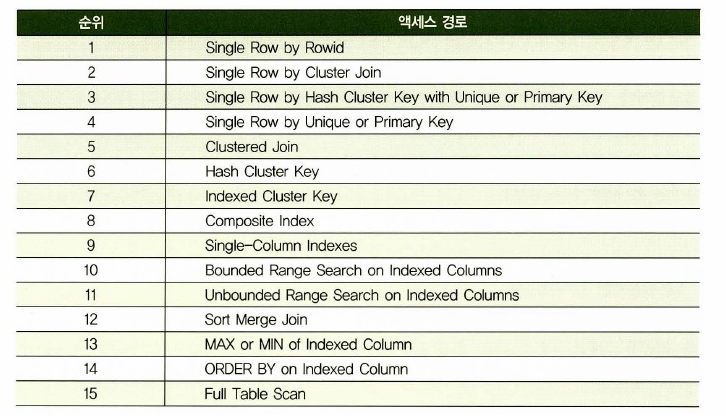
➡️ 옵티마이저가 가장 우선으로 선택하는 액세스 경로는 rowid에 의한 스캔이다! 그리고 한개의 데이터를 검색하는 가장 빠른 방법은 rowid에 의한 스캔이다.
실습
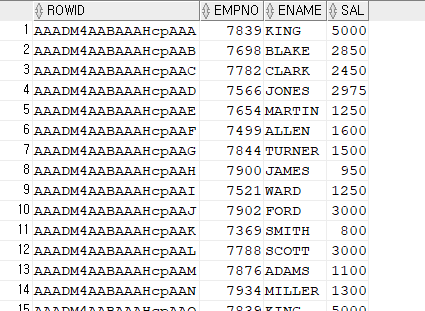
1. emp table의 rowid를 출력하기
select rowid, empno, ename, sal from emp;
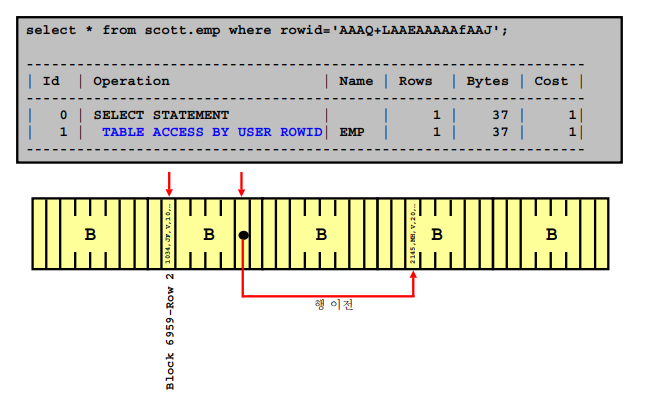
➡️rowid: file# + block# + row# 로 되어있는 행의 물리적 주소이고 unique한 값이다!select empno, ename, sal from emp where rowid='AAADM4AABAAAHcpAAA';2. 아래 SQL의 실행계획 확인
explain plan for select empno, ename, sal from emp where rowid='AAADM4AABAAAHcpAAA'; select * from table(dbms_xplan.display); ----------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 26 | 1 (0)| 00:00:01 | | 1 | TABLE ACCESS BY USER ROWID| EMP | 1 | 26 | 1 (0)| 00:00:01 | -----------------------------------------------------------------------------------➡️
TABLE ACCESS BY USER ROWID이 실행계획이 가장 빠르게 데이터를 엑세스 하는 방법인데 평상시에 이렇게 SQL을 조회하지는 않는다. 튜닝할 때 잘 쓰인다.
문제 이름에 EN 또는 IN 을 포함하고 있는 사원들의 이름, 월급, 부서번호, 직업을 출력하기
create index emp_ename on emp(ename); explain plan for select ename, sal, deptno, job from emp where ename like '%EN%' or ename like '%IN%'; select * from table(dbms_xplan.display); -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 2796 | 61512 | 511 (0)| 00:00:07 | |* 1 | TABLE ACCESS FULL| EMP | 2796 | 61512 | 511 (0)| 00:00:07 | --------------------------------------------------------------------------➡️ Index를 걸었지만 full table scan을 하고있다.
실제 실행계획으로 보기select /*+ gather_plan_statistics */ ename, sal, deptno, job from emp where ename like '%EN%' or ename like '%IN%'; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); ------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | 3 |00:00:00.01 | 3 | |* 1 | TABLE ACCESS FULL| EMP | 1 | 1 | 3 |00:00:00.01 | 3 | ------------------------------------------------------------------------------------➡️ full table scan을 하면서 버퍼를 3개 읽었다. or sql 튜닝!!!해보기
- 튜닝 후!
select /*+ gather_plan_statistics no_query_transformation */ ename, sal, deptno, job from emp where rowid in (select /*+ index_ffs(emp emp_ename) */rowid from emp where ename like '%EN%' or ename like '%IN%'); SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); ---------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ---------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 3 |00:00:00.01 | 17 | |* 1 | FILTER | | 1 | | 3 |00:00:00.01 | 17 | | 2 | TABLE ACCESS FULL | EMP | 1 | 14 | 14 |00:00:00.01 | 3 | |* 3 | TABLE ACCESS BY USER ROWID| EMP | 14 | 1 | 3 |00:00:00.01 | 14 | ----------------------------------------------------------------------------------------------✔️ rowid를 where절로 넘겨준다. in 안에 인덱스에서 검색하게 하는것이 포인트이다. emp를 두번 검색하면 성능이 안좋으므로 밖 쿼리는 emp에서 검색, in 안에는 인덱스에서 검색하도록.
➡️no_query_transformation를 쓰지 않으면 옵티마이져가 쿼리문을 왜이렇게 어렵게 썼니? 하면서 튜닝 전 쿼리로 바꿔서 자기가 알아서 실행하고 full table scan을 해버린다. 그래서 우리는no_query_transformation를 해서 쿼리 변형을 하지 말라고 힌트를 써준다!!!
➡️FILTER가 써져있으면 메인쿼리 실행하고 서브쿼리 실행했다 라는 뜻이다.
- index_ffs
select /*+ gather_plan_statistics no_query_transformation */ ename, sal, deptno, job from emp where rowid in (select /*+ index_ffs(emp emp_ename) */rowid from emp where ename like '%EN%' or ename like '%IN%'); SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));➡️ rowid에 의해서 데이터를 검색하는 sql 튜닝이 위와 같이 sql을 변경하는 것입니다.
완성된 튜닝 sql은 서브쿼리 튜닝까지 배우고 다시!!!!
⭐ no_query_transformation 은 쿼리 변형하지 말고 내가 쓴 쿼리로 실행해라!!!!!
✔️ 샘플 테이블 스캔
💡 액세스 방법중 하나이다. 잘 쓰지이는 않지만 알고있기!
데이터에서 표본 샘플을 랜덤으로 추출하는 쿼리문. 예를들어 경품 추천하는 것을 만든다 할때 활용된다.
select * from sales100 sample block (10); 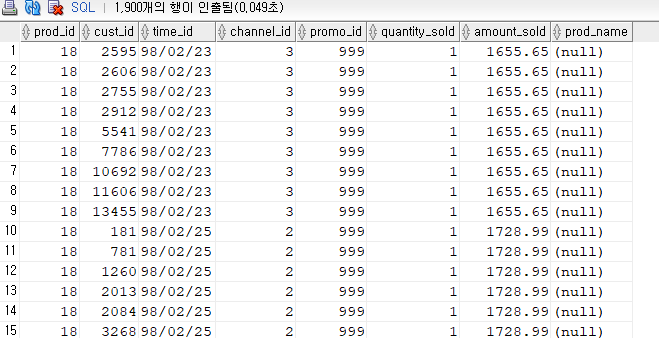
➡️ 10%의 샘플링 데이터가 나왔다.
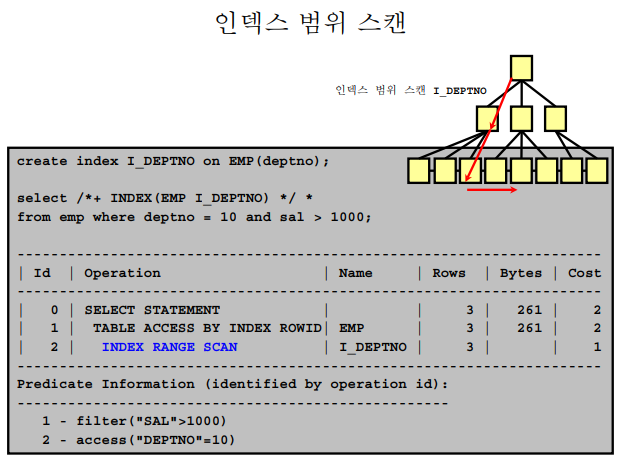
✔️ index range scan
✔️ 인덱스의 종류
1. unique index: 값이 중복되지 않고 유니크해야 생성되는 인덱스 (예 -> empno 컬럼) 값이 유니크 하다는 것이 보장된 인덱스이다!
2. non unique index: 값이 중복되었던 중복되지 않았던간에 모두 생성할 수 있는 인덱스인데, 값이 유니크 하다는 것이 보장되지 않은 인덱스이다.
💡 non unique한 인덱스를 액세스 하는 스캔 방법 : index range scan
실습 사원 테이블에 사원번호에 인덱스를 생성하고 사원번호의 인덱스의 구조를 확인합니다.
create index emp_empno on emp(empno); select empno, rowid from emp where empno >= 0; EMPNO ROWID -- 인덱스는 컬럼값 + rowid로 구성되어있다. ----- ------------------- -- 인덱스의 컬럼은 ascending 하게 정렬되어있다! 7369 AAADORAABAAAHcpAAK 7499 AAADORAABAAAHcpAAF 7521 AAADORAABAAAHcpAAI 7566 AAADORAABAAAHcpAAD 7654 AAADORAABAAAHcpAAE 7698 AAADORAABAAAHcpAAB 7782 AAADORAABAAAHcpAAC 7788 AAADORAABAAAHcpAAL 7839 AAADORAABAAAHcpAAA 7844 AAADORAABAAAHcpAAG 7876 AAADORAABAAAHcpAAM 7900 AAADORAABAAAHcpAAH 7902 AAADORAABAAAHcpAAJ 7934 AAADORAABAAAHcpAAN
문제 사원 이름에 인덱스를 생성하고 인덱스의 구조를 출력하시오 !
인덱스 전체를 다 보려면 ?
숫자컬럼 >= 0
문자컬럼 > ' '
날짜컬럼 < to_date('9999/12/31', 'RRRR/MM/DD')create index emp_ename on emp(ename); select /*+ gather_plan_statistics */ename, rowid from emp where ename > ' ' ; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); ---------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ---------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 1 | |* 1 | INDEX RANGE SCAN| EMP_ENAME | 1 | 14 | 14 |00:00:00.01 | 1 | ----------------------------------------------------------------------------------------
➡️ 이름은 ascending 하게 정렬되어있다.
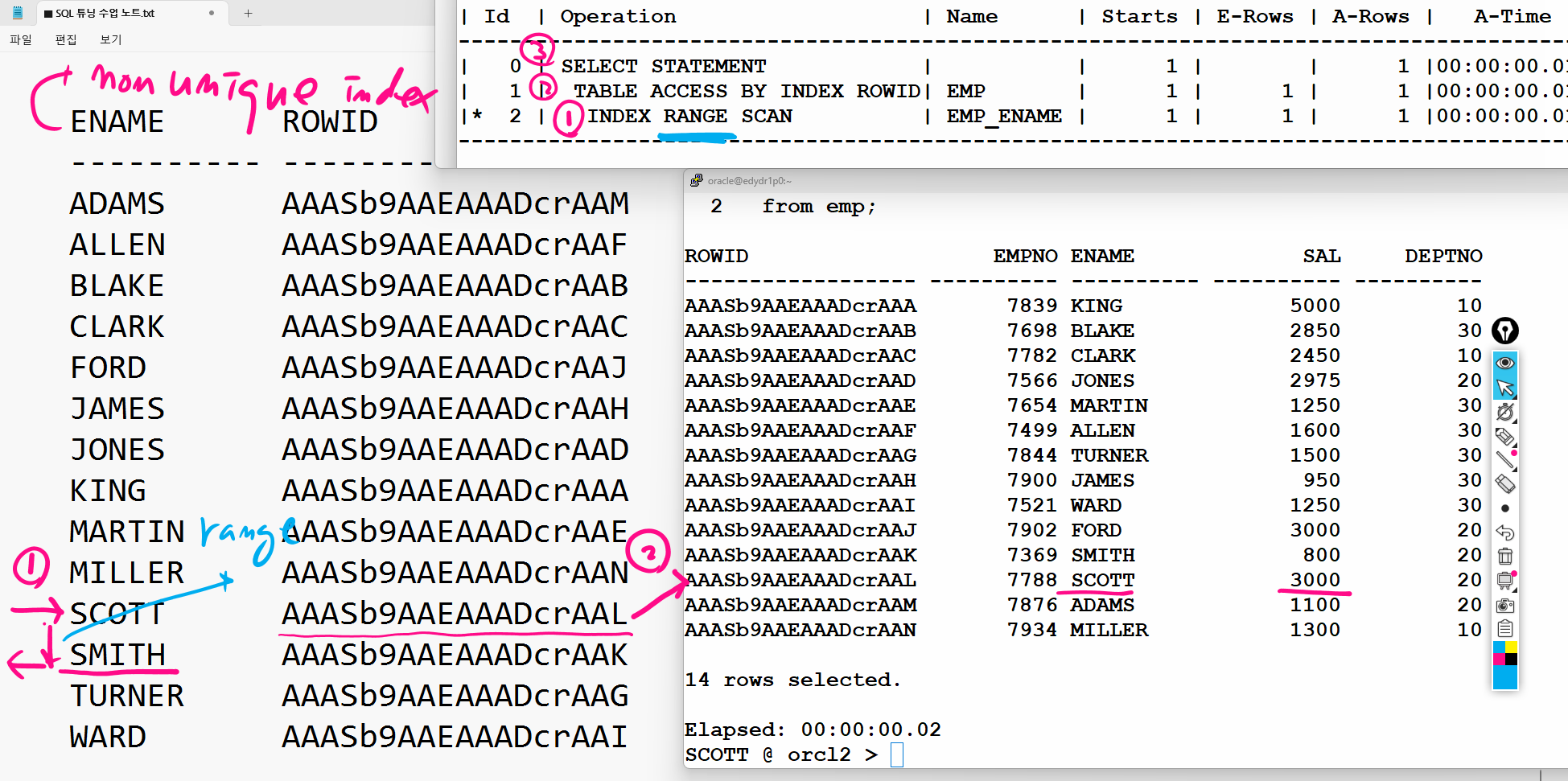
문제 이름이 scott인 사원의 이름과 월급을 출력하는 SQL의 실제 실행계획을 확인하기
왜 난 풀테이블 스캔이 나오는 것인가..
select /*+ gather_plan_statistics */ename, sal from emp where ename = 'SCOTT'; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
index range scan은 scott을 읽고 non unique이다 보니 유니크한 값이 아닐수도 있어서 밑에 데이터를 한번 더 읽은것이다. 유니크한 인덱스라면index unique scan을 했을 것이다.
문제 직업에 인덱스를 걸고 직업의 인덱스의 구조를 출력하기
create index emp_job on emp(job); select /*+ gather_plan_statistics */job, rowid from emp where job > ' ' ;
문제 직업이 매니저인 사원들의 이름과 직업을 출력하는 쿼리문이 어떻게 index range scan을 하는지 출력
select /*+ gather_plan_statistics */ename, job
from emp
where job = 'MANAGER'; - job이 MANAGER 인 사원을 찍는다. 그 rowid인 사원들의 이름, 직업을 가지고 온 후에 아래로 내려와서 테이블을 액세스 하러 간다. 그래서 이름, 직업을 가지고 온후 또 아래로 (range scan)내려와서 또 테이블을 액세서 하러간다. 이름, 직업을 가지고 온 후 PRESIDENT 까지 읽고 나서야 빠져나온다. non unique index 이니까. (테이블을 읽으러 가지는 않는다.)
select /*+ gather_plan_statistics index(emp emp_ename) */ename, sal
from emp
where ename = 'SCOTT';