
복습 SQL 튜닝 케이스
1. table access 방법
* 전체 테이블 스캔 : /*+ full(테이블명) */ * rowid에 의한 스캔 : /*+ rowid */ * sample 스캔 (따로 힌트는 없다.)2. index access 방법
* index range scan : /*+ index(테이블명 인덱스명) */ * index unique scan : /*+ index(테이블명 인덱스명) */ * index full scan : /*+ index_fs(테이블명 인덱스명) */ * index fast full scan : /*+ index_ffs(테이블명 인덱스명) */ * index skip scan : /*+ index_ss(테이블명 인덱스명) */ * index merge scan : /*+ and_equal(테이블 인덱스명1 인덱스명2) */ * index bitmap merge scan : /*+ index_combine(테이블명) */ * index join : /*+ index_join(테이블명 인덱스명1 인덱스명2) */
✔️ index unique scan
유니크 인덱스를 스캔하는 액세스 방법
@demo
-- 유니크 인덱스 만들기
create unique index emp_empno
on emp(empno);
-- 언유니크로 생성!
create index emp_ename
on emp(ename);
select index_name, uniqueness
from user_indexes
where table_name='EMP';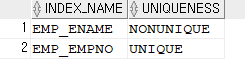
➡️ unique 인덱스는 컬럼의 값이 유니크 하다는 것이 보장이 된 인덱스이다!
💡 실행계획 보기!
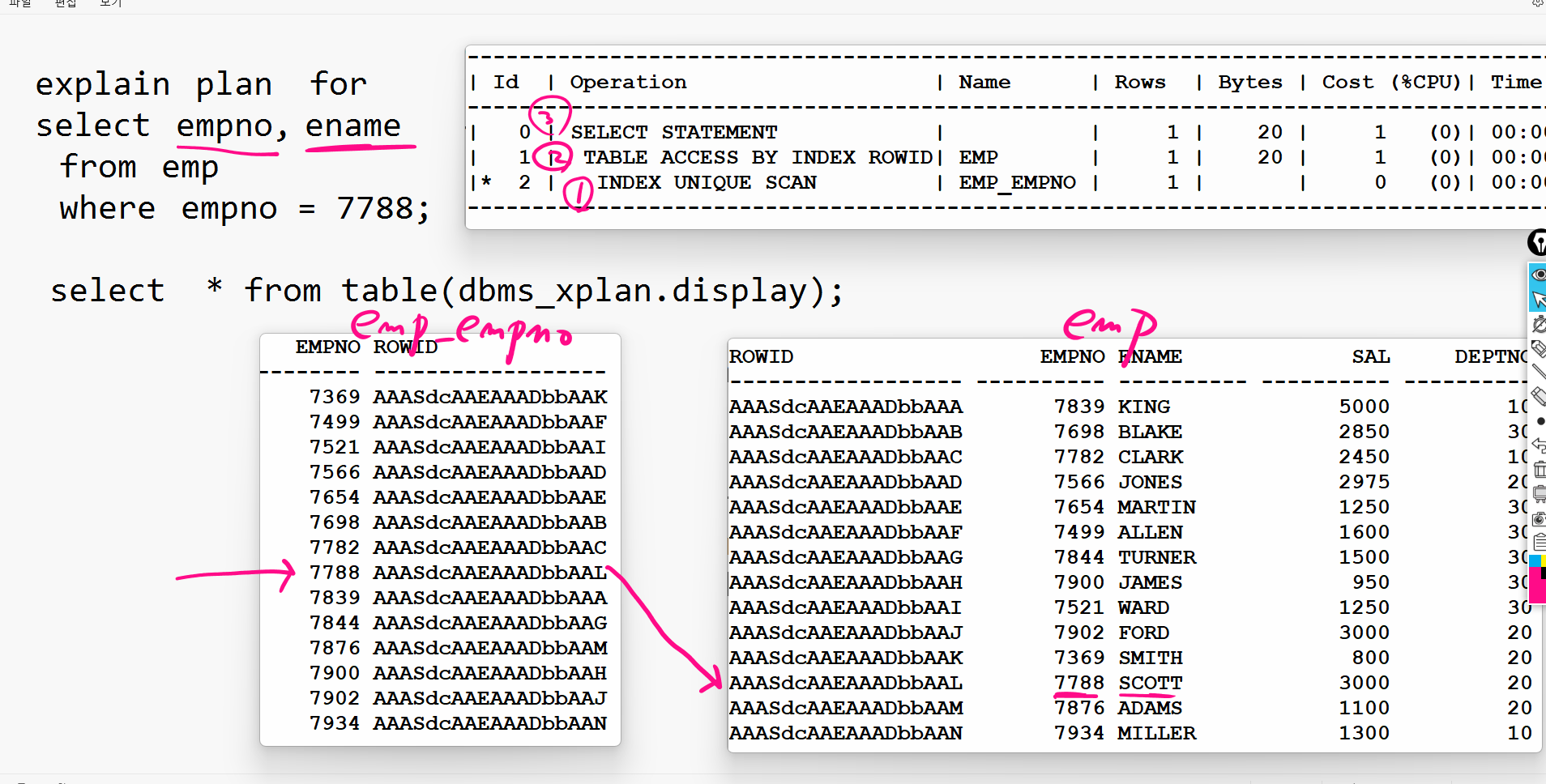
explain plan for select empno, ename, sal from emp where empno = 7788; select * from table(dbms_xplan.display); ----------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 33 | 1 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 33 | 1 (0)| 00:00:01 | |* 2 | INDEX UNIQUE SCAN | EMP_EMPNO | 1 | | 0 (0)| 00:00:01 | -----------------------------------------------------------------------------------------
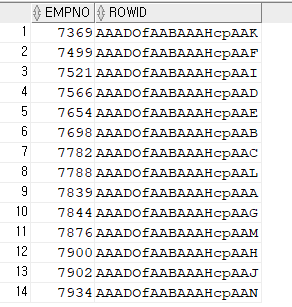
문제1. emp_empno 인덱스의 구조(컬럼+rowid) 확인하기
숫자컬럼 >= 0
문자컬럼 > ' '
날짜컬럼 < to_date('9999/12/31', 'RRRR/MM/DD')select empno, rowid from emp where empno >= 0;
문제2. 사원번호가 7788번인 사원의 사원번호와 사원이름을 출력하는 SQL의 실행이 어떻게 되는지 실행계획 해석하기
explain plan for select empno, ename from emp where empno=7788; select * from table(dbms_xplan.display); ----------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 20 | 1 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 20 | 1 (0)| 00:00:01 | |* 2 | INDEX UNIQUE SCAN | EMP_EMPNO | 1 | | 0 (0)| 00:00:01 | -----------------------------------------------------------------------------------------➡️ TABLE ACCESS를 하는 이유는 이름도 가져와야하니까.
INDEX UNIQUE SCAN이므로 7788 하나를 보고 emp테이블에 가서 데이터를 찾는다. index range scan은 7788 밑에 7839 까지 읽고 끝날것이다.
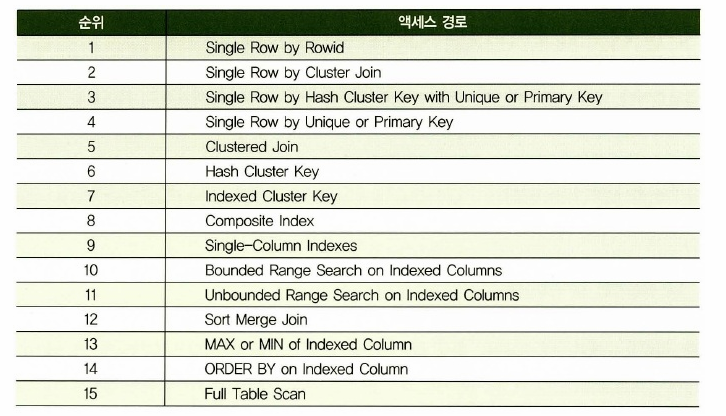
➡️ 유니크 인덱스는 4번째 !! 논유니크는 9번째!
문제3. 옵티마이저는 아래의 SQL의 조건 두개중에 어느 컬럼의 인덱스를 엑세스 하겠는가?
select empno, ename, sal, deptno from emp where empno= 7788 and ename = 'SCOTT';
➡️ 유니크 인덱스인emp_empno을 탈 것으로 예상! 확인해보기explain plan for select empno, ename, sal, deptno from emp where empno= 7788 and ename = 'SCOTT'; select * from table(dbms_xplan.display); ----------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 46 | 1 (0)| 00:00:01 | |* 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 46 | 1 (0)| 00:00:01 | |* 2 | INDEX UNIQUE SCAN | EMP_EMPNO | 1 | | 0 (0)| 00:00:01 | -----------------------------------------------------------------------------------------

문제4. 아래의 SQL이 enmae의 인덱스를 탈 수 있도록 힌트주기
explain plan for select /*+ index(emp emp_ename) */ empno, ename, sal, deptno from emp where empno= 7788 and ename = 'SCOTT'; select * from table(dbms_xplan.display); ----------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 46 | 1 (0)| 00:00:01 | |* 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 46 | 1 (0)| 00:00:01 | |* 2 | INDEX RANGE SCAN | EMP_ENAME | 1 | | 1 (0)| 00:00:01 | -----------------------------------------------------------------------------------------
✔️ 결합 컬럼 인덱스
: 인덱스를 구성하는 컬럼의 갯수에 따라 인덱스가 2가지 종류로 나뉜다.
1. 단일 컬럼 인덱스 (인덱스를 구성하는 컬럼의 갯수가 1개일 때)
2. 결합 컬럼 인덱스 (인덱스를 구성하는 컬럼의 갯수가 2개 이상일 때)
실습 단일컬럼 인덱스와 결합 컬럼 인덱스 만들어보기!
-- 단일컬럼 인덱스 생성 create index emp_deptno on emp(deptno); explain plan for select deptno from emp where deptno=10; select * from table(dbms_xplan.display); ------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 3 | 39 | 1 (0)| 00:00:01 | |* 1 | INDEX RANGE SCAN| EMP_DEPTNO | 3 | 39 | 1 (0)| 00:00:01 | -------------------------------------------------------------------------------➡️ 위와같이 부서번호만 검색하는거라면 emp_deptno 인덱스에서 데이터를 가져오면 되고 굳이 테이블 엑세스를 하러 갈 필요가 없다. 그런데 우리가 검색하는 많은 쿼리문들은 위와같이 select 절에 컬럼이 하나만 쓰는 경우는 드물고 여러개의 컬럼들을 나열해서 검색한다!
그래서 실행계획에 테이블 엑세스를 하러 가는 것이 필요하다!
인덱스만 읽고 다 끝내고 싶다면 ?-- 결합 컬럼 인덱스 생성 create index emp_deptno_sal on emp(deptno,sal); explain plan for select deptno,sal from emp where deptno=10; select * from table(dbms_xplan.display); ----------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 3 | 78 | 1 (0)| 00:00:01 | |* 1 | INDEX RANGE SCAN| EMP_DEPTNO_SAL | 3 | 78 | 1 (0)| 00:00:01 | -----------------------------------------------------------------------------------
문제1. emp_deptno_sal의 인덱스 구조 확인하기
select deptno, sal ,rowid from emp where deptno >= 0 ;
➡️ 부서번호 순으로 정렬이 되어있다.
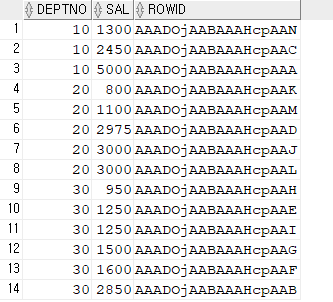
💡 결합 컬럼 인덱스를 사용하게 되면 테이블 엑세스를 생략하거나 줄일 수 있다. -> 성능 높아짐!
문제2. emp_deptno 인덱스와 emp_deptno_sal 두개의 인덱스가 있는 상황에서 아래의 SQL은 어느 인덱스를 엑세스 하겠는가?
select deptno, sal, ename from emp where deptno = 10;➡️ 이경우는 어떤것을 타던 별 차이가 없지만 emp_deptno를 엑세스 했다. (나는 풀테이블..)
문제3. 아래의 SQL은 어느 인덱스를 타는지 확인하기
select deptno, sal, ename from emp where deptno = 10 and sal = 3000; ---------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 33 | 1 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 33 | 1 (0)| 00:00:01 | |* 2 | INDEX RANGE SCAN | EMP_DEPTNO_SAL | 1 | | 1 (0)| 00:00:01 | ----------------------------------------------------------------------------------------------➡️ emp_deptno_sal 결합 컬럼 인덱스를 엑세스했다. 회사의 업무는 대체적으로 뒤에 조건이 많이 붙어져있다. 결합 컬럼 인덱스를 많이 만들어주는것이 옵티마이저에게 빠르게 길을 열어주는 방법이다!
➡️ where 절에 기술한 여러 조건들에 대한 컬럼들을 결합 커럼 인덱스로 생성하면 더 좋은 성능을 보인다.
문제4. 아래 select 문장에 가장 좋은 인덱스를 생성하기 (결합 컬럼 인덱스 만들기)
select empno, ename, sal from emp where empno=7788 and ename='SCOTT' and sal=3000; -- 결합컬럼 인덱스 만들기 create index emp_empno_ename_sal on emp(empno,sal,ename); -- 실행계획 확인하기 explain plan for select empno, ename, sal from emp where empno=7788 and ename='SCOTT' and sal=3000; select * from table(dbms_xplan.display); ---------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 33 | 1 (0)| 00:00:01 | |* 1 | INDEX RANGE SCAN| EMP_EMPNO_ENAME_SAL | 1 | 33 | 1 (0)| 00:00:01 | ----------------------------------------------------------------------------------------➡️
emp_empno_ename_sal나는 이렇게 길게 만들었지만 이렇게 하지 않고 보통emp_indx1이런식으로 만들어준다.
✔️ index full scan
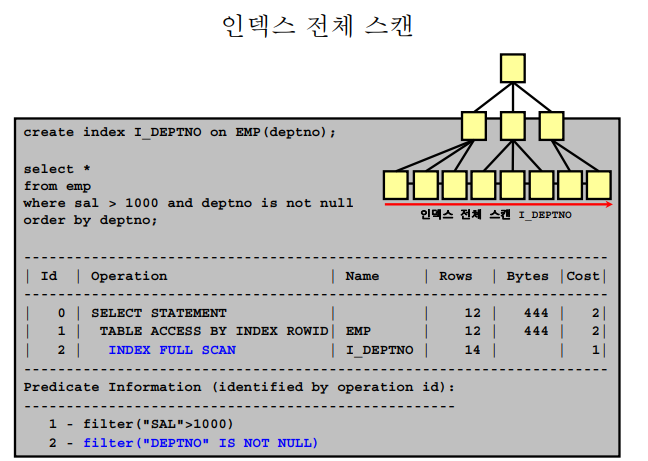
💡 인덱스 풀 스캔은 인덱스의 구조에 따라 전체를 스캔하는 스캔 방법이다.
@demobld
create index emp_sal on emp(sal);
explain plan for
select /*+ index_fs(emp emp_sal) */ count(*)
from emp
where sal >= 0;
select * from table(dbms_xplan.display);
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 1 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
|* 2 | INDEX RANGE SCAN| EMP_SAL | 14 | 182 | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------❓ index full scan 힌트를 줬는데 왜
INDEX RANGE SCAN을 액세스?????
: index full scan을 하려면 몇가지 조건이 있는데 그 조건중에 하나가 index full san을 하려는 컬럼에 not null 제약이 걸려있어야 한다.alter table emp modify sal not null; explain plan for select /*+ index_ffs(emp emp_sal) */ count(*) from emp where sal >= 0; select * from table(dbms_xplan.display); --------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 13 | 2 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 13 | | | |* 2 | INDEX FAST FULL SCAN| EMP_SAL | 14 | 182 | 2 (0)| 00:00:01 | ---------------------------------------------------------------------------------➡️ not null 제약을 만들고
index_fs를 썼지만 옵티마이저가 index range scan 을 했다. 그 이유는 옵티마이저가 판단했을때 index range scan이 비용이 더 적게 들었기 때문이다! 그래서 더 비용이 적게 드는 index fast full로 유도했더니INDEX FAST FULL SCAN으로 실행계획이 출력되었다.index_ffs힌트!!!
✍🏻 어떤 원리로 작동?
index full scan index fast full scan
index_fs index_ffs
인덱스의 구조에 따라 스캔 세그먼트 전체를 스캔
정렬이 보장된다. 정렬이 보장되지 않는다.
single block i/o multi block i/o
병렬 스캔 불가능 병렬 스캔 가능
✍🏻 인덱스 fast full scan으로 튜닝하는 첫번째 튜닝
(현업에서 많이 사용)
예제1.select /*+ index_ffs(emp emp_sal) parallel_index(emp, emp_sal, 4) */ count(*) from emp where sal > 0;
문제1.아래의 SQL의 속도를 높이기 위해 인덱스도 걸고 힌트도 주고 실행하시오select count(job) from emp;-- 1. 인덱스 생성 create index emp_job on emp(job); -- 2. not null 제약 alter table emp modify job not null; -- 3. 힌트 주기! explain plan for select /*+ index_ffs(emp emp_job) parallel_index(emp, emp_job, 4) */ count(job) from emp where job > ' '; select * from table(dbms_xplan.display); ------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib | ------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 6 | 2 (0)| 00:00:01 | | | | | 1 | SORT AGGREGATE | | 1 | 6 | | | | | | | 2 | PX COORDINATOR | | | | | | | | | | 3 | PX SEND QC (RANDOM) | :TQ10000 | 1 | 6 | | | Q1,00 | P->S | QC (RAND) | | 4 | SORT AGGREGATE | | 1 | 6 | | | Q1,00 | PCWP | | | 5 | PX BLOCK ITERATOR | | 14 | 84 | 2 (0)| 00:00:01 | Q1,00 | PCWC | | |* 6 | INDEX FAST FULL SCAN| EMP_JOB | 14 | 84 | 2 (0)| 00:00:01 | Q1,00 | PCWP | | -------------------------------------------------------------------------------------------------------------------➡️
PX어쩌구가 병렬로 처리를 한 것 !! 요게 나와야 한다!만약 제약을 걸 수 없다면 아래처럼
is not null조건 더 주기select /*+ index_ffs(emp emp_job) parallel_index(emp, emp_job, 4) */ count(job) from emp where job > ' ' and job is not null;
❓ 위에 있는 SQL을 더 빠르게 하려면 어떻게 해야할까?
alter session set db_file_multiblock_read_count=256;
✅ 4개씩 메모리를 올리는 것이다. multi block i/o가 가능하므로 db_file_multiblock_read_count 파라미터 설정 가능.
💡 index fast full scan이 block i/o를 하므로 db_file_multiblock_read_count를 크게 해서 더 빠르게 수행되도록 할 수 있다.
✍🏻 인덱스 fast full scan으로 튜닝하는 두번째 튜닝
(sqlp시험에 자주 출제되는 주관식 문제)
문제 아래의 SQL 튜닝하기
@demobld create index emp_ename on emp(ename); select /*+ gather_plan_statistics */ ename, sal, job, deptno from emp where ename like '%EN%' or ename like '%IN%'; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); ------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | 3 |00:00:00.01 | 3 | |* 1 | TABLE ACCESS FULL| EMP | 1 | 1 | 3 |00:00:00.01 | 3 | ------------------------------------------------------------------------------------➡️ full scan을 한다.
or가 튜닝하기 어려운 애이고, like연산자를 사용할 때 위와같이 와일드카드가 양쪽에 있으면 인덱스를 엑세스 하지 못한다. full table scan하는 실행계획이 출력된다. 와일드카드가뒤에만 있으면 index range scan이 가능하지만앞에 있다면 full table scan을 한다.⭐ 튜닝 후
select /*+ gather_plan_statistics no_query_transformation */ ename, sal, job from emp e, (select /*+ index_ffs(emp emp_ename) */ rowid rn from emp where ename like '%EN%' or ename like '%IN%' ) v where e.rowid = v.rn; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); --------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | --------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 3 |00:00:00.01 | 5 | | 1 | NESTED LOOPS | | 1 | 1 | 3 |00:00:00.01 | 5 | | 2 | VIEW | | 1 | 1 | 3 |00:00:00.01 | 4 | |* 3 | INDEX FAST FULL SCAN | EMP_ENAME | 1 | 1 | 3 |00:00:00.01 | 4 | | 4 | TABLE ACCESS BY USER ROWID| EMP | 3 | 1 | 3 |00:00:00.01 | 1 | ---------------------------------------------------------------------------------------------------중간 데이터를 검색하는 것을
index_ffs인덱스를 통해 검색한다. multi block i/o로!(책한번 넘길때 256장씩 팍팍 넘기겠다.) 그렇게 되면 빠르게 목차를 통해 rowid를 찾는다. 그리고 그 rowid로TABLE ACCESS한 것. rowid로 검색하는것이 가장 빠른데e.rowid = v.rn이렇게 rowid로 검색한다.
문제1. 아래의 테이블을 생성하기
create table customers
as
select * from sh.customers;문제2. customers 테이블에 cust_street_address에 인덱스를 생성하기
create index customers_indx1
on customers(cust_street_address);⭐ 중간 데이터 검색 쿼리문의 튜닝 방법
문제3. 아래의 SQL을 튜닝하기
select /*+ gather_plan_statistics */ cust_first_name, cust_last_name, cust_street_address, cust_city
from customers
where cust_street_address like '%Geneva%'
or cust_street_address like '%Mcintosh%';
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); 튜닝 sh 계정이 없어서 코드만 써놓음..!
select /*+ gather_plan_statistics no_query_transformation */
cust_first_name, cust_last_name, cust_street_address, cust_city
from customers c, (select /*+ index_ffs(c2 customers_indx1) */ rowid rn
from customers c2
where cust_street_address like '%Geneva%'
or cust_street_address like '%Mcintosh%') v
where c.rowid = v.rn; ➡️ 튜닝 전에는 버퍼의 갯수가 600개 정도였는데 튜닝 후에는 300개정도로 줄었다.
점심시간 문제 아래의 SQL을 튜닝하기
@demobld
create index emp_job on emp(job);
select empno, ename, sal, job
from emp
where job like '%NAG%'
or job like '%NAL%';
------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 5 |00:00:00.01 | 3 |
|* 1 | TABLE ACCESS FULL| EMP | 1 | 5 | 5 |00:00:00.01 | 3 |
------------------------------------------------------------------------------------튜닝 후!
select /*+ gather_plan_statistics no_query_transformation */ empno, ename, sal, job from emp e, (select /*+ index_ffs(e2 emp_job) */ rowid rn from emp e2 where job like '%NAG%' or job like '%NAL%') v where e.rowid = v.rn; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); ------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 5 |00:00:00.01 | 5 | | 1 | NESTED LOOPS | | 1 | 1 | 5 |00:00:00.01 | 5 | | 2 | VIEW | | 1 | 1 | 5 |00:00:00.01 | 4 | |* 3 | INDEX FAST FULL SCAN | EMP_JOB | 1 | 1 | 5 |00:00:00.01 | 4 | | 4 | TABLE ACCESS BY USER ROWID| EMP | 5 | 1 | 5 |00:00:00.01 | 1 | -------------------------------------------------------------------------------------------------
✔️ index skip scan
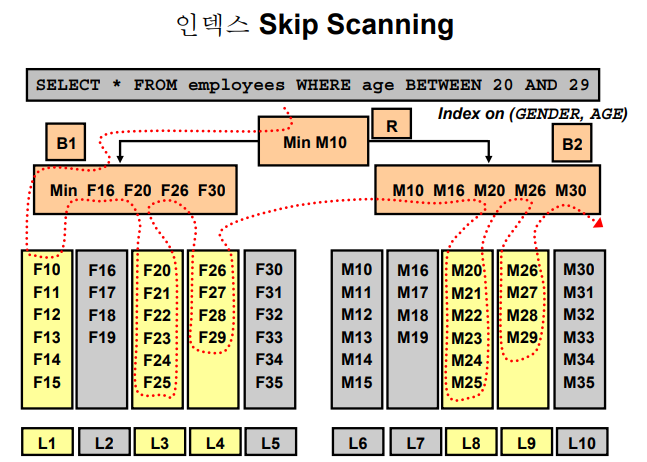
💡 인덱스 full scan 또는 fast full scan 으로 전체 스캔을 하는것이 아니라 full scan 하면서 중간중간 skip을 해서 더 성능을 높이는 스캔 방법!
full table scan
index skip scan
index range scan➡️ full table scan을 하면 너무 느려서 index range scan을 하고싶은데 할 수 없는 상황인 경우 index skip scan이 효과를 볼 수 있다!
실습
create index emp_deptno_sal on emp(deptno,sal); select /*+ gather_plan_statistics */ ename, sal from emp where sal = 2975; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); ------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 3 | |* 1 | TABLE ACCESS FULL| EMP | 1 | 1 | 1 |00:00:00.01 | 3 | ------------------------------------------------------------------------------------➡️ index range scan이 아닌 full table scan을 한다!
: 결합 컬럼 인덱스의 첫번째 컬럼이 where절이 없으면 해당 인덱스를 엑세스 할 수 없다. 지금deptno가 첫번째 컬럼인데 where 절에sal이 있다.
sal에 따로 단일 컬럼 인덱스를 걸면 좋지만 그럴 수 없는 상황이다.
이럴 때 사용하는 것이index skip scan!!
문제1. emp_deptno_saldml 인덱스 구조 확인
select deptno, sal, rowid
from emp
where deptno >= 0;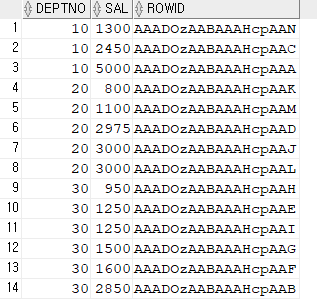
문제2. 위 SQL을 인덱스 스킵 스캔으로 유도해보기
select /*+ gather_plan_statistics index_ss(emp emp_deptno_sal)*/ ename, sal from emp where sal = 2975; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); -------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | -------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 2 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 1 | 1 |00:00:00.01 | 2 | |* 2 | INDEX SKIP SCAN | EMP_DEPTNO_SAL | 1 | 1 | 1 |00:00:00.01 | 1 | --------------------------------------------------------------------------------------------------------
➡️ emp_deptno_sal 인덱스를 전체 스캔할 수 밖에 없지만 중간중간 skip을 할 수 있어서 skip을 많이 하게 되면 될수록 full table scan 보다는 훨씬 좋은 성능을 보인다.
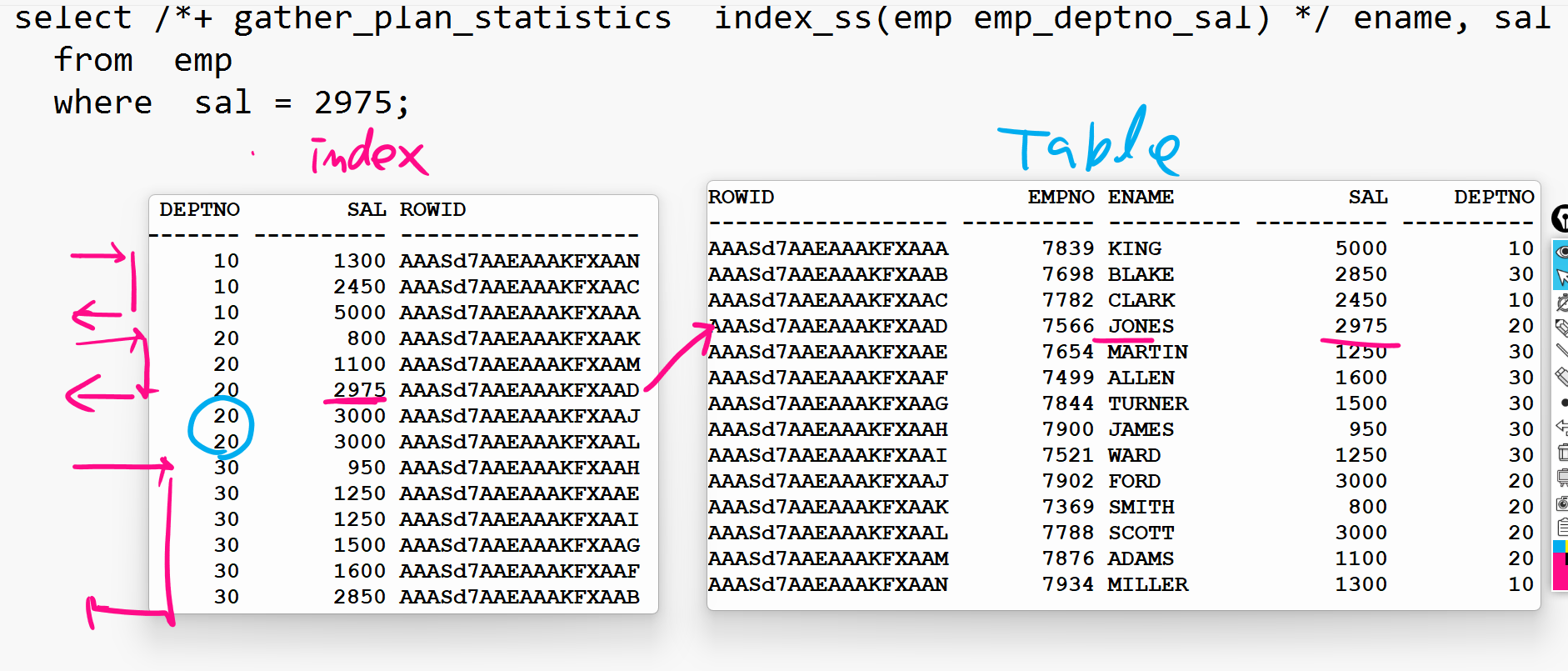
✅ index skip scan 사례
call count cpu elapsed disk query current rows mis Wait Ela
------- ------ -------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.03 0.03 0 0 0 0 1 0.00
Exec 1 0.00 0.00 0 0 0 0 0 0.00
Fetch 1 4.17 16.46 35791 35830 0 1 0 13.96
------- ------ -------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
Total 3 4.20 16.49 35791 35830 0 1 1 13.96
Event waited on Count Zero Ela Elapse AVG(Ela) MAX(Ela) Blocks
---------------------------------------- -------- -------- ---------- ---------- ---------- --------
db file sequential read 6 0 0.01 0.00 0.01 6
global cache cr request 4488 0 6.45 0.00 0.19 0
SQL*Net message to client 2 0 0.00 0.00 0.00 0
SQL*Net message from client 2 0 0.01 0.01 0.01 0
db file scattered read 2247 0 7.49 0.00 0.09 35785
latch free 14 0 0.00 0.00 0.00 0
Rows Row Source Operation
---------- ---------------------------------------------------
1 NESTED LOOPS
1 NESTED LOOPS
1 NESTED LOOPS
1 HASH JOIN OUTER
1 NESTED LOOPS
1 TABLE ACCESS BY INDEX ROWID OBJ#(6730) TBALJUM
1 INDEX UNIQUE SCAN OBJ#(7972) PK_TBALJUM
1 TABLE ACCESS BY INDEX ROWID OBJ#(6729) TBALJUD
1 INDEX RANGE SCAN OBJ#(102234) PK_TBALJUD
0 VIEW
0 TABLE ACCESS BY INDEX ROWID OBJ#(97234) TQC_POSTITEM_RESULTD
1 NESTED LOOPS
0 MERGE JOIN CARTESIAN
1 INDEX UNIQUE SCAN OBJ#(7972) PK_TBALJUM
0 TABLE ACCESS FULL OBJ#(97236) TQC_POSTITEM_RESULTM
0 INDEX RANGE SCAN OBJ#(97235) PK_TQC_POSTITEM_RESULTD <-- 얘때문에 느린것
1 TABLE ACCESS BY INDEX ROWID OBJ#(7045) TITEM
1 INDEX UNIQUE SCAN OBJ#(8502) PK_TITEM
1 TABLE ACCESS BY INDEX ROWID OBJ#(7086) TITEM_MASTER
1 INDEX UNIQUE SCAN OBJ#(101713) PK_TITEM_MASTER
1 TABLE ACCESS BY INDEX ROWID OBJ#(7438) TUNIT
1 INDEX UNIQUE SCAN OBJ#(9139) PK_TUNIT
TQC_POSTITEM_RESULTM
IDX_QC_POSTITEM_RESULTM_01 1 NU B*T ITEM_CODE
IDX_QC_POSTITEM_RESULTM_02 2 NU B*T QC_GB_CODE + QC_POSTITEM_NO
IDX_QC_POSTITEM_RESULTM_03 3 NU B*T QC_GB_CODE + BALJU_NO + ITEM_CODE
IDX_QC_POSTITEM_RESULTM_04 4 NU B*T QC_GB_CODE + ITEM_CODE + BALJU_NO
IDX_QC_POSTITEM_RESULTM_05 5 NU B*T QC_GB_CODE + RECEIPT_NO + ITEM_CODE
IDX_QC_POSTITEM_RESULTM_06 6 NU B*T QC_GB_CODE + QC_POSTITEM_DATE + ITEM_CODE
IDX_QC_POSTITEM_RESULTM_07 7 NU B*T QC_POSTITEM_DATE + QC_GB_CODE + ITEM_CODE
PK_TQC_POSTITEM_RESULTM 8 UN B*T QC_POSTITEM_NO db file scattered read는 full table scan 때문에 느린것이다.
global cache cr request는 RAC 때문에 느린 것. elapsed (16초) - cpu (4초) = 대기시간이 12초. 뭐때문에 느린것? 풀테이블 스캔 때문에 느리다. 관련 SQL 찾아서 보니 IDX_QC_POSTITEM_RESULTM_03에 BALJU_NO가 두번째에 있었다. index_ss으로 튜닝을 하니 아래처럼 줄어들었다.
call count cpu elapsed disk query current rows mis Wait Ela
------- ------ -------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0 0 0.00
Exec 1 0.00 0.00 0 0 0 0 0 0.00
Fetch 1 0.00 0.08 15 35 0 1 0 0.08
------- ------ -------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
Total 3 0.00 0.08 15 35 0 1 0 0.08
Event waited on Count Zero Ela Elapse AVG(Ela) MAX(Ela) Blocks
---------------------------------------- -------- -------- ---------- ---------- ---------- --------
db file sequential read 15 0 0.07 0.00 0.01 15
global cache cr request 8 0 0.00 0.00 0.00 0
SQL*Net message to client 2 0 0.00 0.00 0.00 0
SQL*Net message from client 2 0 0.01 0.01 0.01 0문제 아래의 SQL을 인덱스 skip scan으로 유도하기
@demobld create index emp_job_empno on emp(job,empno); select empno, job, sal from emp where empno = 7902; -- 튜닝 후 select /*+ gather_plan_statistics index_ss(emp emp_job_empno)*/ empno, job, sal from emp where empno = 7902; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); ------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 2 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 1 | 1 |00:00:00.01 | 2 | |* 2 | INDEX SKIP SCAN | EMP_JOB_EMPNO | 1 | 1 | 1 |00:00:00.01 | 1 | -------------------------------------------------------------------------------------------------------➡️ 인덱스 스킵 스캔의 효과를 보려면
결합 컬럼 인덱스의 선두 컬럼의 data 종류가 몇가지 안되어야 유리하다.create index emp_job_sal on emp(job,sal); select job, sal, rowid from emp where job > ' ' ;
➡️ 선두 컬럼은job인데 5개가 있다. 이게 별로 없어야 유리하다는 말!
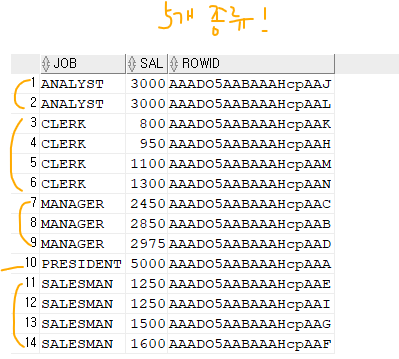
문제2. 아래 두개의 인덱스 중에 어느 인덱스가 index skip scan 효과를 볼 수 있는가? : 위에꺼!
create index emp_deptno_sal on emp(deptno,sal);
create index emp_job_sal on emp(job,sal);문제3. emp 테이블의 부서번호가 몇개 있는지 하나의 SQL로 한번에 출력하기
select count(distinct deptno)
from emp;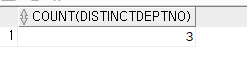
문제4. 아래의 테이블을 만들고 아래의 SQL을 튜닝하기
create table sales500 as select * from sh.sales; create index sales500_indx1 on sales500("channel_id", "cust_id") ; -- 튜닝 전 select /*+ full(sales500) */ * from sales500 where "cust_id" = 2869; -- 튜닝 후 select /*+ gather_plan_statistics index_ss(sales500 sales500_indx1)*/ * from sales500 where "cust_id" = 2869; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); ----------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | ----------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 50 |00:00:00.65 | 57 | 53 | | 1 | TABLE ACCESS BY INDEX ROWID| SALES500 | 1 | 141 | 50 |00:00:00.65 | 57 | 53 | |* 2 | INDEX SKIP SCAN | SALES500_INDX1 | 1 | 2975 | 50 |00:00:00.01 | 8 | 7 | -----------------------------------------------------------------------------------------------------------------
✔️ index merge scan
💡 두개의 인덱스를 같이 사용해서 하나의 인덱스만 사용했을때 보다 더 큰 시너지 효과를 보는 스캔 방법이다.
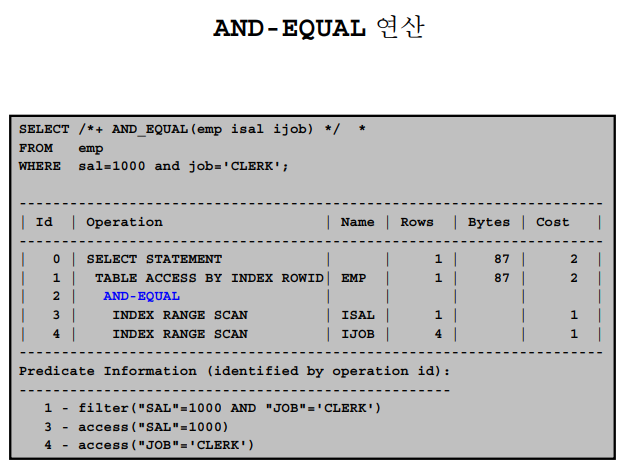
@demo
create index emp_sal on emp(sal);
create index emp_job on emp(job);두군데 다 인덱스가 있다. 그러면 아래의 2개 인덱스중 오라클은 어느 인덱스를 엑세스 할까?
select /*+ gather_plan_statistics */ *
from emp
where sal = 1100 and job = 'CLERK';❓ 월급 인덱스를 엑세스했다. 선택도가 더 좋아서. 그러면 둘다 선택도가 좋다면?? 두개 다 사용해서 시너지 효과를 내자 !! ->
index merge scanselect /*+ gather_plan_statistics and_equal(emp emp_sal emp_job) */ * from emp where sal = 1100 and job = 'CLERK'; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); ------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 4 | |* 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 1 | 1 |00:00:00.01 | 4 | | 2 | AND-EQUAL | | 1 | | 1 |00:00:00.01 | 3 | |* 3 | INDEX RANGE SCAN | EMP_SAL | 1 | 1 | 2 |00:00:00.01 | 2 | |* 4 | INDEX RANGE SCAN | EMP_JOB | 1 | 4 | 1 |00:00:00.01 | 1 | -------------------------------------------------------------------------------------------------➡️ 책의 내용을 찾아내는데 목차 2개를 같이 읽어서 더 빨리 책의 내용을 찾는 방법이다!
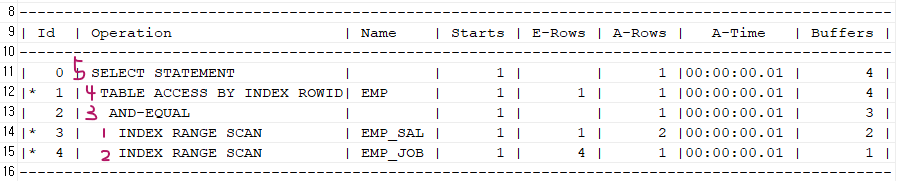
문제1. 아래의 환경을 만드시오!
create table sales600 as select * from sh.sales; create index saels600_indx1 on sales600("channel_id"); create index saels600_indx2 on sales600("prod_id");
문제2. 아래의 SQL이 index merge scan이 되도록 튜닝하시오 (and_equal사용)
select /*+ gather_plan_statistics and_equal(s saels600_indx1 saels600_indx2) */ * from sales600 s where "channel_id" = 3 and "prod_id" = 144; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); ----------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | ----------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 50 |00:00:00.01 | 43 | 6 | |* 1 | TABLE ACCESS BY INDEX ROWID| SALES600 | 1 | 82 | 50 |00:00:00.01 | 43 | 6 | | 2 | AND-EQUAL | | 1 | | 50 |00:00:00.01 | 40 | 6 | |* 3 | INDEX RANGE SCAN | SAELS600_INDX2 | 1 | 49 | 103 |00:00:00.01 | 13 | 0 | |* 4 | INDEX RANGE SCAN | SAELS600_INDX1 | 1 | 495K| 61 |00:00:00.01 | 27 | 6 | -----------------------------------------------------------------------------------------------------------------➡️ 별칭쓸거면 별칭으로 ! 별칭 썼는데 테이블명 힌트안에 쓰면 안먹힘
✔️ index bitmap merge scan
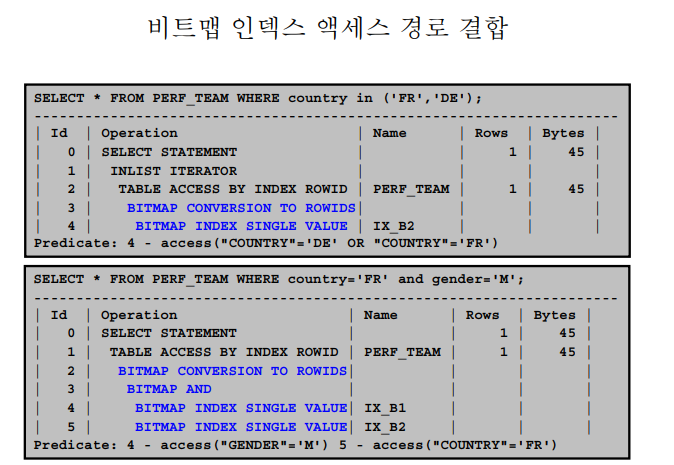
💡 두개의 인덱스를 같이 스캔해서 테이블 액세스를 줄이는 방법은 index merge scan과 똑같은데, 차이가 있다면 비트맵을 이용해서 인덱스의 사이즈를 아주 많이 줄인다! 그래서 인덱스를 스캔하는 시간이 짧아진다.
✍🏻 인덱스를 저장하는 방식에 따라 2개의 인덱스로 나뉜다.
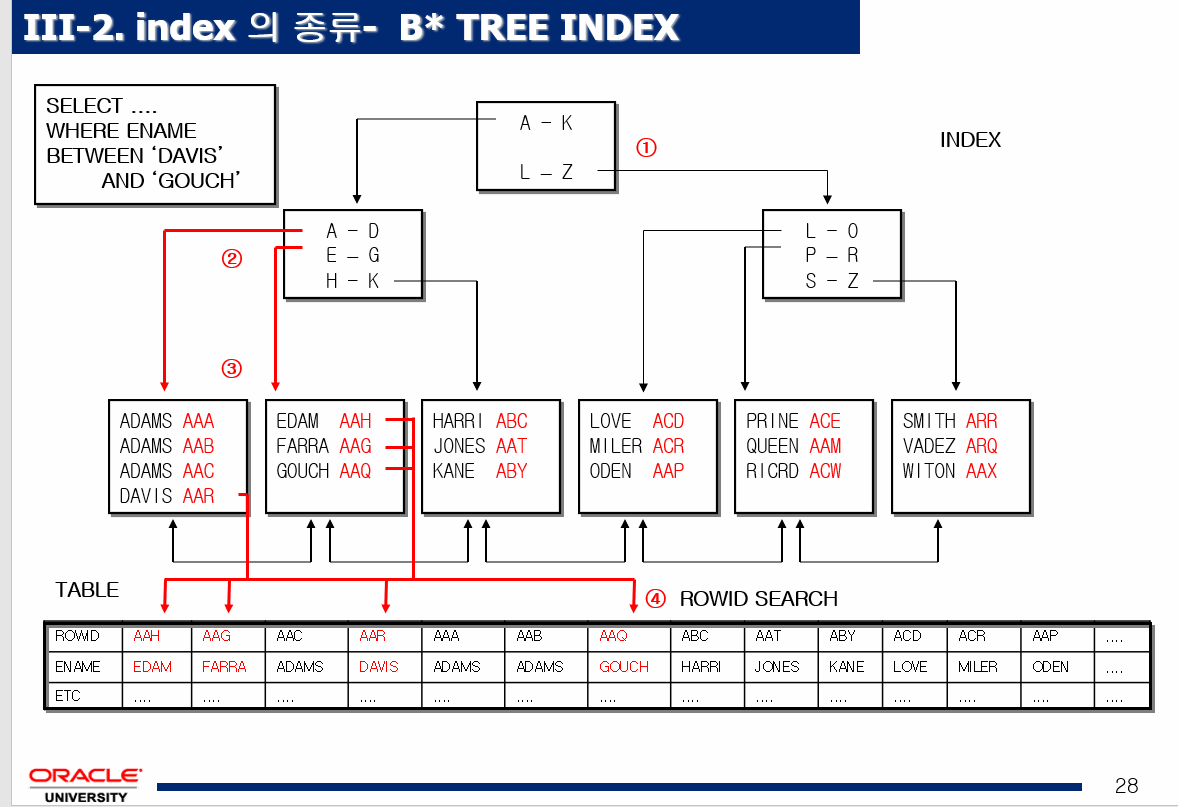
1. b-tree index: 나무를 거꾸로 뒤집어 놓은 구조의 인덱스
select ename, sal from emp where ename='SMITH';➡️ 이름이 SMITH인 사원을 찾기위해 root(1번) 부터 간다. 그후에 branch, leaf 가서
ARR을 찾고 데이터를 찾는다.
➡️ full table scan은 SMITH를 찾아도 끝까지 다 찾는것이다. index스캔은 차례를 보고 바로 찾는것이다. tree구조가 바로 이 구조이다! full scan 보다 속도가 빠르다. 오라클, mysql 모두 다 이구조이다.
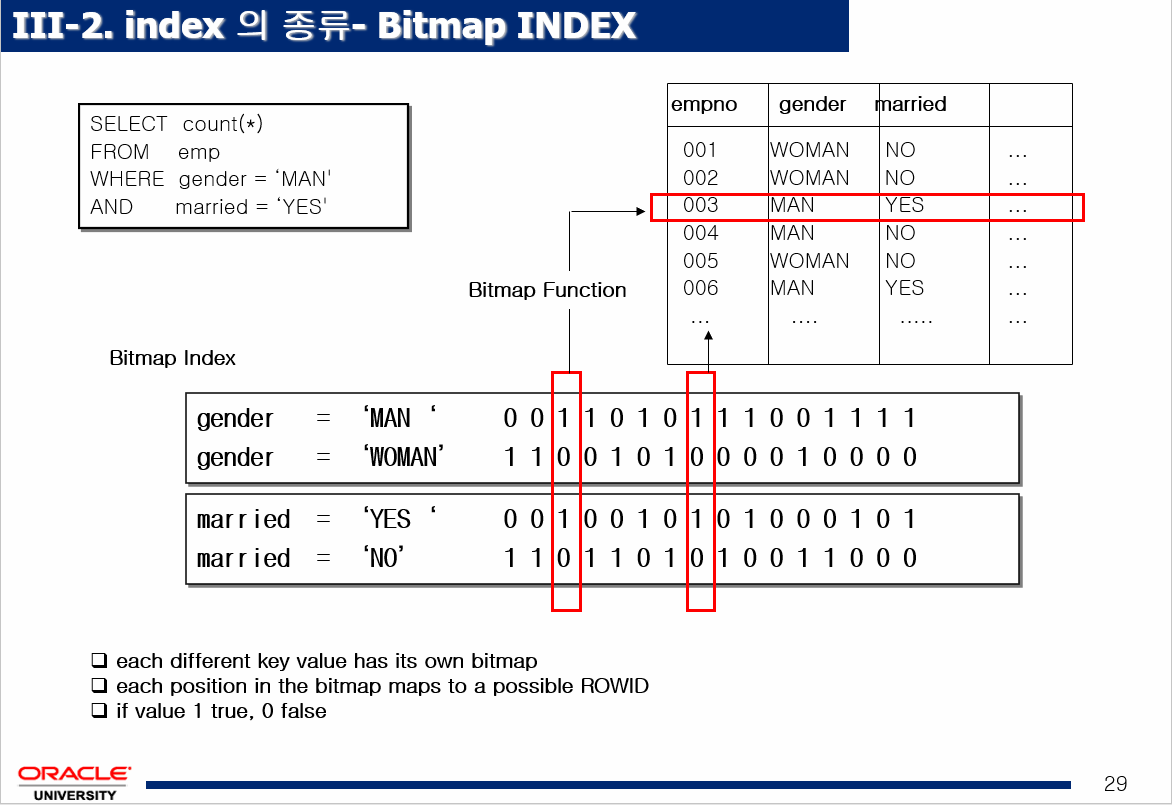
2. bitmap index: 구조는 b-tree 인덱스와 같지만 leaf가 bitmap으로 구성되어있는 인덱스 (bit는 숫자 0,1을 말하고 map은 지도. 숫자 0과1로 구성된 지도!)
➡️ 성별과 같이 데이터의 종류가 몇가지 되지 않는 컬럼에 거는 인덱스가 bitmap 인덱스이다. 성별과 같은 컬럼에 b-tree인덱스를 건다면 성능이 좋지 않다. 그냥 full scan index를 하는것이 낫다!!select * from emp where gender='여자'; ↑ 비트맵 인덱스를 걸면 풀테이블 스캔 보다 더 검색속도가 빠르다. 지금 상황에 제일 느린것은 b-tree 인덱스!
- bitmap 인덱스 장점 : 성별과 같이 중복된 데이터가 많은 컬럼에 유리한 인덱스
- bitmap 인덱스 단점 : 락이 row단위 락이 아니라 세그먼트 단위 락이 걸린다.
실습
create bitmap index emp_bit_job on emp(job);
# A session # B session
update emp
set job='kkkk' update emp
where job='SALESMAN'; set job='aaaa'
where job='ANALYST';➡️ 우리는 지금 락이 걸리지는 않았지만 (테이블이 작아서) 주로 쿼리만 하는 테이블에는 비트맵 인덱스를 생성하는것이 바람직하다. update가 자주 일어나는 테이블을 생성하지 않는게 좋다!
@demobld create bitmap index emp_bit_job on emp(job); create bitmap index emp_bit_deptno on emp(deptno); select /*+ gather_plan_statistics */ ename, sal, job from emp where job='SALESMAN' and deptno=30; --------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | --------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 4 |00:00:00.01 | 2 | |* 1 | TABLE ACCESS BY INDEX ROWID | EMP | 1 | 4 | 4 |00:00:00.01 | 2 | | 2 | BITMAP CONVERSION TO ROWIDS| | 1 | | 6 |00:00:00.01 | 1 | |* 3 | BITMAP INDEX SINGLE VALUE | EMP_BIT_DEPTNO | 1 | | 1 |00:00:00.01 | 1 | --------------------------------------------------------------------------------------------------------- -- index_combine 힌트 사용(bitmap merge scan) select /*+ gather_plan_statistics index_combine(emp)*/ ename, sal, job from emp where job='SALESMAN' and deptno=30; --------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | --------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 4 |00:00:00.01 | 3 | | 1 | TABLE ACCESS BY INDEX ROWID | EMP | 1 | 4 | 4 |00:00:00.01 | 3 | | 2 | BITMAP CONVERSION TO ROWIDS| | 1 | | 4 |00:00:00.01 | 2 | | 3 | BITMAP AND | | 1 | | 1 |00:00:00.01 | 2 | |* 4 | BITMAP INDEX SINGLE VALUE| EMP_BIT_DEPTNO | 1 | | 1 |00:00:00.01 | 1 | |* 5 | BITMAP INDEX SINGLE VALUE| EMP_BIT_JOB | 1 | | 1 |00:00:00.01 | 1 | ---------------------------------------------------------------------------------------------------------➡️ 두개의 비트맵 인덱스를 하나로 합쳐서 하나의 비트맵 인덱스로 만들었고 테이블을 엑세스 한 것이다. 기존의 b-tree 인덱스가 A4지 20장 이라고 한다면 bitmap 인덱스는 A4지 1장이다.
❗ 꼭 비트맵 인덱스가 아니고 b-tree 인덱스여도 index combine 힌트 효과를 볼 수 있다.
b tree 인덱스 -> bitmap 으로 conversion한다.오늘의 마지막 문제 아래의 환경을 만들고 아래의 SQL을 튜닝하기!
@demobld create index emp_deptno on emp(deptno); create index emp_job on emp(job); -- 튜닝전 select /*+ gather_plan_statistics and_equal(emp emp_deptno emp_job) */ ename, sal, job from emp where job='SALESMAN' and deptno=30; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); ---------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ---------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 4 |00:00:00.01 | 5 | |* 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 4 | 4 |00:00:00.01 | 5 | | 2 | AND-EQUAL | | 1 | | 4 |00:00:00.01 | 4 | |* 3 | INDEX RANGE SCAN | EMP_JOB | 1 | 4 | 8 |00:00:00.01 | 3 | |* 4 | INDEX RANGE SCAN | EMP_DEPTNO | 1 | 6 | 4 |00:00:00.01 | 1 | ---------------------------------------------------------------------------------------------------- -- 튜닝후 select /*+ gather_plan_statistics index_combine(emp) */ ename, sal, job from emp where job='SALESMAN' and deptno=30; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); --------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | --------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 4 |00:00:00.01 | 3 | | 1 | TABLE ACCESS BY INDEX ROWID | EMP | 1 | 4 | 4 |00:00:00.01 | 3 | | 2 | BITMAP CONVERSION TO ROWIDS | | 1 | | 4 |00:00:00.01 | 2 | | 3 | BITMAP AND | | 1 | | 1 |00:00:00.01 | 2 | | 4 | BITMAP CONVERSION FROM ROWIDS| | 1 | | 1 |00:00:00.01 | 1 | |* 5 | INDEX RANGE SCAN | EMP_DEPTNO | 1 | | 6 |00:00:00.01 | 1 | | 6 | BITMAP CONVERSION FROM ROWIDS| | 1 | | 1 |00:00:00.01 | 1 | |* 7 | INDEX RANGE SCAN | EMP_JOB | 1 | | 4 |00:00:00.01 | 1 | ---------------------------------------------------------------------------------------------------------
