
SQL 튜닝
⭐ 조인 문장 튜닝시 중요한 점 2가지
1. 조인 순서: 작은 테이블 또는 where 조건에 의해 엑세스 되는 데이터의 양이 작은 테이블을 driving table로 구성해야한다.1) ordered : from 절에서 기술한 테이블 순서대로 조인해라 2) leading : leading 절 힌트 안에 쓴 테이블 순서대로 조인해라
2. 조인 방법1) nested loop 조인 : 조인하는 데이터의 양이 작은 경우에 사용! 동시에 수행되는 SQL인 경우 사용 : use_nl() 2) hash 조인 : 조인하려는 데이터의 양이 많은 경우에 사용! 자주 수행되지 않는 쿼리문의 경우 사용 : use_hash 3) sort merge 조인 : 조인하려는 데이터의 양이 많은 경우 사용! hash 조인으로 수행될 수 없는 경우 사용 : use_merge() * hash join이 가능하려면 SQL의 where절의 조인 연결고리 조건이 =(이퀄) 조건이어야 한다.
✏️ 조인 순서의 중요성
✍🏻 nested loop join의 조인순서 튜닝
(어제 수업에 이어짐)
어제 수업 내용
✔️ where 절에 조인 연결고리 외에 추가적 조건이 없는 경우
- 2개의 테이블을 조인한다면 작은 테이블 -> 큰 테이블
- 3개의 테이블을 조인한다면 아주 작은 테이블 -> 작은테이블 -> 큰 테이블
✔️ where절에 조인 연결고리와 더불어 추가적인 조건이 있는 경우
: 조건에 의해 엑세스 되는 데이터의 양이 작은것을 먼저 driving 하게 하면 된다.
# 예)
select e.ename, d.loc
from emp e, dept d
where e.deptno=d.deptno
and e.job='SALESMAN'; -- 4건
and d.loc='CHICAGO'; -- 1건➡️ 조인 순서 : dept -> emp
➡️ 조인 방법 : nested loop조인 하기!
➡️ /*+ gather_plan_statistics leading(d e) use_nl(e) */
문제1. 아래 SQL의 조인순서와 조인방법을 힌트로 결정하기
✔️ 튜닝전
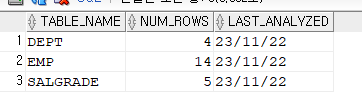
select e.ename, d.loc, s.grade from emp e, dept d, salgrade s where e.deptno=d.deptno and e.sal between s.losal and s.hisal and e.job='SALESMAN' and d.loc='CHICAGO' and s.grade=3;✔️ 테이블 건수 구하기
exec dbms_stats.gather_table_stats('SCOTT', 'SALGRADE'); exec dbms_stats.gather_table_stats('SCOTT', 'EMP'); exec dbms_stats.gather_table_stats('SCOTT', 'DEPT'); select table_name, num_rows, last_analyzed from user_tables where table_name in ('SALGRADE','EMP', 'DEPT');
✔️ where절 조건의 건수 구하기select count(*) from emp where job='SALESMAN'; -- 4건 select count(*) from dept where loc='CHICAGO'; -- 1건 select count(*) from salgrade where grade=3; -- 1건➡️ 건수만 보면 dept -> salgrade -> emp 하면 되지만 dept랑 salgrade 테이블은 연결고리가 없다. 무조건 건수가 작은것을 앞에 두는것이 아니라 연결고리가 있는 순서로 정해준다!!
1. dept -> emp -> salgrade #1건 -- 건수 조사 (4건) select count(*) from emp e, dept d where e.deptno=d.deptno and e.job='SALESMAN' and d.loc='CHICAGO'; 2. salgrade -> emp -> dept #1건 -- 건수 조사 (2건) select count(*) from emp e, salgrade s where e.sal between s.losal and s.hisal and e.job='SALESMAN' and s.grade=3; * dept, emp두개가 조인되었을 때와 salgrade, emp두개가 조인되었을대 건수가 작은것으로 하면 됨➡️ 만약 조인되는 연결고리에 전부 인덱스가 있어서 full table scan이 나오지 않는다는 상황이라면 위 2가지 조인 순서중에 2번 조인순서가 적합합니다. 1번은 조인 횟수가 4번인 반면 2번은 조인 횟수가 2번이다.
1번 조인시도 4번 조인시도 dept ------> emp ------> salgrade 1번 조인시도 2번 조인시도 salgrade ------> emp ------> dept -> 얘가 조인 순서!✔️ 조인 순서와 조인 방법을 힌트로 기술
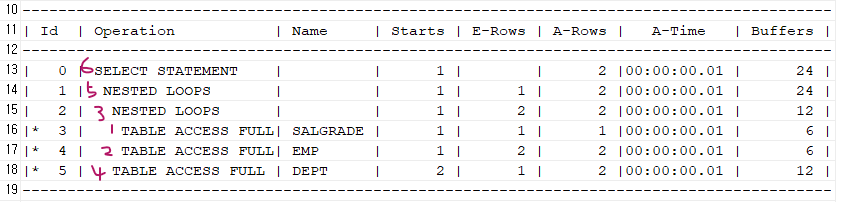
select /*+ gather_plan_statistics leading(s e d) use_nl(e) use_nl(d) */ e.ename, d.loc, s.grade from emp e, dept d, salgrade s where e.deptno=d.deptno and e.sal between s.losal and s.hisal and e.job='SALESMAN' and d.loc='CHICAGO' and s.grade=3;
❓ 반대로 해보자
select /*+ gather_plan_statistics leading(d e s) use_nl(e) use_nl(s) */ e.ename, d.loc, s.grade from emp e, dept d, salgrade s where e.deptno=d.deptno and e.sal between s.losal and s.hisal and e.job='SALESMAN' and d.loc='CHICAGO' and s.grade=3; ------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | 2 |00:00:00.01 | 36 | | 1 | NESTED LOOPS | | 1 | 1 | 2 |00:00:00.01 | 36 | | 2 | NESTED LOOPS | | 1 | 1 | 4 |00:00:00.01 | 12 | |* 3 | TABLE ACCESS FULL| DEPT | 1 | 1 | 1 |00:00:00.01 | 6 | |* 4 | TABLE ACCESS FULL| EMP | 1 | 1 | 4 |00:00:00.01 | 6 | |* 5 | TABLE ACCESS FULL | SALGRADE | 4 | 1 | 2 |00:00:00.01 | 24 | ------------------------------------------------------------------------------------------➡️ 버퍼의 갯수가 24개였는데 36개로 늘어났다.
문제2. 아래의 SQL을 튜닝하기! 조인 순서와 방법을 힌트로 결정하기
-- 튜닝 전
select e.ename, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno=d.deptno
and e.sal between s.losal and s.hisal
and e.job='ANALYST'
and d.loc='DALLAS'
and s.grade=4;
✔️ where절 건수 구하기
select count(*) from emp where job='ANALYST'; -- 2건 select count(*) from dept where loc='DALLAS'; -- 1건 select count(*) from salgrade where grade=4; -- 1건✔️ salgrade -> emp ? dept -> emp? 어떤거부터 할지 건수 구하기
1. dept -> emp -> salgrade -- 건수 조사 (2건) select count(*) from emp e, dept d where e.deptno=d.deptno and e.job='ANALYST' and d.loc='DALLAS'; 2. salgrade -> emp -> dept -- 건수 조사 (2건) select count(*) from emp e, salgrade s where e.sal between s.losal and s.hisal and e.job='ANALYST' and s.grade=4;✔️ 튜닝 (건수가 같으므로 dept->emp->salgrade / salgrade->emp->dept 버퍼 갯수 같다)
select /*+ gather_plan_statistics leading(d e s) use_nl(e) use_nl(s) */ e.ename, d.loc, s.grade from emp e, dept d, salgrade s where e.deptno=d.deptno and e.sal between s.losal and s.hisal and e.job='ANALYST' and d.loc='DALLAS' and s.grade=4; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); ------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | 2 |00:00:00.01 | 24 | | 1 | NESTED LOOPS | | 1 | 1 | 2 |00:00:00.01 | 24 | | 2 | NESTED LOOPS | | 1 | 1 | 2 |00:00:00.01 | 12 | |* 3 | TABLE ACCESS FULL| DEPT | 1 | 1 | 1 |00:00:00.01 | 6 | |* 4 | TABLE ACCESS FULL| EMP | 1 | 1 | 2 |00:00:00.01 | 6 | |* 5 | TABLE ACCESS FULL | SALGRADE | 2 | 1 | 2 |00:00:00.01 | 12 | ------------------------------------------------------------------------------------------⭐ 연결고리가 없는 조인순서로 조인 했을 때의 결과 (dept->salgrade->emp)
: 연결고리가 없어도 결과는 잘 출력이 된다. dept와 salgrade를 조인할 때 연결 고리가 없으므로 where절에 조인 조건 없이 조인하는 SQL처럼 조인되는 데이터의 양이 많아질 수 있다. 그런데 dept table에서 1건만 엑세스 되기 때문에(d.loc='DALLAS') 조인되는 양이 그렇게 많지는 않다. 오히려 이게 성능이 더 좋을수도 있음select /*+ gather_plan_statistics leading(d s e) use_nl(s) use_nl(e) */ e.ename, d.loc, s.grade from emp e, dept d, salgrade s where e.deptno=d.deptno and e.sal between s.losal and s.hisal and e.job='ANALYST' and d.loc='DALLAS' and s.grade=4; ------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | 2 |00:00:00.01 | 18 | | 1 | NESTED LOOPS | | 1 | 1 | 2 |00:00:00.01 | 18 | | 2 | NESTED LOOPS | | 1 | 1 | 1 |00:00:00.01 | 12 | |* 3 | TABLE ACCESS FULL| DEPT | 1 | 1 | 1 |00:00:00.01 | 6 | |* 4 | TABLE ACCESS FULL| SALGRADE | 1 | 1 | 1 |00:00:00.01 | 6 | |* 5 | TABLE ACCESS FULL | EMP | 1 | 1 | 2 |00:00:00.01 | 6 | ------------------------------------------------------------------------------------------
문제3. 위 SQL의 성능을 더 높이기 위해 인덱스를 생성하기
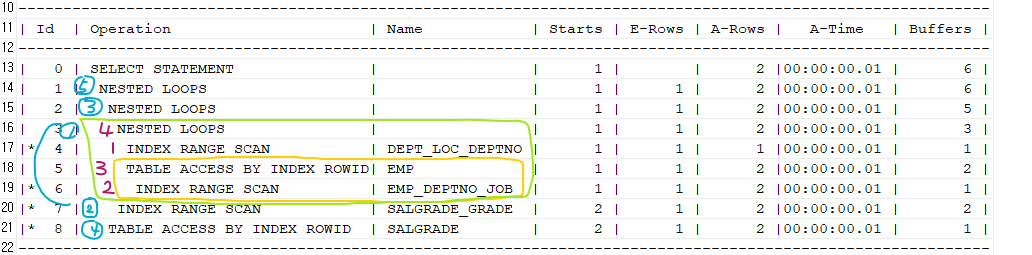
select /*+ gather_plan_statistics leading(d e s) use_nl(e) use_nl(s) */ e.ename, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno=d.deptno -- e.deptno 요기
and e.sal between s.losal and s.hisal -- e.sal 요기
and e.job='ANALYST' -- e.job
and d.loc='DALLAS' -- d.loc
and s.grade=4; -- s.grade#1. emp 테이블을 위해서는 deptno + job 결합컬럼 인덱스 -> 조인 순서가 d e s 라서 create index emp_deptno_job on emp(deptno,job); #2. dept 테이블을 위해서는 loc + deptno 결합컬럼 인덱스 create index dept_loc_deptno on dept(loc,deptno); #3. salgrade 테이블을 위해서는 grade에 단일컬럼 인덱스 create index salgrade_grade on salgrde(grade);➡️ loc를 맨처음으로 엑세스 해서 deptno를 찾고 e.deptno에 넘긴다. e.deptno가 인덱스를 타서 job을 찾는다. 그 후 이름에 대한 정보가 인덱스에 없기때문에 테이블 엑세스를 하는데 결합컬럼 인덱스에 ename도 포함되어있었다면 그냥 인덱스만 엑세스 할 것이다.
➡️ 1,2,3,4 결과를 salgrade와 조인한다.
실행계획을 볼 때는 같은 테이블에 관련된 부분은 한 묶음으로 묶어버린다. 묶은 상태에서 실행계획을 읽으면 된다.가장 중요하게 봐야하는 부분은 큰 그림을 보면 되는데, 내가 준 힌트대로 조인 순서와 방법이 나왔는지 확인하면 된다.
🚨 다음과 같이 힌트를 주지 않도록 주의하기
select /*+ gather_plan_statistics leading(dept emp salgrade) use_nl(emp) use_nl(salgrade) */ e.ename, d.loc, s.grade
from emp e, dept d, salgrade s
where e.deptno=d.deptno
and e.sal between s.losal and s.hisal
and e.job='ANALYST'
and d.loc='DALLAS'
and s.grade=4; ❗ from 절이 먼저 실행되므로 지금 emp->e로 바뀌었는데 힌트를 e로 안주고 emp로 힌트를 주면 실행계획이 제대로 나오지 않는다!! 이런 경우 꼭 별칭을 써주기
💡 OLTP에서는 nested loop 조인을 써야하는데 느리다?
nested loop 조인이 느린 경우는 보통 조인 연결고리 컬럼에 인덱스가 없는 경우가 가장 느린 경우이고, 조인 연결고리에 인덱스가 있는데 느린 경우는 조인 순서가 잘못되었기 때문
✍🏻 해쉬 조인의 조인순서 튜닝
1. 2개의 테이블의 조인 튜닝
select e.ename, d.loc from emp e, dept d where e.deptno=d.deptno;
❓ 해쉬 테이블을 emp로 하려면
select /*+ gather_plan_statistics leading(e d) use_hash(d) */ e.ename, d.loc
from emp e, dept d
where e.deptno=d.deptno;
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 14 | | | |
|* 1 | HASH JOIN | | 1 | 14 | 14 |00:00:00.01 | 14 | 1753K| 1753K| 802K (0)|
| 2 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | |
| 3 | TABLE ACCESS FULL| DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | |
----------------------------------------------------------------------------------------------------------------❓ 해쉬 테이블을 dept로 하려면
select /*+ gather_plan_statistics leading(d e) use_hash(e) */ e.ename, d.loc
from emp e, dept d
where e.deptno=d.deptno;
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 14 | | | |
|* 1 | HASH JOIN | | 1 | 14 | 14 |00:00:00.01 | 14 | 1696K| 1696K| 1072K (0)|
| 2 | TABLE ACCESS FULL| DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | |
| 3 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | |
----------------------------------------------------------------------------------------------------------------2. 3개의 테이블의 조인 튜닝
-- 일단 table하나 만들기 create table bonus as select empno, sal*1.2 as bonus from emp; select /*+ gather_plan_statistics leading(e d b) use_hash(d) use_hash(b) */ e.ename, d.loc, b.bonus from emp e, dept d, bonus b where e.deptno=d.deptno and e.empno=b.empno;
➡️ emp, dept둘중에는 emp가 hash table이다. 그리고 emp,dept 해시조인한 결과와 bonus 를 조인할때는 결과가 해시테이블이다.
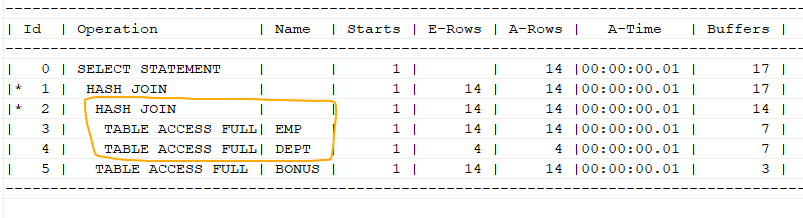
⭐ swap_join_inputs()
문제1. 실행계획이 아래와 같이 출력되게 하시오
select /*+ gather_plan_statistics leading(e d b) use_hash(d) use_hash(b) swap_join_inputs(b) */ e.ename, d.loc, b.bonus
from emp e, dept d, bonus b
where e.deptno=d.deptno
and e.empno=b.empno;
------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 17 | | | |
|* 1 | HASH JOIN | | 1 | 14 | 14 |00:00:00.01 | 17 | 1888K| 1888K| 1332K (0)|
| 2 | TABLE ACCESS FULL | BONUS | 1 | 14 | 14 |00:00:00.01 | 3 | | | |
|* 3 | HASH JOIN | | 1 | 14 | 14 |00:00:00.01 | 14 | 1557K| 1557K| 978K (0)|
| 4 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | |
| 5 | TABLE ACCESS FULL| DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | |
------------------------------------------------------------------------------------------------------------------- swap_join_inputs() : 해쉬조인시에 build input 테이블을 결정하는 힌트
- no_swap_join_inputs() : 해쉬조인시에 probe input 테이블을 결정하는 힌트
➡️ bonus가 만약 작다면 메모리에 보너스테이블이 올라가야 하므로 1번 힌트를 사용해서 emp,dept를 조인한 결과와 bonus 테이블을 조인할 때 bonus 테이블을 hash table로 만드는힌트이다.
문제2. 아래의 실행계획이 나오도록 힌트를 주시오
------------------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ------------------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 17 | | | | |* 1 | HASH JOIN | | 1 | 14 | 14 |00:00:00.01 | 17 | 1696K| 1696K| 1052K (0)| | 2 | TABLE ACCESS FULL | DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | | |* 3 | HASH JOIN | | 1 | 14 | 14 |00:00:00.01 | 10 | 1888K| 1888K| 1149K (0)| | 4 | TABLE ACCESS FULL| BONUS | 1 | 14 | 14 |00:00:00.01 | 3 | | | | | 5 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | | ------------------------------------------------------------------------------------------------------------------ select /*+ gather_plan_statistics leading(b e d) use_hash(e) use_hash(d) swap_join_inputs(d) */ e.ename, d.loc, b.bonus from emp e, dept d, bonus b where e.deptno=d.deptno and e.empno=b.empno;➡️ hash 테이블로 구성하는 테이블은 메모리로 올라가는 테이블이다. probe 테이블 보다는 데이터의 양이 적은게 메모리로 올라가야 한다.
문제3. 아래와 같이 실행계획이 나오게 하기
------------------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ------------------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 17 | | | | |* 1 | HASH JOIN | | 1 | 14 | 14 |00:00:00.01 | 17 | 1557K| 1557K| 635K (0)| |* 2 | HASH JOIN | | 1 | 14 | 14 |00:00:00.01 | 10 | 1888K| 1888K| 1127K (0)| | 3 | TABLE ACCESS FULL| BONUS | 1 | 14 | 14 |00:00:00.01 | 3 | | | | | 4 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | | | 5 | TABLE ACCESS FULL | DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | | ------------------------------------------------------------------------------------------------------------------ select /*+ gather_plan_statistics leading(b e d) use_hash(e) use_hash(d) no_swap_join_inputs(d) */ e.ename, d.loc, b.bonus from emp e, dept d, bonus b where e.deptno=d.deptno and e.empno=b.empno;
문제4. (점심시간 문제) 다음과 같이 실행계획이 나오게 하기
-- 환경구성
create table sales200 as select * from sh.sales;
create table times200 as select * from sh.times;
create table products200 as select * from sh.products;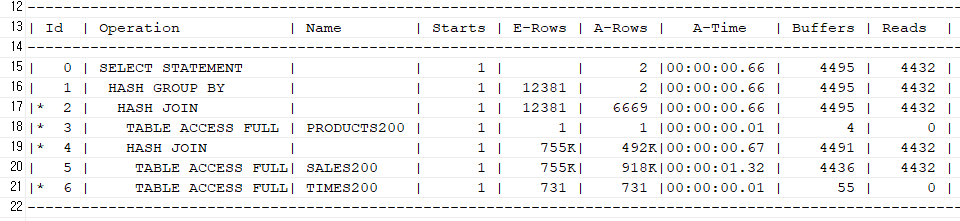
select /*+ gather_plan_statistics leading(s t p) use_hash(t) use_hash(p) swap_join_inputs(p) */ p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold) from sales200 s, times200 t, products200 p where s.time_id = t.time_id and s.prod_id = p.prod_id and t.CALENDAR_YEAR in (2000,2001) and p.prod_name like 'Deluxe%' group by p.prod_name, t.calendar_year; ---------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem | ---------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 2 |00:00:00.66 | 4495 | 4432 | | | | | 1 | HASH GROUP BY | | 1 | 12381 | 2 |00:00:00.66 | 4495 | 4432 | 1407K| 1407K| 1094K (0)| |* 2 | HASH JOIN | | 1 | 12381 | 6669 |00:00:00.66 | 4495 | 4432 | 1451K| 1451K| 397K (0)| |* 3 | TABLE ACCESS FULL | PRODUCTS200 | 1 | 1 | 1 |00:00:00.01 | 4 | 0 | | | | |* 4 | HASH JOIN | | 1 | 755K| 492K|00:00:00.67 | 4491 | 4432 | 51M| 7734K| 74M (0)| | 5 | TABLE ACCESS FULL| SALES200 | 1 | 755K| 918K|00:00:01.32 | 4436 | 4432 | | | | |* 6 | TABLE ACCESS FULL| TIMES200 | 1 | 731 | 731 |00:00:00.01 | 55 | 0 | | | | ----------------------------------------------------------------------------------------------------------------------------------
✏️ sort merge join도 조인되는 순서가 중요한가?
select /*+ gather_plan_statistics leading(d e) use_merge(e) */ e.ename, d.loc, e.deptno
from emp e, dept d
where e.deptno = d.deptno;
➡️ 정렬을 하지 않았지만 merge join이 일어났으므로 deptno가 정렬이 되었다.

➡️ 조인 순서가
dept -> emp : 조인 시도 횟수 4번
emp -> dept : 조인 시도 횟수 14번
문제1. sort merge join으로 위 SQL을 실행했을 때 조인 순서에 따라 버퍼의 갯수가 차이가 나는지 확인하기
✔️ dept -> emp
✔️ dep -> dept
select /*+ gather_plan_statistics leading(d e) use_merge(e) */ e.ename, d.loc, e.deptno from emp e, dept d where e.deptno = d.deptno; ----------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ----------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 14 | | | | | 1 | MERGE JOIN | | 1 | 14 | 14 |00:00:00.01 | 14 | | | | | 2 | SORT JOIN | | 1 | 4 | 4 |00:00:00.01 | 7 | 2048 | 2048 | 2048 (0)| | 3 | TABLE ACCESS FULL| DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | | |* 4 | SORT JOIN | | 4 | 14 | 14 |00:00:00.01 | 7 | 2048 | 2048 | 2048 (0)| | 5 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | | ----------------------------------------------------------------------------------------------------------------- select /*+ gather_plan_statistics leading(e d) use_merge(d) */ e.ename, d.loc, e.deptno from emp e, dept d where e.deptno = d.deptno; ----------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ----------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 14 | | | | | 1 | MERGE JOIN | | 1 | 14 | 14 |00:00:00.01 | 14 | | | | | 2 | SORT JOIN | | 1 | 14 | 14 |00:00:00.01 | 7 | 2048 | 2048 | 2048 (0)| | 3 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | | |* 4 | SORT JOIN | | 14 | 4 | 14 |00:00:00.01 | 7 | 2048 | 2048 | 2048 (0)| | 5 | TABLE ACCESS FULL| DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | | -----------------------------------------------------------------------------------------------------------------➡️ 위 SQL은 차이가 없지만 SORT MERGE 조인도 순서가 중요하다.
✏️ Outer join 튜닝 방법
💡 아우터 조인의 실행계획은 조인되는 순서가 기본적으로 outer 조인 사인이 없는 쪽에서 있는쪽으로 조인을 합니다.
# 예)
select /*+ gather_plan_statistics */ e.ename, d.loc
from emp e, dept d
where e.deptno(+) = d.deptno;
SELECT *
FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 15 |00:00:00.01 | 14 | | | |
|* 1 | HASH JOIN OUTER | | 1 | 14 | 15 |00:00:00.01 | 14 | 1696K| 1696K| 1083K (0)|
| 2 | TABLE ACCESS FULL| DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | |
| 3 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | |
----------------------------------------------------------------------------------------------------------------문제1. 아래의 데이터를 입력하고 아래의 SQL을 수행하는데 조인 순서를 dept -> emp 순이 되게 하시오!
insert into emp(empno,ename,sal,deptno) values(2921,'JACK',4500,70); select /*+ gather_plan_statistics leading(d e) use_hash(e) */ e.ename, d.loc from emp e, dept d where e.deptno = d.deptno(+); ---------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ---------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 14 | | | | |* 1 | HASH JOIN OUTER | | 1 | 14 | 14 |00:00:00.01 | 14 | 1753K| 1753K| 962K (0)| | 2 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | | | 3 | TABLE ACCESS FULL| DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | | ----------------------------------------------------------------------------------------------------------------➡️ 아우터 조인은 기본적으로 조인 순서가 outer join sign이 없는쪽에서 있는쪽으로 조인이 되므로 leading 힌트가 소용이 없어졌다.
아우터 조인은 기본적으로 조인 순서가 outer join sign이 없는쪽에서 있는쪽으로 조인이 된다. leading 힌트가 안되므로 swap join inputs 힌트 사용하기!!
select /*+ gather_plan_statistics leading(d e) use_hash(e) swap_join_inputs(d) */ e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno(+);
-------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 14 | | | |
|* 1 | HASH JOIN RIGHT OUTER| | 1 | 14 | 14 |00:00:00.01 | 14 | 1696K| 1696K| 1083K (0)|
| 2 | TABLE ACCESS FULL | DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | |
| 3 | TABLE ACCESS FULL | EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | |
-------------------------------------------------------------------------------------------------------------------➡️ swap_join_inputs으로 조인 순서를 변경했다.
문제2. 아래 SQL을 튜닝하기(해쉬조인으로 수행, 조인 순서도 변경하기)
✔️ 튜닝 전
select /*+ leading(s t) use_nl(t) */ t.calendar_year, sum(s.amount_sold) from sales200 s, times200 t where s.time_id = t.time_id (+) and t.week_ending_day_id = 1581 group by t.calendar_year;✔️ 튜닝 후
select /*+ gather_plan_statistics leading(t s) use_hash(s) swap_join_inputs(t) */ t.calendar_year, sum(s.amount_sold) from sales200 s, times200 t where s.time_id = t.time_id (+) and t.week_ending_day_id = 1581 group by t.calendar_year; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); ------------------------------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem | ------------------------------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.32 | 4491 | 4432 | | | | | 1 | HASH GROUP BY | | 1 | 9718 | 1 |00:00:00.32 | 4491 | 4432 | 1200K| 1200K| 525K (0)| |* 2 | HASH JOIN | | 1 | 9718 | 3490 |00:00:00.04 | 4491 | 4432 | 1599K| 1599K| 872K (0)| |* 3 | TABLE ACCESS FULL| TIMES200 | 1 | 7 | 7 |00:00:00.01 | 55 | 0 | | | | | 4 | TABLE ACCESS FULL| SALES200 | 1 | 755K| 918K|00:00:00.58 | 4436 | 4432 | | | | ------------------------------------------------------------------------------------------------------------------------------➡️
swap_join_inputs(t)를 쓰지 않아도 결과가 잘 출력되긴 하지만 지금 hash join right outer가 안나왔다. 이것은 쿼리 변형기가 아우터조인 할 필요 없잖아 하고 알아서 빼고 조인한것이다.select /*+ gather_plan_statistics leading(t s) use_hash(s) swap_join_inputs(t) */ t.calendar_year, sum(s.amount_sold) from sales200 s, times200 t where s.time_id = t.time_id (+) and t.week_ending_day_id(+) = 1581 group by t.calendar_year; --------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem | --------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 2 |00:00:00.88 | 4491 | 4432 | | | | | 1 | HASH GROUP BY | | 1 | 755K| 2 |00:00:00.88 | 4491 | 4432 | 62M| 6396K| 3689K (0)| |* 2 | HASH JOIN RIGHT OUTER| | 1 | 755K| 918K|00:00:01.37 | 4491 | 4432 | 1599K| 1599K| 1187K (0)| |* 3 | TABLE ACCESS FULL | TIMES200 | 1 | 7 | 7 |00:00:00.01 | 55 | 0 | | | | | 4 | TABLE ACCESS FULL | SALES200 | 1 | 755K| 918K|00:00:00.77 | 4436 | 4432 | | | | ---------------------------------------------------------------------------------------------------------------------------------➡️ 위처럼 나와야 함!!
✔️ full outer join 튜닝
select /*+ gather_plan_statistics */ e.ename, d.loc
from emp e full outer join dept d
on (e.deptno=d.deptno);
-----------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-----------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 15 |00:00:00.01 | 14 | | | |
| 1 | VIEW | VW_FOJ_0 | 1 | 15 | 15 |00:00:00.01 | 14 | | | |
|* 2 | HASH JOIN FULL OUTER| | 1 | 15 | 15 |00:00:00.01 | 14 | 1696K| 1696K| 1068K (0)|
| 3 | TABLE ACCESS FULL | DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | |
| 4 | TABLE ACCESS FULL | EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | |
----------------------------------------------------------------------------------------------------------------------- ➡️ 위와 같이 실행계획이 나오면 쿼리 변형기가 제대로 full outer join을 한 것이다!!
쿼리 변형기가 SQL을 union all도 사용하고 in line view도 사용하면서 복잡하게 쿼리를 재작성해서 위 결과를 출력할 수도 있다. 그렇게 되면 성능이 느려진다!
그런 경우 실행계획을 일부러 보자면 다음과 같다.
select /*+ gather_plan_statistics optimizer_features_enable('10.2.0.1') opt_param('_optimizer_native_full_outer_join','off') */ e.ename, d.loc from emp e full outer join dept d on (e.deptno=d.deptno);⭐ 11g -> 19c 업그레이드 할 때 제일 걱정하는 부분이 11g 버전일 때 잘 수행되던 SQL이 19c로 업그레이드 하면 느려지는 것을 걱정한다.
optimizer_features_enable(오라클버전)힌트를 쓰면 해당 버전일때의 옵티마이저 실행계획이 출력된다.------------------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ------------------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | 15 |00:00:00.01 | 28 | | | | | 1 | VIEW | | 1 | 15 | 15 |00:00:00.01 | 28 | | | | | 2 | UNION-ALL | | 1 | | 15 |00:00:00.01 | 28 | | | | |* 3 | HASH JOIN OUTER | | 1 | 14 | 14 |00:00:00.01 | 14 | 1753K| 1753K| 947K (0)| | 4 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | | | 5 | TABLE ACCESS FULL| DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | | |* 6 | HASH JOIN ANTI | | 1 | 1 | 1 |00:00:00.01 | 14 | 1696K| 1696K| 1068K (0)| | 7 | TABLE ACCESS FULL| DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | | | 8 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | | ------------------------------------------------------------------------------------------------------------------❓ 지금 위에가 튜닝 전 실행계획이 나온건데, 이런 실행계획이 나온다면 아래와 같이 튜닝한다!
select /*+ gather_plan_statistics optimizer_features_enable('10.2.0.1') opt_param('_optimizer_native_full_outer_join','on') */ e.ename, d.loc from emp e full outer join dept d on (e.deptno=d.deptno); ----------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ----------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 15 |00:00:00.01 | 14 | | | | | 1 | VIEW | VW_FOJ_0 | 1 | 15 | 15 |00:00:00.01 | 14 | | | | |* 2 | HASH JOIN FULL OUTER| | 1 | 15 | 15 |00:00:00.01 | 14 | 1696K| 1696K| 1068K (0)| | 3 | TABLE ACCESS FULL | DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | | | 4 | TABLE ACCESS FULL | EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | | -----------------------------------------------------------------------------------------------------------------------➡️
opt_param힌트는 오라클 파라미터를 시스템 레벨이 아닌 SQL레벨에 적용할 때 사용하는 힌트이다!
➡️_optimizer_native_full_outer_join하라미터는 union all을 쓰면서 복잡하게 sql이 변경이 되면 그렇게 하지 말고 그냥 순수하게 full outer join 하라고 옵티마이저에게 알려주는 것이다!
문제. 아래의 SQL의 조인순서가 emp->dept 가 되게 하기
-- 튜닝 전
select /*+ gather_plan_statistics */ e.ename, d.loc
from emp e, dept d
where e.deptno(+)=d.deptno
and e.job(+)='SALESMAN';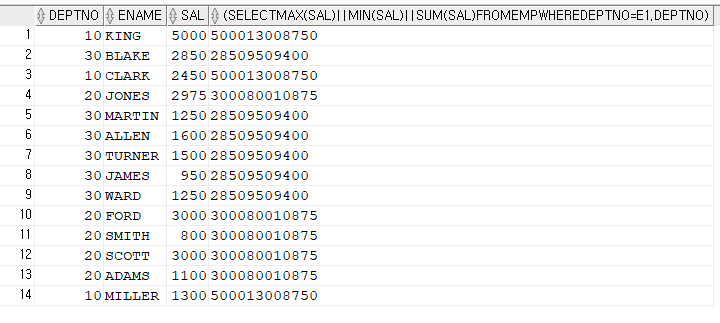
✔️ 튜닝 후
select /*+ gather_plan_statistics leading(e d) use_hash(d) swap_join_inputs(e) */ e.ename, d.loc from emp e, dept d where e.deptno(+)=d.deptno and e.job(+)='SALESMAN'; ------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 7 |00:00:00.01 | 14 | | | | |* 1 | HASH JOIN RIGHT OUTER| | 1 | 4 | 7 |00:00:00.01 | 14 | 1753K| 1753K| 418K (0)| |* 2 | TABLE ACCESS FULL | EMP | 1 | 4 | 4 |00:00:00.01 | 7 | | | | | 3 | TABLE ACCESS FULL | DEPT | 1 | 4 | 4 |00:00:00.01 | 7 | | | | -------------------------------------------------------------------------------------------------------------------
✏️ 스칼라 서브쿼리를 이용한 조인
💡select 문에서 서브쿼리를 쓸 수 있는 절
select -> subquery -> scalar subquery
from -> subquery -> in line view
where -> subquery
group by -> X
having -> subquery
order by -> subquery -> scalar subquery
문제1. 이름, 월급, 사원 테이블의 최대 월급을 출력하기
-- 튜닝 전
select /*+ gather_plan_statistics */ ename, sal, (select max(sal) from emp) maxsal
from emp;
-------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 7 |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 7 |
| 2 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 |
| 3 | TABLE ACCESS FULL | EMP | 1 | 14 | 14 |00:00:00.01 | 7 |
-------------------------------------------------------------------------------------➡️ EMP 테이블을 두번이나 엑세스 하고 있는것이 문제!
-- 튜닝 후
select /*+ gather_plan_statistics */ ename, sal, max(sal) over() as maxsal
from emp;
----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 7 | | | |
| 1 | WINDOW BUFFER | | 1 | 14 | 14 |00:00:00.01 | 7 | 2048 | 2048 | 2048 (0)|
| 2 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | |
----------------------------------------------------------------------------------------------------------------➡️ WINDOW BUFFER
문제2. 부서번호, 이름, 월급, 자기가 속한 부서번호의 최대 월급 출력하기
✔️튜닝 전
select /*+ gather_plan_statistics */ deptno, ename, sal, (select max(sal) from emp where deptno=e1.deptno) from emp e1; ------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 7 | | 1 | SORT AGGREGATE | | 3 | 1 | 3 |00:00:00.01 | 21 | |* 2 | TABLE ACCESS FULL| EMP | 3 | 1 | 14 |00:00:00.01 | 21 | | 3 | TABLE ACCESS FULL | EMP | 1 | 14 | 14 |00:00:00.01 | 7 | -------------------------------------------------------------------------------------✔️튜닝 후
select /*+ gather_plan_statistics */ deptno, ename, sal, max(sal) over(partition by deptno) from emp; ---------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ---------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 7 | | | | | 1 | WINDOW SORT | | 1 | 14 | 14 |00:00:00.01 | 7 | 2048 | 2048 | 2048 (0)| | 2 | TABLE ACCESS FULL| EMP | 1 | 14 | 14 |00:00:00.01 | 7 | | | | ----------------------------------------------------------------------------------------------------------------
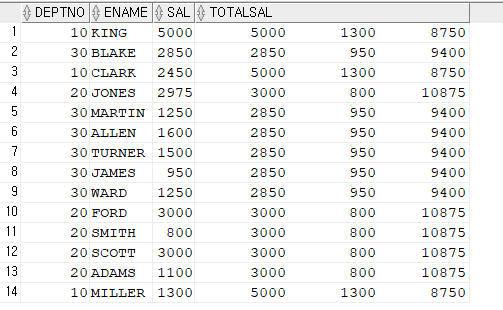
문제3. (재작년 SQLP 주관식 문제) 부서번호, 이름, 월급, 자기가 속한 부서번호의 최대월급, 자기가 속한 부서번호의 최소월급, 자기가 속한 부서번호의 토탈 월급 출력
select /*+ gather_plan_statistics */ deptno, ename, sal,
max(sal) over(partition by deptno),
min(sal)over(partition by deptno),
sum(sal)over(partition by deptno)
from emp;문제4. 위 결과를 분석함수를 사용하지 말고 스칼라 서브쿼리로 출력하기
-- 튜닝 전 SQL이다. 악성 sql!! select /*+ gather_plan_statistics */ deptno, ename, sal, (select max(sal) from emp where deptno=e1.deptno) as maxsal, (select min(sal) from emp where deptno=e1.deptno) as minsal, (select sum(sal) from emp where deptno=e1.deptno) as sumsal from emp e1; ------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 7 | | 1 | SORT AGGREGATE | | 3 | 1 | 3 |00:00:00.01 | 21 | |* 2 | TABLE ACCESS FULL| EMP | 3 | 1 | 14 |00:00:00.01 | 21 | | 3 | SORT AGGREGATE | | 3 | 1 | 3 |00:00:00.01 | 21 | |* 4 | TABLE ACCESS FULL| EMP | 3 | 1 | 14 |00:00:00.01 | 21 | | 5 | SORT AGGREGATE | | 3 | 1 | 3 |00:00:00.01 | 21 | |* 6 | TABLE ACCESS FULL| EMP | 3 | 1 | 14 |00:00:00.01 | 21 | | 7 | TABLE ACCESS FULL | EMP | 1 | 14 | 14 |00:00:00.01 | 7 | -------------------------------------------------------------------------------------➡️ EMP 테이블을 4번이나 조회하고있다. 대표적인 튜닝 전 SQL이다!
- 힌트
select max(sal), min(sal), sum(sal) from emp where deptno = 10; select /*+ gather_plan_statistics */ deptno, ename, sal, (select max(sal), min(sal), sum(sal) from emp where deptno=e1.deptno) from emp; -- 00913. 00000 - "too many values"➡️ 스칼라 서브쿼리의 특징은 딱 한개의 결과값만 출력한다.
select /*+ gather_plan_statistics */ deptno, ename, sal, (select max(sal) || min(sal) || sum(sal) from emp where deptno=e1.deptno) from emp e1;
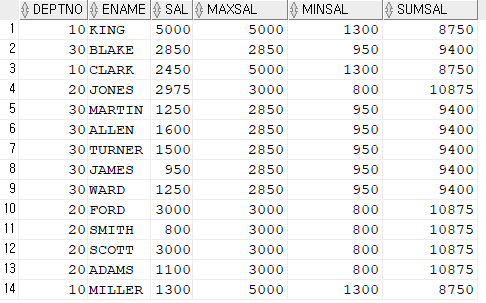
💡 최대값, 최소값, 토탈값을 잘라내야하는데 잘라내기 좋도록 만들어주기select /*+ gather_plan_statistics */ deptno, ename, sal, (select lpad(max(sal),10,' ')|| lpad(min(sal),10,' ') || lpad(sum(sal),10,' ') from emp where deptno=e1.deptno)as totalsal from emp e1;💡 substr 사용해서 최종튜닝
select deptno, ename, sal, substr(totalsal,1,10) maxsal, substr(totalsal,11,10) minsal, substr(totalsal,21,10) sumsal from ( select /*+ gather_plan_statistics */ deptno, ename, sal, (select lpad(max(sal),10,' ')|| lpad(min(sal),10,' ') || lpad(sum(sal),10,' ') from emp where deptno=e1.deptno)as totalsal from emp e1 ) ;
문제 아래의 SQL을 튜닝하기
-- 튜닝 전
select /*+ gather_plan_statistics */ ename, sal, job,
(select max(sal) from emp where job=e1.job) maxsal,
(select min(sal) from emp where job=e1.job) minsal,
(select sum(sal) from emp where job=e1.job) sumsal
from emp e1
where sal between 1000 and 3000;✔️ 튜닝 후
select /*+ gather_plan_statistics */ ename, sal, job, substr(totalsal,1,10) maxsal, substr(totalsal,11,10) minsal, substr(totalsal,21,10) sumsal from ( select ename, sal, job,(select lpad(max(sal),10,' ')|| lpad(min(sal),10,' ') || lpad(sum(sal),10,' ') from emp where deptno=e1.deptno)as totalsal from emp e1 ) where sal between 1000 and 3000; ------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 11 |00:00:00.01 | 7 | | 1 | SORT AGGREGATE | | 3 | 1 | 3 |00:00:00.01 | 21 | |* 2 | TABLE ACCESS FULL| EMP | 3 | 1 | 14 |00:00:00.01 | 21 | |* 3 | TABLE ACCESS FULL | EMP | 1 | 11 | 11 |00:00:00.01 | 7 | -------------------------------------------------------------------------------------
✏️ 조인을 내포한 DML문 튜닝
💡 DML문에서의 서브쿼리문
문제1. ALLEN의 월급을 KING의 월급으로 변경하기
update emp set sal = ( select sal from emp where ename='KING') where ename = 'ALLEN';
❓ update 문에서는 어디에 서브쿼리를 쓸 수 있는가?
- update <- 서브쿼리
- set <- 서브쿼리
- where <- 서브쿼리
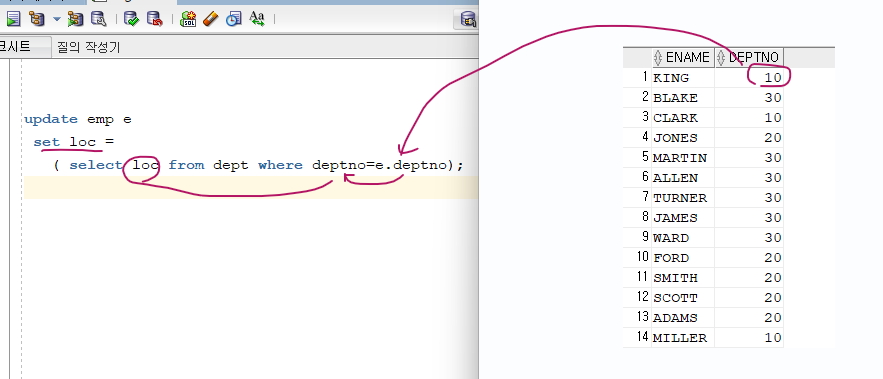
문제2. 사원 테이블에 loc 컬럼을 추가하고 해당 사원이 속한 부서위치로 값을 갱신
alter table emp add loc varchar2(10); -- 내 오답 update emp set loc = ( select loc from emp e, dept d where e.deptno=d.deptno); -- 답 update emp e set loc = ( select loc from dept where deptno=e.deptno); select ename, loc from emp;
➡️ 위 SQL은 emp 테이블의 건수만큼 update를 반복한다. 그래서 성능이 떨어진다. emp테이블이 14건이면 14번 update문이 실행됨 그래서 튜닝전 SQL이다.
튜닝 후SQL이 되려면 update가 1번만 실행될 수 있도록 해야한다.
alter table emp
add loc varchar2(10);문제3. 아래의 view를 생성하기
create or replace view emp100
as
select e.empno, e.ename, e.sal, e.loc as emp_loc, d.loc as dept_loc
from emp e, dept d
where e.deptno=d.deptno;
select emp_loc,dept_loc
from emp300;
update emp300
set emp_loc=dept_loc;
-- ORA-01779 error가 난다. ➡️ 위와 같이 에러가 발생합니다. 이 update 가 가능하려면 dept 테이블에 deptno 에 primary key 제약이 걸려 있어야합니다.
alter table dept add constraint dept_deptno_pk primary key(deptno); ??왜 여기 update emp300 set emp_loc=dept_loc; select ename, loc from emp;➡️ view를 update한다는 것은 실제 테이블을 update한다는 것이다.
만약 뷰를 만들 수 없다면 다음과 같이 update문에 서브쿼리를 사용하면 된다.update emp set loc=null; commit; alter table dept add constraint dept_deptno_pk primary key(deptno); --튜닝전 update emp e set loc = ( select loc from dept d where d.deptno = e.deptno ); alter table dept add constraint dept_deptno_pk primary key(deptno); --튜닝후 update ( select e.empno, e.ename, e.sal, e.loc as emp_loc, d.loc as dept_loc from emp e, dept d where e.deptno = d.deptno ) set emp_loc = dept_loc;
문제5. emp 테이블에 dname컬럼을 추가하고 dname을 해당 사원의 부서명으로 값을 갱신하기
update (select e.empno, e.ename, e.sal, e.dname as emp_dname, d.dname as dept_dname from emp e, dept d where e.deptno=d.deptno) set emp_dname = dept_dname;➡️ 한번에 update를 해서 성능이 개선된다.
문제6. 이번에는 merge문으로 값을 갱신
update emp
set loc=null;
-- 튜닝 전
update emp e
set loc = (select loc
fro dept
where deptno = e.deptno );튜닝 후
merge into emp e using dept d on ( e.deptno = d.deptno ) when matched then update set e.loc = d.loc ;
문제7. 아래의 환경 만들기
✔️ 실습 환경만들기
drop table sales100; drop table sales200;create table sales100 as select * from sh.sales; create table sales200 as select rownum rn, prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold from sales100;alter table sales200 add date_id date;create table time2 ( rn number(10), date_id date );begin for i in 1 .. 918843 loop insert into time2 values( i , to_date('1961/01/02','YYYY/MM/DD')+ i ); end loop; end; / commit;select rn, date_id from sales200 where rownum < 100; select rn, date_id from time2 where rownum < 100;➡️ time2 테이블에는 date_id가 있지만 sales200 에는 없다. time2에 데이터 넣을거임
✔️ 튜닝 전
set timing on update sales200 s set date_id = (select date_id from time2 where rn=s.rn);✔️ 튜닝 후
merge into sales200 s using time2 t on (s.rn = t.rn) when matched then update set s.date_id = t.date_id ;
